
简介
随着 Lakehouse 的日益普及,人们对分析和比较作为该数据架构核心的开源项目的兴趣日益浓厚:Apache Hudi、Delta Lake 和 Apache Iceberg。
目前发表的大多数比较文章似乎仅将这些项目评估为传统的仅附加工作负载的表/文件格式,而忽略了一些对现代数据湖平台至关重要的品质和特性,这些平台需要通过连续的表管理来支持更新繁重的工作负载。本文将更深入地介绍 Apache Hudi 的技术差异以及它如何成为一个成熟的数据湖平台,领先于其他平台。
特性比较
首先让我们看一个整体的功能比较。在您阅读时,请注意 Hudi 社区如何在湖存储格式之上投入巨资开发综合平台服务。虽然格式对于标准化和互操作性至关重要,但表/平台服务为您提供了一个强大的工具包,可以轻松开发和管理您的数据湖部署。


特性亮点
当然,构建数据湖平台不仅仅是功能可用性的复选框。让我们选择上面的一些差异化功能,用简单的英语深入研究用例和真正的好处。
增量管道
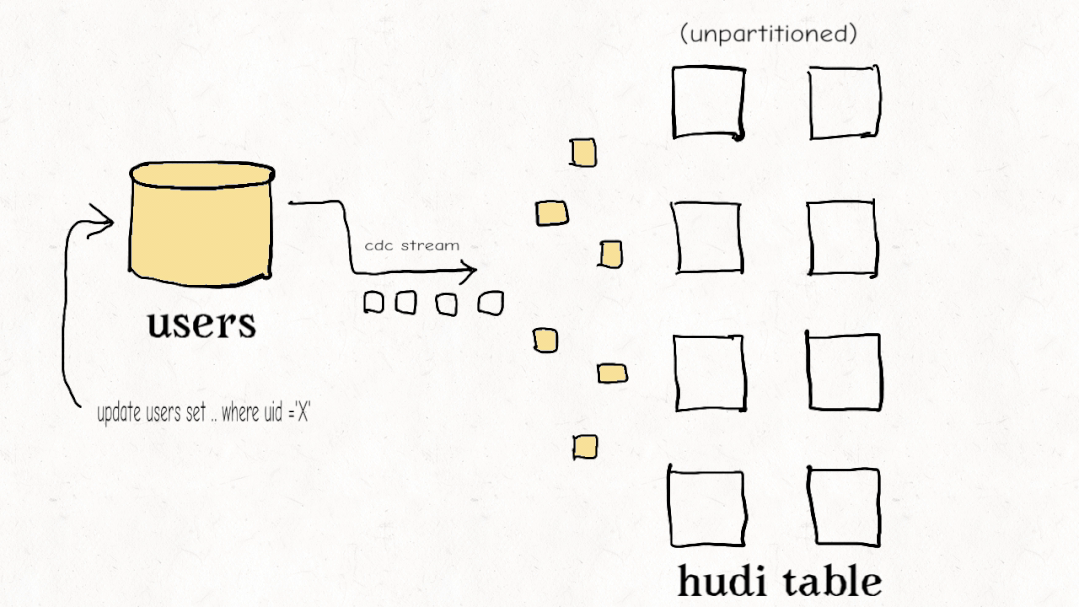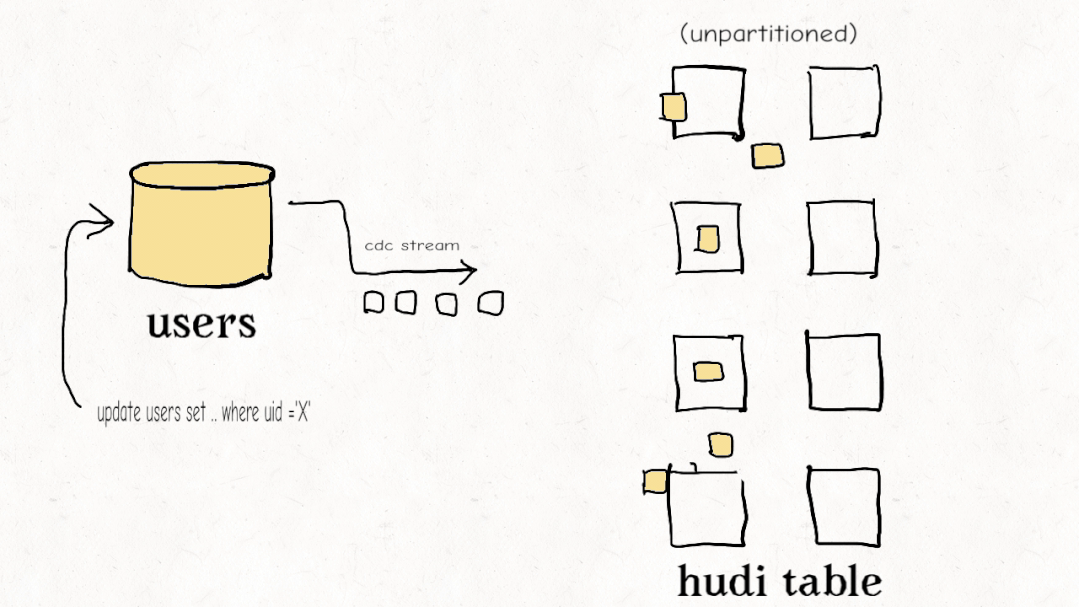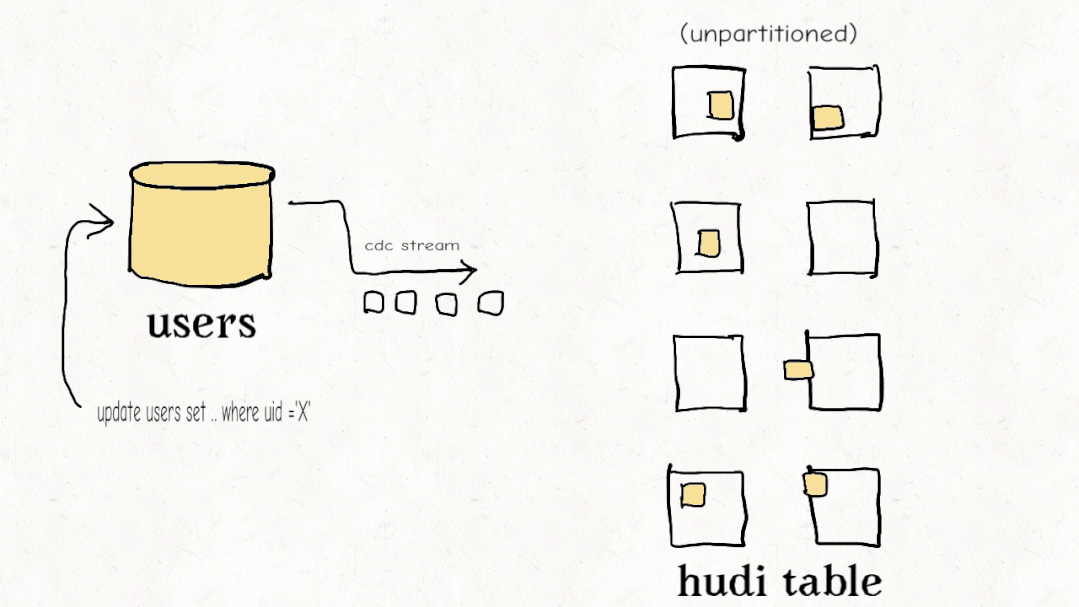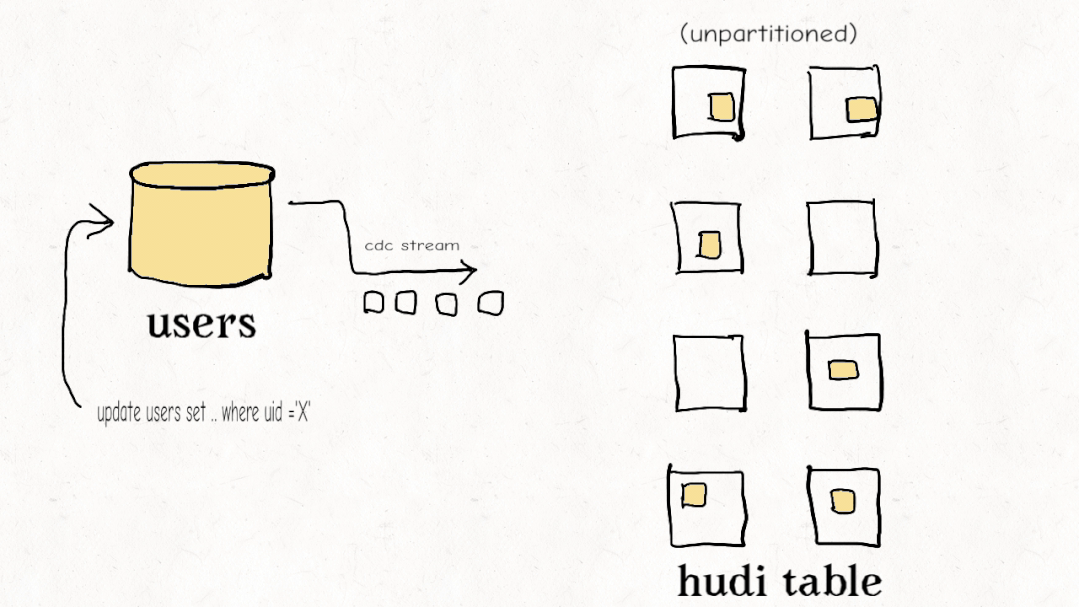
今天的大多数数据工程师都觉得他们必须在流式处理和老式批处理 ETL 管道之间做出选择。Apache Hudi 开创了一种称为增量管道的新范例。开箱即用,Hudi 跟踪所有更改(追加、更新、删除)并将它们公开为更改流。使用记录级索引,您可以更有效地利用这些更改流来避免重新计算数据并仅以增量方式处理更改。虽然其他数据湖平台可能会提供一种增量消费更改的方式,但 Hudi 的设计初衷是为了有效地实现增量化,从而以更低的延迟实现具有成本效益的 ETL 管道。
Databricks 最近开发了一个类似的功能,他们称之为Change Data Feed,他们一直持有该功能,直到最终在 Delta Lake 2.0 中开源。Iceberg 有增量读取,但它只允许您读取增量附加,没有更新/删除,这对于真正的变更数据捕获和事务数据至关重要。
并发控制
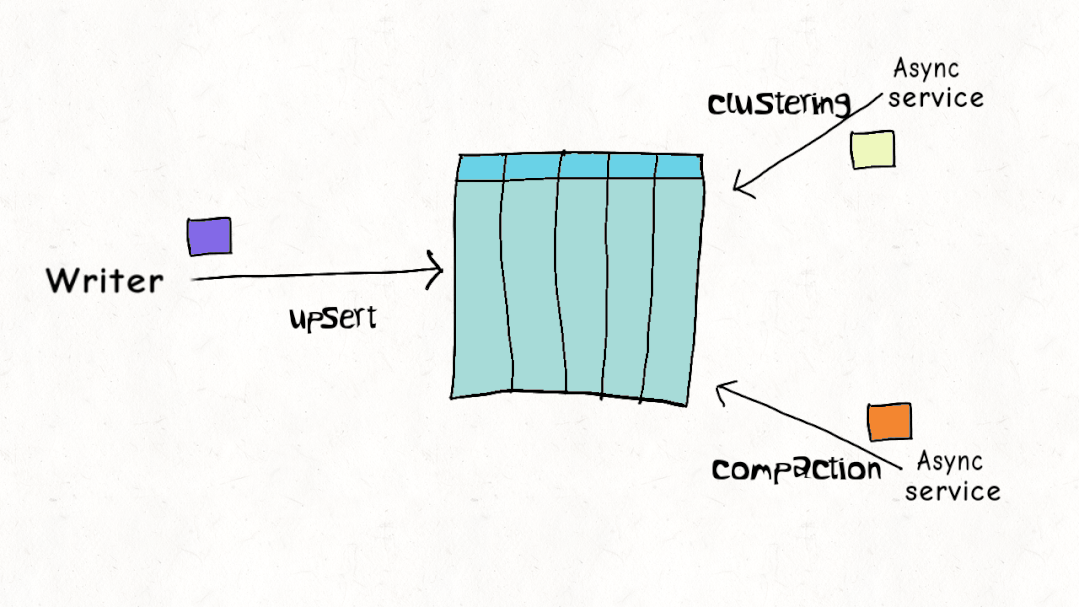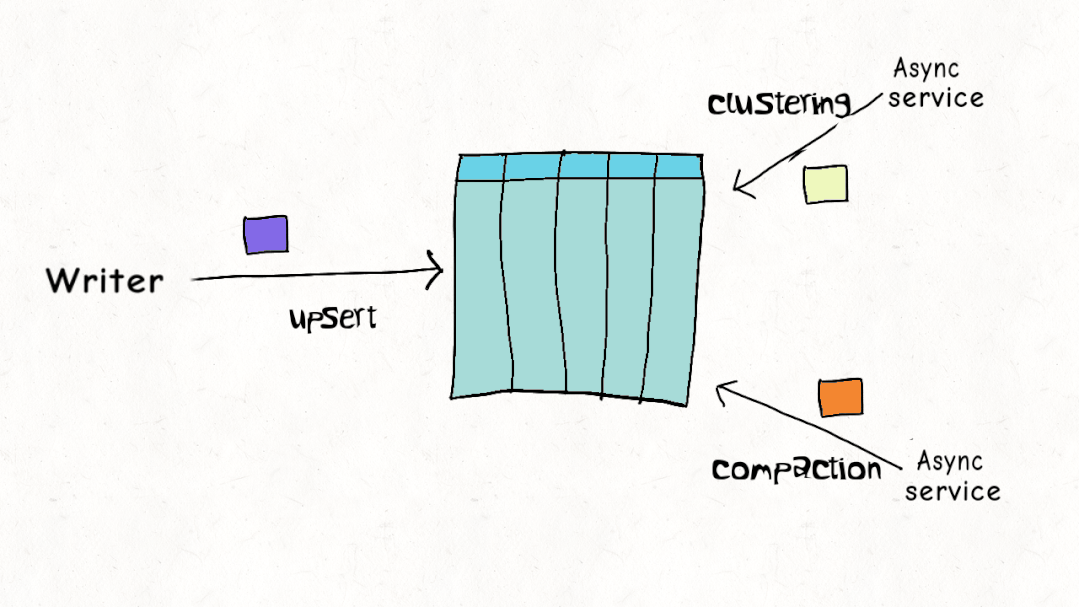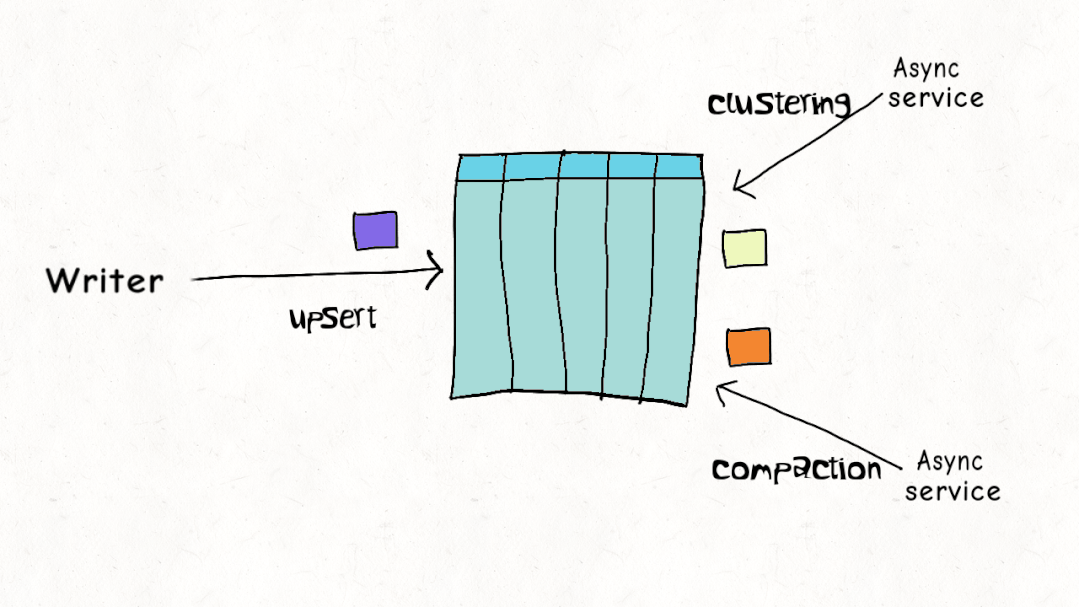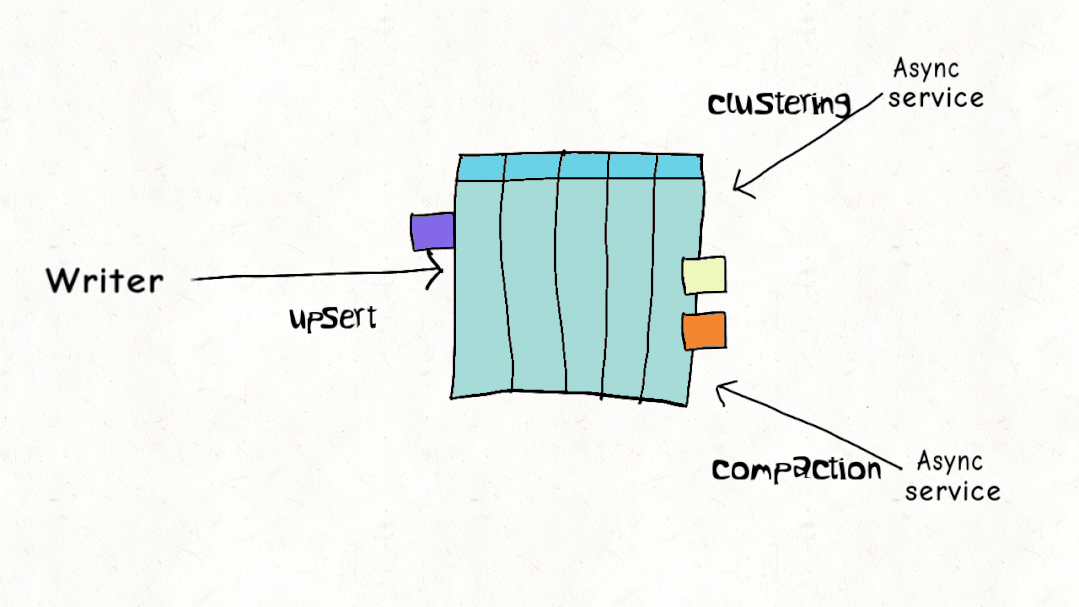
ACID 事务和并发控制是 Lakehouse 的关键特征,但与现实世界的工作负载相比,当前的设计实际上是如何叠加的?Hudi、Delta 和 Iceberg 都支持乐观并发控制(OCC)。在乐观并发控制中,编写者检查他们是否有重叠的文件,如果存在冲突,他们就会使操作失败并重试。以 Delta Lake 为例,这只是一个 Apache Spark 驱动程序节点上的 JVM 级别锁,这意味着直到最近,您在单个集群之外还没有 OCC 。
虽然这可能适用于仅附加的不可变数据集,但乐观并发控制在现实世界场景中遇到困难,由于数据加载模式或重组数据以提高查询性能,因此需要频繁更新和删除。通常,让编写器离线以进行表管理以确保表的健康和高性能是不切实际的。Apache Hudi 并发控制比其他数据湖平台(文件级别)更精细,并且针对多个小更新/删除进行了优化的设计,在大多数现实世界的情况下,冲突的可能性可以大大降低到可以忽略不计。您可以在此博客中阅读更多详细信息,如何在多写入器场景中使用异步表服务进行操作,而无需暂停写入器。这非常接近标准数据库支持的并发级别。
Merge on Read
任何好的数据库系统都支持写入和查询性能之间的不同权衡。Hudi 社区在为整个行业的数据湖存储定义这些概念方面做出了一些开创性的贡献。Hudi、Delta 和 Iceberg 都将数据写入和存储在 parquet 文件中。发生更新时,这些 parquet 文件会进行版本控制和重写。这种写模式模式就是业界现在所说的写时复制 (CoW)。此模型非常适合优化查询性能,但可能会限制写入性能和数据新鲜度。除了 CoW,Apache Hudi 还支持另一种表存储布局,称为Merge On Read(铁道部)。MoR 使用列式 parquet 文件和基于行的 Avro 日志文件的组合来存储数据。更新可以在日志文件中批量处理,以后可以同步或异步压缩到新的 parquet 文件中,以平衡最大查询性能和降低写入放大。
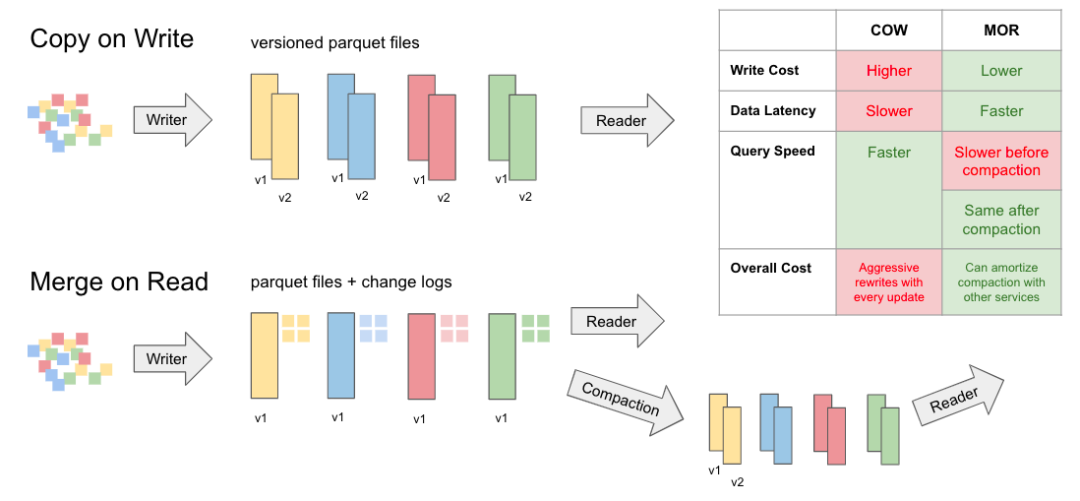
因此,对于近乎实时的流式工作负载,Hudi 可以使用更高效的面向行的格式,而对于批处理工作负载,hudi 格式使用可矢量化的面向列的格式,并在需要时无缝合并两种格式。许多用户转向 Apache Hudi,因为它是唯一具有此功能的项目,可让他们实现无与伦比的写入性能和 E2E 数据管道延迟。
分区演进
Apache Iceberg 经常强调的一个特性是隐藏分区,它解锁了所谓的分区演化。基本思想是当您的数据开始演变,或者您只是没有从当前分区方案中获得所需的性能价值时,分区演变允许您更新分区以获取新数据而无需重写数据。当你进化你的分区时,旧数据会留在旧的分区方案中,只有新数据会随着你的进化而分区。如果用户不了解演化历史,则以多种方式分区的表会将复杂性推给用户,并且无法保证一致的性能。

Apache Hudi 采用不同的方法来解决随着数据随着集群的发展而调整数据布局的问题。您可以选择粗粒度的分区策略,甚至不分区,并在每个分区内使用更细粒度的集群策略。集群可以同步或异步运行,并且可以在不重写任何数据的情况下进行演进。这种方法可以与Snowflake的微分区和集群策略相媲美。
多模式索引

索引是数据库和数据仓库不可或缺的组成部分,但在数据湖中基本上不存在。在最近的版本中,Apache Hudi 为 Lakehouse 创建了首创的高性能索引子系统,我们称之为Hudi 多模式索引。Apache Hudi 提供了一种异步索引机制,允许您在不影响写入延迟的情况下构建和更改索引。这种索引机制具有可扩展性和可扩展性,可以支持任何流行的索引技术,例如 Bloom、Hash、Bitmap、R-tree 等。
这些索引存储在Hudi 元数据表中,该表存储在数据旁边的云存储中。在这个新版本中,元数据以优化的索引文件格式编写,与 Delta 或 Iceberg 通用文件格式相比,点查找的性能提高了 10-100 倍。在测试真实世界的工作负载时,这个新的索引子系统可将整体查询性能提高 10-30 倍。
摄取工具
数据平台与数据格式的不同之处在于可用的运营服务。Apache Hudi 的一个与众不同之处是名为DeltaStreamer的强大摄取实用程序。DeltaStreamer 经过实战测试并在生产中使用,以构建当今地球上一些最大的数据湖。DeltaStreamer 是一个独立的实用程序,它允许您从各种来源(如 DFS、Kafka、数据库更改日志、S3 事件、JDBC 等)增量摄取上游更改。
Iceberg 没有托管摄取实用程序的解决方案,而 Delta Autoloader 仍然是 Databricks 的专有功能,仅支持 S3 等云存储源。
User Cases: 来自社区的案例
功能比较和基准测试可以帮助新手确定可用的技术选择,但更重要的是评估您的个人用例和工作负载,以找到适合您的数据架构的合适方式。所有这三种技术,Hudi、Delta、Iceberg,对于某些用例都有不同的起源故事和优势。Iceberg 诞生于 Netflix,旨在解决文件列表等云存储规模问题。Delta 诞生于 Databricks,它在使用 Databricks Spark 运行时具有深度集成和加速功能。Hudi 诞生于 Uber,旨在为近乎实时的 PB 级数据湖提供支持,并提供无痛的表管理。
经过多年在社区中参与现实世界的比较评估,当您拥有超越简单的仅附加插入的成熟工作负载时,Apache Hudi 通常具有技术优势。一旦您开始处理许多更新、开始添加真正的并发性或尝试减少管道的 E2E 延迟,Apache Hudi 就会在性能和功能集方面成为行业领导者。
以下是来自社区的几个示例和故事,他们独立评估并决定使用 Apache Hudi:
亚马逊Package Delivery System
“ATS 面临的最大挑战之一是处理 PB 级数据,需要以最小的时间延迟进行持续的插入、更新和删除,这反映了真实的业务场景和数据包向下游数据消费者的移动。”
“在这篇文章中,我们展示了我们如何以每小时数百 GB 的速度实时摄取数据,并使用使用 AWS Glue Spark 作业和其他方法加载的Apache Hudi表在 PB 级数据湖上运行插入、更新和删除操作。AWS 无服务器服务,包括 AWS Lambda、Amazon Kinesis Data Firehose 和 Amazon DynamoDB”
字节跳动/抖音
“在我们的场景中,性能挑战是巨大的。单表最大数据量达到400PB+,日增量为PB级,总数据量达到EB级。”
“吞吐量比较大。单表吞吐量超过100GB/s,单表需要PB级存储。数据模式很复杂。数据是高维和稀疏的。表格列的数量范围从 1,000 到 10,000+。而且有很多复杂的数据类型。”
“在决定引擎时,我们检查了三个最流行的数据湖引擎,Hudi、Iceberg 和 DeltaLake。这三者在我们的场景中各有优缺点。最终选择Hudi作为存储引擎是基于Hudi对上下游生态的开放性、对全局索引的支持,以及针对某些存储逻辑的定制化开发接口。”
沃尔玛
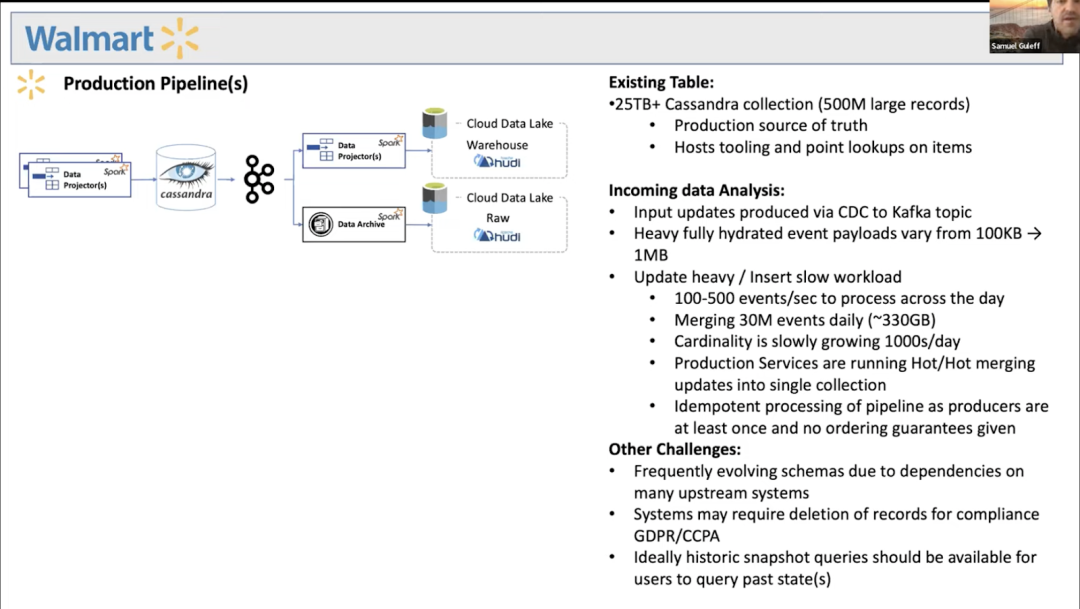
从视频转录:
“好吧,是什么让我们为我们提供了支持,为什么我们真的很喜欢在其他用例中解锁了这一功能的Hudi功能?我们喜欢我们可以使用的乐观并发或 mvcc 控件。我们围绕异步压缩做了很多工作。我们正在考虑对读取表的合并进行异步压缩而不是内联压缩。
我们还希望减少延迟,因此我们显着利用了读取表上的合并,因为这使我们能够更快地追加数据。我们也喜欢对删除的原生支持。这是我们为 ccpa 和 gdpr 之类的东西构建的自定义框架,有人会在其中放入服务台票,我们必须构建一个自动化流程来从 hdfs 中删除记录,这对我们来说是开箱即用的。
行版本控制非常重要,显然我们的很多管道都有乱序数据,我们需要显示最新的记录,因此我们提供版本密钥作为我们框架的一部分,用于将所有 upsert 插入到hudi 表中。
客户可以选择要保留多少行版本,从而能够提供快照查询并获得增量更新(例如过去五个小时内更新的内容),这一事实对很多用户来说真的很强大”
罗宾汉
“Robinhood 确实需要保持数据湖的低数据新鲜度。许多过去在市场时间之后或之前以每日节奏运行的批处理管道必须以每小时或更高的频率运行,以支持不断发展的用例。很明显,我们需要更快的摄取管道将在线数据库复制到数据湖。”
“我们正在使用Apache Hudi从 Kafka 增量摄取变更日志,以创建数据湖表。Apache Hudi 是一个统一的数据湖平台,用于在数据湖上执行批处理和流处理。Apache Hudi 带有一个功能齐全的基于 Spark 的开箱即用的摄取系统,称为 Deltastreamer,具有一流的 Kafka 集成和一次性写入功能。与不可变数据不同,我们的 CDC 数据有相当大比例的更新和删除。Hudi Deltastreamer 利用其可插入的记录级索引在 Data Lake 表上执行快速高效的 upserts。”
Zendesk
“数据湖管道将 Zendesk 高度分布式数据库中的数据整合到数据湖中进行分析。
Zendesk 使用 Amazon Database Migration Service (AWS DMS) 从 8 个 AWS 区域的 1,800 多个 Amazon Aurora MySQL 数据库中捕获变更数据 (CDC)。它使用 Amazon EMR 和Hudi检测事务更改并将其应用到数据湖。
Zendesk 票证数据包含超过 100 亿个事件和 PB 级数据。Amazon S3 中的数据湖文件以Apache Hudi格式进行转换和存储,并在 AWS Glue 目录中注册,可用作数据湖表,用于通过 Amazon Athena 进行分析查询和使用。”
GE航空
“在 AWS 中引入更无缝的Apache Hudi体验对我们的团队来说是一个巨大的胜利。我们一直忙于将 Hudi 整合到我们的 CDC 交易管道中,并且对结果感到非常兴奋。我们能够花更少的时间编写代码来管理我们的数据存储,而将更多的时间集中在我们系统的可靠性上。这对我们的扩展能力至关重要。随着我们接近另一个主要的生产切换,我们的开发管道已超过 10,000 个表和 150 多个源系统。”
最后,鉴于 Lakehouse 技术的发展速度有多快,重要的是要考虑该领域的开源创新来自何处。以下是一些起源于 Hudi 的基本思想和功能,现在正在被其他项目采用。
事实上,除了表元数据(文件列表、列统计信息)支持之外,Hudi 社区还开创了构成当今湖屋的大多数其他关键功能。在过去的 4 年里,该社区已经支持了 1500 多个用户问题和 5500 多个 slack 支持线程,并且正在以雄心勃勃的愿景迅速发展壮大。用户可以将这种创新记录视为未来的领先指标。
在为您的 Lakehouse 选择技术时,对您自己的个人用例进行评估非常重要。功能比较电子表格和基准测试不应该是最终的决定因素,因此我们希望这篇博文只是为您在决策过程中提供一个起点和参考。Apache Hudi 具有创新性,久经沙场,并且会一直存在。加入我们的Hudi Slack,您可以在其中提出问题并与来自全球的充满活力的社区合作。
如果您希望通过一对一咨询深入了解您的用例和架构,请随时通过info@onehouse.ai 联系。在 Onehouse,我们在设计、构建和运营世界上一些最大的分布式数据系统方面拥有数十年的经验。我们认识到这些技术很复杂且发展迅速。很可能我们错过了某个功能,或者可能在上述一些比较中错误地阅读了文档。如果您看到以上任何需要更正的比较,请给info@onehouse.ai 留言,以便我们在本文中保持事实的准确性。
本文转载自凯尔·韦勒 Flink,原文链接:https://mp.weixin.qq.com/s/J_a36noSfB3GoPXvN-lVdg。