
01 背景
2020年以来,半导体生产不足,这个问题困扰着全世界。互联网企业高度依赖于网络基础设施和服务器设施,没有半导体就没有满足个人需要的个人电子消费品,也就没有蓬勃发展的互联网行业。
哔哩哔哩作为一家以多媒体内容为核心服务的公司,亦高度依赖于企业级服务器设备,需要大量的服务器设备进行数据计算和数据存储。芯片荒引起采购周期的延长、采购数量的被动减少,甚至导致设备一机难求。随着大量人群了解B站、涌入B站、喜欢B站,在B站产生了大量的数据,哔哩哔哩对服务器数量的需求越来越高,一增一减之间,数据建设陷入了计算不够用、存储不够用的窘境。
02 数据分析
面临这种资源紧缺的困难,数据平台部对主站数仓的数据进行了多维度、全场景的统计分析。经过分类,得出以下四类数据:
-
日志型数据
-
业务型数据
-
手工产出数据
-
元数据
手工产出数据和元数据对于大数据体系来说,数据量一般很小,对计算资源的需求也不多。数据占比更多的是日志型数据和业务型数据。
对于日志型数据,又分为客户端日志和服务端日志,但无论哪类日志,一般来说均属于增量类、静态类数据,一旦产生即不会对数据本身进行再次变更。
对于业务型数据,主要来源于业务数据库中的生产数据,即传统的会进行DDL、DML等操作的数据,会频繁的进行增删改查。在数据仓库使用时,需要计算出最新状态,供下游使用。
03 全量分区表模式
经过对以上几类典型数据的调研和分析,并和各个互联网企业进行沟通和咨询,我们发现整个互联网行业,大量企业采用Ralph Kimall大师的维度建模方法论为指导。对于业务型数据,为了便于ETL使用、便于分析使用,基本上都做成全量分区表的模式。
对于刚刚开始建设数据仓库的团队,一般会永久保存,如果受限于存储容量,会写crontab任务定期删除最早的历史分区。对于数据仓库建设成熟的团队,一般会有专门的数据治理团队负责数据的治理,对接数据开发同学确定数据的生命周期,并对全量分区表制定自动化策略,命中策略后自动删除数据。
全量分区表:
表按照T-1进行创建分区,分区值一般为数据生产时的昨天,如数据在2022-02-26 01:02:03.456生产完成,则分区值为2022-02-25;每个分区存储自数据生产当日00:00:00.000以前的全量数据,即2022-02-26 00:00:00.000以前的全量数据。
目前,哔哩哔哩数据平台部已步入成熟的数据建设阶段,也会有专门的数据治理团队进行治理,把全量分区表的生命周期配置为永久或固定时间周期,在资源充足的背景下,数据仓库开发生产数据、下游任务消费数据均简单和成熟,业内也都是这么做的。
但是当资源紧张时,这种模式的缺点会被快速放大:
-
数据存储浪费严重。
对于没有变化的数据,数据在全量分区表的每一份分区中都存储一份,会存在重复存储问题,当数据变化率低时重复存储比例大大增大。
-
数据存在丢失的问题
这与数据仓库的基本理念不符。如果定期删除全量分区表的最早历史分区,在进行数据分析时,无法满足“随时间变化的”、“ 信息本身相对稳定的”。
数据仓库是一个面向主题的、集成的、随时间变化的、信息本身相对稳定的数据集合,用于对管理决策过程的支持。
针对以上场景,从技术上考量,第一种方案是上文所述的全量分区表,按照离线模式T-1同步增量数据到数据仓库,然后T-2的全量数据并上T-1的增量数据,生产出最新的T-1全量数据,整个链路均为离线链路。具有时效低、性能高、吞吐大的特点。


SQL伪代码如下:
insert overwrite table 目 标 表 partition (分 区 = 昨 天)
select
字 段 列 表
from(
select
字 段 列 表,
row_number() over(
partition by 主 键 列 表
order by
更 新 字 段 desc
) as rn
from
(
select
字 段 列 表
from
增 量 表
where
分 区 = 昨 天
union all
select
字 段 列 表
from
全 量 表
where
分 区 = 前 天
) n
) t
where
rn = 1
第二种方案是现阶段很热的数据湖,比如Hudi,结合Flink CDC,基于Mysql的binlog实时记录收集数据新增、更新等信息,实时更新数据到最新状态。
在初始化时,以离线模式批量从数据库中拉取全量数据,初始化到Hudi表中;订阅数据库的增量数据,增量更新到Hudi表中。数据以分钟级的延迟和数据库保持完全一致。
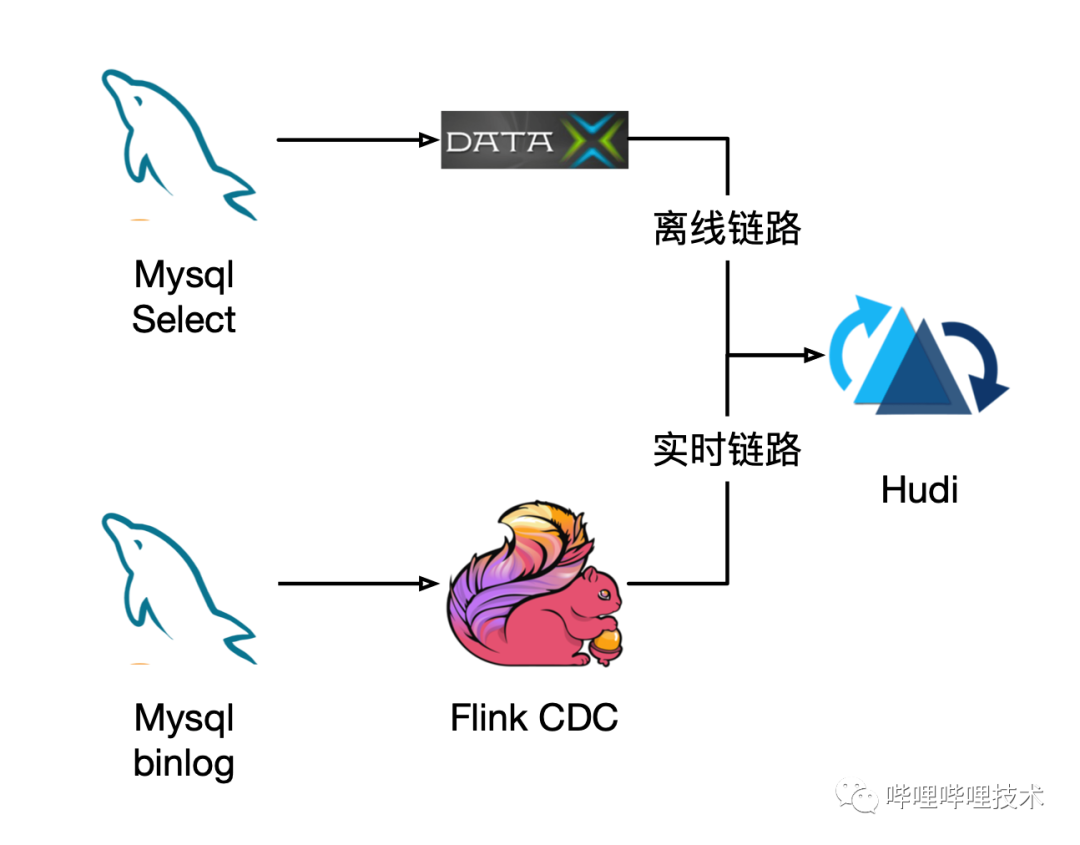
具有时效高、性能中、吞吐中的特点。经过基准性能测试,日新增、变更低于1000万条的数据,使用Hudi+Flink CDC可以较好的实现数据的合并,生产出数据的准实时数据。对于数据的历史所有变更的全版本存储功能现有社区功能还需要继续完善。
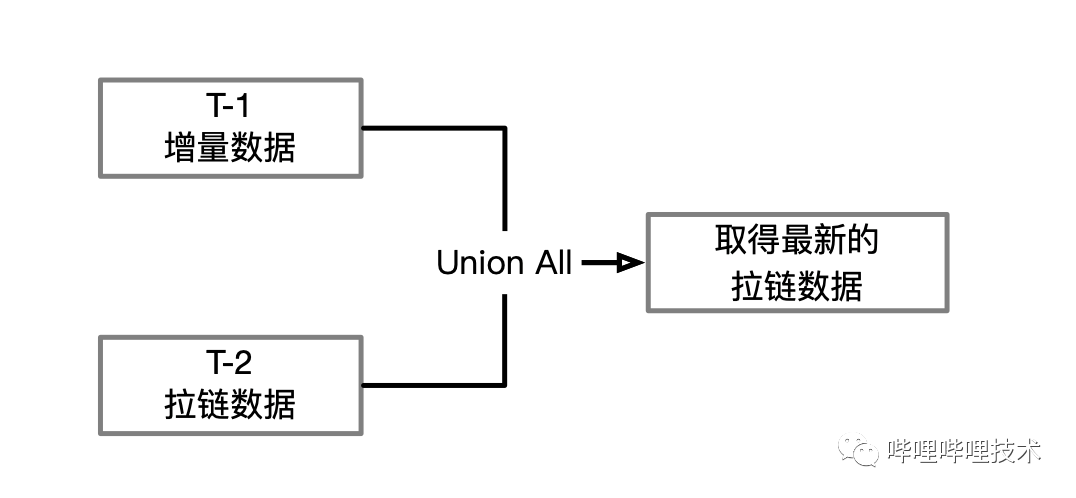
从业务上考量,第三种方案是数据仓库模型设计上拉链表的概念,通过记录历史所有数据的状态和数据的生命周期,保留所有的数据快照。从语义上和技术实现上来看,这和第一种方案的全量分区表可以保证完全一致,数据可以做全等校验和检测,下游用户迁移时,可以无缝进行迁移,缩短全量分区表的生命周期时,下游用户无感知。
04 基于拉链表的全量表优化方案
基于以上几种方案,数据团队和技术团队经过多次的沟通和讨论,推进第二种方案Hudi + Flink CDC和第三种方案拉链表支持研发。
Hudi+Flink CDC用于支持新型准实时需求类需求,对于时效性要求高的需求,比如需要分钟级的延迟,以Hudi+Flink CDC进行支持。
拉链表方案做存量全量分区表的无缝迁移,和支持离线T-1类的时效性要求较低的需求,以及需要历史所有变更的全版本下的支持。
拉链表:针对数据仓库设计中表存储数据的方式而定义的一种存储规范,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
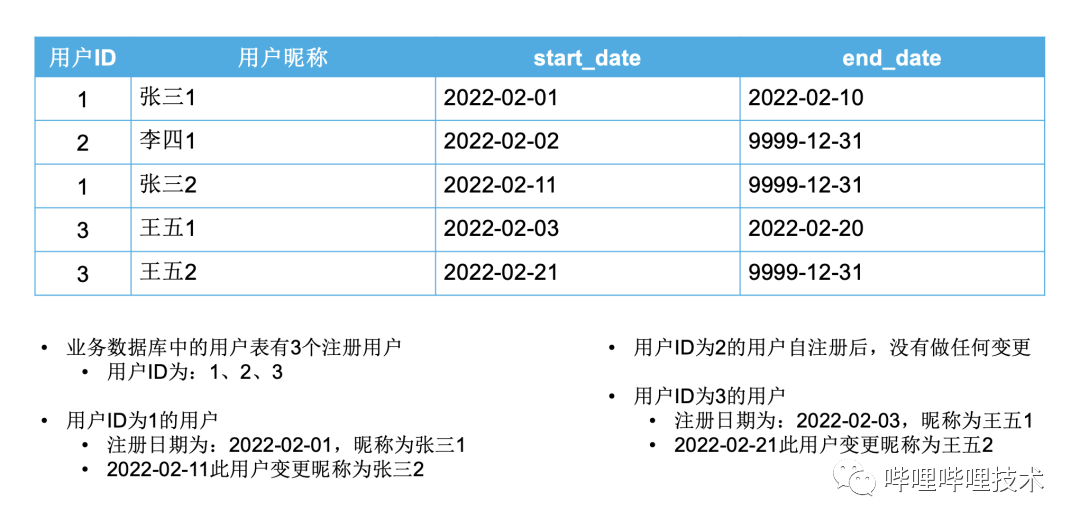
假设我们有一份用户表,里面有两个字段,第一个是用户ID,每个用户唯一且不变,第二个字段是用户昵称,用户可以自己任意更新自己的昵称。
经过对数据重复率和数据覆盖率测试,对比一年前的用户数据和最新的用户数据,重复率为9990‱(万分之)。即一年前的数据经过一年后,仅有10‱进行了变更。对于这种重复率的数据,我们可以对全量分区表拉链表化。
基于本项目对一份数据进行了拉链化测试,之前数据量1.20PB,拉链化后降低到5.06TB,优化率99.578%;每日产出任务的IO资源消耗由6.11TB+7.60GB降低到5.06TB+7.60GB,IO和计算资源的优化率均为17.16%。
拉链表生产的数据样例如下:
生产此拉链表的SQL为:
INSERT OVERWRITE TABLE 拉链表
SELECT
n1.id,
n1.昵称,
n1.start_date,
CASE
WHEN n1.end_date = '9999-12-31'
AND n2.id IS NOT NULL THEN '业务日期-1'
ELSE n1.end_date
END AS end_date
FROM 拉链表 n1
LEFT OUTER JOIN
(SELECT id FROM 用户表
WHERE 昨日新注册 OR 昨日变更昵称) n2 ON n1.id = n2.id
UNION ALL
SELECT id, 昵称, '业务日期' as start_date, '9999-12-31' as end_date
FROM 用户表
WHERE
昨日新注册 OR 昨日变更昵称
关于这个sql:
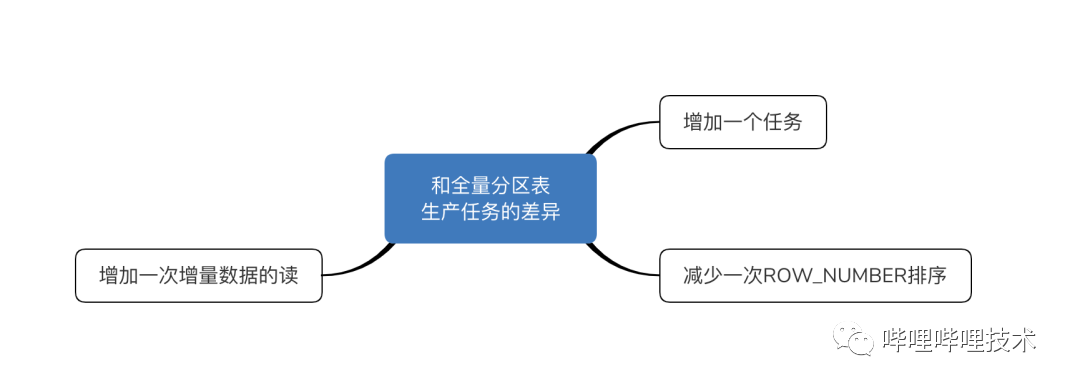
经过上述加工,可以生产出一份反应历史数据变化的拉链表数据。虽说大大降低了存储,但是有没有方案不增加增量数据的读取次数,且不增加任务数?通过对拉链表的生产逻辑进行了深入分析,仅仅靠SQL是无法达到目的的,需要开发一个通用型的技术方案,下面讲述一下我们的思路,由于大数据系统最早以MapReduce发展起来的,本文所述的技术方案以MapReduce为基本框架,欢迎大家一起交流。
整个MapReduce的数据流如下:

上述MR生产拉链表数据时,相对于传统的拉链表生产SQL,仅需要一个任务、读取一次拉链表、读取一次增量数据,且不需要单独增加一步排序的步骤。在节省存储资源的同时,又能节省计算资源。
05 总结
对全量分区表进行拉链化,优化的技术方案不仅能降低存储,而且还能降低一定的计算资源。
后续我们会和大家聊聊如何进行拉链表的幂等化,如何高效地对数据进行覆盖率和重复率测试,预估全量分区表拉链化的收益以及有选择性地优化全量分区表等内容。
本期作者

董子平
哔哩哔哩资深开发工程师
负责B站主站数仓团队社区、数据安全运营,专注于数据仓库、数据安全的落地、应用和推广。
本文转载自数仓团队@哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/qeRkBfCWGPBOR6YSlaRvjg。