
vivo 互联网大数据团队-Zheng Xiaofeng
一、背景
Druid 是一个专为大型数据集上的高性能切片和 OLAP 分析而设计的数据存储系统。
由于Druid 能够同时提供离线和实时数据的查询,因此Druid最常用作为GUI分析、业务监控、实时数仓的数据存储系统。
此外Druid拥有一个多进程,分布式架构,每个Druid组件类型都可以独立配置和扩展,为集群提供最大的灵活性。
由于Druid架构设计和数据(离线,实时)的特殊性,导致Druid元数据管理逻辑比较复杂,主要体现在Druid具有众多的元数据存储介质以及众多不同类型组件之间元数据传输逻辑上。
本文的目的是通过梳理 Druid 元数据管理这个侧面从而进一步了解 Druid 内部的运行机制。
二、 Druid 元数据相关概念
2.1 Segment
Segment 是Druid管理数据的最基本单元,一个Datasource包含多个Segment,每个Segment保存着Datasource某个时间段的数据,这个特定时间段的数据组织方式是通过Segment的payload(json)来定义的,payload内部定义了某个Segment的维度,指标等信息。
同一个Datasource的不同Segment的payload信息(维度、指标)可以不相同,Segment信息主要包含下面几部分:
-
【时间段(Interval)】:用于描述数据的开始时间和结束时间。
-
【DataSource】: 用字符串表示,指定segment隶属于哪个Datasource。
-
【版本(Version)】:用一个时间表示,时间段(Interval)相同的Segment,版本高的Segment数据可见,版本低的Segment会被删除掉。
-
【Payload 信息】:主要包含了此Segment的维度和指标信息,以及Segment数据存在DeepStorage 位置信息等等。


segment主要组成部分

segment 内部数据样例
2.2 Datasource
Datasource相当于关系型数据库的表,Datasource的Schema是根据其可用的Segment动态变化的,如果某个Datasource没有可用的Segment(used=1),在druid-web的Datasource列表界面和查询界面看不到这个Datasource。
元数据库中druid_dataSource表并没有保存Schema信息,只保存了该Datasource对应 实时任务消费数据的偏移量信息,都说Druid的Datasource相当于关系型数据库的表,但是Druid中表(Datasource)Schema信息,并不是定义在druid_dataSource元数据表里。
那么在druid-web 页面上看到的Datasource 的Schema信息是怎么来的呢?
其实它是实时根据该Datasource下所有Segment元数据信息合并而来,所以DataSource的Schema是实时变化的,
这样设计的好处是很好的适应了Datasource维度不断变化的需求在 :
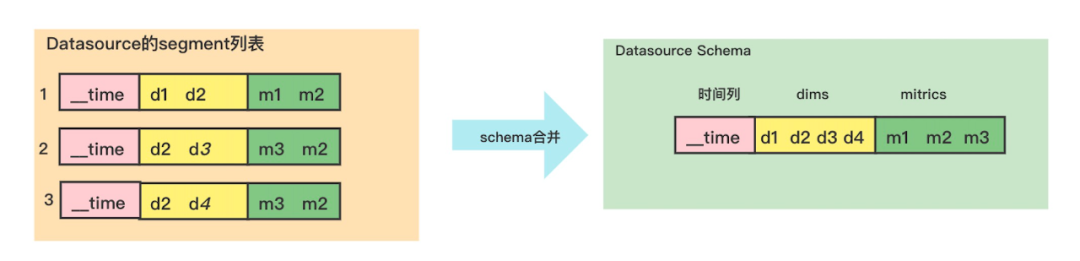
Schema的合并过程
2.3 Rule
Rule定义了Datasource的Segment留存规则,主要分两大类:Load和Drop。
-
Load 表示Segment 保留策略。
-
Drop 表示 Segment 删除策略。
Load/Drop规则均有三个子类,分别是Forever Load/Drop,Interval Load/Drop以及Period Load/Drop,一个Datasource包含1个或多个Rule规则,如果没有定义Rule规则就使用集群的Default Rule规则。
Datasource Rule规则列表是有序的(自定义规则在前面,集群默认规则在后面),在运行Run规则时,会对该Datasource下所有可用的Segment信息,按照Run规则的先后顺序进行判断,只要Segment满足某个Rule规则,后面的规则Rule就不再运行(如图:Rule处理逻辑案例)。Rule规则主要包含下面几部分信息:
-
【类型】:类型有删除规则和加载规则。
-
【Tier和副本信息】:如果是Load规则,需要定义在不同Tier的Historical机器副本数。
-
【时间信息】:删除或加载某个时间段的Segment。
Rule 样例如下:
[{"period": "P7D","includeFuture": true,"tieredReplicants": {"_default_tier": 1,"vStream":1},"type": "loadByPeriod"},{"type": "dropForever"}]
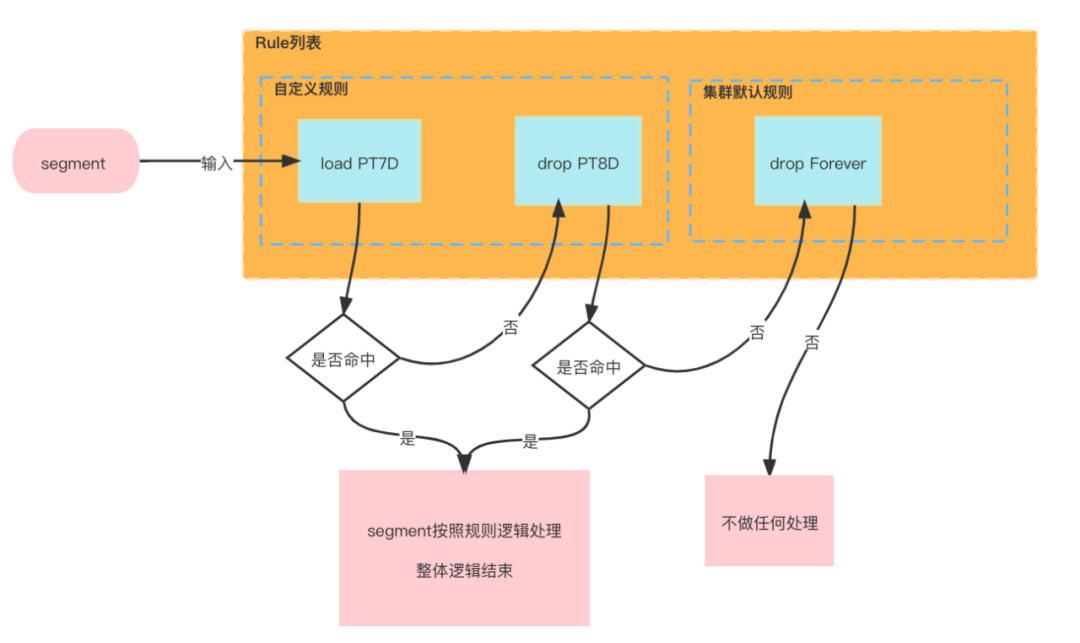
Rule处理逻辑案例
2.4 Task
Task主要用于数据的摄入(本文主要讨论实时摄入kafka数据的任务),在Task的运行过程中,它会根据数据时间列产生一个或者多个Segment,Task分为实时和离线任务。
实时任务(kafka)是Overload进程根据Supervisor定义自动生成;
离线任务(类型:index_hadoop,index_parallel)则需要外部系统通过访问接口方式提交。
每个任务主要包含下面几部分信息:
-
【dataSchema】:定义了该任务生成的Segment中有哪些维度(dimensionsSpec),指标(metricsSpec),时间列(timestampSpec),Segment粒度(segmentGranularity),数据聚合粒度(queryGranularity)。
-
【tuningConfig】:任务在摄入数据过程中的优化参数(包括Segment生成策略,索引类型,数据丢弃策略等等),不同的任务类型有不同的参数设置。
-
【ioConfig】:定义了数据输入的源头信息,不同的数据源配置项有所不同。
-
【context】:关于任务全局性质的配置,如任务Java进程的option信息。
-
【datasource】:表示该任务为那个Datasource 构造Segment。
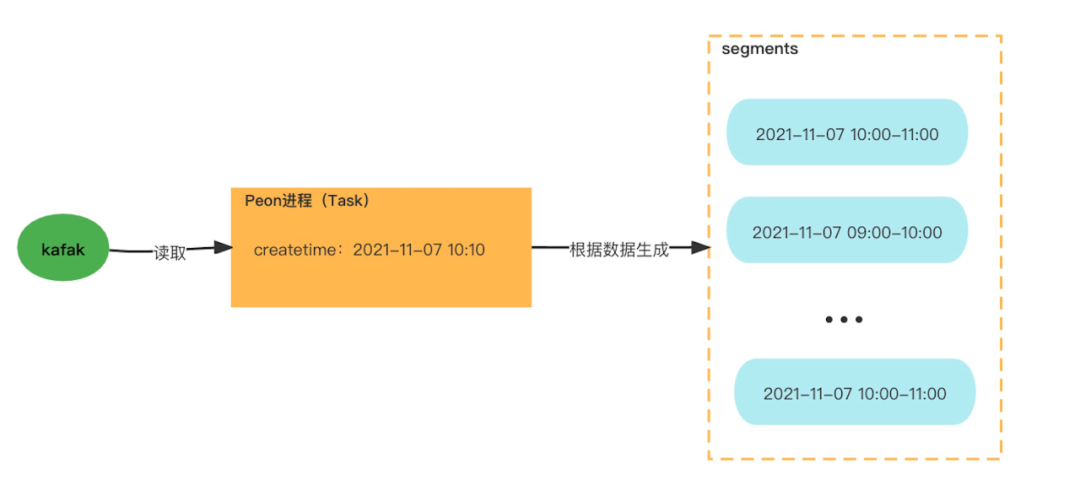
实时任务生成Segment案例
2.5 Supervisor
Supervisor 用于管理实时任务,离线任务没有对应的Supervisor,Supervisor与Datasource是一对一的关系,在集群运行过程中Supervisor对象由Overlord进程创建,通过Overlord接口提交Supervisor信息后,会在元数据库(MySQL)中持久化,Supervisor内容与Task相似,可以认为实时Task是由Supervisor 克隆出来的。
三、Druid 整体架构
前面笼统地介绍了Druid元数据相关概念,为了深入的了解Druid元数据,先从宏观的角度认识一下Druid的整体架构。
可以形象地把Druid集群类比为一家公司,以Druid不同组件类比这家公司中不同类型员工来介绍Druid集群,Druid组件大体可以分为三类员工:领导层,车间员工和销售员工,如下图:
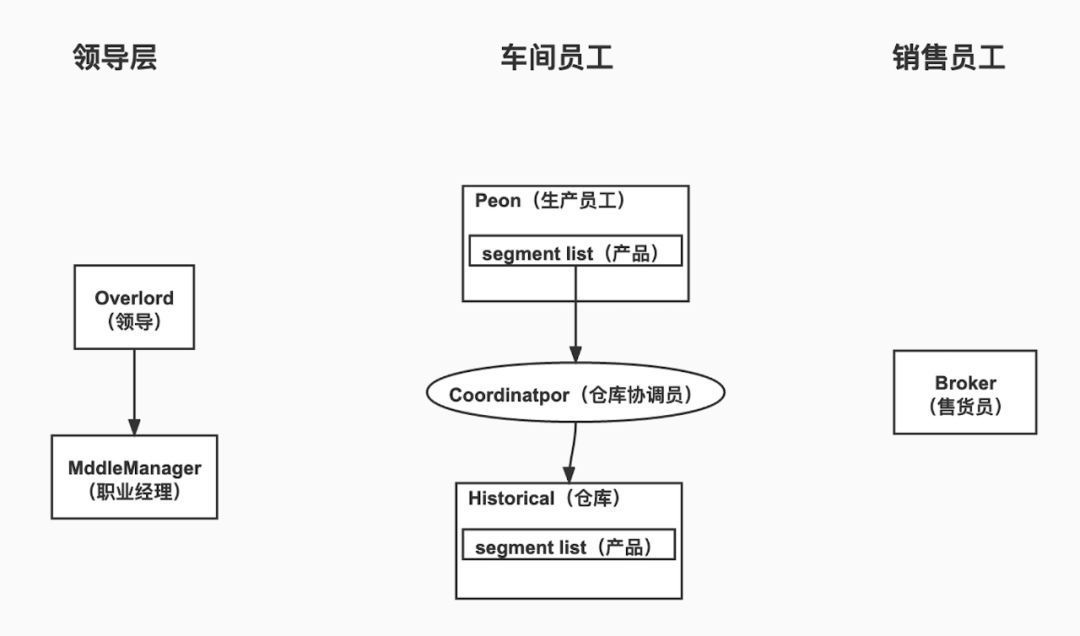
Druid组件分类
-
领导层: 领导根据外部市场需求(Overlord接收外部摄入任务请求),然后把生产任务下发到对应的职业经理人(MiddleManager),职业经理人管理团队(MiddleManager 启动Peon进程),下发具体生产任务给不同类型的员工(Peon进程)。
-
车间员工: 生产员工(Peon) 负责生产产品(segment),仓库管理员(Coordinator)负责把生产出来的产品(segment)分配到仓库(Historical)中去。
-
销售员工: 销售员(Broker)从生产员工(Peon)获取最新的产品(segment),从仓库中获取原来生产的产品(segment),然后把产品整理打包(数据进一步合并聚合)之后交给顾客(查询用户)。
上面通过类比公司的方式,对Druid集群有了初步的整体印象。
下面具体介绍 Druid 集群架构,Druid 拥有一个多进程,分布式架构,每个Druid组件类型都可以独立配置和扩展,为集群提供最大的灵活性。
一个组件的中断不会立即影响其他组件。
下面我们简要介绍Druid各个组件在集群中起到的作用。
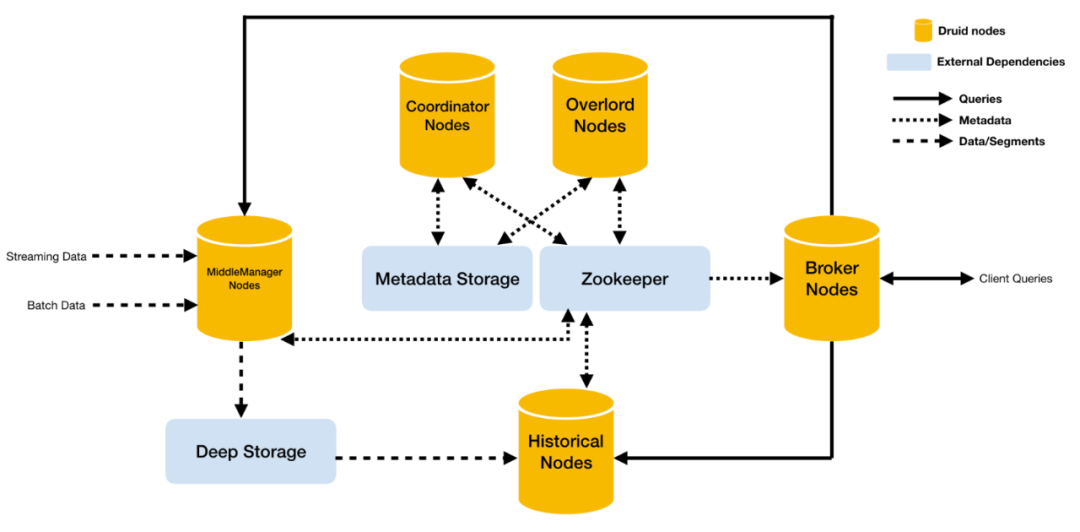
Druid架构
-
Overlord
Overlord负责接受任务、协调任务的分配、创建任务锁以及收集、返回任务运行状态给调用者。当集群中有多个Overlord时,则通过选举算法产生Leader,其他Follower作为备份。
-
MiddleManager
MiddleManager负责接收Overlord分配的实时任务,同时创建新的进程用于启动Peon来执行实时任务,每一个MiddleManager可以运行多个Peon实例,每个实时Peon既提供实时数据查询也负责实时数据的摄入工作。
-
Coordinator
Coordinator 主要负责Druid集群中Segment的管理与发布(主要是管理历史Segment),包括加载新Segment、丢弃不符合规则的Segment、管理Segment副本以及Segment负载均衡等。如果集群中存在多个Coordinator Node,则通过选举算法产生Leader,其他Follower作为备份。
-
Historical
Historical 的职责是负责加载Druid中非实时窗口内且满足加载规则的所有历史数据的Segment。每一个Historical Node只与Zookeeper保持同步,会把加载完成的Segment同步到Zookeeper。
-
Broker
Broker Node 是整个集群查询的入口,Broker 实时同步Zookeeper上保存的集群内所有已发布的Segment的元信息,即每个Segment保存在哪些存储节点上,Broker 为Zookeeper中每个dataSource创建一个timeline,timeline按照时间顺序描述了每个Segment的存放位置。
每个查询请求都会包含dataSource以及interval信息,Broker 根据这两项信息去查找timeline中所有满足条件的Segment所对应的存储节点,并将查询请求发往对应的节点。
四、 Druid元数据存储介质
Druid 根据自身不同的业务需要,把元数据存储在不同的存储介质中,为了提升查询性能,同时也会将所有元数据信息缓存在内存中。把历史数据的元数据信息保存到元数据库(MySQL),以便集群重启时恢复。
由于Druid 拥有一个多进程,分布式架构,需要使用Zookeeper进行元数据传输,服务发现,主从选举等功能,并且历史节点会把Segment元数据信息存储在本地文件。
那么历史节点(Historical)为什么会把该节点加载的Segment元数据信息缓存在自己节点的本地呢?
是因为在历史节点发生重启之后,读取Segment的元数据信息不用去Mysql等其他元数据存储介质进行跨节点读取而是本地读取, 这样就极大地提升了历史节点数据的恢复效率。
下面分别介绍这些存储介质(内存、元数据库、Zookeeper、本地文件)里的数据和作用。
4.1 元数据库(MySQL)
MySQL 数据库主要用于长期持久化 Druid 元数据信息,比如segment部分元数据信息存在druid_segments表中,历史的Task信息存在druid_tasks,Supervisor信息存储在druid_supervisors等等。
Druid部分服务进程在启动时会加载元数据库持久化的数据,如:Coordinator进程会定时加载表druid_segments 中used字段等于1的segment列表,Overlord 启动时会自动加载druid_supervisors表信息,以恢复原来实时摄入任务等等。
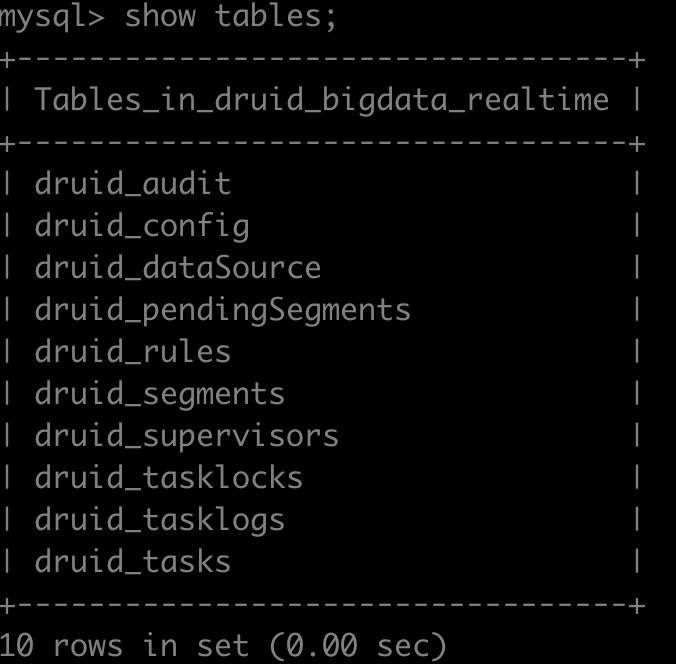
MySQL 元数据库表
4.2 Zookeeper
Zookeeper 主要存储 Druid 集群运行过程中实时产生的元数据,Zookeeper 数据目录大概可以分为Master节点高可用、数据摄入、数据查询3类目录。
下面介绍Druid相关Zookeeper目录元数据内容。
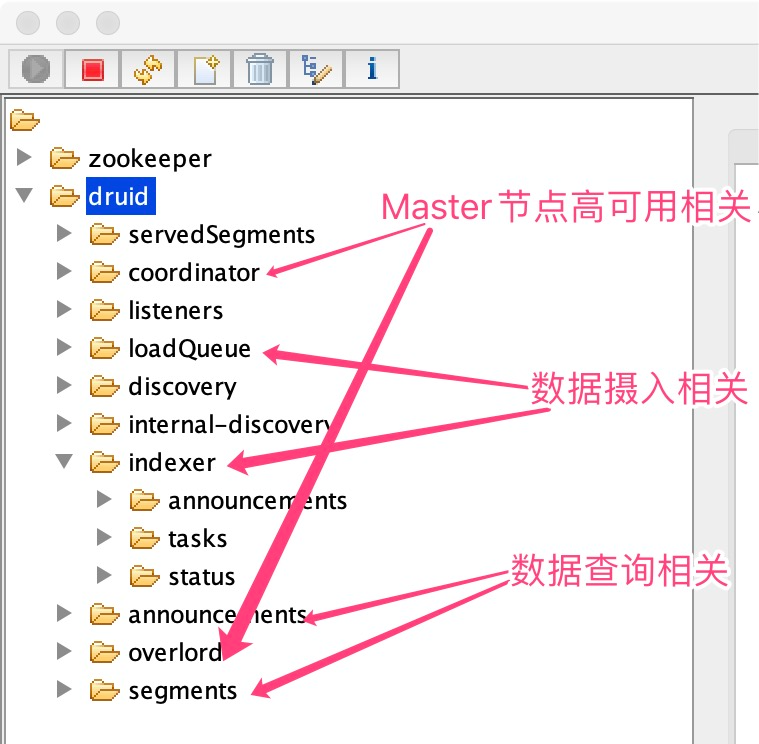
Zookeeper 元数据节点分类
4.2.1 Master 节点高可用相关目录
${druid.zk.paths.base}/coordinator: coordinator 主从高可用目录,有多个临时有序节点 编号小的是leader。
${druid.zk.paths.base}/overlord: overlord 主从高可用目录,有多个临时有序节点 编号小的是leader。
4.2.2 数据查询相关目录
${druid.zk.paths.base}/announcements:只存储historical,peon进程的host:port,没有MiddleManager,broker,coodinator等进程信息,用于查询相关节点服务发现。
${druid.zk.paths.base}/segments:当前集群中能被查询到的segment列表。目录结构:historical或peon的host:port/${segmentId},Broker节点会实时同步这些Segment信息,作为数据查询的重要依据。
4.2.3 数据摄入相关目录
${druid.zk.paths.base}/loadQueue: Historical需要加载和删除的segment信息列表(不止只有加载),Historical进程会监听这个目录下自己需要处理的事件(加载或删除),事件完成之后会主动删除这个目录下的事件。
${druid.zk.paths.indexer.base}=${druid.zk.paths.base}/indexer:关于摄入任务数据的base目录。
${druid.zk.paths.indexer.base}/announcements:保存当前存活MiddleManager列表,注意historical,peon 列表不在这里,这里只存储摄入相关的服务信息,用于数据摄入相关节点服务发现。
${druid.zk.paths.indexer.base}/tasks Overlord 分配的任务信息放在这个目录(MiddleManager的host:port/taskInfo),等任务在MiddleManager上运行起来了,任务节点信息将被删除。
${druid.zk.paths.indexer.base}/status:保存任务运行的状态信息,Overlord通过监听这个目录获取任务的最新运行状态。
4.3 内存
Druid为了提升元数据访问的效率会把元数据同步到内存,主要通过定时SQL 查询访问方式同步MySQL元数据或者使用Apache Curator Recipes实时同步Zookeeper上的元数据到内存如下图。
每个进程中的元数据不一样,下面一一介绍一下各个角色进程缓存了哪些数据。
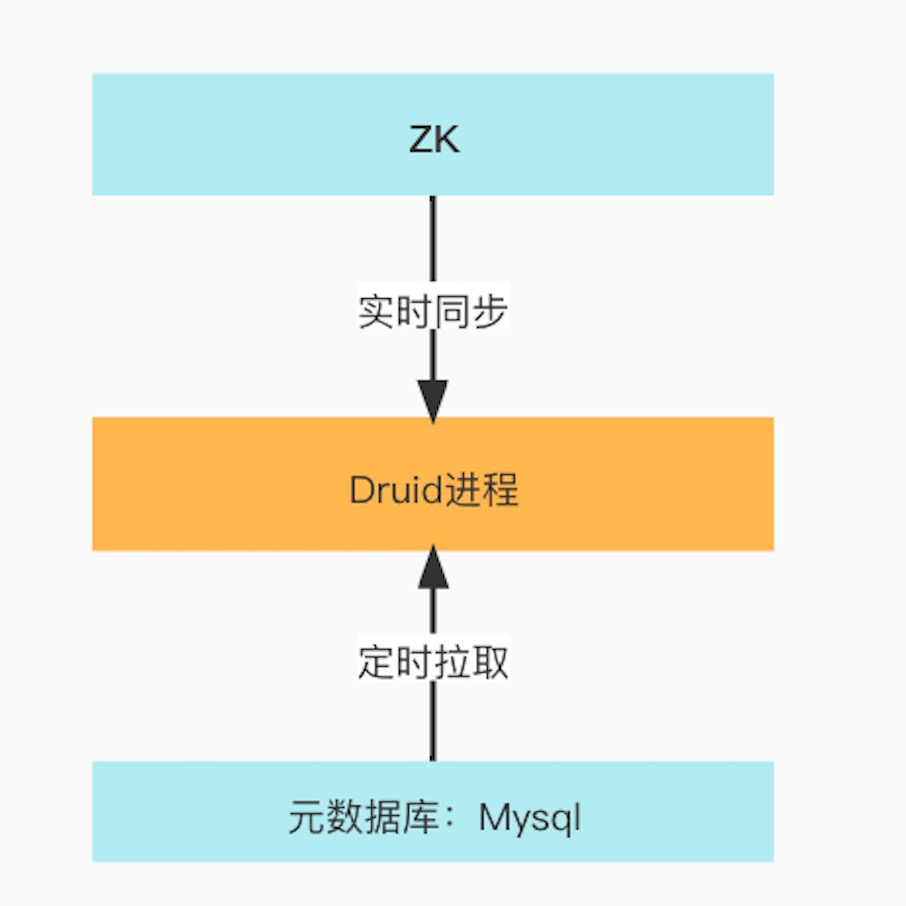
Druid进程元数据同步方式
4.3.1 Overlord
实时同步Zookeeper目录
(${druid.zk.paths.indexer.base}/announcements)下的数据,使用变量
RemoteTaskRunner::zkWorkers(类型:Map)存储,每ZkWorker对应一个MM进程,在ZkW orker对象中会实时同步Zookeeper目录(${druid.zk.paths.indexer.base}/status/${mm_host:port})任务信息,使用
RemoteTaskRunner::runningTasks变量存储。
默认每分钟同步数据库中druid_tasks active = 1的数据,使用变量TaskQueue::tasks(类型:List )存储,在同步时会把内存中的Task列表与最新元数据里的Task列表进行比较,得到新增的task列表和删除的task列表,把新增的Task加到内存变量TaskQueue::tasks,清理掉将要被删除的task
4.3.2 Coordinator
默认每1分钟同步元数据库中druid_segemtns 中列 used=1的segment列表到变量
SQLMetadataSegmentManager::dataSourcesSnapshot。
默认每1分钟同步元数据库druid_rules表信 SQLMetadataRuleManager::rules变量
使用CoordinatorServerView类(后面会介绍)实时同步
${druid.zk.paths.base}/announcements,
${druid.zk.paths.base}/segments的数据,用于与元数据库中的segment对比,用来判断哪些segment应该加载或删除。
4.3.3 Historical
会实时同步
${druid.zk.paths.base}/loadQueue/${historical_host:port} 下的数据,进行segment的加载与删除操作,操作完成之后会主动删除对应的节点。
Historical通过上报segment信息到
${druid.zk.paths.base}/segments来暴露
segment。
4.3.4 MiddleManager
会实时同步
${druid.zk.paths.indexer.base}/tasks/${mm_host:port}的数据,进行任务(peon)进程的启动,启动完成之后会主动删除对应的节点。
MiddleManager上报segment信息到
${druid.zk.paths.base}/segments来暴露
segment。
4.3.5 Broker
使用BrokerServerView类实时同步
${druid.zk.paths.base}/announcements,
${druid.zk.paths.base}/segments的数据,构建出整个系统的时间轴对象
(BrokerServerView::timelines) 作为数据查询的基本依据。同步过程中类的依赖关系如下图。
下层的类对象使用监听上层类对象的方式感知sement的增删改,并做相应的逻辑处理, 会同时监听${druid.zk.paths.base}/announcements和${druid.zk.paths.base}/segments的数据的数据变化,通过回调监听器的方式通知到下层类对象。

zk中segment同步到Druid进程过程中对象之间的监听关系
4.4 本地文件
本地文件的元数据主要用于恢复单个节点时读取并加载。
例如:Historical节点第一个数据目录下的info_dir目录(如:/data1/druid/segment-cache/info_dir),保存了该节点加载的所有segment信息,在Historical进程重启时会读取该目录下的segment元数据信息,判断本地是否有该segment的数据,如果没有就去深度存储系统(hdfs)下载,数据下载完成后会上报segment信息到Zookeeper
(路径:${druid.zk.paths.base}/segments)。
五、Druid 元数据相关业务逻辑
由于Druid组件类型比较多,业务逻辑比较复杂,从整体到局部方式,从宏观到细节,循序渐进地了解Druid的业务逻辑,以便了解Druid元数据在业务逻辑中发挥的作用。
5.1 Druid 元数据整体业务逻辑
前面从整体了解了 Druid 集群各个组件的协作关系,下面分别从摄入任务管理、数据摄入、数据查询三个方面的业务逻辑来梳理元数据在 Druid 集群所起的作用。
5.1.1 摄入任务管理
摄入数据之前需要用户提交摄入任务,Overlord根据任务的配置会相应命令MiddlerManager启动该任务的相关进程(peon进程)用于摄入数据,具体流程如下图中数据序号顺序执行。
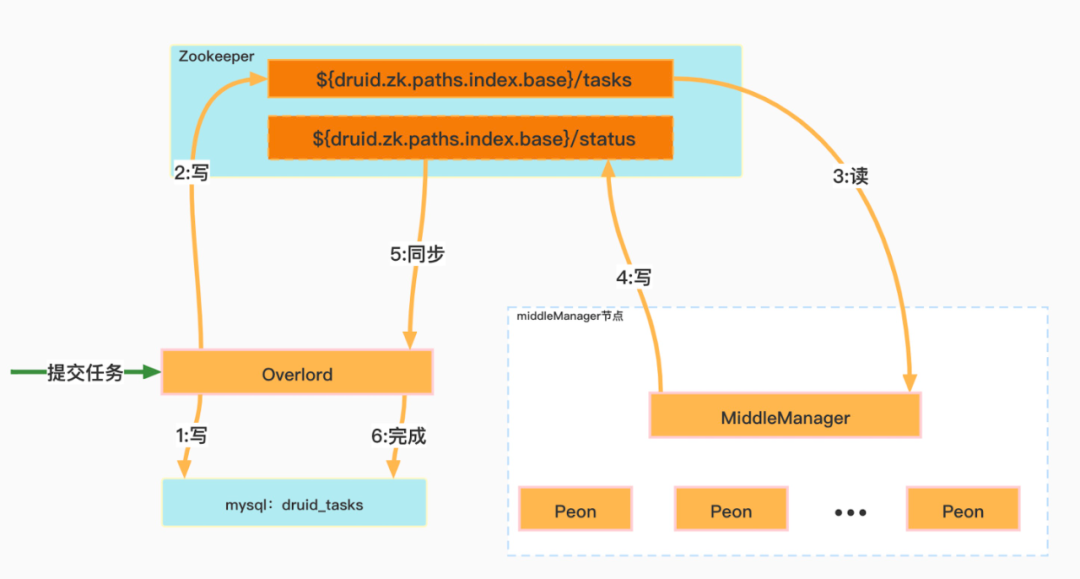
任务提交与管理
下面分别按照上图中数字序号顺序介绍 Druid 内部关于任务管理的业务逻辑:
① Overlord进程收到任务提交请求之后,会把任务信息写入druid_tasks表,此时字段active等于1。
② Overlord分配任务给特定的MiddleManager节点,并把task信息写入Zookeeper目录(${druid.zk.paths.indexer.base}/tasks )下。
③ MiddleManager进程监听当前节点在Zookeeper目录
(${ruid.zk.paths.indexer.base}/task)需要启动的task信息。
④ MiddleManager会以fork的方式启动Peon进程(task)此时Peon进程开始摄入数据,并把任务Running状态写入Zookeeper目录
(${ruid.zk.paths.indexer.base}/status)。
⑤ Overlord会实时监听Zookeeper目录
(${ruid.zk.paths.indexer.base}/status)获取任务运行最新状态。
⑥ 任务完成后Overlord会把task状态信息更新到数据库表druid_tasks,此时字段active=0。
5.1.2 数据摄入逻辑
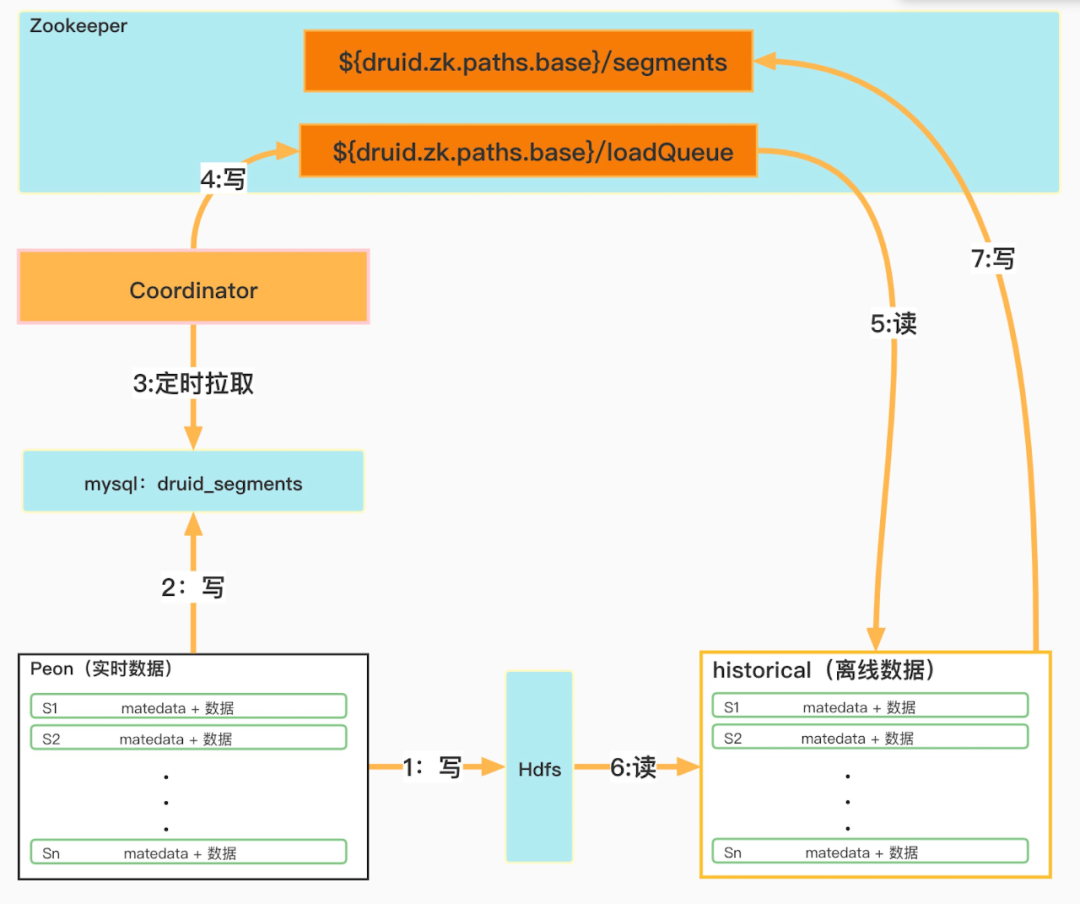
Druid数据摄入逻辑
下面分别按照上图中数字序号顺序介绍Druid内部关于数据摄入的业务逻辑:
① Peon进程在本地生产segment之后,会上传segment数据到深度存储Hdfs。
② 插入一条segment元数据信息到元数据druid_segments表中,包括segment数据hdfs地址,Interval信息,注意此时used字段为1。
③ Coordinator进程定时拉取druid_segments表中used为1的数据。
④ Coordinator进程把segment分配信息写入Zookeeper目录:
${druid.zk.paths.base}/loadQueue。
⑤ HIstorical进程监听当前节点在Zookeeper目录
(${druid.zk.paths.base}/loadQueue)获取需要加载的segment信息。
⑥ 从Hdfs下载segment数据,加载segment。
⑦把已加载的segment的元数据信息同步到Zookeeper目录(${druid.zk.paths.base}/segments)。
5.1.3 数据查询逻辑
数据查询主要涉及到Peon、Historical,Broker三个角色,Broker会根据client的查询请求中包含的dataSource和interval信息,筛选出需要查询的segment,然后Broker作为客户端从Peon获取实时数据,从Historical获取历史数据,再根据查询要求,将两部分数据进一步聚合,如下图:
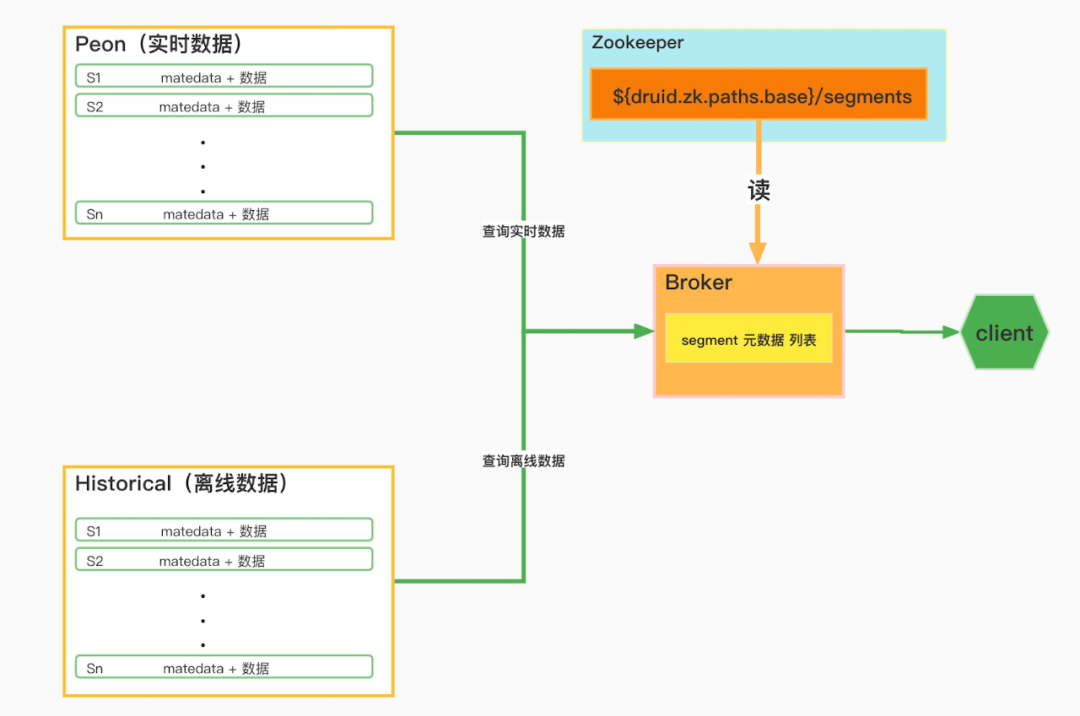
Druid数据查询逻辑
5.2 Druid 元数据具体业务逻辑
有了前面对Druid集群整体认识之后,下面更为细致的探讨Druid元数据在各个组件之间发挥的作用。
如下图虚线箭头表示元数据的传输,下面按照图中数字序号介绍每个虚线箭头两端组件与元数据存储介质(MySQL、Zookeeper)之间的元数据,每条具体从组件对元数据存储介质包含读和写两方面来介绍,如下:
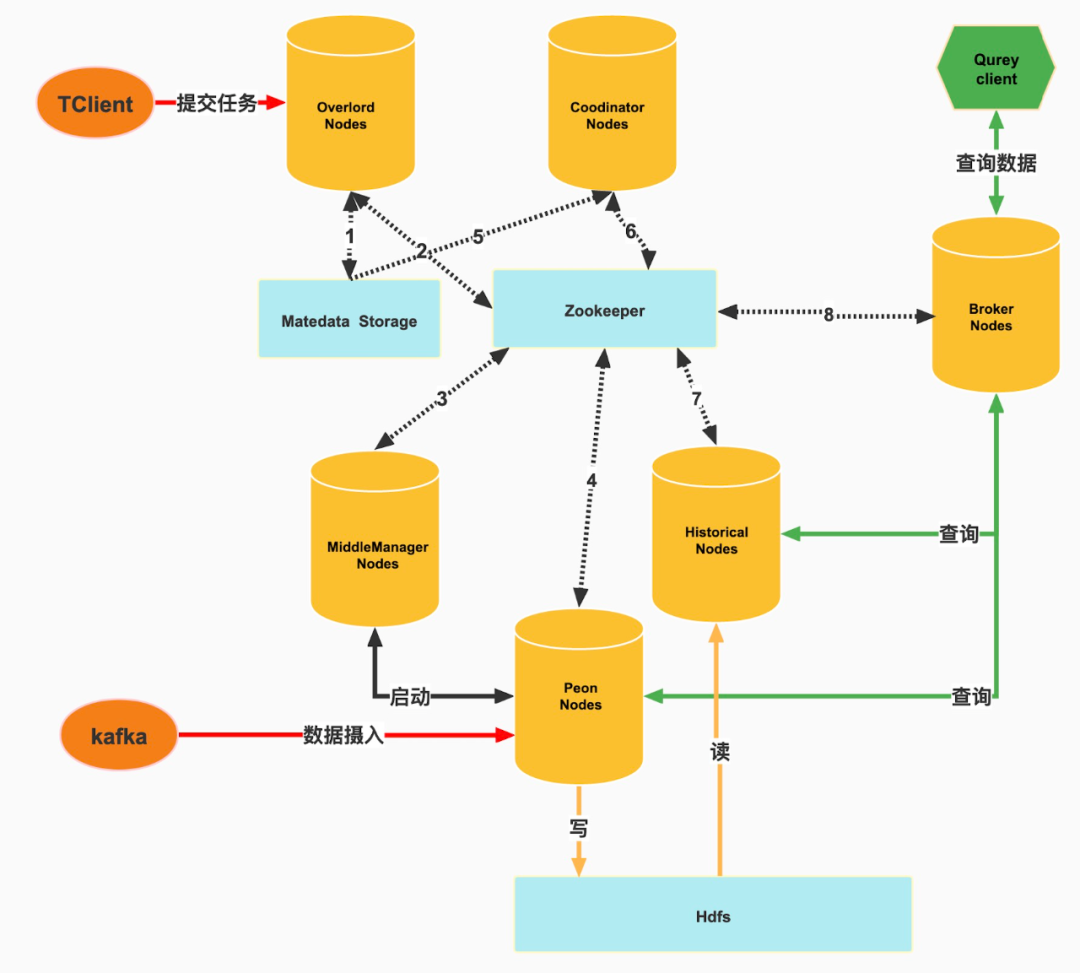
Druid元数据业务逻辑
① 写:启动任务时写入task信息,提交实时任务时写入supervisor信息。读:broker调用overlord接口时会查询不同状态下的task信息,进程重启时恢复supervisor信息。
② 写:分配任务到MiddleManager时,写入任务信息。读:同步正在运行任务的状态信息。
③ 写:写入当前节点任务状态信息到Zookeeper,读:读取带启动或终止任务信息。
④ 写:任务启动后上报实时segment信息。
⑤ 读:coordinator定时读取字段used=1的segment列表信息。
⑥ 写:coordinator分配的segment信息,读:已分配的segment列表信息。
⑦ 写:已加载完成的segment信息,读:需要加载的segment信息。
⑧ 读:加载完成的segment信息,作为数据查询的依据。
六、总结
前面以整体到局部、抽象到细节的方式从四个方面(Druid元数据基本概念、Druid整体架构、Druid元数据存储介质Druid元数据相关业务逻辑)介绍了Druid元数据在Druid集群中扮演的角色。
Druid 拥有一个多进程,分布式架构,每个组件只关注自己的业务逻辑和元数据,通过RPC通信或Zookeeper 进行组件之间的解耦,每个 Druid 组件类型都可以独立配置和扩展,极大提供集群的灵活性,以至于一个组件的中断不会立即影响其他组件,下面对Druid元数据做一个总结:
-
Druid元数据存储介质有内存、元数据库(MySQL)、Zookeeper、本地文件。
-
元数据库(MySQL)和本地的元数据起到备份、持久化的作用。Zookeeper主要起到元数据传输桥梁,实时保存元数据的作用,同时把元数据同步到内存,极大提升了Druid数据查询和数据摄入的性能,而本地文件的元数据主要用于恢复单个节点时快速读取并加载到内存。
-
在Druid组件进程中会把Zookeeper和元数据库(MySQL)里的元数据分别通过实时同步和定时拉取的方式同步到进程的内存中,以提高访问效率。
-
保存在各个组件进程中内存的元数据才是当前集群中最新最全的元数据。
本文转载自Zheng Xiaofeng vivo互联网技术,原文链接:https://mp.weixin.qq.com/s/8Na3gSm_pKk_Ql_eaj0NBQ。