摘要: 基于对数据时间旅行的思考,引出了对目前三种数仓形态和两种数仓架构的思考。结合数据湖在 Flink 的应用和数据湖元数据类型的思考,探索了基于数据湖的 Flink SQL 流批一体的实践,在流批一体 SQL 表达一致、结果一致性、流批任务分离、混合调度依赖等进行了设计和探索。同时,欢迎大家多分享具体实践,一起共筑新的数据实践方式。
大规模的数据处理兴起于 Hadoop 生态的发展,关键在于分布式储存和分布式计算的发展,造就了如今近百种有关大数据的生态技术。数仓理论和建模理论基于大数据技术体系得以快速发展,其中离线数仓的标准化建设得到了广泛应用。数据的本质是一种行为的具象,业务在对数据的需求,核心在于对行为的可探索和可观察。基于此,我们需要明确一点,大数据技术是否完全满足了业务对数据需求在时间维度上的确定性了呢,这点是值得思考的。那么我们先来看一下数据的时间旅行。
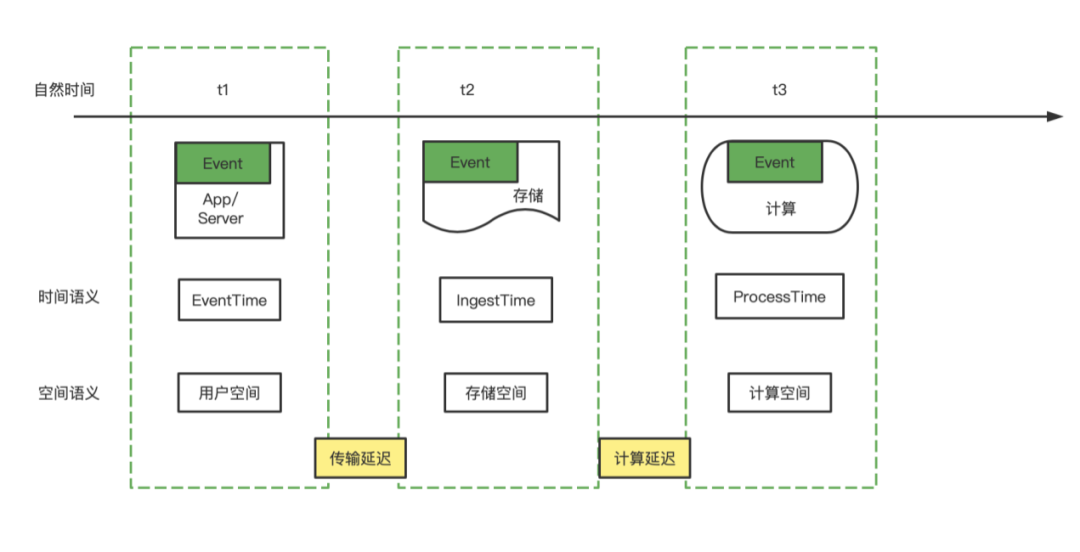
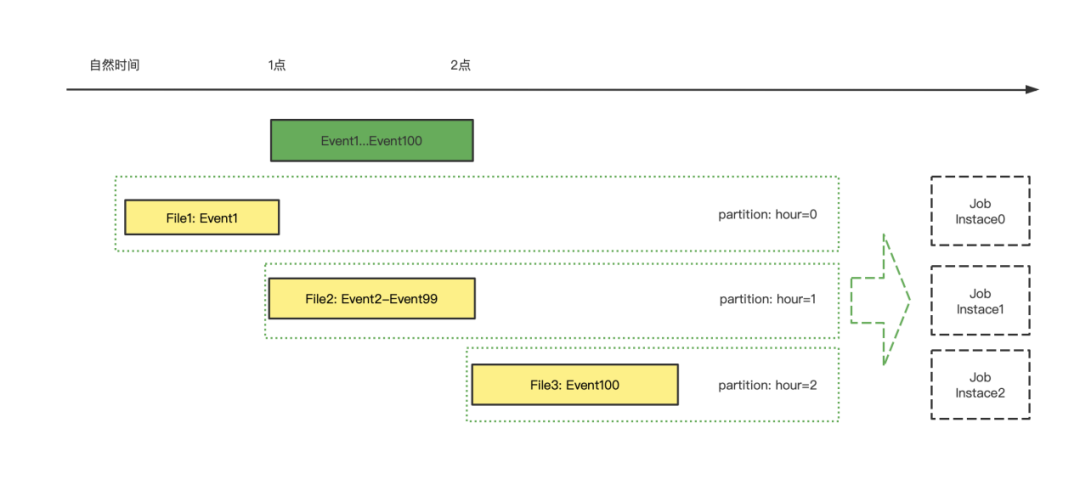
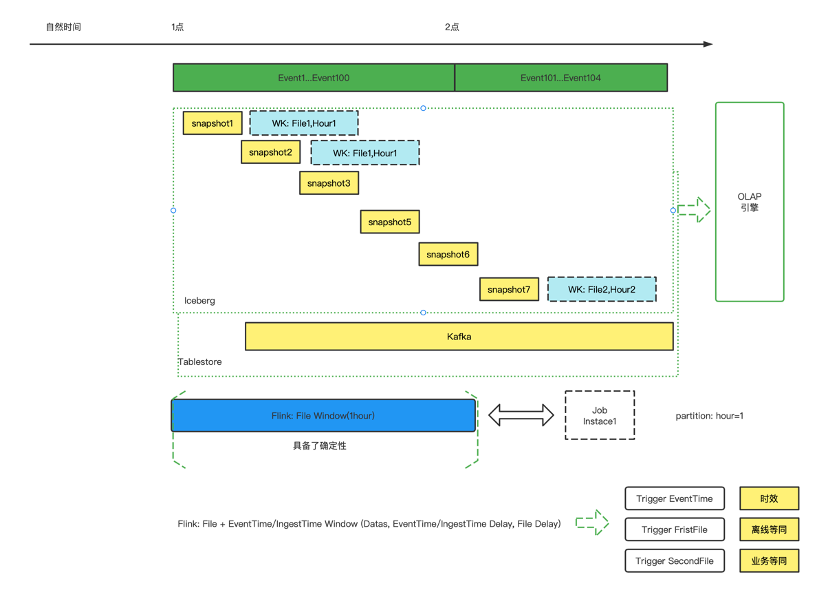
业务期望的数据:用户空间下的时间数据,t1时间数据,用户自然时间点或自然时间段的明细或者统计数据。 传输延迟:App 用户,数据发送到网关或者日志服务系统,或者 Server 日志落文件系统所产生的延迟。Event 进入到存储空间,可以代表数据已经是确定的,基本可观察,一般情况下,这个延迟很小。但是,在某些情况,比如 APP 的日志产生之后,但是因为网络等问题一直没有发送,或者 Server 宕机,导致延迟发送或者最终丢失。总体而言,传输延迟属于不可控延迟,暂时没有什么好的技术方案来解决。 存储空间:数据承载于实际的存储中,离线数仓承载于具体的分布式文件系统,实时数仓基于 Kafka 的消息队列系统,近实时数仓承载于数据湖存储中。这里可以抽象来看离线数仓,Event 承载于分布式文件系统,以小时分区为例,某个小时的分区本质是自然时间产生的文件的集合,时间精度退化为小时级别。 计算延迟:数据进入存储之后,与进入计算空间的时间差,t3-t2。实时数仓中,计算延迟是数据的 ProcessTime-IngestTime。离线数仓中,计算延迟是调度产生实例运行时间-数据进入存储空间的时间差。本质离线数仓和实时数仓的计算延迟在抽象上看是一致的。计算延迟在不同的数仓体系下,产生的时效不同,我们会划分为三种主流的数仓体系,秒级的实时数仓,分钟级的近实时数仓,小时级的离线数仓。可以看出,数仓的时效性差异,因为传输延迟的不可控,退化为计算延迟的差异。 在离线数仓和实时数仓,常常会提到数据的有界和无界,认为离线数仓的数据是有界的,实时数仓的消息流是无界的。准确与否在于数据的确定性考量。 离线数仓的确定性,在于文件自然生成时间的确定性和不可更改性,某个小时的自然文件生成,近似等于事件时间在自然时间的确定性,反例就是我们能看到数据漂移的情况,事件时间会或多或少落入上个小时或者下个小时的自然文件生成时间。那么离线数仓的确定性,实质是数据的 IngestTime 的确定性,具有天然的文件属性,易于分割。当我们说离线数仓计算的数据是准确的时候,默认了传输延迟带来的影响很小或者默认了当前小时的数据指标的标准是文件的自然形成时间。
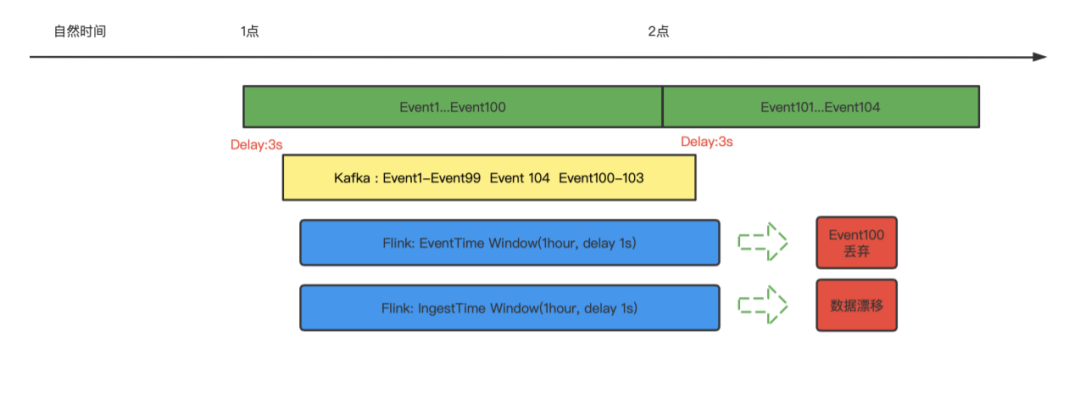
实时数仓,常常会提及不确定性或者说 Lambda 架构实际是对实时数仓的不确定性的替代方案。这种不确定性的原因是什么呢?这里分为四类情况说明,一是 ETL 的处理,从窗口上来说,是单条数据即为一个窗口,窗口的产生和销毁在一个 Event 中完成,y=window(data)。二是基于 EventTime 的时间窗口,如果再定义延迟时间,y=window(datas, datas.EventTime, delay),第三种和第四种分别就是 IngestTime 和 ProcessTime 的时间窗口函数。对比离线数仓,可以看出,基于 IngestTime 的时间窗口和离线数仓的时间语义最为一致。离线数仓在时间窗口上,可以看做为数据进入文件的自然时间所对应的小时窗口,数据所承载的文件的确定性,保证了小时窗口的数据确定性,y=window(files)。
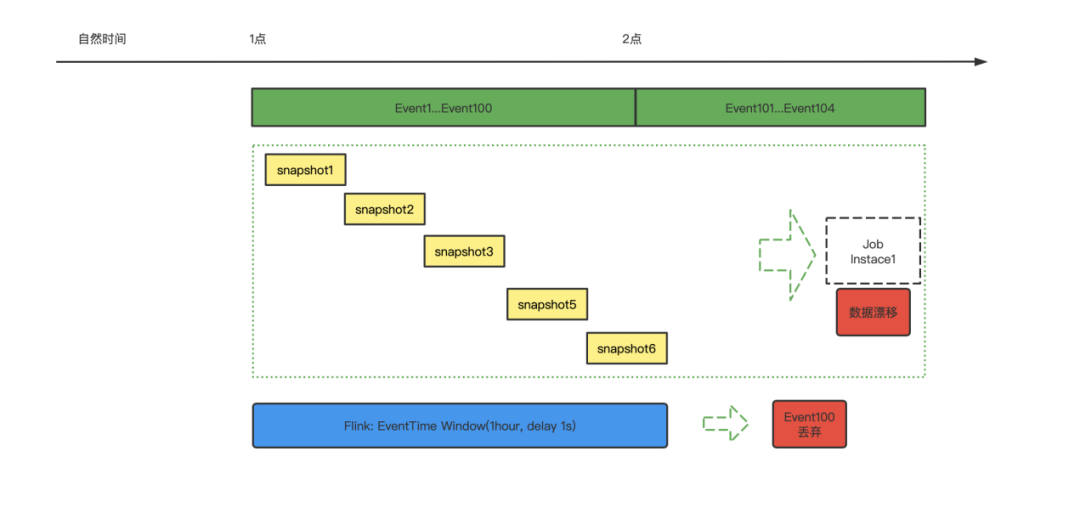
近实时数仓,比如基于 Iceberg 的数据湖建立的近实时数仓,在于离线数仓对比中,实际是将基于小时文件细分到分钟级别的快照文件上来,y=window(snapshots)。对比实时数仓,因为 Kafka 的 IngestTime 目前在精确性上是不精确的,基于快照的文件划分,在精确性上有一定的保证,同时在降低时效程度,从秒退化为分钟,很多场景是可以容忍的。
三种在时间维度对比上看,一是在某个时间,统计的本质对业务的需求都是近似的,这个本质是传输延迟所带来的,但是这个在实践中,不影响数据的可用性和统计学意义。二是不同数仓的划分,是存储和计算技术发展所带来的。三是离线数仓的确定性模糊了传输延迟,实时数仓的不确定性,是对传输延迟的一种取舍,人为的限定了 EventTime 的最大延迟时间,从而保证了指标的时效性,都是具有实践的意义所在。
Lambda 和 Kappa 架构
在时间维度下的取舍
当离线数仓刚刚发展的时候,只有一种数仓架构,也是基于大数据分布式处理刚刚发展的原因。随着实时技术的发展,大家在时效性上有了更多要求,但是同离线数仓对比的时候,在数据的准确性上,因为统计的窗口不同,必然会导致某个时刻的指标结果的不严格一致。 为了解决这种不严格一致的情况,Lambda 架构(由 Storm 的作者 Nathan Marz 提出的)产生的,实时确保时效,离线确保准确。最终会以确保离线三个时间窗口的统计一个事件时间窗口的结果,来回补实时数仓以为 EventTime 窗口,因为时效性丢弃的延迟数据的结果,从而保证业务上对 EventTime 窗口的要求,或者默认为离线的 IngestTime 所产生的文件分区近似认为 EventTime 的时间窗口。这种带来的弊端,维护两套数据路线,而大家总在想办法解决。 Kappa 架构的提出,得益于实时计算的效率提升,但是因为在批处理技术短板,生产实践推广受限。Kappa 架构是基于实时 EventTime 的一种数据窗口处理,因为 Kafka 的 IngestTime 不精确和为了同离线数仓对比而权衡考虑,EventTime 在传输延迟上的不可控,导致 Kappa 架构的准确性就会出现折扣。虽然是业务上最准确的时间范围,可行性上确不佳。 近些年来,不断发展的 MPP 架构的 OLAP 查询引擎,并不会涉及到时间窗口的计算取舍,OLAP 引擎本质是基于 ProcessTime 来加速查询的一种技术手段,是数仓不可分割的一部分,但是传输延迟的不可控没有解决,但是将计算延迟下推到了查询时,通过快速查询来解决尽可能减少计算延迟,同时保证了查询的灵活性,自助分析探索上有着广泛的应用。 从数仓架构的发展上看,不断在围绕结果的确定性,技术的可行性,数据的时效性,查询的灵活性上,不断的权衡,各个组件也是依据实际需求而发展起来的。 基于三种数仓体系和两种架构的思考,每个设计都是兼顾一种或多种考量,那么能不能实现一种机制,能够较好的满足数仓需求体系建设呢?从目前的技术发展上看,是有一定的可能性的。架构体系的发展一是基于技术基础,二是不断吸收组件的优点,做加法。 除去实时、近实时、离线数仓的划分,从技术的视角去看数仓建设的可行性。那么我们就要选取一些重要的点,取舍掉一些不可能的实现。 第一点是结果的确定性,这点是基于离线数仓发展的思考。不确定性带来的问题是信息的不对称,确定性的结果是可以模糊一定的指标含义的。 第二点是数据的时效性,高时效必然能够满足低时效,反之不然。另外数据的时效性,本身是基础组件的技术发展所限制的。 第三点是开发的便利性,排在时效性后面的考虑是,便利性是基于应用层面建设的,难度一般是弱于基础组件的,可以通过不断实践优化,达到一个良好的使用体验。 第四点是查询的灵活性和高响应,OLAP 的基础设计保证了查询速度,那么 OLAP 的技术架构体现是可以复用或者拓展的。 那么基于上面四点考虑,可以在实时数仓的基础上,优先解决掉确定性问题。这个是很重要的一个命题,要保证计算结果同离线数仓的一致性。这一点的实现方面,可以参考离线数仓,模糊 EventTime 和 IngestTime,用文件的 start 和 end 作为确定性的依据,文件的中间实时计算,确保时效性。那么基于Flink,就需要实现一种基于文件自然分割的 Watermark 机制,作为计算窗口划分的依据。 在确定性问题之后,需要解决计算的成本和使用的成本,这里比较重要的是存储层,实时数仓依赖 Kafka,Kafka 发展不具备数仓一些重要的点,成本是一个方面,查询是一个方面,Kafka 无法架构在各种 OLAP 引擎或者计算引擎上面。这里,近实时数仓的依赖,比如数据湖或者 Paimon,数据湖分钟级的时效。不过,从发展的角度上看,是一种可行的解决方案。数据湖兼顾了流计算和批计算,同时,如果未来 OLAP 引擎如果能够在数据湖上实现类似 MPP 架构的查询效率,这也是有可能的,比如短期可以用数据冗余,将数据湖格式的数据转换一份到 OLAP 对应的引擎上实现加速查询。 第三个方面,流式计算的管理和依赖机制,借鉴于离线数仓的管理方式,需要一套完备的数据依赖管理,任务容错回跑机制。实时数仓一般是基于单个任务式的管理,离线数仓是基于任务流的管理,那么实时数仓的发展,也必然要实现任务流的管理方式,覆盖整个开发链路。 为了实现一种统计的数仓架构,那么需要的发展工作如下:一是着重发展存储层,比如数据湖,既要比较好的适应流和批引擎,又要能够高度适应 OLAP 查询引擎。二是在实时数仓或者近实时数仓,引入类似离线数仓的调度依赖管理和补数和容错回跑机制,或者在离线调度上兼容流任务依赖调度,实现任务流级别的管理和流批一体的数仓实现。三是在引擎层着重发展Flink批处理能力。
最终的任务运行方式同时包含三种:实时模式、离线模式、业务模式,分别对应着不同的数据准确性级别。也可以任选其一或者其二作为运行方式。
基于 Flink 和数据湖
的流批一体近实时数仓设计示例
stg_table(partition=hour) =>计算任务(insert overwrite partition=hour)=> dwd_table(partition=hour)=>计算任务(insert overwrite partition=hour)=> dws_table(partition=hour)=>同步任务=>OLAP 加速=>数据服务 如果存储层是基于数据湖(以 Paimon 为例): 离线调度产生的表的版本信息,commit_kind: insert overwrite 类型的。同时离线任务的驱动,是基于调度依赖的驱动,one by one 的调度。 如果是基于流式计算,比如分钟级生成snapshot那么会演变为: stg_table(version=snapshot_id) =>计算任务(insert into version=snapshot_id)=> dwd_table(version=snapshot_id)=>计算任务(insert into version=snapshot_id)=> dws_table(version=snapshot_id)=>同步任务=>OLAP 加速=>数据服务 那么启动多个任务,任务是持续的运行。commit_kind: insert into类型的。 那么要想实现流批一体的近实时数仓,需要解决如下问题: 1. Flink 任务支持批量计算能力要持续不断的加强 从 Flink 1.16/1.17 的版本发布情况,在批处理能力上有比较大的提升,同时,社区也在持续不断的加强批处理能力以及同 hive 的兼容能力。 2. 如何使用同一份 Flink SQL,既可以用于批任务调度,又可以用于流任务运行呢 两张表:dwd_partition_word_count,dws_partition_word_count,计算 word count
CREATE TABLE tablestore.tablestore_test.dwd_partition_word_count ( logdate String , user_id bigint ) PARTITIONED BY (logdate) WITH ( 'bucket' = '3' ); CREATE TABLE tablestore.tablestore_test.dws_partition_word_count ( logdate String , user_id bigint , cnt BIGINT , PRIMARY KEY (logdate,user_id) NOT ENFORCED ) PARTITIONED BY (logdate) WITH ( 'bucket' = '3' );
批任务的 Flink SQL:
insert overwrite tablestore.tablestore_test.dws_partition_word_count PARTITION (logdate=${start_date}) select user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count where logdate=${start_date} group by user_id;insert overwrite tablestore.tablestore_test.dws_partition_word_countselect logdate, user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count where logdate=${start_date} group by logdate,user_id;
流任务的 Flink SQL:
insert into tablestore.tablestore_test.dws_partition_word_count select logdate,user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count group by logdate,user_id;
如何用一个 Flink SQL 来实现流批模型下的不同呢? 不同点:Insert into 和 Insert overwrite 的问题,这个通过在提交运行模式的时候,如果是批任务,则是 Insert Overwrite,如果是流任务,则转为 Insert into,这个在技术上没有什么难点。 不同点:Where 条件的数据范围问题。抽象来看,流任务和批任务的时间范围在表达上是可以统一的
insert overwrite tablestore.tablestore_test.dws_partition_word_countselect logdate, user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count where logdate>=${start_date} and logdategroupby logdate,user_id;
比如跑 4 月 22 号一天的数据,执行的批 SQL 为:
insert overwrite tablestore.tablestore_test.dws_partition_word_countselect logdate, user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count where logdate>='20230422' and logdate'20230422'group by logdate,user_id;
select logdate, user_id,count (1 ) as cnt from tablestore.tablestore_test.dwd_partition_word_count where logdate>='19700101' and logdate'99990101'group by logdate,user_id;
insert overwrite/into 和时间范围,可以由平台执行的时候自动转换和参数输入。 任务完成开发,在批模式下,用调度任务验证了逻辑无误,那么之后可以用流模式,一直持续不断的运行。一是计算逻辑变更或者历史数据修复怎么办,二是可不可以支持流批双跑。其实本质是一个问题。如果计算逻辑变更,那么可以修改流批一体的 SQL 逻辑,然后流任务重启应用新的计算逻辑。同时,流批一体的 SQL,在调度上回跑历史数据,重新刷写数据。 重刷历史数据的时候,流任务会不会读取到重刷的历史数据进行计算。 这个问题主要是通过上述说的数据湖版本 commit kind 解决。批任务只应用 insert overwrite,流任务应用 insert into.如果流任务检测到 insert overwrite 的版本提交,直接跳过,不做实际的数据读取和处理。只处理 insert into 的数据。实际批任务的执行,对流任务不会产生影响。 目前在数据湖流式读取上,只需要加个开关选项就可以实现。 4. 流任务的 Insert into 如何实现主键写入 如果流任务的 Insert into 不能实现主键写入,那么分区数据的重复性无法解决,那么就只能流批双跑来解决数据的重复性问题。也就是,下游如果是主键幂等写入,insert into 和 insert overwrite 语义等同。 这个可以通过数据湖主键表(比如 Paimon 的主键表)实现。Paimon 的主键表已初步具备生产可用性。 如果一个流任务,下游接的是批任务调度,如果实现调度依赖呢? 比较优雅的实现可以是,在流任务写入下游表的时候,假如数据的 Watermark 写入到下游表的属性中,如果最晚的数据已经是当前小时的 05 分,那么当前小时的下游调度任务,通过检查表的属性时间,就可以判断批任务的调度实例是否应该拉起。或者也可以基于流任务的运行延迟做检查依赖。 基于上述的实现和解决,我们基本就可以实现流批一体的 Flink SQL 在批模式和流模式下运行,如果调度依赖做的比较完善的情况下,可以实现流批混跑。同时补数或者双跑对流任务的稳定性不会产生影响。 实际开发,就可以用批任务先开发验证,然后用流模式拉起,数据产出基本是分钟级别的。出问题可以用批任务修正。 本文转载自张剑 Apache Flink ,原文链接:https://mp.weixin.qq.com/s/Pn_f01__R9IoqnkR_C59ow。