
导读:
本系列文章将结合实际开发和使用经验,聊聊可以从哪些方面对数仓查询引擎进行优化。
Impala是Cloudera开发和开源的数仓查询引擎,以性能优秀著称。除了Apache Impala开源项目,业界知名的Apache Doris和StarRocks、SelectDB项目也跟Impala有千丝万缕的联系。笔者所在的网易数帆大数据团队,是最早一批将其作为分析型数仓查询引擎的团队,目前正基于Impala打造有数高性能数仓引擎。
文章大致可以分为这几个部分:首先会对简单介绍下Impala的架构和元数据管理,以便后续内容展开;接着从执行引擎,存储优化,物化视图,数据缓存和虚拟数仓等维度进行探讨。本文为执行引擎篇。
Impala简介
Impala集群包含一个Catalog Server (Catalogd)、一个Statestore Server (Statestored) 和若干个Impala Daemon (Impalad)。Catalogd主要负责元数据的获取和DDL的执行,Statestored主要负责消息/元数据的广播,Impalad主要负责查询的接收和执行。
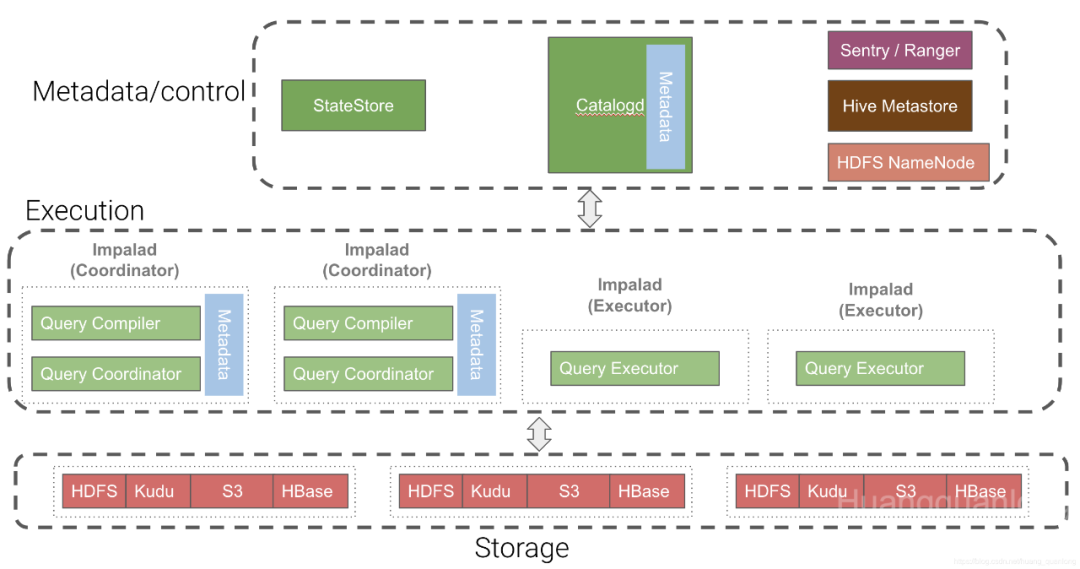

Impalad又可配置为coordinator only、 executor only 或coordinator and executor(默认)三种模式。Coordinator角色的Impalad负责查询的接收、计划生成、查询的调度等,Executor角色的Impalad负责数据的读取和计算。默认配置下每个Impalad既是Coordinator又是Executor。生产环境建议做好角色分离,即每个Impalad要么是Coordinator要么是Executor。
1.1 元数据管理
Impala的元数据缓存在catalogd和各个Coordinator角色的Impalad中。Catalogd中的缓存是最新的,各个Coordinator都缓存的是Catalogd内元数据的一个复本。元数据由Catalogd向外部系统获取,并通过Statestored 传播给各个Coordinator。
以Hive表为例,Catalogd中的元数据分别从Hive Metastore(HMS)和HDFS NameNode(NN)获取。从HMS获取的信息包括元数据信息和统计信息两部分,元数据信息指有哪些库和表,表定义,列类型等,对应“show databases,show tables,show create table xxx,show ”等操作。统计信息包括表的大小,行数,分区和各列的信息等,对应“show table stats xx,show column stats xx”等操作。从NN获取的是文件粒度的信息,包括文件存储位置,副本和文件块信息等。
1.2 管理服务器
管理服务器是有数高性能数仓增加的Impala模块,提供集群粒度的SQL查看界面,持久化保存历史查询信息并展示,SQL审计,查询错误和查询性能分析,自动进行统计信息计算等。

执行引擎(Execute Engine)
2.1 执行模型
在执行模型这块,目前主要有动态代码生成(code generation或just in time/JIT)和向量化计算两个流派,Impala主要是基于JIT进行性能优化,对于向量化引擎,Impala社区版目前并没有相关规划,有数高性能数仓团队也有计划对其进行向量化改造。
在具体实现上,Impala属于改进版的火山模型,官方论文描述为
The execution model is the traditional Volcano‑style with Exchange operators. Processing is performed batch‑at‑a‑time: each GetNext() call operates over batches of rows, similar to
即在传统的火山模型的基础上加入Exchange操作符,用于进行不同执行节点的数据交换。每次会获取一批记录而不是一条记录。
不管是JIT还是矢量化,其目的都是尽可能地减少执行引擎核心代码流程的调用次数并提高函数执行效率,这对于需要处理海量记录时非常重要。Impala通过每次获取一批记录来减少调用次数,再利用JIT技术来生成针对特定类型数据的执行流程函数,提高每次调用的效率。
更进一步,Impala采用数据流水线(streaming pipelined)执行机制,充分利用计算资源进行并发执行。在Impala 4.0版本,完整支持了executor节点的多线程执行模型,进一步提高并发能力,压榨计算资源。
动态代码生成原理及优化
JIT技术与静态编译技术相反,其是在具体的查询运行之前才进行代码编译,此时,查询中需要处理的列类型,用到的算子和函数都已经确定,可以为该查询生成特定版本的处理函数。如下图所示:

左侧是通用的从文件读取记录(tuple)并解析的行数,外层一个for循环用于对每一列进行处理,内层的switch用于判断列的类型并调用特定的解析函数。如果我们已经知道该记录由三列组成,类型分别为int,bool和int,那么JIT技术就可以生成如图右侧的函数版本,不需要for循环,也不需要switch判断,显然,执行效率更高。
总的来说,Impala使用LLVM来进行JIT优化,生成对于某个具体查询最优的函数实现。其优化项具体包括移除条件分支(Removing conditionals,如上所示)、移除内存加载和内联虚函数调用等。
启用动态代码生成时,在查询执行前需要先动态生成其执行代码,因此有一定的时间消耗,对于小查询,动态代码生成可能是有害的,生成代码的时间都有可能超过SQL执行时间。Impala提供了DISABLE_CODEGEN_ROWS_THRESHOLD参数,默认为50000,如果SQL需要处理的记录数小于该值,则不会使用动态代码生成进行执行优化。Impala 4.0版本对JIT进行了进一步优化,采用异步化改造来避免生成JIT代码对查询性能的影响,当编译未完成时使用原函数,完成后无缝切换成优化后的函数代码。
2.2 计算资源
Impala属于SQL on Hadoop的一种,基于MPP(Massively Parallel Processing,即大规模并行处理)架构,正常情况下,查询涉及的各种操作均在内存中完成的,因此,可用内存的多少及对其的利用效率,对Impala查询性能有极大影响。同样地,作为一个OLAP查询引擎,可用的CPU资源对查询性能也至关重要。Impala虽提供了少数CPU相关配置项,如num_threads_per_core 等,但对CPU使用的控制能力较差。本小节后续仅介绍内存资源相关,CPU计算后续另开一篇单独介绍。
Impala资源池
Impala有比较丰富的资源使用限制方式,称为准入控制。其中资源池(resource pool)是Impala进行并发控制的主要手段,可以决定某个查询是否会被拒绝,或执行,或排队。其主要有两种控制方式,一种是手动设置最大并发数控制,超过阈值的请求会进行排队,可以设置允许排队的最大请求数和排队时长,超过阈值的请求直接返回失败;另一种是基于内存的并发控制,下面进行重点介绍。
基于内存的并发控制
Impala集群支持通过fair-scheduler.xml设置多个资源池并规定其最大可用内存(maxResources),再通过llama-site.xml为每个资源池设置请求级别的内存限制,包括内存分配上下限max-query-mem-limit和min-query-mem-limit,及clamp-mem-limit-query-option。除了通过资源池相关配置控制请求的内存使用,还可以通过MEM_LIMIT请求选项设置内存限制。而clamp-mem-limit-query-option就是设置是否允许MEM_LIMIT设置的内存突破资源池内存配置的限制。
需要注意的是,max-query-mem-limit,min-query-mem-limit和MEM_LIMIT设置的是请求在每个executor节点允许申请的最大内存,请求申请的总内存还需要乘上执行该请求的executor节点个数。
若Impala通过预估发现查询所需的内存资源超过集群总内存资源,该查询会被拒绝;若总资源满足,但由于部分资源已被其他查询占用,则会将其放入请求队列,待可用资源满足查询要求时再按查询提交的先后顺序调度执行。
若预估的内存资源超过了设置的max-query-mem-limit,则以max-query-mem-limit为准,若小于min-query-mem-limit,则以min-query-mem-limit为准。假设查询请求设置了MEM_LIMIT,需先判断clamp-mem-limit-query-option的值,若为true,则仍然受max-query-mem-limit,min-query-mem-limit约束。下面举个例子进行说明:
假设一个Impala集群有5个executor节点,集群配置了一个最大可用内存为100GB的资源池。查询请求的内存上下限为10GB和2GB,若clamp-mem-limit-query-option为true,Impala为某个查询请求A预估的内存为14GB(或设置了MEM_LIMIT为14GB),则查询A在每个executor最多只能分配10GB内存。若clamp-mem-limit-query-option为false,查询A最多可分配14GB内存。
假设clamp-mem-limit-query-option为true,则该资源池最多只能同时执行2个查询A这样的请求(2 * 5 * 10GB)。
通过上面的例子可知Impala的准入控制会在每个executor为查询请求预留所需的内存,因此,所预留的内存应该尽可能接近实际所需内存,预留过少会导致查询失败或中间结果溢出,预留过多会导致集群资源没有被充分利用。在内存资源管理的精确性方面,Impala还有较多需优化的点。
准入控制存在的问题
(1)集群同步
Impala进行准入控制的载体是coordinator节点,由于一个集群至少有2个及以上的coordinator节点,但准入控制是针对整个集群的。Impala通过statestore的impala-request-queue topic机制在coordinator间周期性地同步每个coordinator上的查询并发和内存使用情况。
Impala采用去中心化的设计来实现准入控制,而不是通过一个中心节点来统一决策,虽然在性能和可用性上有优势,但是这会导致coordinator获取的其他coordinator信息过旧的问题,尤其是在查询并发度较高时,会导致准入控制模块做出错误的决策。
(2)内存预估精度
Impala需要基于统计信息来评估查询需要消耗多少内存,因为统计信息里面会记录表的记录数,列的类型和大小等。没有统计信息,就无法正确评估内存消耗,也就无法以较优的方式执行该查询。(统计信息相关的详细描述见下一小节)
但就算是有统计信息,仍有可能依然没法正确估算需消耗的内存量。如下所示:
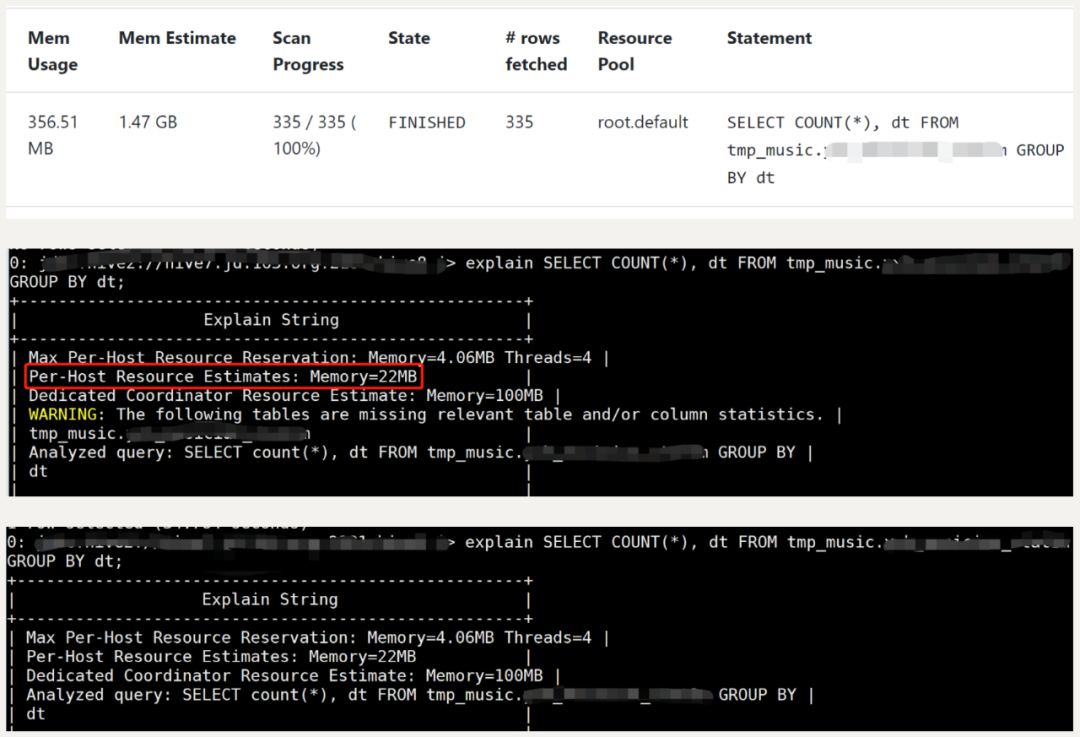
上图第一张的”Mem Usage”和”Mem Estimate”分别表示查询实际消耗和预估消耗的总内存,可见明显差别。上图下面两张为通过compute incremental stats/compute stats前后通过explain看到的内存预估情况,可见每个节点均22MB(共67个executor节点),即该查询内存预估不精确不是因为没有统计信息导致的。
数据溢出(spill to disk)
内存不够怎么办?
如果因为集群同步延迟或内存预估低于实际所需内存,导致查询执行过程中消耗的内存超过准入控制的计算值,此时数据溢出功能可以派上用场。数据溢出是Impala一种兜底机制,避免因中间结果集过大导致内存不足,进而引起查询失败。当然,并不是所有情况的内存不足都会启用数据溢出,能够进行数据溢出的算子主要包括group by,order by,join,distinct和union;
数据溢出机制的用处在于,能够最大限度避免查询失败。OLAP场景由于SQL复杂度远高于OLTP,耗时也明显更长,查询失败的代价更大。其带来的问题是因为需要将中间结果写盘并读取,SQL查询性能会明显下降,因此,应该通过查询优化尽可能避免数据溢出。
关闭数据溢出
有两种方法可以关闭数据溢出,均是通过query option来设置,分别是SCRATCH_LIMIT和DISABLE_UNSAFE_SPILLS。
SCRATCH_LIMIT用于设置溢出目录的大小,当设为0时,即关闭了数据溢出特性。
DISABLE_UNSAFE_SPILLS更加智能,用于禁止不安全的数据溢出。Impala认为下列情况属于不安全的溢出:查询中存在没有统计信息的表,或没有为join设置hint,或对分区表进行insert … select操作。
优化资源分配效率
(1)集中式准入控制
从Impala社区了解到,目前Impala在开发新的准入控制实现,预计后续会提供集中式的准入控制方案,详见 Single Admission Controller per Cluster;
(2)降低准入信息同步延时
虽可以通过statestore_update_frequency_ms缩短topic更新周期来缓解,但无法从根本上解决。除此之外,在Impala部署时,还应该控制coordinator的数量,对于50个节点以下的集群,一般情况下配置2个coordinator实现高可用即可;
(3)丰富统计信息类型
至于为什么在有统计信息情况下预估还是不够精确,原因也很好理解,即统计信息本身过于粗粒度,缺乏像直方图这样细粒度的数据统计。
基于历史查询的内存估算优化(HBO)
从前述的例子可知,有数的Impala版本通过管理服务器保存了Impala执行过的历史查询信息,其中就包括了查询的实际内存使用量。在BI场景,报表SQL会重复执行,往往一天一次或数次,完全可以将该SQL第一次执行的内存使用量作为后面几次的内存预估值。进一步,可以提取同类SQL查询模板,计算该模板下SQL的最大及平均内存使用量作为内存预估值。
此外,由于BI报表的SQL都来源于事先创建的数据模型,可以预先计算数据模型SQL的内存消耗,在执行该模型对应的报表SQL时,模型部分的内存消耗无需再次计算,直接代入即可。基于此,我们完成了方案设计和功能实现,下图为一个查询开启HBO优化前后的内存估算值变化
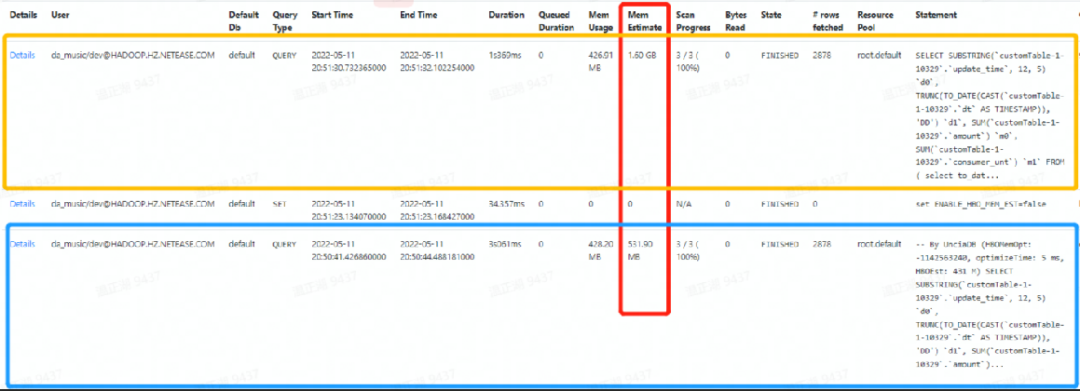
下图为将HBO用在某业务集群上启用前后的效果对比。


2.3 基于代价优化(CBO)
CBO与RBO(基于规则优化)都是传统的执行计划优化方式。CBO主要基于索引和统计信息等元数据来选择更优的执行计划。传统的商业数仓和OLTP系统有健全的索引系统,并且会自动计算表的统计信息。因此,CBO往往能够较充分发挥。但目前开源的分析型数仓查询引擎(下称OLAP),做得并不好,以Impala为例,自身并没有索引系统,主要依赖底层的存储系统,虽提供了统计信息计算的命令,但不会自动进行统计信息计算。在此,我们先介绍其对统计信息的使用。
统计信息的用途
在Impala中,统计信息主要用于准入控制和确定Join方式等场景。
确定Join方式包括Join的先后顺序和Join的方法,Join方式有shuffle和broadcast两种。如下文描述:
Impala does not consider all possible join orderings, focusing instead on the subset of left deep join plans. This usually means joins are arranged in a long chain where the left input is preferred to be larger than the right input.
三个及以上的表进行Join时,一般选择将结果集最小的Join先算掉,对于两表Join,若是大表和小表,由于Impala使用Hash Join,采用大表左(probe table),小表在右(build table)的方式,将小表broadcast到大表分片所在的各个executor节点,若是大表跟大表,则采用shuffle的方式,两表都会进行Hash分片,各个executor节点对两表相同Hash值的分片进行Join。
如果SQL中的表缺失了统计信息,如查询所涉及的记录数,所涉及的各列的大小等,则无法准确预估该SQL的内存消耗,导致准入控制模块出现误判,生产环境中常会出现因executor节点可用内存不足导致查询排队的情况,但其实此时内存是够的,这里有多方面的原因,比如该查询SQL所需内存预估值过大,或已经在执行的查询的配额过大等。相反的,如果预估所需内存过小,则可能导致查询在执行过程中因为executor节点无法分配所需内存而导致SQL执行失败。
同样的,如果没有统计信息,也就无法判断两表参与Join的记录数和大小,出现大小表Join时大表被广播的情况。在Impala中,两表Join,没有统计信息的表会被放在右边,所以,对大表做统计信息计算显得更加重要。
除此之外,统计信息用于调优前文提到的动态代码生成。上文提到的DISABLE_CODEGEN_ROWS_THRESHOLD参数需要在有统计信息的情况下使用,无统计信息,意味着不知道需要处理多少条记录,该参数也就无法生效。
统计信息计算
Impala为什么不像MySQL等数据库一样自动计算和更新表统计信息呢?个人认为,主要是不好做,MySQL自动进行统计信息更新的方式是监测表中的记录,如果更新的记录数超过设定的阈值,则自动触发更新。当Impala对接Hive表时,往往仅用于查询而不是数据产出,数据产出由Spark或Hive负责,因此也就无法自动感知表中数据的变化。
如果能够及时感知Hive表的数据变化情况,那么就有办法驱动统计信息更新。Impala可以通过订阅有数大数据开发及管理平台的数据产出日志,感知Hive表的数据变化。具体的统计信息计算由Impala管理服务器执行。Impala 3.4版本下,表和列的统计信息字段如下所示。
[localhost:21000] > show table stats t1;Query: show table stats t1+-------+--------+------+--------+| #Rows | #Files | Size | Format |+-------+--------+------+--------+| -1 | 1 | 33B | TEXT |+-------+--------+------+--------+Returned 1 row(s) in 0.02s[localhost:21000] > show column stats t1;Query: show column stats t1+--------+--------+------------------+--------+----------+----------+| Column | Type | #Distinct Values | #Nulls | Max Size | Avg Size |+--------+--------+------------------+--------+----------+----------+| id | INT | -1 | -1 | 4 | 4 || s | STRING | -1 | -1 | -1 | -1 |+--------+--------+------------------+--------+----------+----------+Returned 2 row(s) in 1.71s
进行统计信息计算的“compute stats”命令本质是通过两条SQL分别获取表/分区和列粒度的信息:即为上述两个查询结果中的为“-1”的字段进行赋值,如下所示:
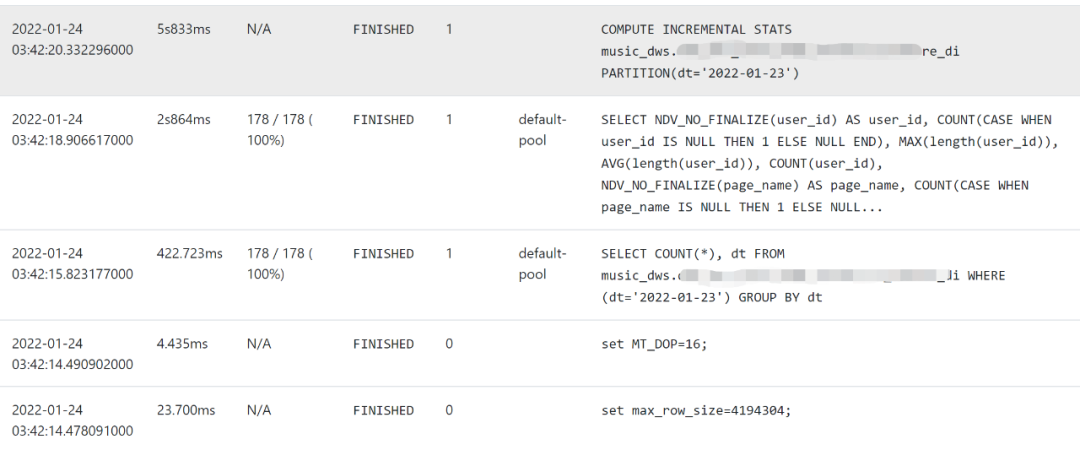
两个SQL均需在全表扫描的基础上进行聚合操作。对于大表,这需要消耗可观的计算资源,而且,若表中的列个数非常多,则统计信息的存储空间也是需要考虑的因素(需要持久化到HMS元数据库中,并缓存在catalogd和impalad)。对于分区表,一般使用“compute incremental stats”每次仅计算一个分区,但有时仍会因为统计信息过大而出错,这是由于超过了增量统计信息计算的“inc_stats_size_limit_bytes”参数设定值导致:
org.apache.impala.common.AnalysisException: Incremental stats size estimate exceeds 200.00MB.参考Impala的文档,统计信息计算可以进行如下优化:
-
对于分区表,仅对频繁查询的分区计算统计信息,并定期删除旧分区统计信息;
-
对于宽表,仅对频繁查询的列计算统计信息;
-
对于记录数过多的表,启用统计信息高级特性:推断和采样(Extrapolation and Sampling)
从性能优化角度,统计信息显然是越精细越好。但在OLAP这种大数据量场景下,越精细意味着越庞大的统计信息计算和存储开销,使用何种粒度的统计信息是个需要权衡的问题。
2.4 查询的分布式执行
在大数据场景下,单靠单台服务器执行分析型查询操作显然过于单薄,所以分析型数仓一般基于MPP(Massively Parallel Processing,即大规模并行处理)架构,Impala就是基于MPP,可以将一个查询分为多个片段分布式执行。在Impala上,分布式执行又可分为节点间和节点内。
为了能够在分布式执行的同时,能够对不同业务或不同类型的SQL进行隔离,避免相互影响,有数的Impala版本进一步引入了虚拟数仓概念,能够有效的进行资源隔离,同时有兼顾资源的有效利用。对于虚拟数仓,我们会在后续单独写一篇文章进行介绍。
节点间并行
在“Impala简介”小节提到,Impala有多个executor节点,在确定执行计划时,Impala会充分考虑并发执行该查询,尽可能将需要扫描的数据分成range分发到各executor节点上执行,并响应对数据进行查询所需的算子进行分布式计算。
因此,在数据量足够大的情况下,增加executor节点数可以提升查询性能。若executor所在服务器的计算资源充足,可以考虑同一台服务器上部署多个executor节点。
节点内并行
Impala还可以通过MT_DOP参数配置查询在executor节点内的执行并发线程数。对于统计信息计算产生的SQL,Impala自动将MT_DOP设置为4以提升计算性能。相比节点间并行,节点内并行通过query option设置,更加灵活可控。在Impala 3.4及之前版本,MT_DOP不够完善,无法支持分布式Join等操作,从Impala 4.0开始,MT_DOP已支持绝大部分算子。我们在TPCH和TPCDS场景下的测试数据表明,将MT_DOP设置为16的性能明显好于不设置或将其设置为1时的性能,绝对性能有数倍提升。
合理配置并行数
显然,查询的执行并行度不是越高越好,需要考虑Impala集群的查询并发数以及executor节点的计算资源可用量。一般建议executor节点所在服务器的计算资源和网络资源的利用率应该小于80%。
对于节点内并行,需要考虑impala profile输出对性能的影响,在配置高MT_DOP时,应启用精简模式的profile-v2(gen_experimental_profile=true),防止profile过大。
2.5 查询重试和改写
查询重试
查询出错的原因有很多,比如执行该查询的任意一个executor不可用(宕机或网络隔离等),或因排队过久导致执行超时,或因元数据过旧导致执行出错等。
在Impala 4.0版本,引入了查询透明重试的特性,该特性会判断引起查询出错的原因,目前支持对因executor不可用而出错的查询进行自动重试,无需用户/客户端参与。
元数据过旧重试
因元数据过旧导致执行出错是Impala特有的错误场景,最典型的错误形如:“Failed to open HDFS file …..”。有数的Impala版本还支持对该类错误进行透明重试,coordinator节点通过匹配错误关键字识别错误类型。在重试前会解析HDFS文件路径获取库名和表名,并获取当前该表的元数据版本,重试时若元数据版本未变化,这会将对应的表元数据失效掉,重新加载元数据。
对元数据错误进行查询重试,是一种把错误内部化的一种优化方式。元数据过旧是由于Impala出于性能考虑对其进行了缓存,对用户来说元数据缓存应该是黑盒的,因缓存过旧导致的错误,不应该直接暴露给使用者,应该在系统设计时消化掉。
SQL改写
常规改写
Impala提供了表达式级别的改写优化,改写规则主要包括常量折叠、通用表达式提取和,全部规则如下所示:
Listrules = new ArrayList(); // BetweenPredicates must be rewritten to be executable. Other non-essential// expr rewrites can be disabled via a query option. When rewrites are enabled// BetweenPredicates should be rewritten first to help trigger other rules.rules.add(BetweenToCompoundRule.INSTANCE);//between转大小比较// Binary predicates must be rewritten to a canonical form for both Kudu predicate// pushdown and Parquet row group pruning based on min/max statistics.rules.add(NormalizeBinaryPredicatesRule.INSTANCE);//规范化二元谓语,如“5 + 3 = id"改为"id = 5 + 3"if (queryCtx.getClient_request().getQuery_options().enable_expr_rewrites) {rules.add(FoldConstantsRule.INSTANCE);//常量折叠,如"1 + 1"改为"2"rules.add(NormalizeExprsRule.INSTANCE);//规范化表达式,如"id = 0 OR false"改为"FALSE OR id = 0"rules.add(ExtractCommonConjunctRule.INSTANCE);//通用表达式提取,如"(int_col// Relies on FoldConstantsRule and NormalizeExprsRule.rules.add(SimplifyConditionalsRule.INSTANCE);//简化条件判断,场景覆盖较广,包括if、case等等,如"if(true, id, id+1)"改为"id"rules.add(EqualityDisjunctsToInRule.INSTANCE);//or转in,如"int_col = 1 or int_col = 2"改为"int_col IN (1, 2)"rules.add(NormalizeCountStarRule.INSTANCE);//count(常量)转为count(*),如"count(1)"改为"count(*)"rules.add(SimplifyDistinctFromRule.INSTANCE);//简化条件判断(is distinct, , 等)语句,如"if(bool_col bool_col, 1, 2)"改为"1"rules.add(SimplifyCastStringToTimestamp.INSTANCE);//简化将字符串转为时间戳,如"cast(unix_timestamp(date_string_col) as timestamp)"改为"CAST(date_string_col AS TIMESTAMP)"}exprRewriter_ = new ExprRewriter(rules);}
从上面的代码可知,大部分的改写规则需要通过ENABLE_EXPR_REWRITES 这个query option开启。
定制改写
有数的Impala版本在上述基础上,结合BI工具和业务属性进行针对性的优化,有助于提升BI查询性能。其中一项优化是简化时间比较表达式。举例如下:
SELECT TO_DATE(CAST(t1.dtAS TIMESTAMP))d0,t2.itemnamed1,COUNT(DISTINCTt1.user_id)m0FROMmusic_dws.dws_log_music_xxx_aggr_dit1WHERE (((TO_DATE(CAST(t1.dtAS TIMESTAMP)) >= CAST('2021-01-01' AS TIMESTAMP)) AND (TO_DATE(CAST(t1.dtAS TIMESTAMP))
已知t1表为按天分区,dt为分区字段,结构为’yyyy-mm-dd’,那么在此条件下,可以将dt字段与时间字符串进行比较,去掉CAST AS TIMESTAMP和TO_DATE操作,上述SQL可改写为:
SELECTt1.dtd0,t2.itemnamed1,COUNT(DISTINCTt1.user_id)m0FROMmusic_dws.dws_log_music_xxx_aggr_dit1WHERE (t1.dt>= '2021-01-01') AND (t1.dt
高级改写
从上面Impala原生支持的改写规则可以看出,其支持的改写规则都比较初级,实现上是将SQL拆解为SelectList、FromClause、WhereClause、GroupByExpr和OrderByExpr等片段后,对各片段进行改写。并没有对SQL进行整体的,跨片段的改写。
有数的Impala版本还可进一步对SQL整体进行改写优化,其中最为重要的是基于物化视图的SQL透明改写,我们会在后续单独写一篇文章进行介绍。除了物化视图改写,还有其他一些优化手段,如左连接(left join)消除等。
左连接消除
一般来说,BI软件基于某个数仓模型(宽表,星型,雪花型等)创建报告,其中包括一张或多张报表,举一个网易云音乐使用有数BI报表模型为例,SQL形如:
SELECTt1.os, other select listFROMmusic_impala.left_join_table1t1LEFT JOINmusic_impala.left_join_table2t2ON ((t1.is_new=t2.is_new) AND (t1.anchor_id=t2.anchor_id) AND (t1.app_ver=t2.app_ver) AND (t1.os=t2.os) AND (TO_DATE(CAST(t1.dtAS TIMESTAMP)) =t2.report_date))LEFT JOINmusic_impala.left_join_table3t3ON ((t1.is_new=t3.is_new) AND (t1.anchor_id=t3.anchor_id) AND (t1.app_ver=t3.app_ver) AND (t1.os=t3.os) AND (TO_DATE(CAST(t1.dtAS TIMESTAMP)) =t3.report_date))LEFT JOINmusic_iplay.left_join_table4t4ON ((t1.dt=t4.dt) AND (t1.anchor_id= CAST(t4.anchor_idAS VARCHAR(255))))
可以认为,该模型是将下面这4个数仓表通过左连接打宽成一个逻辑大宽表。
music_impala.left_join_table1、music_impala.left_join_table2、music_impala.left_join_table3music_impala.left_join_table4`
下面是产生的一个报表的列表筛选器组件产生的SQL。
SELECTt1.osd0FROMmusic_impala.left_join_table1t1LEFT JOINmusic_impala.left_join_table2t2ON ((t1.is_new=t2.is_new) AND (t1.anchor_id=t2.anchor_id) AND (t1.app_ver=t2.app_ver) AND (t1.os=t2.os) AND (TO_DATE(CAST(t1.dtAS TIMESTAMP)) =t2.report_date))LEFT JOINmusic_impala.left_join_table3t3ON ((t1.is_new=t3.is_new) AND (t1.anchor_id=t3.anchor_id) AND (t1.app_ver=t3.app_ver) AND (t1.os=t3.os) AND (TO_DATE(CAST(t1.dtAS TIMESTAMP)) =t3.report_date))LEFT JOINmusic_iplay.left_join_table4t4ON ((t1.dt=t4.dt) AND (t1.anchor_id= CAST(t4.anchor_idAS VARCHAR(255))))GROUP BYt1.osLIMIT 20000
对于BI软件来说,基于模型产生该SQL非常合理。但考虑到模型是逻辑的大宽表,在Impala层面,可以对SQL进行改写以优化查询性能。
该筛选器用于在报告中对music_impala.left_join_table1的os字段进行选择,且模型中各表Join的条件(ON和WHERE)均没有对os字段进行过滤性操作。在这种情况下,如果在select list中没有对os字段进一步做SUM/AVG/COUNT等聚合操作(可以是MIN/MAX/DISTINCT等聚合操作),那么可以去掉left join算子,改写成如下形式:
SELECTt1.osd0FROMmusic_impala.left_join_table1t1GROUP BYt1.osLIMIT 20000
小结
本文简单说明了Impala的系统架构和元数据管理,介绍了我们内部版本引入的集中式管理服务器。重点介绍了在分析型数仓技术中执行引擎这块的主要技术点和常见优化方法,并结合Impala展开进行了分析,包括动态代码生成、基于准入控制的资源管理、基于统计信息的代价计算、查询并行执行、SQL优化和错误重试等。
下一篇我们会重点分析由云原生数仓Snowflake引入的虚拟数仓特性。
荣廷,网易杭研数据库开发专家。10年数据库和存储开发经验,2013年起一直从事数据库内核和数据库云服务相关工作,现为杭研数据库内核团队负责人;专注于数据库内核技术和分布式系统架构,乐于挑战和解决疑难问题;负责网易MySQL分支InnoSQL的开发和优化工作,大幅提升了线上业务的MySQL数据库服务质量;主导并推动MGR、MyRocks等新方案在考拉海购、云音乐、传媒等业务场景大规模使用;累计申请10+技术发明专利(已授权8个),《MySQL 内核:InnoDB 存储引擎 卷1》作者之一。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/7227/