
本文章将结合我们的工作实践,分享如何基于Kubernetes实现在/离线业务的混合部署,在不影响在线业务的前提下,将CPU利用率提高到50%以上,大幅降低企业数据中心成本。
引言
服务器资源利用率较低,IT基础设施的总拥有成本(TCO)逐年上涨,一直是困扰很多企业的难题。统计数据显示,数据中心成本中服务器采购成本占比超过50%,而全球服务器平均资源利用率不到20%,造成了巨大的IT基础设施成本浪费。
而在网易集团内部,传媒、音乐、严选、有道等互联网业务快速发展,互联网业务服务器数量不断攀升,但是服务器实际资源利用率比较低(平均CPU利用率不超过15%),IT基础设施成本问题日益严峻。
在/离线业务混合部署,是国内外大型IT企业公认的能够有效提升服务器资源利用率的解决方案。随着云原生技术的发展,Kubernetes逐渐成为数据中心的一项基础设施,将在/离线业务统一使用Kubernetes调度编排日渐成熟。
网易杭研容器编排团队提出了一套基于kubernetes的在离线业务混部方案和跨Kubernetes集群的全局资源调度方案,二者作为一个互补的、整体的资源利用率优化方案,目前已经在网易内部多个事业部落地,在无需业务改造、不影响业务SLO(service-level objective)的前提下,资源利用率得到显著提升。
本文将从以下几个方面逐渐展开:
-
资源利用率现状和原因分析
-
在/离线业务混部系统 Zeus
-
跨集群全局资源调度系统 KubeMiner
-
落地进展
-
未来展望
资源利用率现状和原因分析
麦肯锡数据统计显示,整个业界的服务器平均利用率大约为6%,而Gartner的估计要乐观一些,大概在12%。国内一些银行的数据中心的利用率大概在5%左右。而网易内部服务器CPU平均使用率不超过15%。
而造成利用率比较低的原因主要有以下几个方面:
不同类型的业务划分了独立的服务器资源池,资源无法有效互补
企业中一般存在两种类型的工作负载:在线服务(latency-sensitive service)和离线任务(batch job)。在线服务如搜索/主站/支付/推荐等,具有处理优先级高、时延敏感性高、错误容忍度低以及白天负载高晚上负载低等特点。而离线任务如AI训练/音视频转码/大数据处理等,具有处理优先级低、时延敏感性低、错误容忍度高以及运行时负载一直较高等特点。由于在线服务与离线任务这两类工作负载天然存在互补性,将在/离线业务混合部署是提高服务器资源利用率的有效途径。
但是绝大多数企业在构建数据中心或者机房的时候,对于在线服务和离线服务是单独采购机器并且分开管理部署的,各自采用独立的资源调度管理系统(比如离线业务使用Yarn调度,在线业务Mesos调度),从服务器采购、规划到业务调度层面都是完全隔离的。即使没有企业组织架构以及资源调度系统不一致等原因,为了充分保障在线业务的SLO,避免离线业务对在线业务的性能干扰,用户通常也将在/离线业务运行在不同的服务器上。在线业务服务器资源利用率很低,浪费严重;而离线业务服务器资源利用率很高,并且在企业深度挖掘用户价值和精细化运营的大背景下,资源需求增长迅猛,缺乏足够的算力。
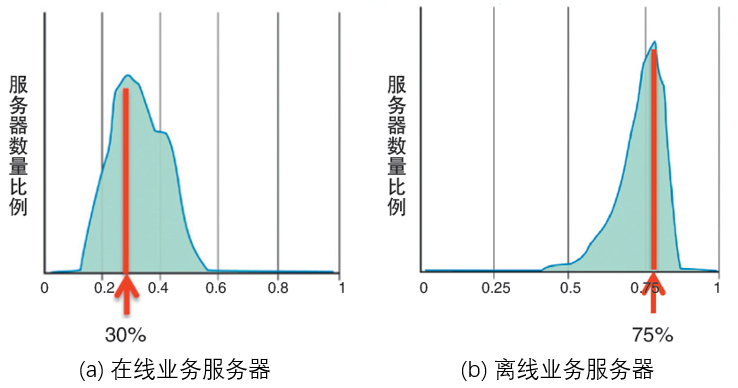

(图1 Google数据中心服务器资源利用率统计)
图1 是Google在线业务服务器和离线业务服务器的CPU利用率分布图。在线业务服务器CPU使用率集中在30%,而离线业务服务器CPU使用率集中在75%。
在线业务存在波峰波谷,用户按照波峰申请资源,波谷时资源浪费
大多数面向用户的在线服务的负载具有明显的波峰波谷,比如白天用户使用量较多,资源利用率相应较高,但是夜间用户使用量较少,资源利用率相应较低。用户在部署业务时,为了保证业务的稳定性,必然会按照业务波峰申请资源,但是波峰持续的时间可能并不长,导致大部分时间服务器资源利用率很低。
在线业务申请了过量的资源,request和real usage之间存在较大gap
很多业务开发人员或者运维人员在部署业务时,对于业务的资源需求配置存在一定的盲目性,通常会申请远超实际需求的资源。另外,很多业务为了容灾通常会多副本、跨机房冗余部署。
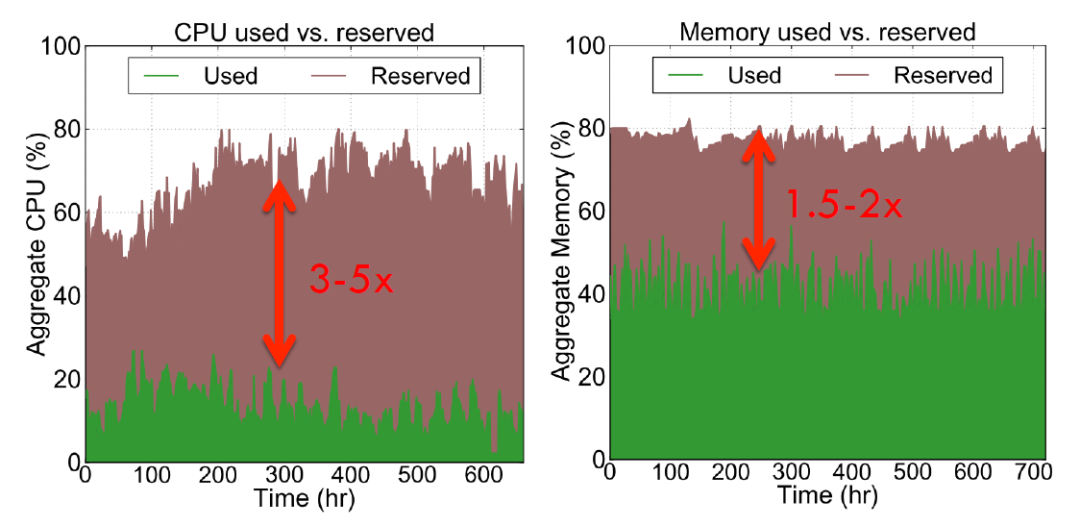
(图2 Twitter 服务器资源利用率统计)
图2 是推特数据中心资源使用情况,可以看到cpu利用率大约在20%左右,但是用户申请了60%左右的cpu资源;内存利用率在40%左右,但是用户申请了80%左右的内存资源。业务已申请的但是实际没有使用的资源,即使是空闲的,其他业务也是无法使用的。Reserved – Used差值越大,资源浪费越多。
不同部门或者不同团队部署了独立的K8S集群,无法做全局的服务器资源统筹规划和调度
由于企业组织架构等原因,不同的团队和部门通常会部署独立的Kubernetes集群,导致集团内部k8s集群数量众多,服务器资源呈现碎片化。有的集群资源利用率很高,但是缺乏足够的算力,经常需要想方设法协调服务器资源;而有的集群资源利用率很低,存在大量的空闲算力没有得到有效利用。
测试集群的资源没有得到有效利用
每个生产集群都对应了至少一个测试集群。在网易内部,测试集群的数量较多,服务器资源也很多。但是这部分资源大部分时间是空闲的,并没有得到有效利用。测试环境的机器,完全可以通过跑SLO要求不高的离线计算任务来有效利用起来。
针对上述导致资源利用率较低的几个原因,我们相应提出了两个解决方案:
-
在/离线业务混部 Zeus
-
跨集群全局资源调度 KubeMiner
本文重点介绍 在/离线业务混部Zeus,KubeMiner会在后续另一篇文章中进行分享。
在离线业务混合部署 Zeus
混合部署(co-location)是指将在线业务和离线业务混合部署在同一集群和服务器上。
-
一方面,可以将离线业务混部到在线业务的服务器上,让离线业务能够充分利用在线业务服务器的空闲资源,提高在线业务服务器资源利用率
-
另一方面,音乐或者严选等在线业务会有大促活动,临时需要大量的资源。这个时候可以将在线业务弹性混部到离线业务的服务器上,优先保证在线业务的资源需求,大促结束后再把资源归还给离线业务。
容器化和 Kubernetes(Google开源的容器编排引擎,简称k8s) 为企业应用的大规模混部打开了一扇窗,但是站在 Kubernetes 的肩膀上,混部依然是对企业架构能力的一个巨大挑战。我们基于业界主流的容器编排框架Kubernetes,研发网易集团的在/离线业务混合部署系统,统一在/离线业务的基础设施,显著提高数据中心资源利用率,大幅降低集团IT基础设施的总拥有成本。
3.1 Kubernetes 存在的问题
问题一 静态调度
Kubernetes 是使用的静态调度。静态调度是指根据容器的资源请求(resource request)进行调度,而不考虑节点的实际负载。所以,经常会发生节点负载很低,但是调度不了新的 pod 上去的情况。
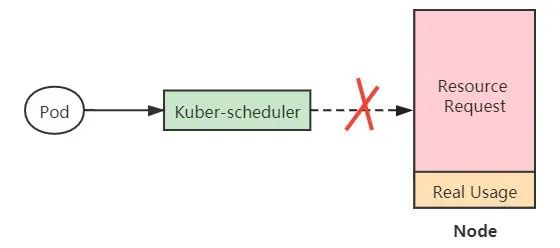
(图3 Kubernetes静态调度导致资源利用率较低)
另外,静态调度会导致Node之间的负载不均衡,有的节点资源利用率很高,而有的节点资源利用率很低。Kubernetes在调度时是有一个负载均衡优选调度算法(LeastRequested)的,但是它调度均衡的依据是resource request 而不是Node实际的资源使用率。
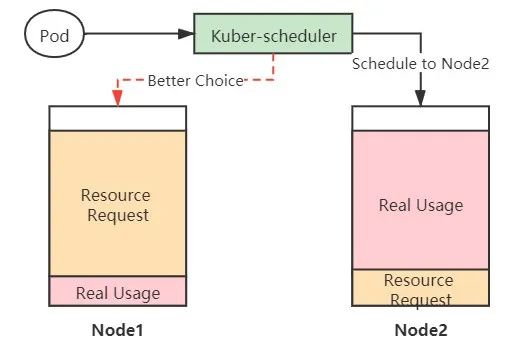
(图4 Kubernetes静态调度导致负载不均衡)
问题二 隔离性较弱
当在线业务和离线业务混部在同一台服务器上时,会争用服务器上的各种共享资源,包括CPU、内存、Cache、磁盘、网络等等。假如没有做精细化的资源隔离,离线业务很容易影响到在线业务的性能和稳定性。而Kubernetes中是没有在线业务和离线业务的概念的,所以也不存在针对在/离线业务之间的资源隔离问题。Kubernetes 对于pod之间的资源隔离也是很弱的,仅仅通过cgroups在cpu维度使用cpu.shares控制发生cpu争用时的时间片分配比例,使用cfs quota限制cpu使用上限;内存维度使用memory limit in bytes限制使用上限。如果贸然将在/离线业务混部在同一台机器上,是无法保证在线业务的SLO的。
因此,我们在设计开发基于Kubernetes的在/离线业务混部系统时,也是围绕着这两个核心矛盾来解决。
3.2 混部系统架构设计
我们基于 Kubernetes 实现了在 / 离线业务混部系统,遵循以下设计原则:
-
动态调度:根据节点的实际资源使用率实现离线业务的动态调度
-
动态资源分配:根据在线业务的资源需求,动态调整分配给离线业务的资源量,动态更新资源隔离配置
-
插件化:基于Kubernetes的扩展机制开发,没有更改Kubernetes的任何一行核心代码,可将混部系统便捷交付到任何一个标准的Kubernetes集群中
-
业务零改造:将业务视为黑盒,不需要业务做任何的改造和适配
-
可运维、可观测:对用户和运维人员友好,可实时观测混部相关的各种监控图表,掌握集群的资源使用情况和混部系统的状态
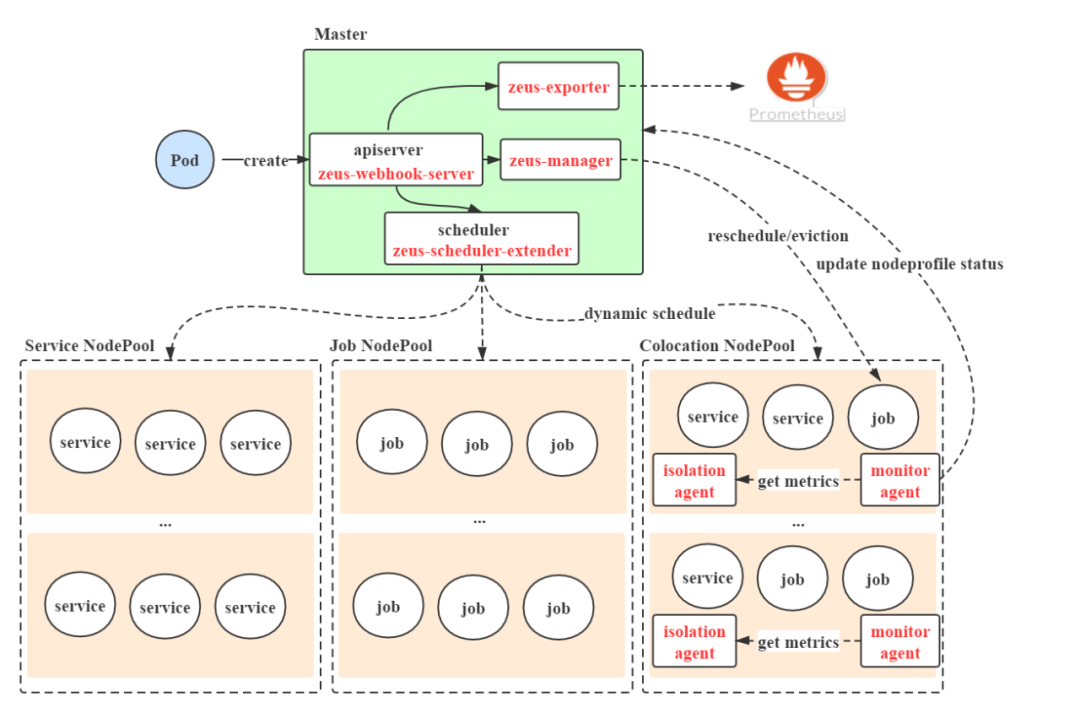
(图5 混部系统Zeus的架构设计)
3.2.1 Node资源池划分
我们将Node划分为三种类型,放到三个不同的Node资源池中:
-
在线资源池:设置了label colocation.netease.com/node-pool: service的node,只能调度在线业务上来
-
离线资源池:设置了label colocation.netease.com/node-pool: job的node,只能调度离线业务上来
-
混部资源池:设置了label colocation.netease.com/node-pool: colocation的node。可以混合调度在/离线业务上来
混部之前只有在线资源池和离线资源池,在线业务和离线业务运行在不同的Node上。混部肯定不是一蹴而就的,用户不可能一开始就把所有的业务、所有的服务器进行混部。为了支持用户逐步接受和应用混部技术,我们额外添加了一个新的混部资源池。用户可以根据自己的需求,控制什么时间迁移多少服务器到混部资源池,服务器也可以在各个资源池之间很方便的进行迁移,从而控制好混部的进度和风险。
随着混部系统的不断成熟和用户对混部接纳度的提高,逐步缩小在线资源池和离线资源池,增大混部资源池。当然,可能也存在极个别的在线业务无法进行混部,那就部署到在线资源池即可,不一定要求所有的业务进行混部。
3.2.2 定义离线资源
离线资源是指node上可以分配给离线业务使用的资源,这里主要指CPU和memory。我们自定义两种扩展资源colocation/cpu和colocation/memory(分别对应原生的cpu和memory),实现离线任务的动态调度。之所以添加这两个扩展资源主要有三个原因:
-
在/离线业务的调度不会因为 cpu/memory 资源问题而互相影响。即不会存在Node上调度的离线任务申请了太多资源,而影响到在线业务的正常调度
-
我们可以根据节点的负载动态更新colocation/cpu和colocation/memory的capacity,即动态调整分配给离线业务的资源量
-
离线业务因为没有申请cpu/memory,所以会被归类到besteffort qos class。从而在发生Kubelet Eviction时,离线任务会优先被驱逐
这两个扩展资源(colocation/cpu 和 colocation/memory)对用户来说是透明的,用户创建离线业务时,实际还是申请的cpu和memory资源。我们通过webhook的方式拦截Pod的创建请求,自动帮用户完成资源请求的转换。
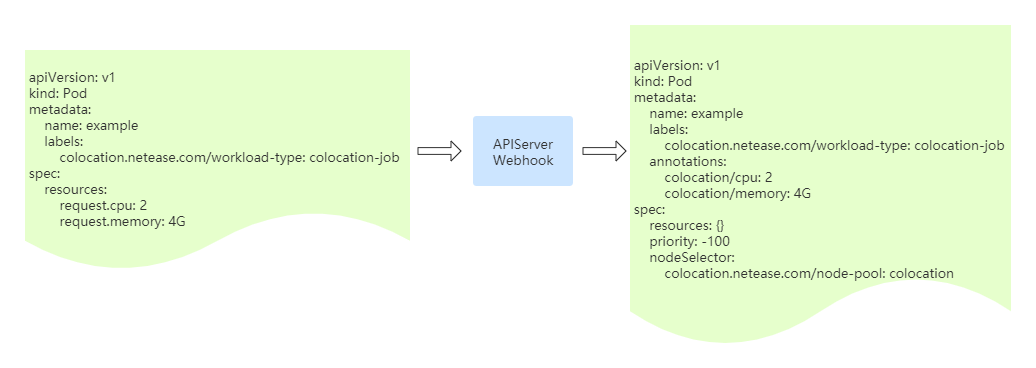
(图6 zeus-webhook-server拦截Pod创建请求,更改字段)
3.2.3 动态调度离线任务
针对kubernetes静态调度的问题,我们提出基于节点实际负载实现动态调度离线任务的机制。该动态调度机制利用监控组件实时绘制节点和业务的资源画像,扩展调度器基于节点和业务的资源画像信息,采用基于时间滑动窗口的动态加权算法计算并选择“最优”的候选调度节点(当前和未来一段时间负载较低的节点),进而将离线任务调度到该节点上从而提高服务器资源使用率并使得节点之间负载更加均衡。
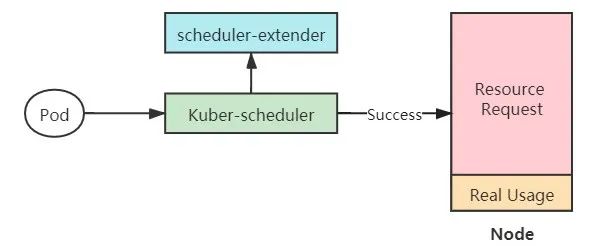
(图7 基于Kubernetes scheduler extender 实现动态调度)
-
可以控制每个节点允许调度离线任务的时间段,比如只允许在每天的凌晨0-6点混部
-
可以控制每个节点最多调度几个离线任务
-
可以动态自适应地调整每个node上可以分配给离线任务的资源量
-
将离线任务优先调度到负载较低、空闲资源较多的节点上
-
如果该节点近期内发生过离线任务的驱逐,那么短时间内不允许再调度离线任务上来,避免颠簸
3.2.4 离线任务的重调度
存在这样一种场景,刚开始时混部节点上的在线业务较少或者流量较小,能够分配给离线业务的资源较多,因此用户能够调度较多的离线业务上去。但是,后来用户调度了更多的在线业务上来或者在线业务的流量飙升,导致节点上能够给离线业务的资源迅速减少,离线任务执行效率会降低。假如此时,其他混部节点比较空闲,为了避免离线任务的饥饿,我们会重调度离线任务到其他node上。
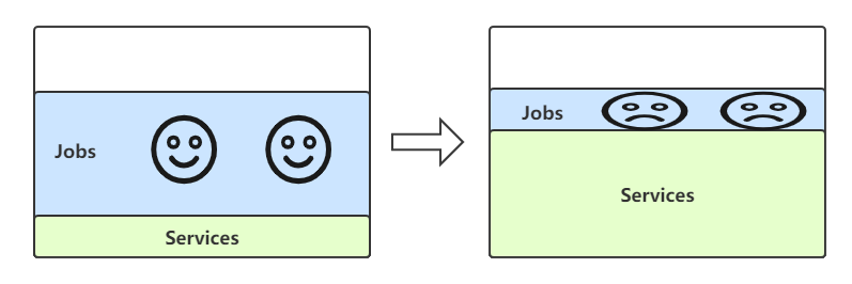
(图8 离线任务的重调度)
离线任务的重调度,主要有如下优点:
-
均衡各个混部节点的负载情况
-
避免某个节点负载过高,避免影响在线业务性能和稳定性
-
提高离线业务的执行效率
但是,重调度也有缺点,如果离线任务没有远程checkpoint机制,会导致重调度之前的算力被浪费,甚至导致整个任务计算失败。影响程度有多大,跟单个任务的处理时长有关系的。如果处理一个任务的时长是秒级,那么重调度的影响是微乎其微的。如果处理一个任务的时长是天级别的,那么重调度的影响还是比较大的。因此,是否使用重调度功能,重调度的触发阈值等,用户都是可以根据业务场景灵活配置的。
3.2.5 动态资源分配和多维度资源隔离
每个Node上分别分配给在线业务和离线业务多少资源,是根据在线业务的资源需求,动态自适应的调整的,而非一个静态的配置。
在线业务负载比较小,空闲资源比较多,那么我们分配给离线业务的资源就会比较多,即Node的离线资源容量会比较大;在线业务负载比较高,那么我们分配给离线业务的资源就会比较少,即Node的离线资源容量会比较小。
离线资源容量的计算公式如下:
ColocationResourceCapacity = Max(Allocatable * 最大利用率 - 在线业务使用量, minGuaranteedResource)其中最大利用率是一个混部系统配置变量,用户可以根据实际情况进行配置,通过最大利用率来控制分配给离线业务多少资源。比如一个混部节点的cpu capacity为56核,allocatable为55核,该节点上的在线业务实际使用了10核,并且配置该节点的CPU最大利用率配置为50%,离线业务的最低资源保证为2核,则该混部节点的colocation/cpu的capacity为:
Capacity of colocation/cpu = Max( 55*50% - 10 , 2 ) = 12.5 核在具体实现时,我们会参考Node的历史负载,计算方式会比上述更加复杂一些,但是基本原理就是这样。
资源隔离方面,我们开发了一个isolation-agent 运行在每个Node上,该组件通过分析业务和Node的资源画像信息,动态更新CGroups配置,实现了服务器上多种共享资源的隔离和限制。

(图9 资源隔离框架)
CPU资源隔离:
我们支持多个CPU隔离策略,以达到不同业务场景下更好的隔离效果:
-
因为离线任务被归类到BestEffort class,其cgroup cpu.shares=2。当cpu繁忙时,分配给离线任务的时间片较少
-
设置离线任务的CPU调度类为 sched_idle
-
在线业务和离线业务分别运行在两个不同的cpuset中
-
在线业务不绑核,离线业务绑核。因为某些类型的在线业务需要高并发,运行在所有的cpu核上有利于提高其性能
-
在线业务和离线业务运行在两个不同的numa node上
内存资源隔离:
-
设置cgroup memory.limit_in_bytes 限制内存使用上限
-
在/离线业务配置不同的pagecache回收优先级,当触发全局的pagecache回收时,优先回收离线任务的pagecache
-
受限于硬件特性,目前我们还不支持内存带宽的限制等
-
我们的内核组同学正在开发pagecache的后台主动回收机制
L3 cache隔离:
-
在/离线业务不会调度到同一个物理核上,因此实现L1/L2 cache的隔离
-
如果使用了numa 隔离策略,在/离线业务运行在不同的numa node上,那么就能做到L1/L2/L3 cache的隔离
-
我们基于Intel RDT-CAT缓存分配技术,实现了离线任务的L3 cache隔离,限制离线任务使用L3的大小
网络隔离:
在/离线流量划分了不同的优先级(配置不同的DSCP标记),针对不同类型的流量配置分级担保和限速策略,交换机在转发网络包时优先转发在线业务的网络包,当发生网络拥塞时优先丢弃离线业务网络包,实现全链路网络QoS。
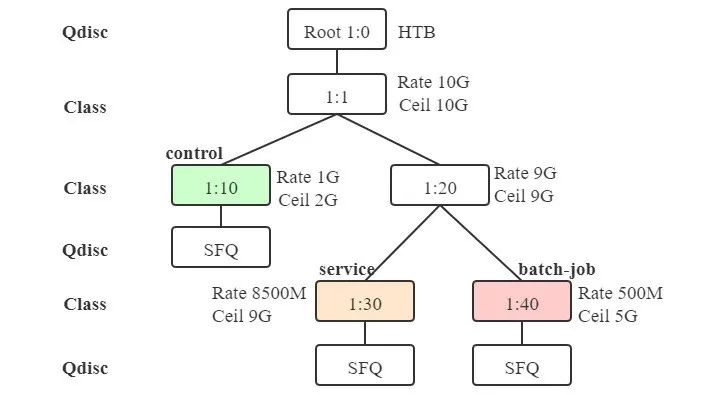
(图10 网络流量担保和限速)
我们也正在基于cgroupv2 开发更加完善的资源隔离功能,比如buffer io的隔离、内存pagecache的隔离等。不过这个特性需要高版本的Kubernetes和Linux内核。
跨集群全局资源调度 KubeMiner
作为基础设施服务提供方,我们在运维管理集团内部各个业务方的Kubernetes集群时,在资源方面发现几个突出的问题:
-
Kubernetes集群数量众多,每个业务部门有多个测试和生产集群,资源碎片化,缺乏统筹规划
-
测试集群的计算资源没有得到有效利用,浪费比较严重
-
不同的Kubernetes集群资源利用率严重不均衡。有的业务部门缺乏算力,经常找我们内部协调机器或者使用公有云;而有的业务部门服务器资源利用率很低,有大量的空闲算力
-
在线业务的Kubernetes集群资源利用率较低,资源浪费严重;而离线业务的Kubernetes集群资源利用率较高,缺乏足够算力
-
在线业务部门存在大促、重大运营活动等业务需求,临时需要大量的算力。而某些离线业务通常能够容忍短期停跑,让出资源
针对这些痛点,我们研发了KubeMiner服务,通过技术手段解决企业组织架构等原因导致的不同部门之间服务器资源隔阂问题,实现集团层面的服务器资源全局调度。整个方案对用户完全透明,用户不需要做任何业务改造,用户可以像使用本集群的资源一样去使用其他集群的资源。
KubeMiner的更多技术细节,会在后续另一篇文章中专门介绍。
落地进展
本系统和方案已经成功落地到传媒、严选、音乐等互联网业务。目前提供离线算力达到数万核,服务器平均 CPU 使用率从小于15%提高到55%以上。
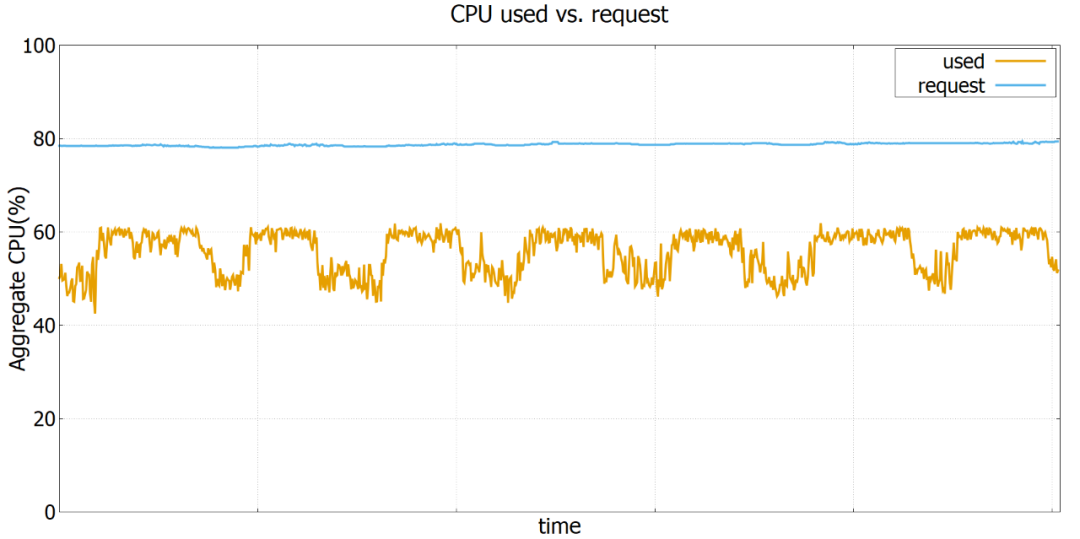
未来规划
业务上,我们会继续推广在/离线业务混部、扩大混部规模,希望将本项目的研究成果和实践经验应用到网易集团内其他事业部,通过技术手段解决服务器资源利用率较低和企业组织架构导致的不同部门之间服务器资源隔阂的问题,实现集团层面的服务器资源全局调度,实现更大规模的降本增效收益。
技术上,我们会从以下几个方面继续演进我们的混部系统:
-
监控:基于ebpf等技术,实现 Pod/Deployment/Node 级别更加细粒度的监控,提高可观测性。比如CPU调度时延、CPU就绪队列长度、网络重传次数、上层协议用户请求时延(http、grpc、redis、kafka …)等
-
隔离:推动基础网络架构的升级演进;推动高版本内核的落地,充分利用高版本内核提供的资源隔离能力;对操作系统调度算法进行持续优化
-
调度:基于历史负载数据,预测在线业务的资源需求,优化调度优选算法和资源分配策略
岚清,网易数帆轻舟事业部技术专家,负责容器网络编排、在/离线业务混部、云原生可观测性体系建设等多个项目。目前专注于分布式系统架构、云原生可观测性等技术领域。

本文转载自岚清 网易有数,原文链接:https://mp.weixin.qq.com/s/O_eMEpNNou_huDKOnrikvQ。