
Apache Hudi(发音为“hoodie”)是下一代流数据湖平台。 Apache Hudi 将核心仓库和数据库功能直接引入数据湖。 Hudi 提供表、事务、高效的更新插入/删除、高级索引、流式摄取服务、数据集群/压缩优化和并发性,同时将您的数据保持为开源文件格式。
Hudi目前支持Flink、Spark与Java引擎实现数据写入。今天我们挑选其中一种,来看一下Flink引擎中的DataStream API写入方式。
根据官网以及hudi相关代码,目前基于Flink DataStream API写入hudi的方式也可分为hudi官网所述的如下方式(https://hudi.apache.org/docs/flink-quick-start-guide#insert-data):
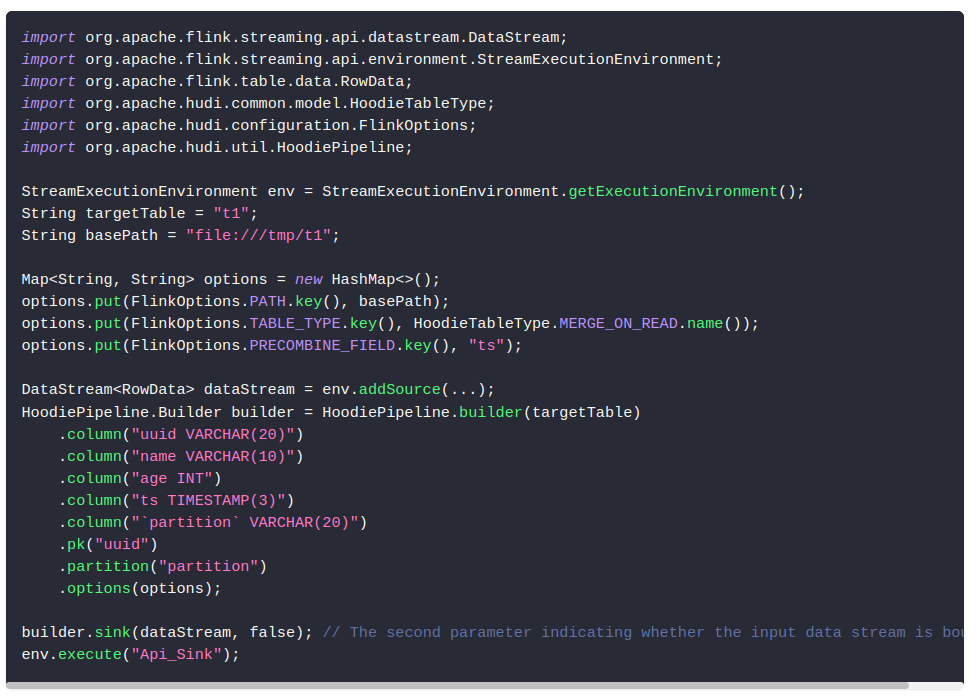

以及hudi源码中HoodieFlinkStreamer类提供的示例。
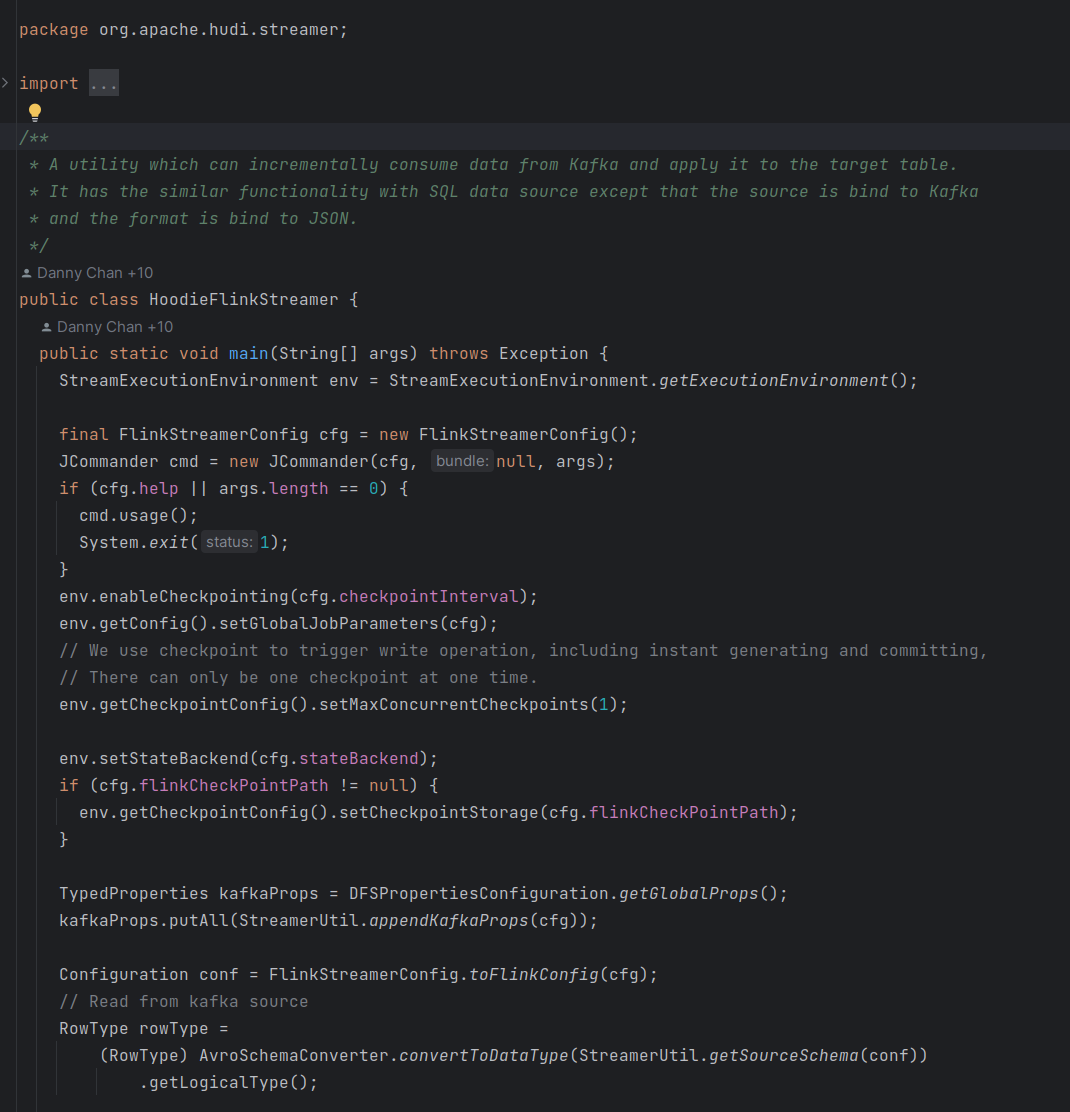
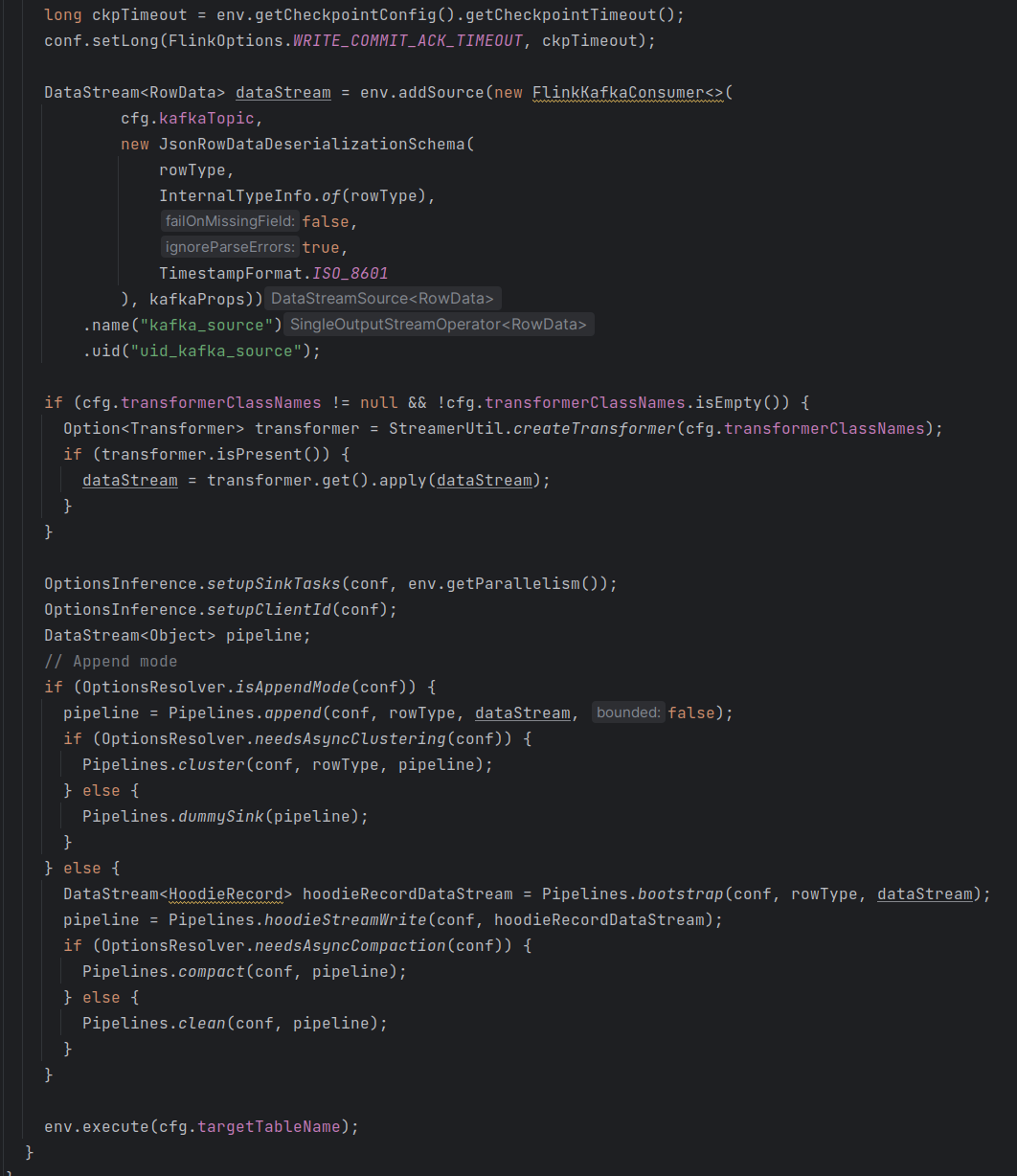
大概地,我们将上述两种方式分别成为HoodiePipeline方式和HoodieFlinkStreamer方式,两种方式本质上还是大同小异。下面我们简要分析一下这两种方式。
HoodiePipeline方式
Map<String, String> options = new HashMap<>();
options.put(FlinkOptions.PATH.key(), basePath);
options.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.MERGE_ON_READ.name());
options.put(FlinkOptions.PRECOMBINE_FIELD.key(), "ts");
DataStream<RowData> dataStream = env.addSource(...);
HoodiePipeline.Builder builder = HoodiePipeline.builder(targetTable)
.column("uuid VARCHAR(20)")
.column("name VARCHAR(10)")
.column("age INT")
.column("ts TIMESTAMP(3)")
.column("`partition` VARCHAR(20)")
.pk("uuid")
.partition("partition")
.options(options);
builder.sink(dataStream, false); // The second parameter indicating whether the input data stream is bounded
env.execute("Api_Sink"); 以数据写入为例,在读取数据源数据之后,基于表字段和表路径构建HoodiePipeline.Builder,进而在sink函数中传入数据源。
sink函数为具体执行者。其内容如下:
public DataStreamSink<?> sink(DataStream<RowData> input, boolean bounded) {
TableDescriptor tableDescriptor = getTableDescriptor();
return HoodiePipeline.sink(input, tableDescriptor.getTableId(), tableDescriptor.getResolvedCatalogTable(), bounded);
}HoodiePipeline.sink内容为:
/**
* Returns the data stream sink with given catalog table.
*
* @param input The input datastream
* @param tablePath The table path to the hoodie table in the catalog
* @param catalogTable The hoodie catalog table
* @param isBounded A flag indicating whether the input data stream is bounded
*/
private static DataStreamSink<?> sink(DataStream<RowData> input, ObjectIdentifier tablePath, ResolvedCatalogTable catalogTable, boolean isBounded) {
FactoryUtil.DefaultDynamicTableContext context = Utils.getTableContext(tablePath, catalogTable, Configuration.fromMap(catalogTable.getOptions()));
HoodieTableFactory hoodieTableFactory = new HoodieTableFactory();
return ((DataStreamSinkProvider) hoodieTableFactory.createDynamicTableSink(context)
.getSinkRuntimeProvider(new SinkRuntimeProviderContext(isBounded)))
.consumeDataStream(input);
}分析该return语句,其调用的方法为HoodieTableFactory#createDynamicTableSink,HoodieTableSink#getSinkRuntimeProvider,上述代码即hudi扩展flink的动态表的相关方法。
其中,HoodieTableSink#getSinkRuntimeProvider内容为:
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
return (DataStreamSinkProviderAdapter) dataStream -> {
// setup configuration
long ckpTimeout = dataStream.getExecutionEnvironment()
.getCheckpointConfig().getCheckpointTimeout();
conf.setLong(FlinkOptions.WRITE_COMMIT_ACK_TIMEOUT, ckpTimeout);
// set up default parallelism
OptionsInference.setupSinkTasks(conf, dataStream.getExecutionConfig().getParallelism());
// set up client id
OptionsInference.setupClientId(conf);
RowType rowType = (RowType) schema.toSinkRowDataType().notNull().getLogicalType();
// bulk_insert mode
final String writeOperation = this.conf.get(FlinkOptions.OPERATION);
if (WriteOperationType.fromValue(writeOperation) == WriteOperationType.BULK_INSERT) {
return Pipelines.bulkInsert(conf, rowType, dataStream);
}
// Append mode
if (OptionsResolver.isAppendMode(conf)) {
DataStream<Object> pipeline = Pipelines.append(conf, rowType, dataStream, context.isBounded());
if (OptionsResolver.needsAsyncClustering(conf)) {
return Pipelines.cluster(conf, rowType, pipeline);
} else {
return Pipelines.dummySink(pipeline);
}
}
DataStream<Object> pipeline;
// bootstrap
final DataStream<HoodieRecord> hoodieRecordDataStream =
Pipelines.bootstrap(conf, rowType, dataStream, context.isBounded(), overwrite);
// write pipeline
pipeline = Pipelines.hoodieStreamWrite(conf, hoodieRecordDataStream);
// compaction
if (OptionsResolver.needsAsyncCompaction(conf)) {
// use synchronous compaction for bounded source.
if (context.isBounded()) {
conf.setBoolean(FlinkOptions.COMPACTION_ASYNC_ENABLED, false);
}
return Pipelines.compact(conf, pipeline);
} else {
return Pipelines.clean(conf, pipeline);
}
};
}HoodieFlinkStreamer方式
相信分析完HoodiePipeline方式,HoodieFlinkStreamer方式也就死一目了然了,其直接使用的是HoodieTableSink#getSinkRuntimeProvider方法中的代码构造DataStream。
Flink DataStream API实现Hudi数据写入
官方给了HoodiePipeline方式写入hudi的示例,但是HoodieFlinkStreamer方式给的并不全。下面我们以HoodieFlinkStreamer方式为例,读取kafka数据进而写入Hudi。
kafka发送数据
数据结构
package com.zh.ch.bigdata.examples.kafka;
import java.io.Serializable;
public class HudiSource implements Serializable {
private int uuid;
private String name;
private int age;
private int ts;
public HudiSource() {
}
public HudiSource(int uuid, String name, int age, int ts) {
this.uuid = uuid;
this.name = name;
this.age = age;
this.ts = ts;
}
public int getUuid() {
return uuid;
}
public void setUuid(int uuid) {
this.uuid = uuid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getTs() {
return ts;
}
public void setTs(int ts) {
this.ts = ts;
}
}
producer类
package com.zh.ch.bigdata.examples.kafka;
import com.alibaba.fastjson2.JSON;
import com.zh.ch.bigdata.examples.utils.PropertiesUtil;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class KafkaProducerExample implements Runnable {
private static final Logger log = LoggerFactory.getLogger(KafkaProducerExample.class);
@Override
public void run() {
Properties kafkaConfig = PropertiesUtil.load("kafka/src/main/resources/kafkaConfig.properties");
try (KafkaProducer<String, Object> producer = new KafkaProducer<>(kafkaConfig)) {
for (int i = 500; i < 600; i++) {
producer.send(new ProducerRecord<>("hudi_topic_20230619_2", Integer.toString(i), JSON.toJSONString(new HudiSource(i, "name" + i, i, i))));
}
}
}
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
4,
8,
10,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10));
executor.execute(new KafkaProducerExample());
executor.shutdown();
}
}
相关参数:
bootstrap.servers =10.8.0.1:30092
linger.ms =1
acks =1
key.serializer =org.apache.kafka.common.serialization.StringSerializer
value.serializer =org.apache.kafka.common.serialization.StringSerializer
key.deserializer =org.apache.kafka.common.serialization.StringDeserializer
value.deserializer =org.apache.kafka.common.serialization.StringDeserializer
group.id =consumer-group-1Flink消费数据写入Hudi
package com.zh.ch.bigdata.examples.hudi;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.formats.common.TimestampFormat;
import org.apache.flink.formats.json.JsonRowDataDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.runtime.typeutils.InternalTypeInfo;
import org.apache.flink.table.types.logical.IntType;
import org.apache.flink.table.types.logical.RowType;
import org.apache.flink.table.types.logical.VarCharType;
import org.apache.hudi.com.beust.jcommander.JCommander;
import org.apache.hudi.common.config.DFSPropertiesConfiguration;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.configuration.OptionsInference;
import org.apache.hudi.configuration.OptionsResolver;
import org.apache.hudi.sink.transform.Transformer;
import org.apache.hudi.sink.utils.Pipelines;
import org.apache.hudi.streamer.FlinkStreamerConfig;
import org.apache.hudi.util.StreamerUtil;
import java.util.ArrayList;
import java.util.List;
/**
* 运行参数
* <p>
* --table-type MERGE_ON_READ
* --kafka-bootstrap-servers kafka:30092
* --kafka-topic hudi_topic_20230619_2
* --target-table hudi_tbl
* --target-base-path file:///data/hudi/hudidb/hudi_tbl
* --kafka-group-id consumer-group
* --source-avro-schema
* "{\"type\": \"record\",\"name\": \"triprec\",\"fields\": [ {\"name\": \"name\",\"type\": \"string\"},{\"name\":
* \"age\", \"type\": \"int\"},{\"name\":\"uuid\",\"type\": \"int\"},{\"name\":\"ts\",\"type\": \"long\"}]}"
*/
public class HudiFlinkStreamer {
public static void main(String[] args) throws Exception {
// 创建flink DataStream执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final FlinkStreamerConfig cfg = new FlinkStreamerConfig();
JCommander cmd = new JCommander(cfg, null, args);
if (cfg.help || args.length == 0) {
cmd.usage();
System.exit(1);
}
// 设置并行度
env.setParallelism(4);
// 设置checkpoint
env.enableCheckpointing(30000);
cfg.setString("rest.port", "8081");
env.getConfig().setGlobalJobParameters(cfg);
// We use checkpoint to trigger write operation, including instant generating and committing,
// There can only be one checkpoint at one time.
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.setStateBackend(cfg.stateBackend);
if (cfg.flinkCheckPointPath != null) {
env.getCheckpointConfig().setCheckpointStorage(cfg.flinkCheckPointPath);
}
Configuration conf = FlinkStreamerConfig.toFlinkConfig(cfg);
TypedProperties kafkaProps = DFSPropertiesConfiguration.getGlobalProps();
kafkaProps.putAll(StreamerUtil.appendKafkaProps(cfg));
// Read from kafka source
RowType.RowField rowField = new RowType.RowField("name", new VarCharType(VarCharType.MAX_LENGTH));
RowType.RowField rowField1 = new RowType.RowField("age", new IntType());
RowType.RowField rowField2 = new RowType.RowField("uuid", new IntType());
RowType.RowField rowField3 = new RowType.RowField("ts", new IntType());
List<RowType.RowField> rowFields = new ArrayList<>();
rowFields.add(rowField);
rowFields.add(rowField1);
rowFields.add(rowField2);
rowFields.add(rowField3);
RowType rowType = new RowType(rowFields);
DataStream<RowData> dataStream = env
.addSource(new FlinkKafkaConsumer<>(cfg.kafkaTopic, new JsonRowDataDeserializationSchema(rowType,
InternalTypeInfo.of(rowType), false, true, TimestampFormat.ISO_8601), kafkaProps))
.name("kafka_source").uid("uid_kafka_source");
if (cfg.transformerClassNames != null && !cfg.transformerClassNames.isEmpty()) {
Option<Transformer> transformer = StreamerUtil.createTransformer(cfg.transformerClassNames);
if (transformer.isPresent()) {
dataStream = transformer.get().apply(dataStream);
}
}
OptionsInference.setupSinkTasks(conf, env.getParallelism());
DataStream<Object> pipeline;
// Append mode
if (OptionsResolver.isAppendMode(conf)) {
pipeline = Pipelines.append(conf, rowType, dataStream, false);
if (OptionsResolver.needsAsyncClustering(conf)) {
Pipelines.cluster(conf, rowType, pipeline);
}
else {
Pipelines.dummySink(pipeline);
}
}
else {
DataStream<HoodieRecord> hoodieRecordDataStream = Pipelines.bootstrap(conf, rowType, dataStream);
pipeline = Pipelines.hoodieStreamWrite(conf, hoodieRecordDataStream);
if (OptionsResolver.needsAsyncCompaction(conf)) {
Pipelines.compact(conf, pipeline);
}
else {
Pipelines.clean(conf, pipeline);
}
}
pipeline.print();
env.execute(cfg.targetTableName);
}
}
总结
针对上述两种方式,我们可以发现其实都是大同小异的,最后都是调用的一段相同代码,都是相当灵活的。在使用过程中,可结合自己的业务场景分别选择。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/14195/