
近年来,随着大数据分析技术的进步,大量业务场景对数据仓库的实时性提出了更高的要求,Lakehouse 架构逐渐被各大公司熟悉和接受,Apache Hudi(以下简称 Hudi)、Apache Iceberg(以下简称 Iceberg)、Delta Lake 都被看成是下一代数据湖的解决方案,并被称为数据湖技术三剑客。
StarRocks 作为当前最流行的 OLAP 分析引擎之一,阿里云EMR OLAP 团队与 StarRocks 社区在 2021 年就开始合作,共同设计并实现了 StarRocks Connector 框架,用于统一外部数据源的接入分析,并且基于 Connector 框架完成了对 Hudi、Iceberg、Delta Lake 等主流数据湖表格式的接入。
#01
StarRocks 支持 Hudi 的现状
-
Copy On Write 表(简称 COW )
-
Merge On Read 表(简称 MOR )
#02
StarRocks 支持 Hudi 的技术解析
—
Hudi 将数据仓库和数据库的核心功能直接引入数据湖,并提供了表、事务、高效的更新/删除、高级索引、流式摄取服务、小文件管理、压缩优化和读写并发隔离等技术,同时将数据保持为开源文件格式(Parquet,ORC,Avro)。
Copy On Write 表:简称 COW,这类 Hudi 表使用列存储格式(例如 Parquet)存储数据,如果有数据写入,则会对整个 Parquet 文件进行复制。COW 表具备列存储读取效率高的优点,适用于对读取效率要求高的场景。
Merge On Read 表:简称 MOR,这类 Hudi 表使用列存储格式(例如 Parquet)和行存储格式(Avro)共同存储数据。当数据更新时,将更新写入到行文件中,然后根据作业配置,以同步或异步方式将两种格式的数据文件进行合并并生成新的列存储文件(Compaction)。MOR 表具备行存储写入效率高的优点,适用于对写入效率要求高的场景。
Hudi 对于两种类型的表,提供了不同的查询类型:
-
Snapshot Queries:快照查询,查询数据的最新快照,即表的最新数据
-
Incremental Queries:增量查询,可以查询指定时间范围内新增或修改的数据
-
Read Optimized Queries:读取优化查询,该查询为 MOR 表特有,仅查询 Parquet 文件中的数据,即牺牲一部分数据时效性来换取最佳的读取性能
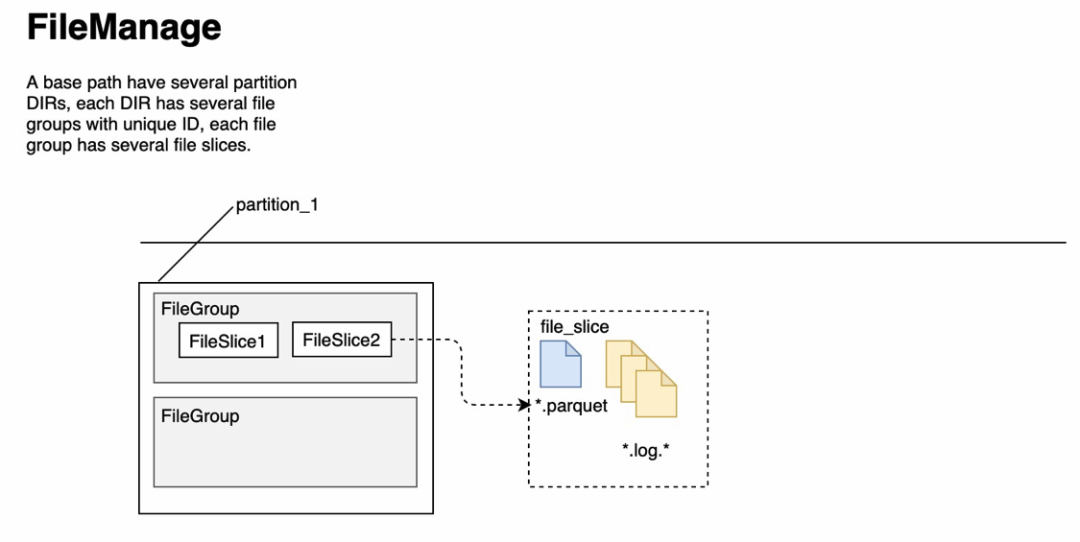
Hudi 将单个目录下的数据划分为多个 File group,每个 File group下包含多个 File Slice,File Slice 是 Hudi 文件组织系统里的最小管理单位,它由 0 个或 1 个 base 数据文件(列存储)和 0 个或多个增量 delta log 文件(行存储)组成。

StarRocks 整体架构分为两大部分:FE 和 BE,FE 使用 Java 语言,BE 使用 C++ 语言。
下面我们分别介绍 FE 和 BE 在外部表读取时对应的主要功能。
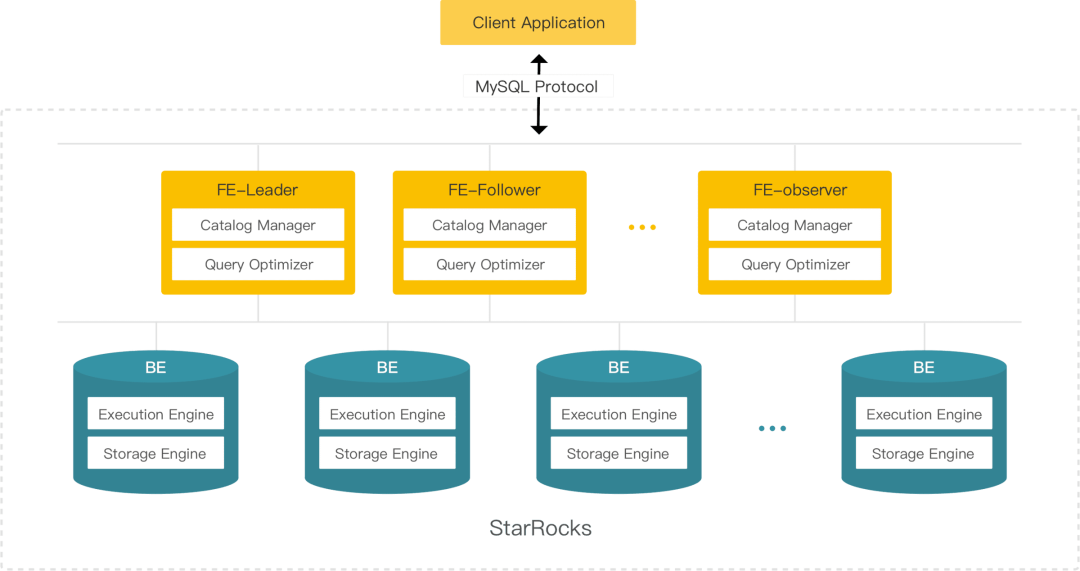
FE 的主要作用有:
-
数据表的基本元信息,如表结构 Schema、存储位置、分区信息、不同类别的统计信息等; -
数据表下的数据文件信息,如某个分区下的文件列表、大小、压缩格式等。
2. 查询规划。包括解析 SQL 文本,生成逻辑执行计划和物理执行计划,对执行计划进行优化,如分区/列裁剪,Join Reorder 等。
3. 查询调度。使用上述的外部表元数据,根据数据的分布情况分配可用的 BE 节点资源等信息,规划每个 BE 需要执行的具体计算任务,并使用算法保证数据本地性的同时,尽可能让每个 BE 节点并行地读取大致相同的数据量以提高执行效率。
BE 主要作用有:
1. 执行 FE 分配的计算任务。如 Scan、Join、Shuffle、Aggregate 等。
Hudi 的格式支持开发工作主要对 FE/BE 在外表上的对应功能来针对性实现和优化。
FE 端改造:
1. 在外部表的元信息方面,增加存储 Hudi 特有的元信息:
-
表类型,用来存储 Hudi 表类型。取值为 COW 或 MOR;
-
Input Format,用来区分 MOR 的查询类型。Hudi 的 MOR 表在写入端(如 Spark)建表时,会额外生成
_rt 和
_ro 两张表,分别对应同一张 MOR 表的 Snapshot 查询表和 Read Optimized 查询表。Snapshot 查询表的 Input Format 信息取值为 org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat,Read Optimized 查询的 Input Format 信息取值为 org.apache.hudi.hadoop.HoodieParquetInputFormat;
数据文件元信息方面,增加 Optional 的 Delta Logs 文件列表字段,用来存储 Hudi MOR 表 Base 数据文件相对应的 Logs 更新文件信息。
2. 将 Hudi 元信息采集模块集成到全新 Catalog 框架内,只需要创建一次 Hudi Catalog,后续便可以直接查询该 Catalog 下的所有 Hudi 表,不再需要以前的手工创建外部表的繁琐过程。
(https://docs.starrocks.io/zh-cn/latest/data_source/catalog/hudi_catalog)
全新 Catalog 框架结构: 
3. CBO 优化器和执行计划优化:
-
通过 Hive Metastore 读取和缓存 Hudi 分区信息,应用到分区数据裁剪优化规则里;
-
通过 Hive Metastore 读取和缓存 Hudi 表的相关统计信息,应用到 Join Reorder 等 CBO 优化规则里。
4.表结构解析完成 Hudi 表字段类型映射:
-
通过读取 Hudi 表的 Avro Schema,在各个字段上完成 Hudi Type 到 StarRocks Type 映射,具体如下:

备注:即将发布的 StarRocks 2.5.0 版本会支持 Struct、Map 数据类型的读取,Hudi COW 表也会同步支持。
5. 平衡 IO 请求优化:
StarRocks 查询传统的 Hive 表的时候,若单个数据文件的大小过大,会对这个文件进行 File Split 均匀拆分,形成多个 Scan Range。但在 Hudi 表的实现里,我们直接对 Base file 和对应 Delta Logs(即 File Slice)形成一个 Scan Range,除了有潜在的 Merge 逻辑数据问题之外,还有 IO 效率取舍,即使做了 File Split 拆分,比如拆成 3 份,其对应的 Delta Logs 就需要跟着拆分后的 File Slice 重复读取3次,这很可能会加剧存储系统的压力。在工程实现上,我们在 Scan Range 里添加了 useJNIReader 的标识字段,用来指示 BE 侧执行选择 Native Reader 还是 JNI reader,这两个 Reader 的具体用途见下文 BE 端改造部分。
6. 元数据请求优化:
通过批量以及异步的方式访问 Hive Metastore 获取 Hudi 表分区统计信息,在 FE 对其进行缓存并计算表级别统计信息用于查询优化,同时缓存 Scan 节点所要扫描的文件元数据信息来减少 Namenode 的压力并提升查询速度。用户可通过查询来触发元数据的异步加载,使得用户无需手动刷新元数据即可访问最新数据文件。 FE 和 BE 传输改造:
由于 FE 和 BE 使用 Thrift 协议传输信息,分别按照表元数据和 Scan Range 的改动,相对应添加了 Thrift 字段,确保 BE 端可以正确拿到执行计算所需要的信息。 BE 端改造:
StarRocks BE 端本身自己实现了高效的 Native Reader,用来读取不同的数据格式,如 ORC/Parquet 等。Native Reader 做了很多 IO 优化的实现,如: -
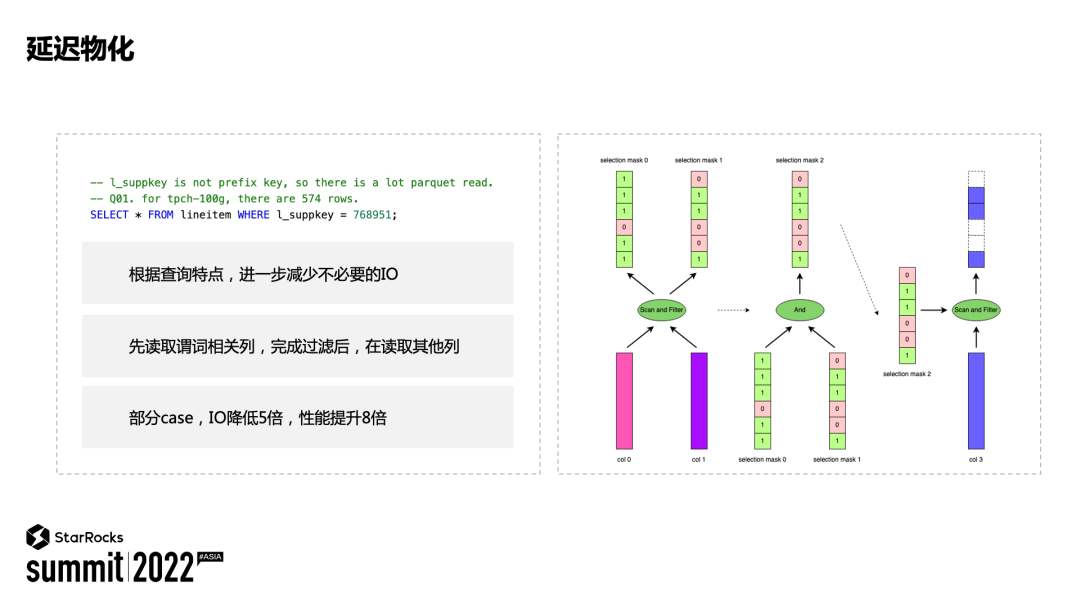
延迟物化:根据查询请求特征进行优化,先将参与谓词计算的列读出来,然后根据计算谓词的过滤结果,再将过滤结果下推读取其他列,并跳过被过滤的行,从而达到减少 IO 请求次数,提升查询性能。
-
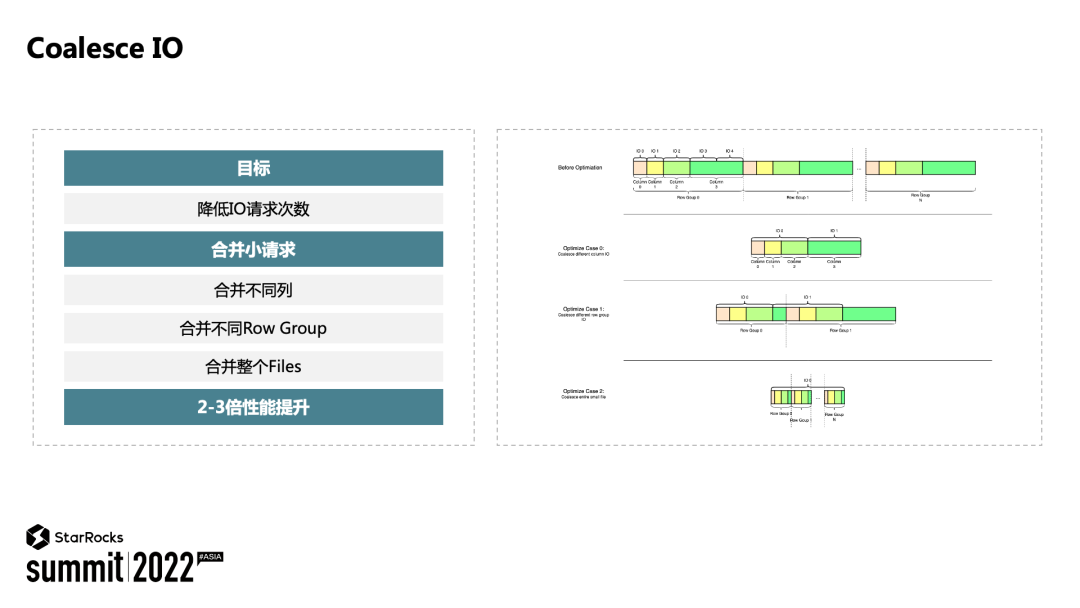
Coalesce IO:读取数据文件时,合并小的 IO 请求(如小的列,小的 Row Group),减少 IO 次数,增加每次 IO 的请求量,提升查询性能。
– BE 端 Hudi Reader 设计方案评估过程
在实现 Hudi MOR 的支持过程中,在设计阶段我们考虑了两种可行方案:
1.使用 C++ 在 BE 全新实现一套 Hudi Reader,用来读取 Avro 格式的 Delta logs 文件和 Parquet 格式的 Base 文件,然后参考 Hudi 社区 Java 版本的 merge 逻辑完成合并,最终输出结果数据。这种方案可以带来 native 执行速度快的优势,但缺点也很明显,自行维护成本太高,且不方便及时更新社区的进展。
2. 在 BE 端使用 JNI 调用 Hudi 社区的 Java SDK,直接使用社区 SDK 读取 File Slice 的结果数据,然后传给 BE 端使用。与第一种方案相比,优缺点正好相反,但代码维护工作量会大大减少。同时,我们考虑到 Java 在大数据生态的优势地位,想统一抽象一个通用的 JNI Reader,让所有基于 Java 实现的数据源 SDK,都可以通过 JNI Reader 方便地接入到 StarRocks 里来。
因此,我们最终选择了第二套基于 JNI 方案,并把实现目标从原来的仅支持 Hudi MOR 数据格式扩展到实现通用的 JNI Connector。
– JNI Connector 设计介绍
在实现过程中,我们对 JNI Connector 做了大量的优化,同时借鉴了 Spark Photon 的内存设计和实现思路,让 C++ 和 Java 使用同一块 Native Memory 共享数据,Java 端使用 JVM 的 Native 操作类 Unsafe 直接将 Hudi Java SDK 的结果数据写入 Native Memory 里,C++ 便可以直接使用这块内存进行数据计算,从而减少数据多次内存拷贝的开销。实际上,类似这样的跨语言共享内存的编程模式在阿里云 EMR 技术产品里实践落地非常广泛,如基于开源 Apache Spark 做了深度优化的 EMR Spark,对 OSS 透明加速的 Jindo 等都有类似的设计和思想。接下来,我们将展开讲讲这块的具体设计思路。
数据列存储设计
在 BE 端,所有数据列是存储在 Column 的数据结构里,不同类型的数据列对应不同的 Column 数据结构。例如:
-
存储 INT 数据列使用的数据结构是 FixedLengthColumn
-
存储 VARCHAR 类型数据列使用的数据结构是 BinaryColumnBase
这些对应关系可以参考 type_traints.h 源文件。
(https://github.com/StarRocks/starrocks/blob/main/be/src/column/type_traits.h)
实现 JNI Connector 工程上比较复杂的地方是,需要根据不同类型的数据类型安排对应的内存布局实现,且要尽量做到与 BE 端对应数据类型的内存布局相同,进而尽量减少 BE 端读取内存数据到 Column 时转化的开销。
对于 INT、LONG、DOUBLE 等定长类型的数据列,对应的 Column 数据结构是FixedLengthColumn
,其底层存储使用了 vector ,即:将数据列存储在一段连续的内存,对于这种类型,我们只需将 Java SDK 读出来的数据列按顺序依次放在 Native Memory 里即可。 对于 VARCHAR 这类变长类型的数据列,对应的 Column 数据结构是 BinaryColumnBase
,以 BinaryColumn 为例,以其底层存储使用了 vector 和 vector ,vector 即连续的字节流用来存储数据(Bytes),vector 即连续的 int 序列用来存储行索引(Offsets)。对于这种类型,我们需要将 Java SDK 读出来的数据转换成字节流放在 vector 对应的 Native Memory 里,将行号放在 vector 对应的 Native Memory 里。 vector
和 vector 读取变长数据的方法如下图所示: 
例如,获取数据列的第x行,通过 Offsets 获取该行的起始索引 start=offsets(x) 和下一行的起始索引 end=offsets(x+1),然后使用这两个索引通过 Bytes 获取具体数据对应的字节流 bytes.slice(start,end),最后按照字段类型做相应的转换即可。
注:为方便表述,上面例子做了一定的简化,对于 Nullable 数据列,实际上还有FixedLengthColumn
的数据结构,对应一段连续的 Bool 数据,用来表示对应行号的列数据取值是否为 Null,用来加速 Nullable 列的计算效率,减少数据列的存储空间。 内存分配和管理设计
由于 BE 端是通过 Memory Tracker 进行内存管理的,我们在实现 JNI Reader 时,由 Memory Tracker 统一进行内存的分配和销毁,避免直接使用 JVM Unsafe 分配 Native Memory,来保证内存统计的准确性,并防止出现错误的内存使用导致的各类问题。
编程框架设计
在编程框架上,我们完整定义了 JNI Connector 的 Java 接口,让开发者不需要进行复杂的 JNI 编程以及相关的内存管理,只需要继承 ConnectorScanner 抽象类,实现 open(), getNext(), close() 这三个抽象方法,然后在 BE 侧给出具体实现类的名称,便可以完整使用我们的 JNI Connector, 读取各类 Java 数据源的数据。
混合使用 Native Reader 和 JNI Reader 设计
在 Hudi Reader 的实现里,我们有一个优化方案。上文提到,我们在 Scan range 里添加了 useJNIReader 的字段。这个字段具体取值在 FE 端通过下面逻辑控制:
判断当前表的数据类型:如果是 MOR 表,查询类型为 Snapshot,且该 File Slice 包含一个或一个以上的 Delta log,useJNIReader 便置为 True,其他情况都为 False。
这样带来的效果是,对于同一个 MOR 表的 Snapshot 读取,BE 端实际上会同时混合使用两种不同的 Reader 去拿数据,使用 Native reader 读取不包含 Delta Logs 的 File Slice,使用 JNI Reader 读取包含 Delta Logs 的 File Slice,不同的 Reader 混合使用可以进一步提升读取效率,且这些加速对于用户都是透明无感知的。
6 使用案例 1. 创建 hudi catalog
CREATE EXTERNAL CATALOG "hudi_catalog"PROPERTIES ("type" = "hudi","hive.metastore.uris"= "thrift://xxx:9083" -- hive metastore地址);2. 执行查询
select * from hudi_catalog.. ; +------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+| id | age | _hoodie_commit_time | _hoodie_partition_path | _hoodie_record_key | _hoodie_commit_seqno | _hoodie_file_name |+------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+| 3 | 33 | 20220422111823231 | age=33 | id:3 | 20220422111823231_0_3 | 29d8d367-93f9-4bd3-aae4-47852e443e36-0_0-128-114_20220422111823231.orc |+------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+7 性能测试 测试环境:
阿里云 EMR Presto 集群,阿里云 EMR StarRocks 集群
硬件配置:
Master: ecs.g7.4xlarge 16 vCPU 64 GiB
Worker: ecs.g7.4xlarge 16 vCPU 64 GiB * 5
软件配置:
StarRocks 版本:master 分支(Hudi MOR 读取特性会在2.5.0正式发布)
StarRocks 软件配置:默认配置
Presto 版本:0.277
Presto 软件配置: query.max-memory-per-node=40GBquery.max-memory=200GBCOW 表 Snapshot 查询 TPCH-100 测试结果 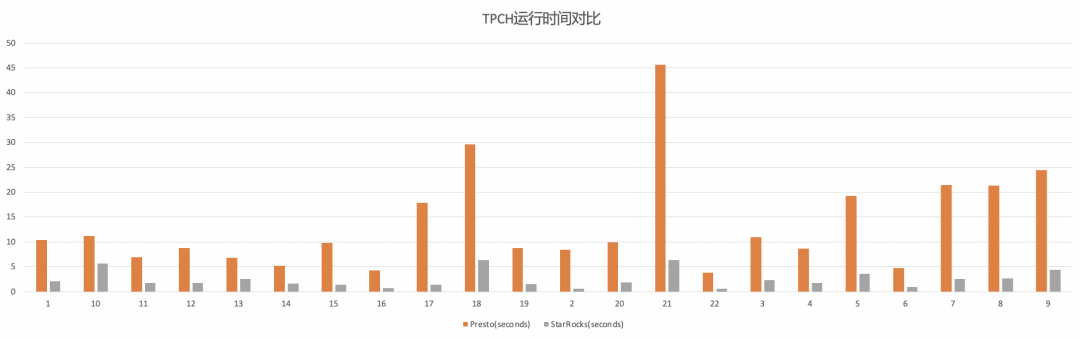
对于 COW 表 Snapshot 查询,使用 StarRocks 相对 Presto 大约会带来 5 倍的性能提升。 MOR 表 Snapshot 查询 TPCH-100 测试结果 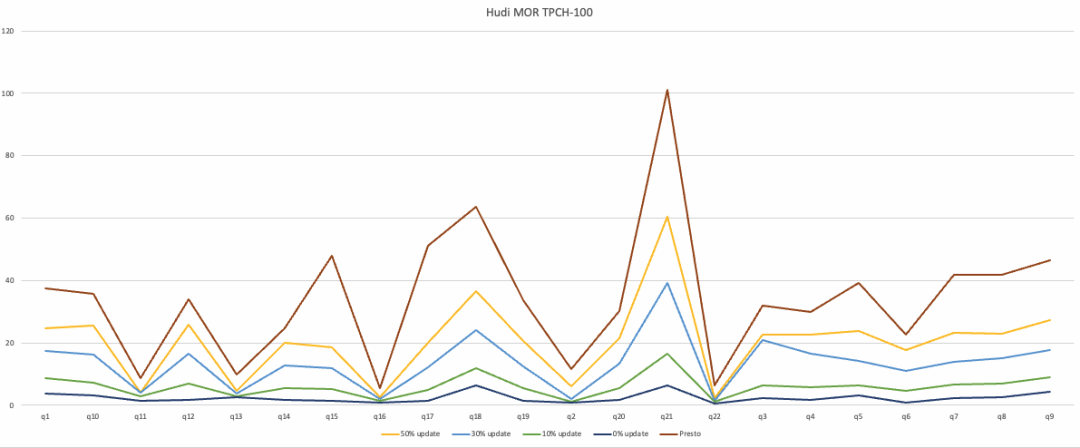
对于 MOR 表 Snapshot 查询,如上文描述,混合使用了 Native Reader 和 JNI Reader,因此,我们在 StarRocks 上测试读取不同比例更新数据(带有 Delta Logs 的 File Slice)的执行时间,来得到不同更新比例场景下的查询效率数据。从测试结果可以看出,更新数据比例越小,StarRocks 实际执行时使用 Native Reader 的比例也就越高,执行效率也越好。 根据社区的经验,最常见的库表更新场景里,在 Hudi 表做 Compaction 操作前,带有 Delta Logs 的 File Slice 占整个表的比例大约在 20% 左右,在这种条件下,使用 StarRocks 相对 Presto 大约会带来 2-3 倍的性能提升。 对于 MOR 表 Read Optimized 查询,StarRocks 内部执行原理和流程与 COW 表相同,性能提升数据也一致。 #03
未来开发方向
—
-
当前 Hudi Scan Range 没有对 Base File 的大小进行 File Split 拆分,是因为考虑了上文所述可能带来的 IO 损失和 Merge 逻辑问题,但实际上,COW 表和 Read Optimized 查询 MOR 表还是依旧可以采用 File Split 逻辑的,针对这些场景还是可以进一步提高 Scan 并发度,提升执行效率。
-
当前 JNI Connector 还不支持复杂的数据类型如 Array、Struct、Map,接下来需要针对这些类型设计对应的 Native Memory 布局,完成这些类型的支持。
-
当前 JNI Connector 在 Decimal、Date、Datetime 这三种数据类型的处理上,Java 端是写入原始 String 到内存,然后在 BE 端读取并转换成 StarRocks 内部的对应类型表示,这些内存转换过程会有一定的时间损耗,后续需要进行针对性的优化,尽可能消除这个转换过程。
-
当前 Hudi 表的部分基础元信息,如 Table location,是通过 Hive Metastore 等外部服务获取的。但在某些应用场景里,用户可能不会将 Hudi 表的元数据同步到 Hive Metastore 里,后续需要将这类 Hudi 表支持起来,在元信息获取流程上解耦外部服务,通过 Hudi Client SDK 完成相关操作。
-
进一步与 Apache Hudi 社区交流和合作,推动开发 C++ 版本的 Hudi SDK。
-
支持对 Hudi 表数据的 Incremental Query 查询类型 。
推荐阅读
Flink SQL操作Apache Hudi并同步Hive使用总结
硬核!Apache Hudi Schema演变深度分析与应用
参考资料: https://hudi.apache.org/ https://help.aliyun.com/document_detail/405463.html?spm=a2c4g.11186623.0.0.36917cc3wBuyu6
本文转载自StarRocks,原文链接:https://mp.weixin.qq.com/s/OhPPDtRH7knAq3FrY-0Avg。
赞 (0)顺丰科技数据治理实践上一篇 2022-11-14 14:09工业数据治理和数据资源化思考与实践下一篇 2022-11-16 03:37订阅评论登录0 评论