
目录
1. Shopee 数据系统建设中面临的典型问题
2. 为什么选择 Hudi
3. Shopee 在 Hudi 落地过程中的实践
4. 社区贡献
5. 总结与展望
湖仓一体(LakeHouse)作为大数据领域的重要发展方向,提供了流批一体和湖仓结合的新场景。目前,企业许多业务中会遇到的数据及时性、准确性,以及存储的成本等问题,都可以通过湖仓一体方案得到解决。
当下,几个主流的湖仓一体开源方案都在不断迭代开发中,业界的应用也都是在摸索中前行,在实际的使用中难免会遇到一些不够完善的地方和未支持的特性。Shopee 内部在使用过程中基于开源的 Apache Hudi 定制了自己的版本,以实现企业级的应用和一些内部业务需求的新特性。
通过引入 Hudi 的 Data lake 方案,Shopee 的 Data Mart、推荐、ShopeeVideo 等产品的数据处理流程实现了流批一体、增量处理的特性,很大程度上简化了这一流程,并提升了性能。
1. Shopee 数据系统建设中面临的典型问题
1.1 Shopee 数据系统简介


上图是 Shopee Data Infrastructure 团队为公司内部业务方提供的一套整体解决方案。
-
第一步是数据集成(Data Integration),目前我们提供了基于日志数据、数据库和业务事件流的数据集成方式; -
然后通过平台的 ETL(Extract Transform Load)服务 load 到业务的数仓中,业务同学通过我们提供的开发平台和计算服务进行数据处理; -
最后的结果数据通过 Dashboard 进行展示,使用即时查询引擎进行数据探索,或者通过数据服务反馈到业务系统中。
下面先来分析一下 Shopee 数据系统建设中遇到的三个典型问题。
1.2 流批一体的数据集成
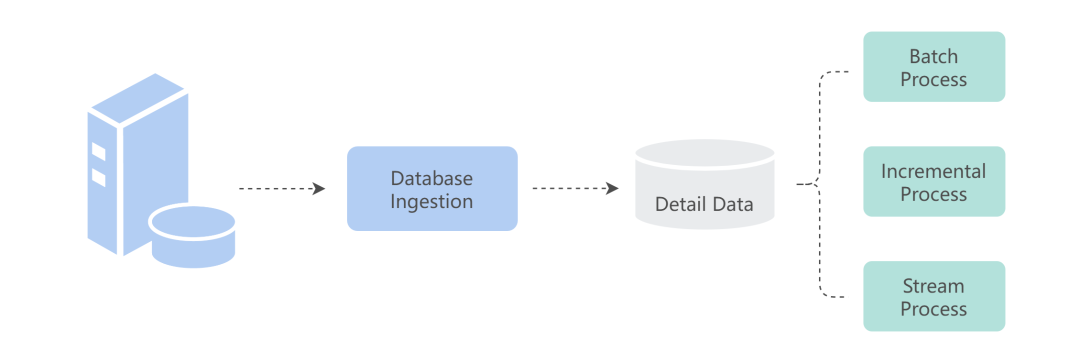
第一个问题:在基于数据库的数据集成过程中,存在同一份数据同时面临流处理和批处理的需求。传统的做法是实现全量导出和 CDC 两条链路。全量导出链路满足批处理的需求,CDC 链路用于实时处理和增量处理的场景。
然而,这种做法存在的一个问题是全量导出效率低,导致数据库负载高。另外,数据一致性也难以得到保证。
同时,在批数据集构建上有一定的存储效率优化,所以我们希望基于 CDC 数据去构建批数据集,以此同时满足三种处理场景的需求,提高数据时效性。
1.3 状态表明细存储
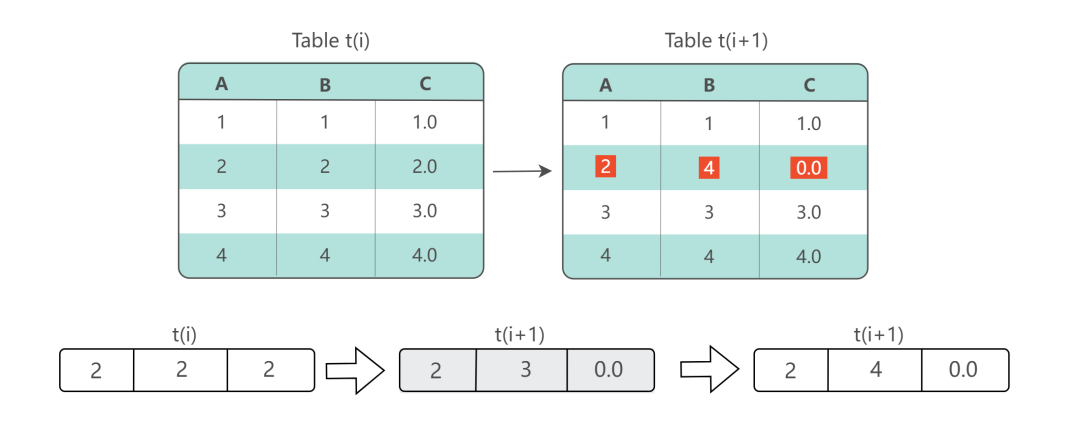
第二个问题是状态表明细的存储。我们可以认为,传统批数据集是在某一时间点对业务数据整体状态的一个快照,压缩到一个点的快照会合并掉业务流程中的过程信息。这些变化过程反映了用户使用我们服务的过程,是非常重要的分析对象。一旦被合并掉,将无法展开。
另外,在很多场景下,业务数据每天变化的部分只占全量数据的一小部分,每个批次都全量存储会带来很大的资源浪费。
1.4 大宽表创建
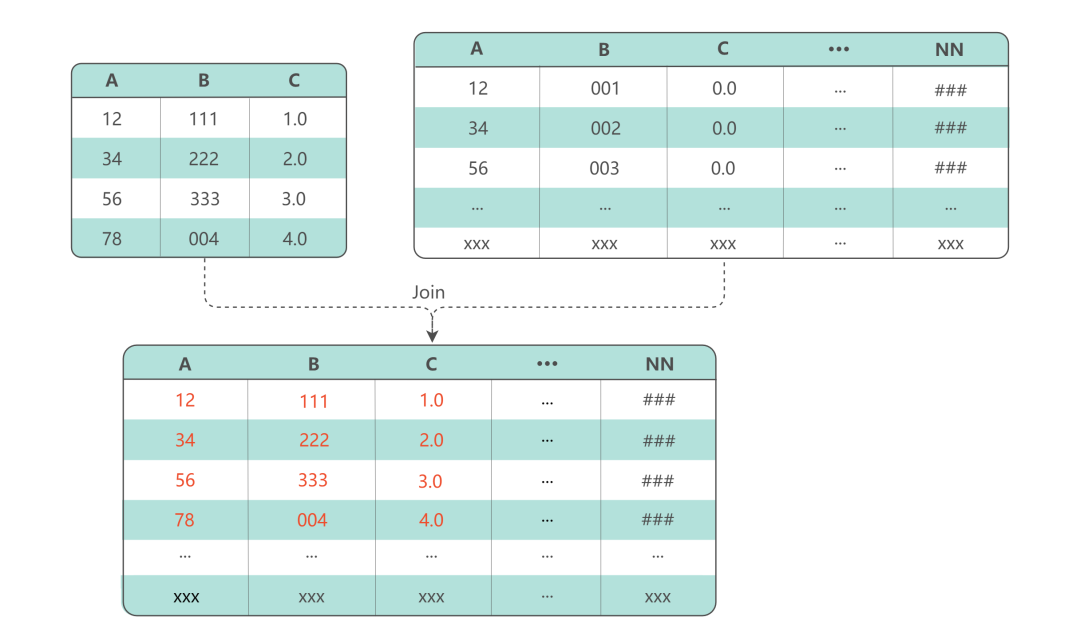
第三个问题是大宽表的创建。近实时宽表构建是数据处理中常见的一种场景,它存在的问题是传统的批处理延迟过高,使用流式计算引擎资源浪费严重。因此,我们基于多个数据集合构建了业务宽表,支持 Ad hoc 类 OLAP 查询。
2. 为什么选择 Hudi
针对上述业务中遇到的问题,基于以下三点考量,最终我们选择 Apache Hudi 来作为解决方案。
2.1 生态支持丰富
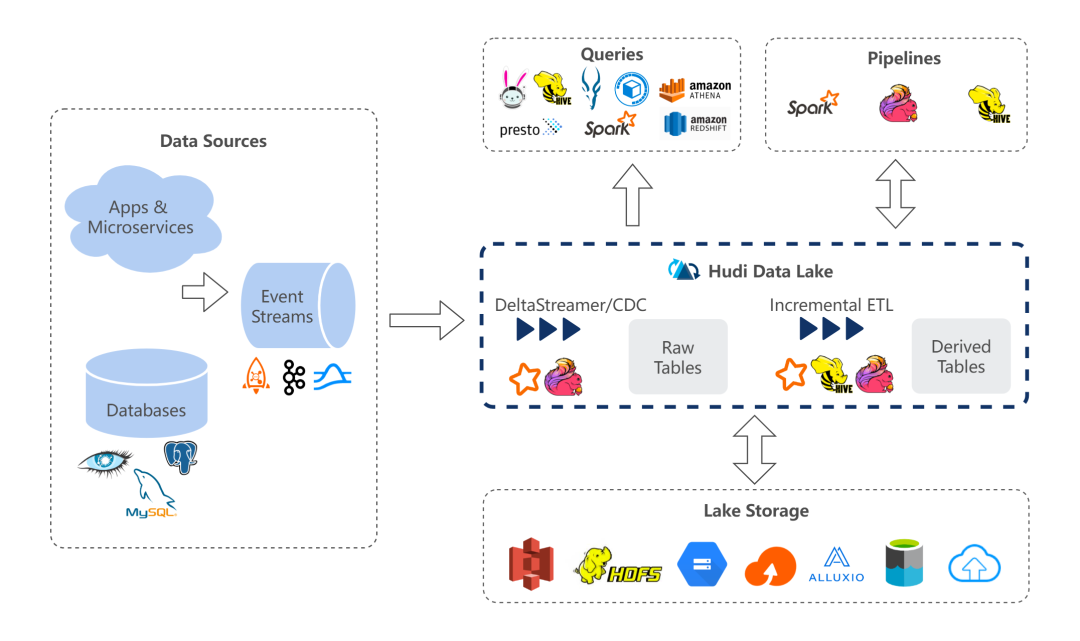
我们期望使用纯流式的方式建设数据集成环境,而 Hudi 对流式场景有着良好的支持。
第二点是对各个大数据生态的兼容。我们构建的数据集将会同时存在批处理、流处理、增量处理和动态探索等多种需求的负载。目前这些工作负载运行在各种计算引擎中,所以,对多种计算引擎的支持也在我们的考虑范围之内。
另一个考量点则是和 Shopee 业务需求的契合。当前,我们亟待处理的数据集大部分来源于业务系统,都带有唯一性标识信息,所以 Hudi 的设计更加符合我们的数据特性。
2.2 插件化的能力

目前我们平台提供 Flink 和 Spark 作为通用计算引擎,作为数据集成和数仓建设负载的承载者,同时也使用 Presto 承载数据探索的功能。Hudi 对这三者都支持。
在实际使用中,根据业务数据的重要程度不同,我们也会给用户提供不同的数据索引方式。
2.3 业务特性匹配
在数据集成过程中,用户的 schema 变化是一个非常常见的需要。ODS 的数据变化可能导致下游的计算任务出错。同时,在增量处理时,我们需要时间处理的语义。支持主键数据的存储对于我们业务数据库的数据来说,意义重大。
3. Shopee 在 Hudi 落地过程中的实践
3.1 实时数据集成
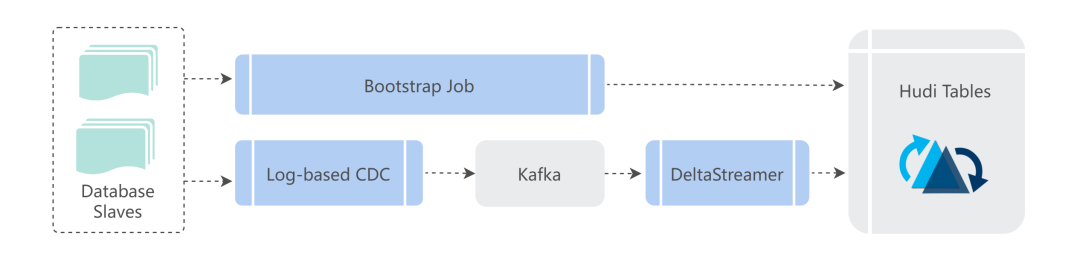
目前 Shopee 内部有大量的业务数据来自业务数据库,我们采用类似 CDC 的技术获取数据库中的变更数据,给业务方构建支持批处理和近实时增量处理的 ODS 层数据。
当一个业务方的数据需要接入时,我们会在进行增量实时集成之前先做一次全量 Bootstrap,构建基础表,然后基于新接入的 CDC 数据进行实时构建。
构建的过程中,我们一般根据用户需求选择构建的 COW 表或者 MOR 表。
1)问题构建与解决方案
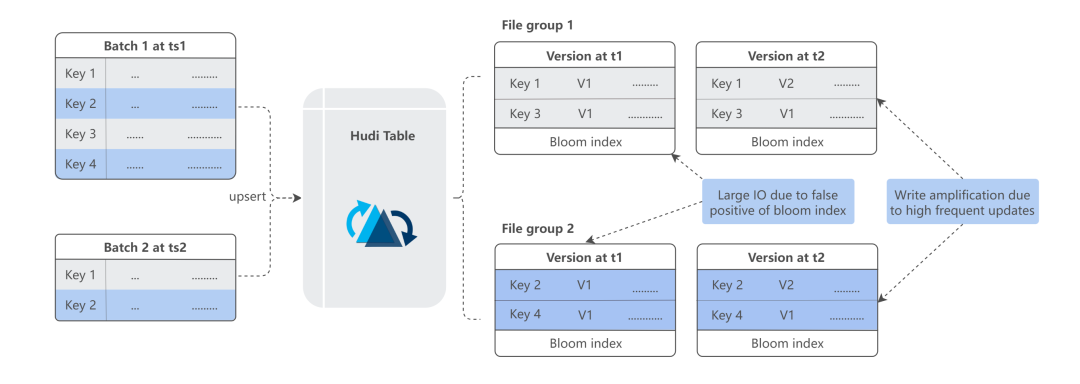
在进行实时构建的过程中,存在以下两种较为常见的问题:
一种是用户将有大量变更的数据集的类型配置为 COW 表,导致数据写放大。此时我们需要做的事情是建立相应的监控来识别这种配置。同时,我们基于 MOR 表的配置化数据合并逻辑,支持数据文件的同步或者异步更新。
第二个问题是默认的 Bloom filter 导致数据存在性判断的问题。这里比较好的方式是采用 HBase Index 解决超大数据集的写入问题。
2)问题解决的效果

这是将我们的某些数据集成链路换成基于 Hudi 的实时集成后的效果。上图是数据可见性占比与时延的关系,目前我们能保证 80% 的数据在 10 分钟内可见可用,所有的数据 15 分钟内可见可用。
下图是我们统计的资源消耗占比图。蓝色部分是实时链路的资源消耗,红色是历史的按批数据集成的资源消耗。
因为切换成了实时链路,对于一些大表重复率低的数据减少了重复处理,同时也减少了集中式处理效率降低导致的资源消耗。因此,我们的资源消耗远低于批处理方式。
3.2 增量视图

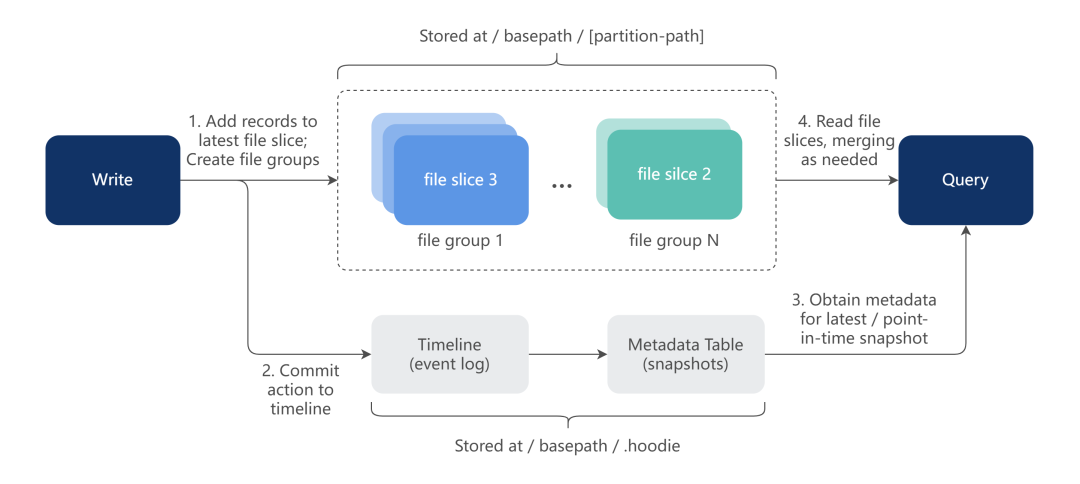
针对用户需要状态明细的场景,我们提供了基于 Hudi Savepoint 功能的服务,按照用户需要的时间周期,定期构建快照(snapshot),这些快照以分区的形式存在元数据管理系统中。
用户可以方便地在 Flink、Spark,或者 Presto 中利用 SQL 去使用这些数据。因为数据存储是完整且没有合并的明细,所以数据本身支持全量计算,也支持增量处理。

在使用增量视图的存储时,对于一些变化数据占比不大的场景,会取得比较好的存储节省效果。
这里有一则简单的公式,用于计算空间使用率:(1 + (t - 1) * p ) / t。
其中,P 表示变化数据的占比,t 表示需要保存的时间周期数。变化数据占比越低,所带来的存储节省越好。对于长周期数据,也会有一个比较好的节省效果。
同时,这种方式对增量计算的资源节省效果也比较好。缺点是按批全量计算会有一定的读放大的问题。
3.3 增量计算
当我们的数据集基于 Hudi MOR 表来构建时,就可以同时支持批处理、增量处理和近实时处理负载。
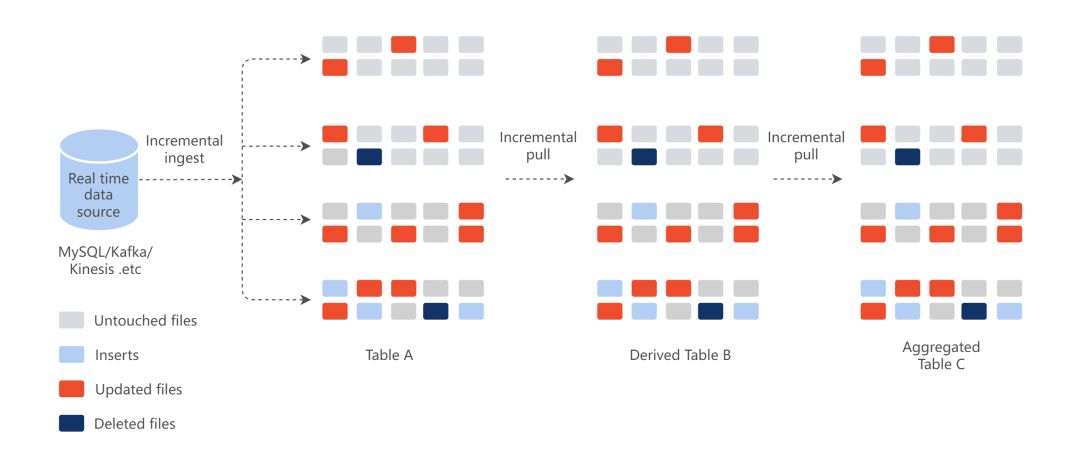
以图为例,Table A 是一个增量的 MOR 表,当我们基于 Table A 来构建后续的表 B 和表 C 时,如果计算逻辑都支持增量的构建,那我们在计算的过程中,只需要获取新增的数据和变化的数据。这样在计算的过程中就显著减少了参与计算的数据量。

这里是离线计算平台基于 Hudi 的增量计算来构建的一个近实时的用户作业分析。当用户提交一个 Spark 任务到集群运行,任务结束后会自动收集用户的日志,并从中提取相关的 Metric 和关键日志写入到 Hudi 表。然后一个处理任务增量读取这些日志,分析出任务的优化项,以供用户参考。
当一个用户作业运行完后,一分钟之内就可以分析出用户的作业情况,并形成分析报告提供给用户。
增量 Join


除了增量计算,增量的 Join 也是一个非常重要的应用场景。
相对于传统的 Join,增量计算只需要根据增量数据查找到需要读取的数据文件,进行读取,并分析出需要重写的分区,重新写入。
相对于全量来说,增量计算显著减少了参与计算的数据量。
Merge Into
Merge Into 是在 Hudi 中非常实用的一个用于构建实时宽表的技术,它主要基于 Partial update 来实现。
MERGE INTO target_table t0
USING SOURCE TABLE s0
ON t0.id = s0.id
WHEN matched THEN UPDATE SET
t0.price = s0.price+5,
_ts = s0.ts;
MERGE INTO target_table_name [target_alias]
USING source_table_reference [source_alias]
ON merge_condition
[ WHEN MATCHED [ AND condition ] THEN matched_action ] [...]
[ WHEN NOT MATCHED [ AND condition ] THEN not_matched_action ] [...]
matched_action
{ DELETE |
UPDATE SET * |
UPDATE SET { column1 = value1 } [, ...] }
not_matched_action
{ INSERT * |
INSERT (column1 [, ...] ) VALUES (value1 [, ...])
这里展示了基于 Spark SQL 的 Merge Into 语法,它让用户构建宽表的作业开发变得非常简单。
基于 Merge Into 的增量 Join 实现
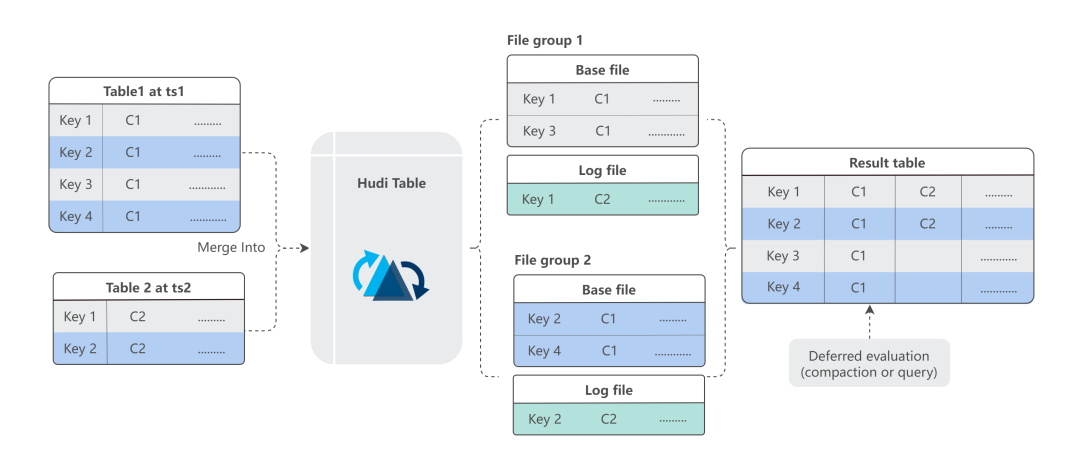
Hudi 的实现是采用 Payload 的方式,在一个 Payload 中可以只存在一张表的部分列。
增量数据的 Payload 被写入到 log 文件中,然后在后续的合并中生成用户使用的宽表。因为后续合并存在时间延迟,所以我们优化了合并的写入逻辑。
在数据合并完成后,我们会在元数据管理中写入一个合并的数据时间和相关的 DML,然后在读取这张 MOR 表的过程中分析 DML 和时间,为数据可见性提供保障。
而采用 Partial Update 的好处是:
-
显著降低了流式构建大宽表的资源使用; -
文件级别的数据修改时,处理效率增高。
4. 社区贡献
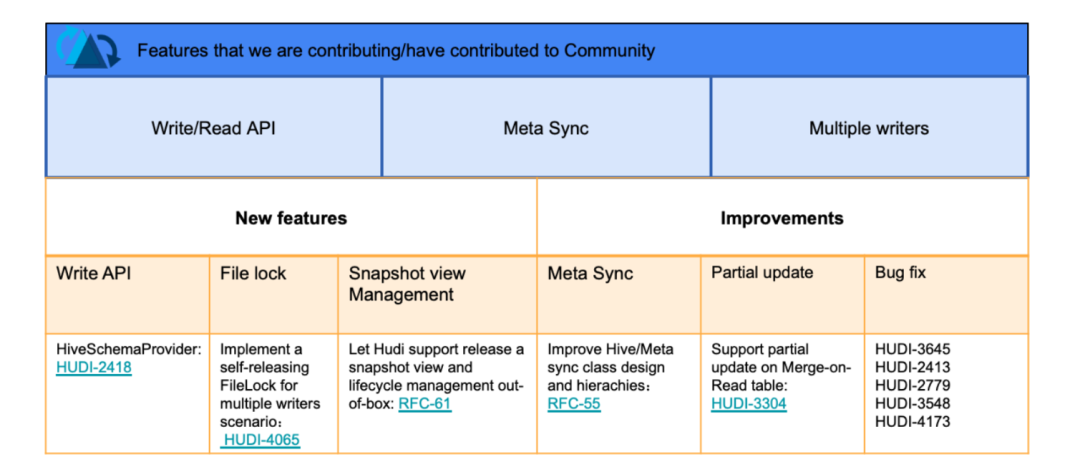
在解决处理 Shopee 内部业务问题的同时,我们也贡献了一批代码到社区,将内部的优化和新特性分享出来,比较大的 feature 有 meta sync(RFC-55 已完成)、snapshot view(RFC-61)、partial update(HUDI-3304)、FileSystemLocker(HUDI-4065 已完成) 等等;同时也帮助社区修复了很多 bug。后续也希望能够用这种方式,更好地满足业务需求的同时,参与社区共建。
4.1 Snapshot View
增量视图(snapshot view)有以下几个典型应用场景:
-
每天在基础表上生成名称为 compacted-YYYYMMDD的快照,用户使用快照表生成每日的衍生数据表,并计算报表数据。当用户下游的计算逻辑发生变化时,能够选择对应快照进行重新计算。还可以设置留存期为 X 天,每天清理掉过期数据。这里其实也可以在多快照的数据上自然地实现 SCD-2。 -
一个命名为 yyyy-archived的存档分支可以每年在数据进行压缩和优化之后生成,如果我们的保存策略有变化(例如要删除敏感信息),那么可以在进行相关的操作之后,在这个分支上生成一个新的快照。 -
一个命名为 preprod-xx的快照可以在进行了必要的质量检查之后再正式发布给用户,避免外部工具与 pipeline 本身的耦合。
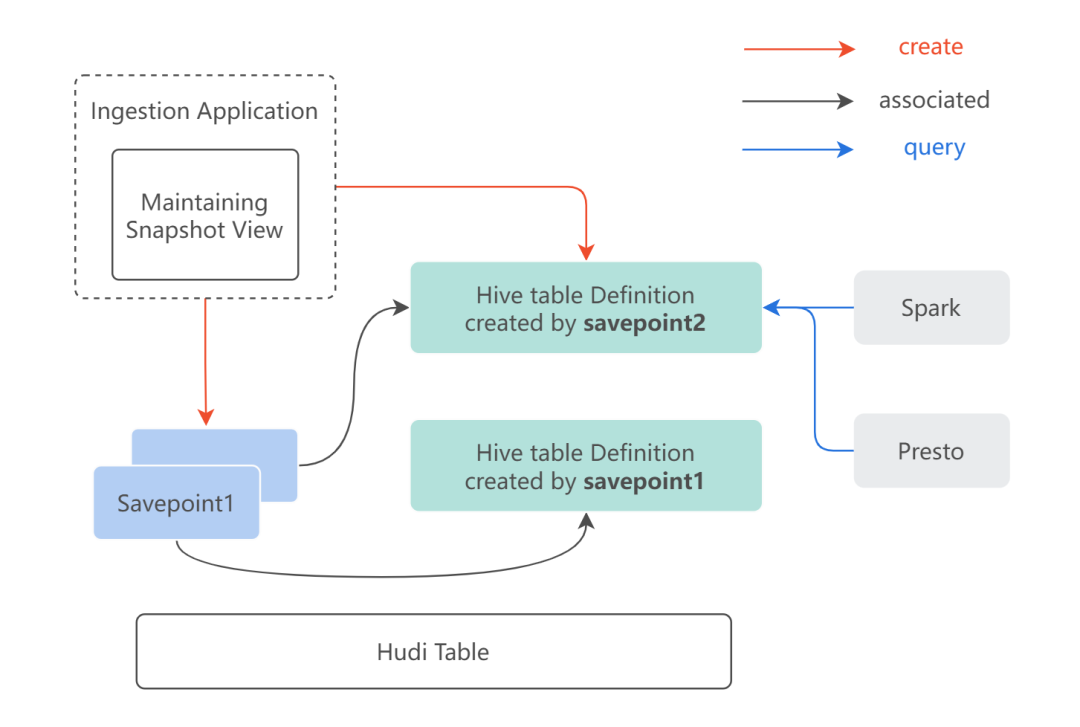
对于 snapshot view 的需求,Hudi 已经可以在一定程度上通过两个关键特性来做支持:
-
Time travel:用户可以提供一个时间点来查询对应时间上的 Hudi 表快照数据。 -
Savepoint:可以保证某个 commit 时间点的快照数据不会被清理,而在 savepoint 之外的中间数据仍然可以被清理。
简单的实现如下图所示:
但是在实际的业务场景中,为了满足用户的 snapshot view 需求,还需要从易用性和可用性上考虑更多。
例如,用户如何得知一个 snapshot 已经正确地发布出来了?这其中包含的一个问题是可见性,也就是说,用户应该可以在整个 pipeline 中显式地拿到 snapshot 表,这里就需要提供类似 Git 的 tag 功能,增强易用性。
另外,在打快照的场景中,一个常见的需求是数据的精准切分。一个例子就是用户其实不希望 event time 在 1 号的数据漂移到 2 号的快照之中,更希望的做法是在每个 FileGroup 下结合 watermark 做精细的 instant 切分。
为了更好地满足生产环境中的需求,我们实现了以下优化:
-
扩展了 savepoint metadata,在此基础上实现快照的 tag、branch 以及 lifecycle 管理,和自动的 meta 同步功能; -
在 MergeOnRead 表上实现精细化的 ro 表 base file 切分,在 compaction 的时候通过 watermark 切分日志文件,保证 snapshot 的精确性。也就是说,我们可以在流式写入的基础上,给下游的离线处理提供精确到 0 点的数据。
目前我们正在将整体功能通过 RFC-61 贡献回社区,实际落地过程的收益前面章节已有介绍,这里不再赘述。
4.2 多源 Partial update
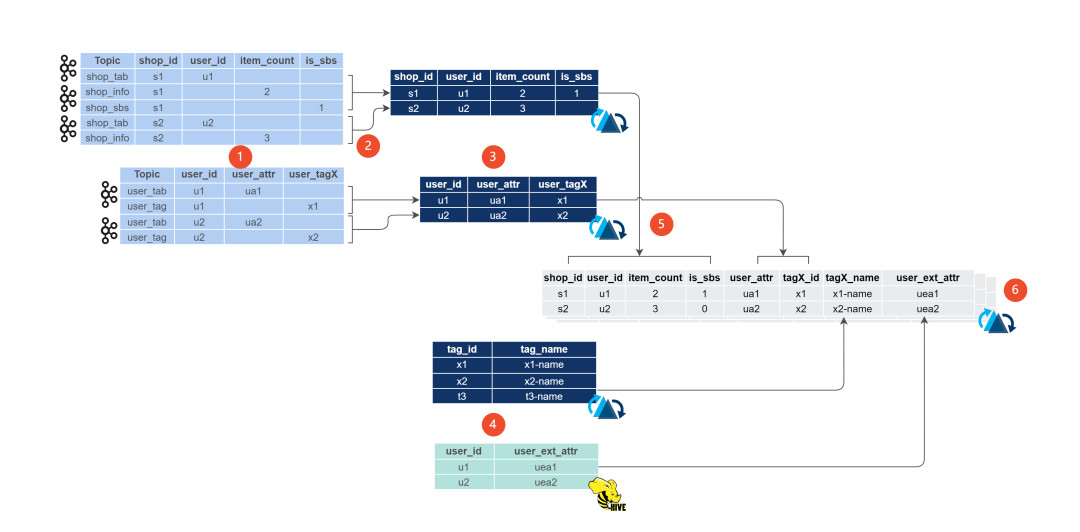
前文简单介绍了多源部分列更新(大宽表拼接)的场景,我们依赖 Hudi 的多源合并能力在存储层实现 Join 的操作,大大降低了计算层在 state 和 shuffle 上的压力。
目前,我们主要是通过 Hudi 内部的 Payload 接口实现多源的部分列更新。下面这张图展示了 Payload 在 Hudi 的写端和读端的交互流程。
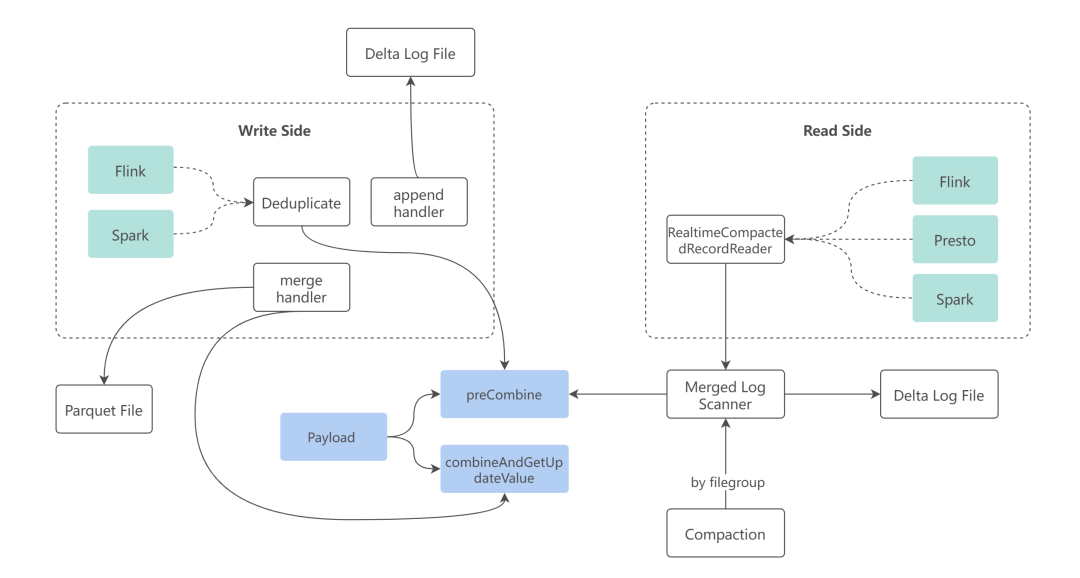
实现的原理基本上就是通过自定义的 Payload class 来实现相同 key 不同源数据的合并逻辑,写端会在批次内做多源的合并并写入 log,读端在读时合并时也会调用相同的逻辑来处理跨批次的情况。
这里需要注意的是乱序和迟到数据(out-of-order and late events)的问题。如果不做处理,在下游经常会导致旧数据覆盖新数据,或者列更新不完整的情况。
针对乱序和迟到数据,我们对 Hudi 做了 Multiple ordering value 的增强,保证每个源只能更新属于自己那部分列的数据,并且可以根据设置的 event time (ordering value) 列,确保只会让新数据覆盖旧数据。
后续我们还准备结合 lock less multiple writers 来实现多 Job 多源的并发写入。
5. 总结与展望
针对在 Shopee 数据系统建设中面临的问题,我们提出了湖仓一体的解决方案,通过对比选型选择了 Hudi 作为核心组件。
在落地过程中,我们通过使用 Hudi 的核心特性以及在此之上的扩展改造,分别满足了三个主要的用户需求场景:实时数据集成、增量视图和增量计算。并为用户带来了低延时(约 10 分钟)、降低计算资源消耗、降低存储消耗等收益。
接下来,我们还将提供更多特性,并针对以下两个方面做进一步完善,从而满足用户更多的场景,提供更好的性能。
5.1 跨任务并发写支持
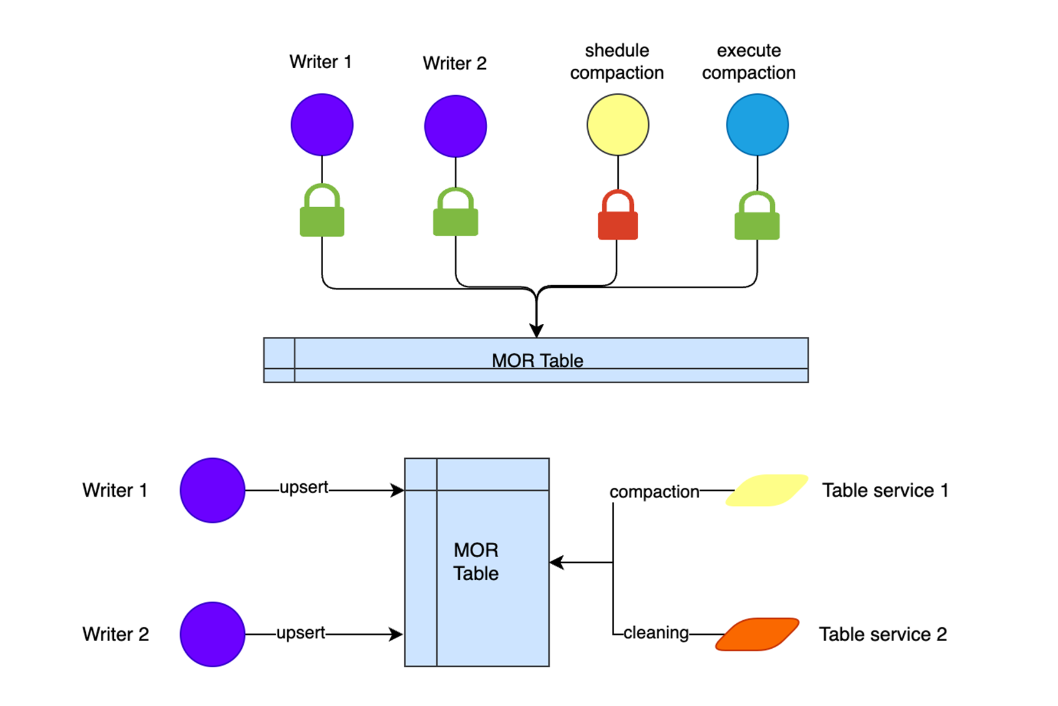
当前 Hudi 支持了基于文件锁的单个任务单 writer 的写入方式。
但是在实际中,有一些场景需要多个任务多 writer 同时写入,且写入分区有交叉,目前的 OCC 对这种情况支持不佳。目前我们正在与社区合作解决 Flink 与 Spark 多重 writer 的场景。
5.2 性能优化
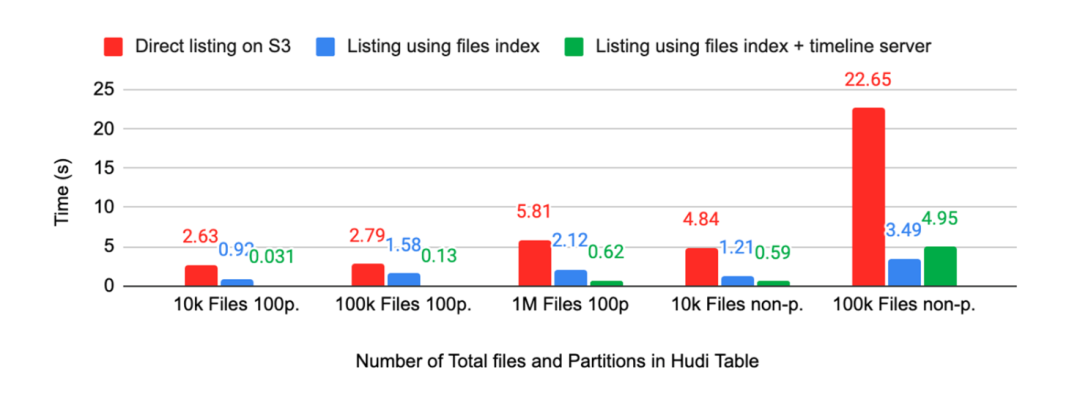
元数据读取以及 File listing 操作无论是在写入端还是读取端都会有很大的性能消耗,海量的分区对外部元数据系统(比如 HMS)也会造成很大压力。
针对这一问题,我们计划第一步将 schema 之外的信息存储从 HMS 过渡到 MDT;第二步是在未来使用一个独立的 MetaStore 和 Table service 的 server,不再强耦合于 HDFS。
在这个 server 中,我们可以更容易地优化读取性能,更灵活地进行资源调整。
本文作者
Jian,大数据技术专家,来自 Shopee Data Infrastructure 团队。
团队简介
Shopee Data Infrastructure 团队专注于为公司构建稳定、高效、安全、易用的大数据基础设施和平台。
我们的业务包括:实时数据链路支持,Kafka、Flink 的相关开发;HDFS、Spark 等 Hadoop 生态组件的开发和维护;Linux 操作系统的运维和大数据组件的运维;OLAP 组件、Presto、Druid、Trino、Elasticsearch、ClickHouse 的开发和业务支持;大数据平台系统、资源管理、任务调度等平台的开发。
本文转载自Jian Shopee技术团队,原文链接:https://mp.weixin.qq.com/s/3nsYTVu9nZCIFaaXP09hiQ。