
动态表是Flink Table和SQL API处理有界和无界数据的核心概念。
在Flink中,动态表只是逻辑概念,其本身并不存储数据,而是将表的具体数据存储在外部系统(比如说数据库、键值对存储系统、消息队列)或者文件中。
动态源和动态写可以从外部系统读写数据。在下面的描述中,动态源和动态写可以归结为connector。接下来我们来看看如何自定义connector。
代码地址:https://git.lrting.top/xiaozhch5/flink-table-sql-connectors.git
总览
在许多情况下,实现者不需要从头开始创建新的连接器,而是希望稍微修改现有的连接器或挂钩到现有的堆栈。 而在其他情况下,实施者也会希望创建专门的连接器。
本节对这两种用例都有帮助。 它解释了从 API 中的纯声明到将在集群上执行的运行时代码的表连接器的一般架构。
实心箭头显示了在转换过程中对象如何从一个阶段到下一个阶段转换为其他对象。

Metadata
Table API 和 SQL 都是声明式 API。 这包括表的声明。 因此,执行 CREATE TABLE 语句会导致目标目录中的元数据更新。
对于大多数catalog实现,外部系统中的物理数据不会针对此类操作进行修改。 特定于连接器的依赖项不必存在于类路径中。 WITH 子句中声明的选项既不被验证也不被解释。
动态表的元数据(通过 DDL 创建或由catalog提供)表示为 CatalogTable 的实例。 必要时,表名将在内部解析为 CatalogTable。
Planning
在规划和优化表程序时,需要将 CatalogTable 解析为 DynamicTableSource(用于在 SELECT 查询中读取)和 DynamicTableSink(用于在 INSERT INTO 语句中写入)。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供特定于连接器的逻辑,用于将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。 在大多数情况下,工厂的目的是验证选项(例如示例中的“端口”=“5022”),配置编码/解码格式(如果需要),并创建表连接器的参数化实例。
默认情况下,DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java 的服务提供者接口 (SPI) 发现的。 连接器选项(例如示例中的 ‘connector’ = ‘custom’)必须对应于有效的工厂标识符。
尽管在类命名中可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态的工厂,它们最终会产生具体的运行时实现来读取/写入实际数据。
规划器使用源和接收器实例来执行特定于连接器的双向通信,直到找到最佳逻辑规划。 根据可选声明的能力接口(例如 SupportsProjectionPushDown 或 SupportsOverwrite),规划器可能会将更改应用于实例,从而改变生成的运行时实现。
Runtime
一旦逻辑规划完成,规划器将从表连接器获取运行时实现。 Runtime 逻辑在 Flink 的核心连接器接口中实现,例如 InputFormat 或 SourceFunction。
这些接口按另一个抽象级别分组为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider(提供 org.apache.flink.api.common.io.OutputFormat)和 SinkFunctionProvider(提供 org.apache.flink.streaming.api.functions.sink.SinkFunction)都是 SinkRuntimeProvider 的具体实例,规划器可以 处理。
完全自定义connectors

本节我们从头定义一个socket connector。
Runtime定义数据源
SocketSourceFunction 打开一个套接字并消耗字节。 它通过给定的字节分隔符(默认为 \n)拆分记录,并将解码委托给可插入的 DeserializationSchema。 源函数只能在并行度为 1 的情况下工作。
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.data.RowData;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.InetSocketAddress;
import java.net.Socket;
public class SocketSourceFunction extends RichSourceFunction<RowData> implements ResultTypeQueryable<RowData> {
private final String hostname;
private final int port;
private final byte byteDelimiter;
private final DeserializationSchema<RowData> deserializer;
private volatile boolean isRunning = true;
private Socket currentSocket;
public SocketSourceFunction(String hostname, int port, byte byteDelimiter, DeserializationSchema<RowData> deserializer) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
this.deserializer = deserializer;
}
@Override
public TypeInformation<RowData> getProducedType() {
return deserializer.getProducedType();
}
@Override
public void run(SourceContext<RowData> sourceContext) throws Exception {
while (isRunning) {
// open and consume from socket
try (final Socket socket = new Socket()) {
currentSocket = socket;
socket.connect(new InetSocketAddress(hostname, port), 0);
try (InputStream stream = socket.getInputStream()) {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
int b;
while ((b = stream.read()) >= 0) {
// buffer until delimiter
if (b != byteDelimiter) {
buffer.write(b);
}
// decode and emit record
else {
sourceContext.collect(deserializer.deserialize(buffer.toByteArray()));
buffer.reset();
}
}
}
} catch (Throwable t) {
t.printStackTrace(); // print and continue
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
try {
currentSocket.close();
} catch (Throwable t) {
// ignore
}
}
}
Table Source and Decoding Format
接下来我们定义动态表数据源
本节说明如何从计划层的实例转换为交付到集群的运行时实例。
SocketDynamicTableSource
SocketDynamicTableSource 在规划期间使用。 在我们的示例中,我们没有实现任何可用的能力接口。 因此,主要逻辑可以在 getScanRuntimeProvider(…) 中找到,我们在其中实例化所需的 SourceFunction 及其 DeserializationSchema 以供运行时使用。 两个实例都被参数化以返回内部数据结构(即 RowData)。
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.connector.source.ScanTableSource;
import org.apache.flink.table.connector.source.SourceFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.RowKind;
public class SocketDynamicTableSource implements ScanTableSource {
private final String hostname;
private final int port;
private final byte byteDelimiter;
private final DecodingFormat<DeserializationSchema<RowData>> decodingFormat;
private final DataType producedDataType;
public SocketDynamicTableSource(String hostname,
int port,
byte byteDelimiter,
DecodingFormat<DeserializationSchema<RowData>> decodingFormat,
DataType producedDataType) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
this.decodingFormat = decodingFormat;
this.producedDataType = producedDataType;
}
@Override
public ChangelogMode getChangelogMode() {
// define that this format can produce INSERT and DELETE rows
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.build();
}
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext scanContext) {
// create runtime classes that are shipped to the cluster
final DeserializationSchema<RowData> deserializer = decodingFormat.createRuntimeDecoder(
scanContext,
producedDataType);
final SourceFunction<RowData> sourceFunction = new SocketSourceFunction(
hostname,
port,
byteDelimiter,
deserializer);
return SourceFunctionProvider.of(sourceFunction, false);
}
@Override
public DynamicTableSource copy() {
return null;
}
@Override
public String asSummaryString() {
return "socket table source";
}
}
Factories
最后定义动态表工厂,在SocketDynamicTableFactory 中定义FACTORY_IDENTIFIER 为socket。SocketDynamicTableFactory 将catalog表转换为表源。 因为表源需要解码格式,为了方便起见,我们使用提供的 FactoryUtil 发现格式。
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import java.util.HashSet;
import java.util.Set;
public class SocketDynamicTableFactory implements DynamicTableSourceFactory {
private static final String FACTORY_IDENTIFIER = "socket";
public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> PORT = ConfigOptions.key("port")
.intType()
.noDefaultValue();
public static final ConfigOption<Integer> BYTE_DELIMITER = ConfigOptions.key("byte-delimiter")
.intType()
.defaultValue(10); // corresponds to '\n'
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// discover a suitable decoding format
final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
// validate all options
helper.validate();
// get the validated options
final ReadableConfig options = helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// create and return dynamic table source
return new SocketDynamicTableSource(hostname, port, byteDelimiter, decodingFormat, producedDataType);
}
@Override
public String factoryIdentifier() {
return FACTORY_IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOSTNAME);
options.add(PORT);
options.add(FactoryUtil.FORMAT); // use pre-defined option for format
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(BYTE_DELIMITER);
return options;
}
}
在META-INF/services/org.apache.flink.table.factories.Factory中写入com.zh.ch.bigdata.flink.connectors.socket.SocketDynamicTableFactory
我们将使用上面提到的大部分接口来启用以下 DDL:
CREATE TABLE UserScores (name STRING, score INT)
WITH (
'connector' = 'socket',
'hostname' = 'localhost',
'port' = '9999',
'byte-delimiter' = '10',
'format' = 'csv',
'csv.allow-comments' = 'true',
'csv.ignore-parse-errors' = 'true'
);由于该格式支持变更日志语义,我们能够在运行时摄取更新并创建一个可以持续评估变化数据的更新视图:
SELECT name, SUM(score) FROM UserScores GROUP BY name;
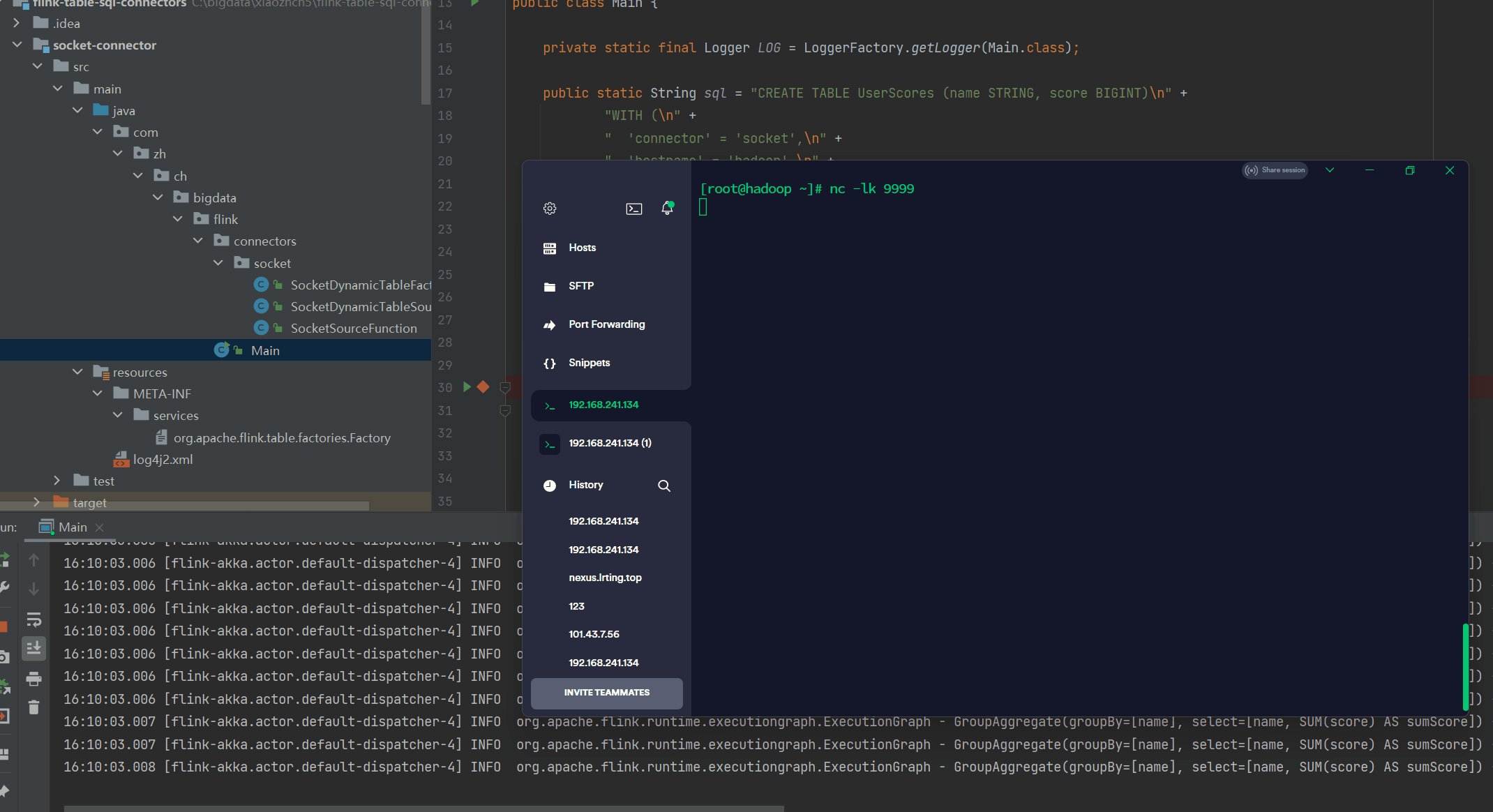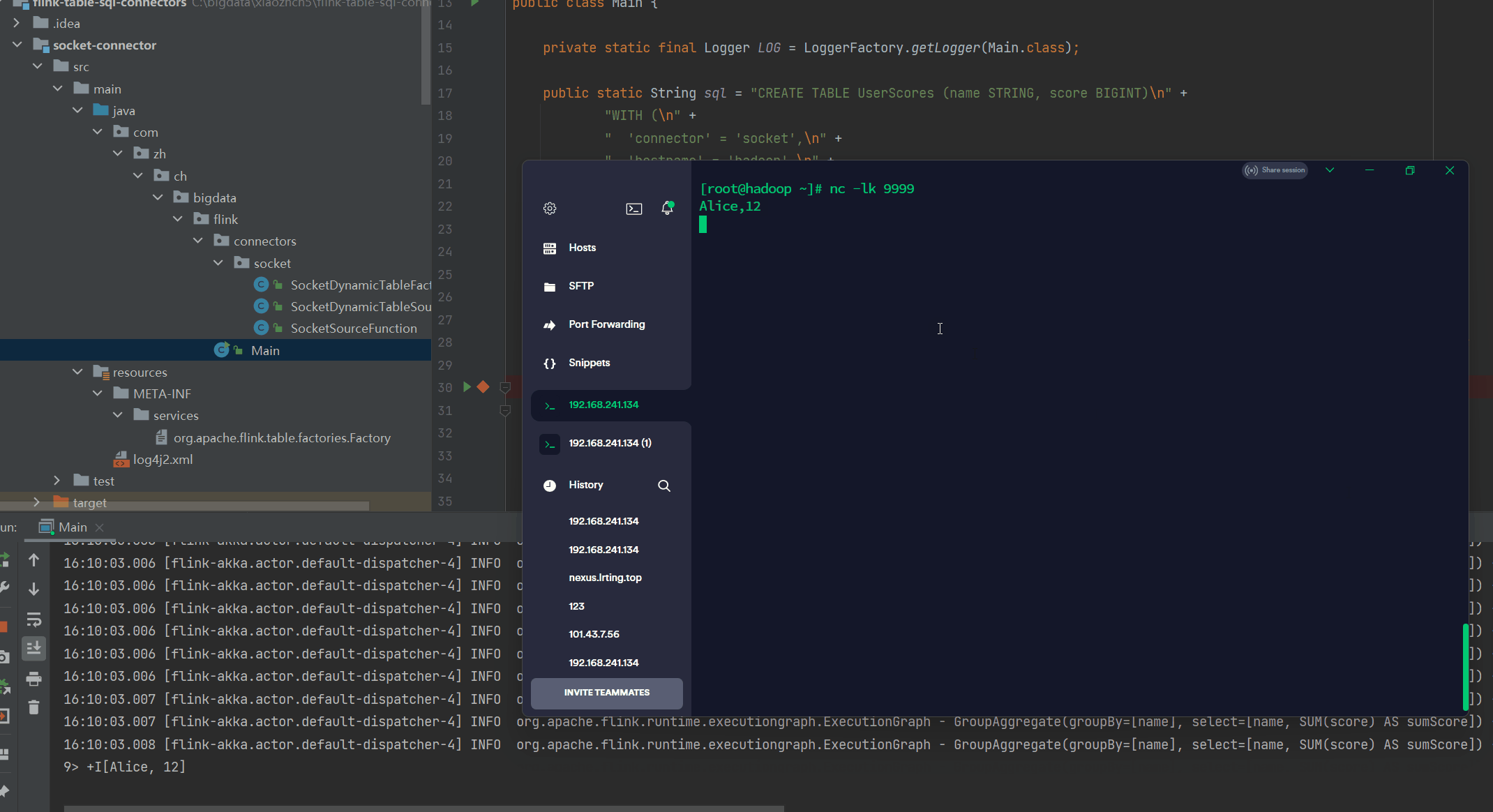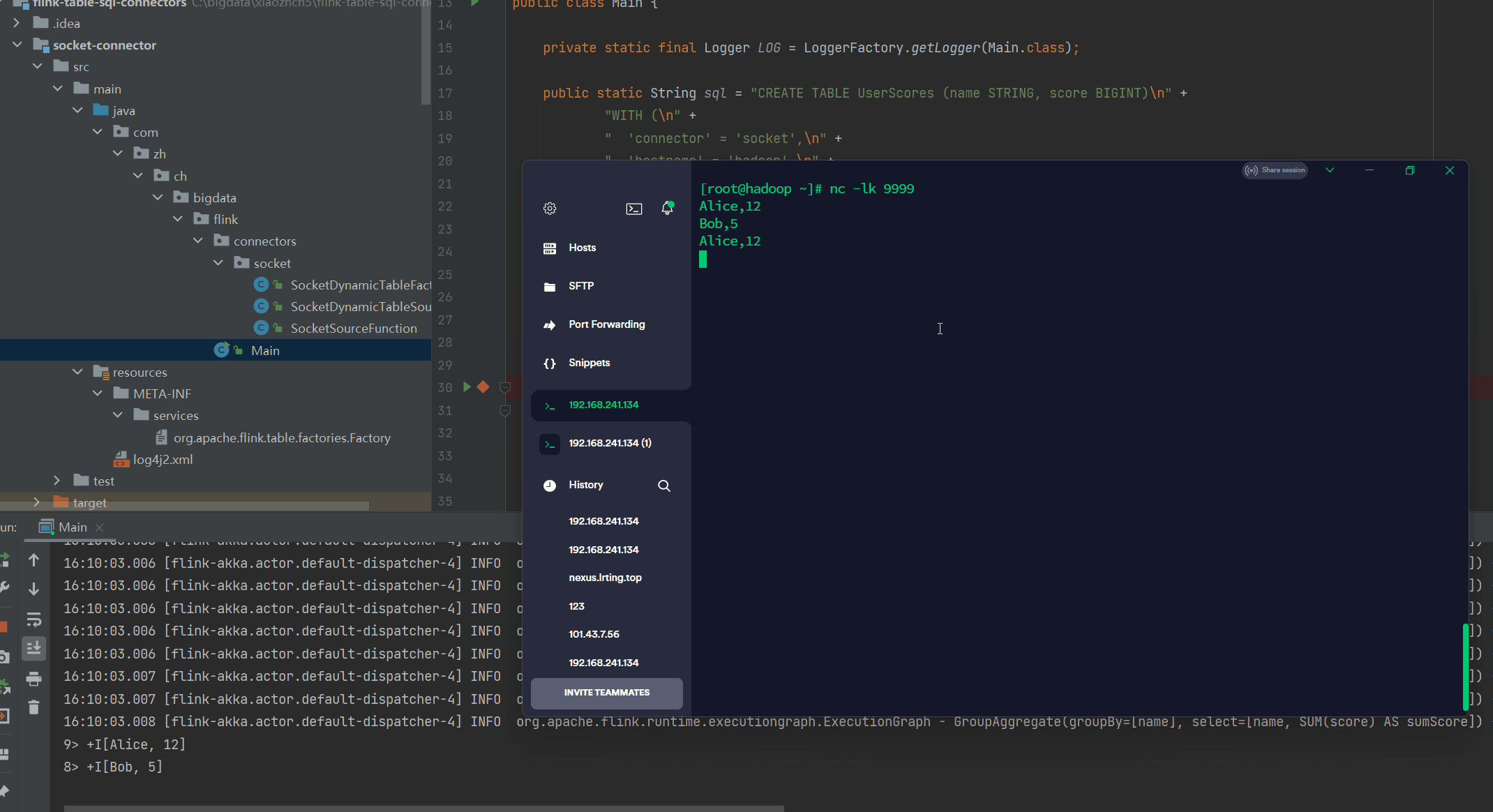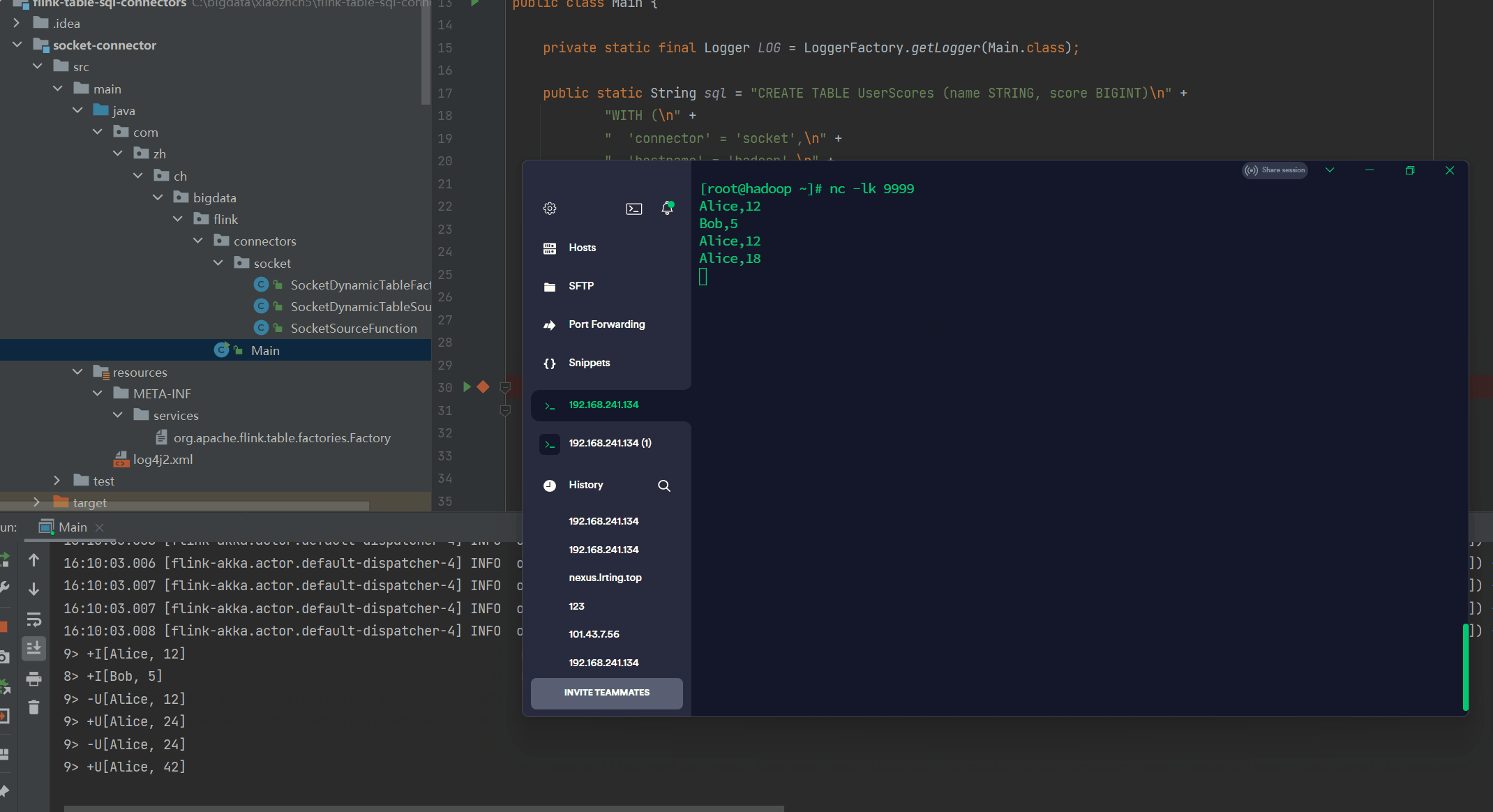
使用以下命令在终端中摄取数据:
> nc -lk 9999
Alice,12
Bob,5
Alice,12
Alice,18完整代码地址:
https://git.lrting.top/xiaozhch5/flink-table-sql-connectors.git
扩展已有connectors
本节介绍用于扩展 Flink 的表连接器的可用接口。
动态表工厂
动态表工厂用于根据catalog和会话信息为外部存储系统配置动态表连接器。
org.apache.flink.table.factories.DynamicTableSourceFactory 可以实现来构造一个DynamicTableSource。
org.apache.flink.table.factories.DynamicTableSinkFactory 可以实现来构造一个DynamicTableSink。
默认情况下,使用连接器选项的值作为工厂标识符和 Java 的服务提供者接口来发现工厂。
在 JAR 文件中,可以将对新实现的引用添加到服务文件中:
META-INF/services/org.apache.flink.table.factories.Factory
该框架将检查由工厂标识符和请求的基类(例如 DynamicTableSourceFactory)唯一标识的单个匹配工厂。
如有必要,catalog实现可以绕过工厂发现过程。为此,目录需要返回一个实现 org.apache.flink.table.catalog.Catalog#getFactory 中请求的基类的实例。
动态表源
根据定义,动态表可以随时间变化。
在读取动态表时,内容可以被认为是:
- 一个更改日志(有限或无限),所有更改都会持续使用,直到更改日志用完。 这由 ScanTableSource 接口表示。
- 一个不断变化的或非常大的外部表,其内容通常不会被完全读取,而是在必要时查询单个值。 这由 LookupTableSource 接口表示。
一个类可以同时实现这两个接口。 规划器根据指定的查询决定它们的使用。
Scan Table Source
ScanTableSource 在运行时扫描来自外部存储系统的所有行。
扫描的行不必只包含插入,还可以包含更新和删除。 因此,表源可用于读取(有限或无限)变更日志。 返回的更改日志模式指示计划程序在运行时可以预期的一组更改。
对于常规的批处理场景,源可以发出有限的仅插入行流。
对于常规流式处理方案,源可以发出无限制的仅插入行流。
对于变更数据捕获 (CDC) 方案,源可以发出带有插入、更新和删除行的有界或无界流。
表源可以实现更多的能力接口,例如 SupportsProjectionPushDown,这可能会在计划期间改变实例。 所有能力都可以在 org.apache.flink.table.connector.source.abilities 包中找到,并在源能力表中列出。
ScanTableSource 的运行时实现必须生成内部数据结构。 因此,记录必须以 org.apache.flink.table.data.RowData 的形式发出。 该框架提供了运行时转换器,因此源仍然可以处理常见的数据结构并在最后执行转换。
Lookup Table Source
LookupTableSource 在运行时通过一个或多个键查找外部存储系统的行。
与 ScanTableSource 相比,源不必读取整个表,并且可以在必要时从(可能不断变化的)外部表中懒惰地获取单个值。
与 ScanTableSource 相比,LookupTableSource 目前仅支持发出仅插入更改。
不支持进一步的能力。 有关更多信息,请参阅 org.apache.flink.table.connector.source.LookupTableSource 的文档。
LookupTableSource 的运行时实现是 TableFunction 或 AsyncTableFunction。 该函数将在运行时使用给定查找键的值调用。
Source Abilities
| Interface | Description |
|---|---|
| SupportsFilterPushDown | Enables to push down the filter into the DynamicTableSource. For efficiency, a source can push filters further down in order to be close to the actual data generation. |
| SupportsLimitPushDown | Enables to push down a limit (the expected maximum number of produced records) into a DynamicTableSource. |
| SupportsPartitionPushDown | Enables to pass available partitions to the planner and push down partitions into a DynamicTableSource. During the runtime, the source will only read data from the passed partition list for efficiency. |
| SupportsProjectionPushDown | Enables to push down a (possibly nested) projection into a DynamicTableSource. For efficiency, a source can push a projection further down in order to be close to the actual data generation. If the source also implements SupportsReadingMetadata, the source will also read the required metadata only. |
| SupportsReadingMetadata | Enables to read metadata columns from a DynamicTableSource. The source is responsible to add the required metadata at the end of the produced rows. This includes potentially forwarding metadata column from contained formats. |
| SupportsWatermarkPushDown | Enables to push down a watermark strategy into a DynamicTableSource. The watermark strategy is a builder/factory for timestamp extraction and watermark generation. During the runtime, the watermark generator is located inside the source and is able to generate per-partition watermarks. |
| SupportsSourceWatermark | Enables to fully rely on the watermark strategy provided by the ScanTableSource itself. Thus, a CREATE TABLE DDL is able to use SOURCE_WATERMARK() which is a built-in marker function that will be detected by the planner and translated into a call to this interface if available. |
以上接口目前仅适用于 ScanTableSource,不适用于 LookupTableSource。
动态表Sink
根据定义,动态表可以随时间变化。
在编写动态表时,可以始终将内容视为更改日志(有限或无限),其中所有更改都被连续写出,直到更改日志用完为止。返回的更改日志模式指示接收器在运行时接受的更改集。
对于常规批处理场景,接收器可以仅接受仅插入行并写出有界流。
对于常规的流式处理方案,接收器只能接受仅插入行,并且可以写出无界流。
对于变更数据捕获 (CDC) 场景,接收器可以使用插入、更新和删除行写出有界或无界流。
表接收器可以实现更多的能力接口,例如 SupportsOverwrite,这可能会在规划期间改变实例。所有能力都可以在 org.apache.flink.table.connector.sink.abilities 包中找到,并在 sink 能力表中列出。
DynamicTableSink 的运行时实现必须使用内部数据结构。因此,记录必须被接受为 org.apache.flink.table.data.RowData。该框架提供了运行时转换器,因此接收器仍然可以在通用数据结构上工作并在开始时执行转换。
Sink Abilities
| Interface | Description |
|---|---|
| SupportsOverwrite | Enables to overwrite existing data in a DynamicTableSink. By default, if this interface is not implemented, existing tables or partitions cannot be overwritten using e.g. the SQL INSERT OVERWRITE clause. |
| SupportsPartitioning | Enables to write partitioned data in a DynamicTableSink. |
| SupportsWritingMetadata | Enables to write metadata columns into a DynamicTableSource. A table sink is responsible for accepting requested metadata columns at the end of consumed rows and persist them. This includes potentially forwarding metadata columns to contained formats. |
Encoding / Decoding Formats
一些表连接器接受对键和/或值进行编码和解码的不同格式。
格式的工作方式类似于模式 DynamicTableSourceFactory -> DynamicTableSource -> ScanRuntimeProvider,其中工厂负责转换选项,源负责创建运行时逻辑。
因为格式可能位于不同的模块中,所以使用类似于表工厂的 Java 服务提供者接口来发现它们。 为了发现格式工厂,动态表工厂搜索与工厂标识符和特定于连接器的基类相对应的工厂。
例如,Kafka 表源需要 DeserializationSchema 作为解码格式的运行时接口。 因此,Kafka 表源工厂使用 value.format 选项的值来发现 DeserializationFormatFactory。
当前支持以下格式工厂:
org.apache.flink.table.factories.DeserializationFormatFactory
org.apache.flink.table.factories.SerializationFormatFactory格式工厂将选项转换为 EncodingFormat 或 DecodingFormat。 这些接口是另一种为给定数据类型生成专用格式运行时逻辑的工厂。
例如,对于 Kafka 表源工厂,DeserializationFormatFactory 将返回一个 EncodingFormat
参考链接:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sourcessinks/
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/3514/
[…] 在文章Flink Table/SQL自定义Sources和Sinks全解析(附代码)中我们说到在Flink Table/SQL中如何自定义Sources和Sinks,有了上述文章的基础,我们再来理解Flink Table/SQL是如何实现Hudi的数据读取与写入就比较容易了。 […]
[…] 在文章Flink Table/SQL自定义Sources和Sinks全解析(附代码)中我们说到在Flink Table/SQL中如何自定义Sources和Sinks,有了上述文章的基础,我们再来理解Flink Table/SQL是如何实现Hudi的数据读取与写入就比较容易了。 […]
[…] 在文章Flink Table/SQL自定义Sources和Sinks全解析(附代码)中我们说到在Flink Table/SQL中如何自定义Sources和Sinks,有了上述文章的基础,我们再来理解Flink Table/SQL是如何实现Hudi的数据读取与写入就比较容易了。 […]
[…] 在文章Flink Table/SQL自定义Sources和Sinks全解析(附代码)中我们说到在Flink Table/SQL中如何自定义Sources和Sinks,有了上述文章的基础,我们再来理解Flink Table/SQL是如何实现Hudi的数据读取与写入就比较容易了。 […]