

点击查看 Apache Flink 1.15 发布公告
一、概述
Generic Log-Based Incremental Checkpointing 的设计初衷是我们将全量的状态快照和增量的检查点机制分隔开,通过持续上传增量 Changelog 的方法,来确保每次 Checkpointing 可以稳定快速的完成,从而减小 Checkpointing 之间的间隔,提升 Flink系统端到端的延迟。拓展开来说,主要有如下三点提升:
-
更短的端到端延迟:尤其是对于 Transactional Sink。Transactional Sink 在 Checkpoint 完成的时候才能完成两阶段提交,因此减小 Checkpointing 的间隔意味着可以更频繁的提交,达到更短的端到端的延迟。 -
更稳定的 Checkpoint 完成时间:目前 Checkpoint 完成时间很大程度上取决于在 Checkpointing 时需要持久化的(增量)状态的大小。在新的设计中,我们通过持续上传增量,以达到减少 Checkpoint Flush 时所需要持久化的数据,来保证 Checkpoint 完成的稳定性。 -
容错恢复需要回滚的数据量更少:Checkpointing 之间的间隔越短,每次容错恢复后需要重新处理的数据就越少。
-
Checkpoint Barrier 流动和对齐的速度; -
将状态快照持久化到非易失性高可用存储(例如 S3)上所需要的时间。



二、设计
-
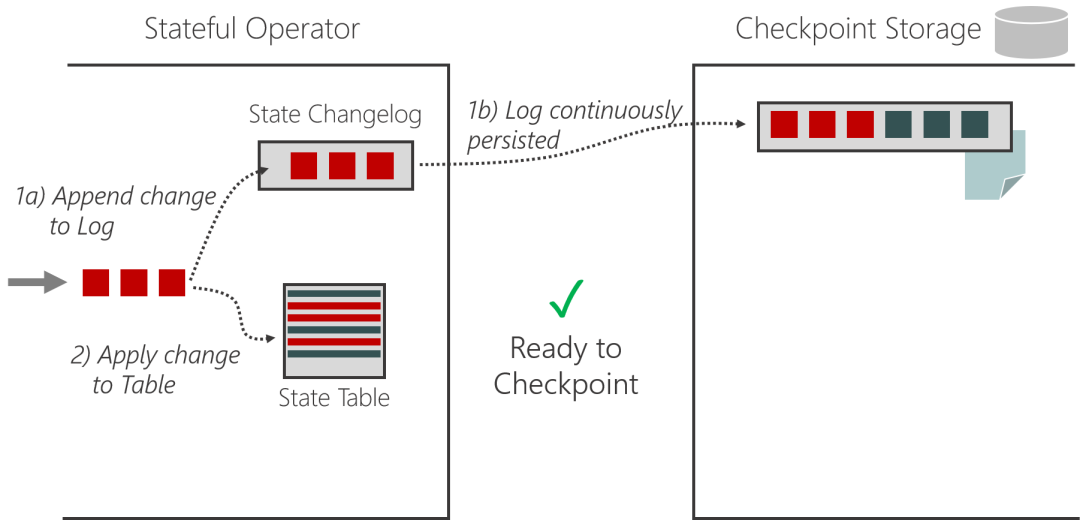
算子在更新状态的时候写双份,一份更新写入状态表 State Table 中,一份增量写入 State Changelog 中。 -
Checkpoint 变成由两个部分组成,第一个部分是当前已经持久化的存在远端存储上的 State Table,第二个部分是增量的 State Changelog。 -
State Table 的持久化和 Checkpointing 过程独立开来,会定期由 background thread 持久化,我们称为 Materialization(物化)的过程。 -
在做 Checkpoint 的时候,只要保证新增的 State Changelog 被持久化就可以了。

-
数据的增量更改(插入/更新/删除)会被写入到 Transaction Log 中。一旦这部分更改的日志被同步到持久存储中,我们就可以认为 Transaction 已经完成了。这个过程类似于上述方法中的 Checkpointing 的过程。 -
同时,为了方便数据查询,数据的更改也会异步持久化在数据表(Table)中。 一旦 Transaction Log 中的相关部分也在数据表中被持久化了,Transaction Log 中相关部分就可以删除了。这个过程类似于我们方法中的 State Table 持久化过程。
-
额外的网络 IO 和额外的 Changelog 持久存储开销; -
缓存 Changelog 带来的额外的内存使用; -
容错恢复需要额外的重放 Changelog 带来的潜在的恢复时间的增加。
三、Changelog 存储(DSTL)
-
短期持久化 State Changelog 是组成 Checkpoint 的一个部分,所以也需要能持久化存储。同时,State Changelog 只需要保存从最近一次持久化 State Table 到当前做 Checkpoint 时的 Changelog,因此只需要保存很短时间(几分钟)的数据。
-
写入频率远远大于读取频率 只有在 Restore 或者 Rescale 的情况下才需要读取 Changelog,大部分情况下只有 append 操作,并且一旦写入,数据就不能再被修改。
-
很短的写延迟 引入 State Changelog 是为了能将 Checkpoint 做得更快(1s 以内)。因此,单次写请求需要至少能在期望的 Checkpoint 时间内完成。
-
保证一致性 如果我们有多个 State Changelog 的副本,就会产生多副本之间的一致性问题。一旦某个副本的 State Changelog 被持久化并被 JM 确认,恢复时需要以此副本为基准保证语义一致性。
3.1 DSTL 方案的选择
-
没有额外的外部依赖:目前 Flink Checkpoint 持久化在 DFS 中,所以以 DFS 来实现 DSTL 没有引入额外的外部组件。 -
没有额外的状态管理:目前的设计方案中 DSTL 的状态管理是和 Flink Checkpointing 机制整合在一起的,所以也不需要额外的状态管理。 -
DFS 原生提供持久化和一致性保证:如果实现多副本分布式日志,这些都是额外需要考虑的成本。
-
更高的延迟:DFS 相比于写入本地盘的分布式日志系统来讲一般来说有更高的延迟。 -
网络 I/O 限制:大部分 DFS 供应商出于成本的考虑都会对单用户 DFS 写入限流限速,极端情况有可能会造成网络过载。
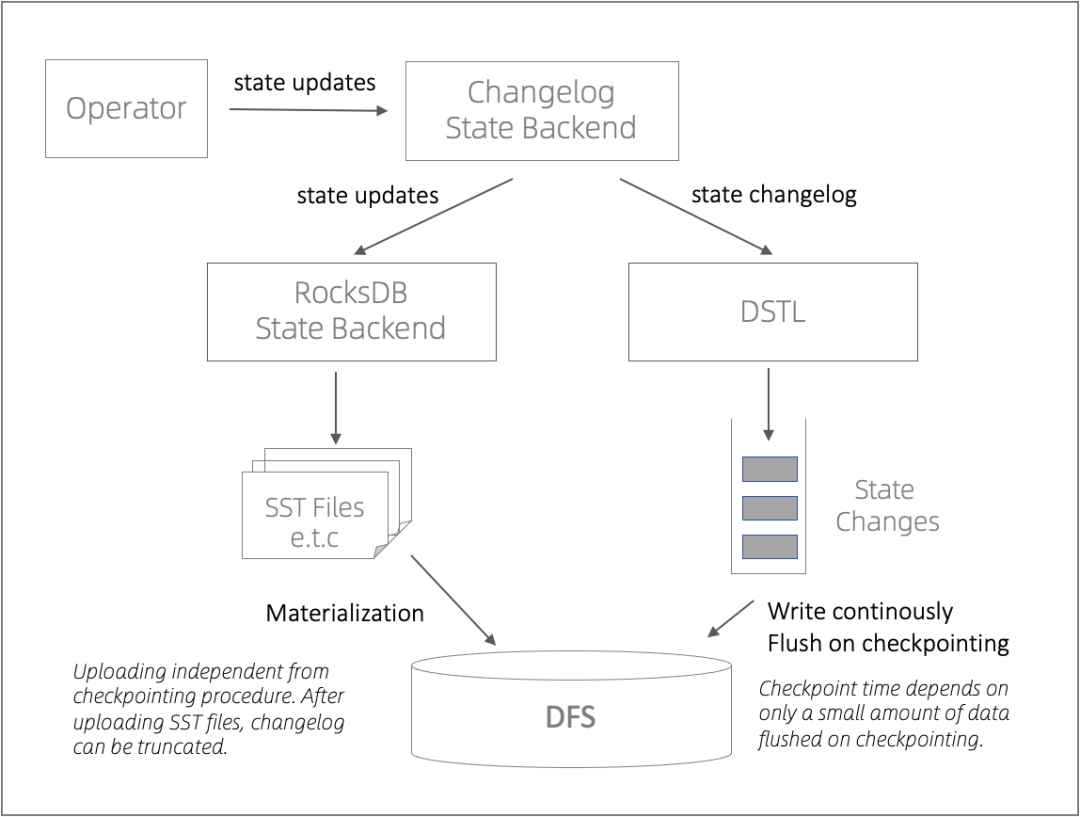
3.2 DSTL 架构
-
状态清理问题 前面有提到在新的架构中,一个 Checkpoint 由两部分组成:1)State Table 和 2)State Change Log。这两部分都需要按需清理。1)这个部分的清理复用 Flink 已有的 Checkpoint 机制;2)这个部分的清理相对较复杂,特别是 State Change Log 在当前的设计中为了避免小文件的问题,是以 TM 为粒度的。在当前的设计中,我们分两个部分来清理 State Change Log:一是 Change Log 本身的数据需要在 State Table 物化后删除其相对应的部分;二是 Change Log 中成为 Checkpoint 的部分的清理融合进已有的 Flink Checkpoint 清理机制[4] 。
-
DFS 相关问题 -
长尾延迟问题 为了解决 DFS 高长尾延迟问题,DFS 写入请求会在允许超时时间(默认为 1 秒)内无法完成时重试。 -
小文件问题 DFS 的一个问题是每个 Checkpoint 会创建很多小文件,并且因为 Changleog State Backend 可以提供更高频的 Checkpoint,小文件问题会成为瓶颈。为了缓解这种情况,我们将同一个 Task Manager 上同一作业的所有 State Change 写到同一个文件中。因此,同一个 Task Manager 会共享同一个 State Change Log。
四、Benchmark 测试结果分析
-
State Change Log 增量的部分与全量状态大小之比,增量越小越好。 -
不间断上传状态增量的能力。这个和状态访问模式相关,极端情况下,如果算子只在 Checkpointing 前更新 Flink State Table 的话,Changelog 起不到太大作用。 -
能够对来自多个 Task 的 changelog 分组批量上传的能力。Changelog 分组批量写 DFS 可以减少需要创建的文件数量并降低 DFS 负载,从而提高稳定性。 -
底层 State Backend 在刷磁盘前对同一个 key 的 更新的去重能力。因为 state change log 保存的是状态更新,而不是最终值,底层 State Backend 这种能力会增大 Changelog 增量与 State Table 全量状态大小之比。 -
写持久存储 DFS 的速度,写的速度越快 Changelog 所带来的提升越不明显。
4.1 Benchmark 配置
-
算子并行度:50 -
运行时间:21h -
State Backend:RocksDB (Incremental Checkpoint Enabled) -
持久存储:S3 (Presto plugin) -
机器型号:AWS m5.xlarge(4 slots per TM) -
Checkpoint 间隔: 10ms -
State Table Materialization 间隔:3m -
Input Rate:50K Events /s
4.2 ValueState Workload
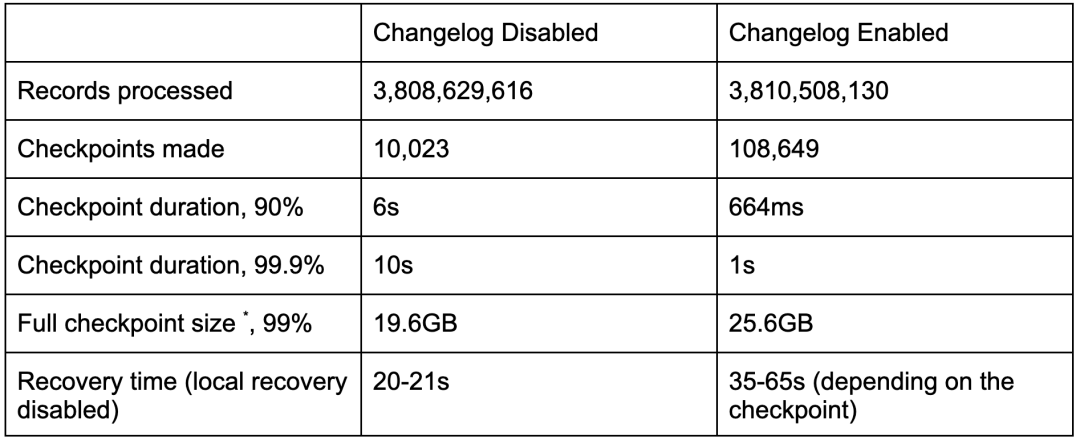
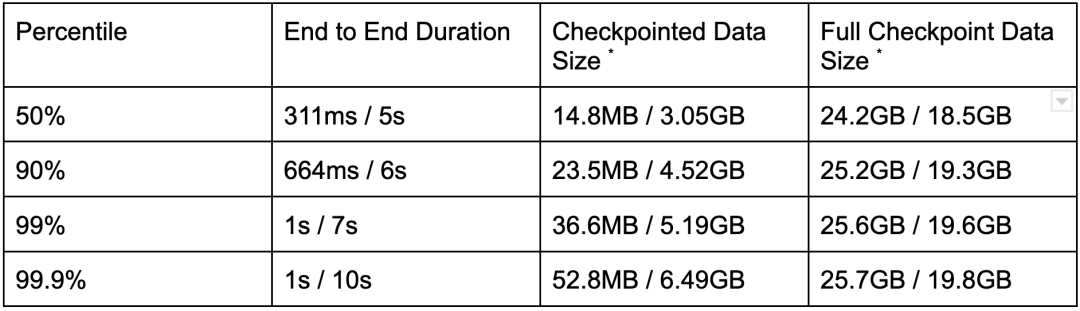
表2: 基于 ValueState Workload 的 Changelog(开启/关闭)的 Checkpoint 相关指标对比
-
Checkpointed Data Size 是指在收到 Checkpoint Barrier,Checkpointing 过程开始后上传数据的大小。对于 Changelog 来说,大部分数据在 Checkpointing 过程开始前就已经上传了,所以这就是为什么开启 Changelog 时这个指标要比关闭时小得多的原因。 -
Full Checkpoint Data Size 是构成 Checkpoint 的所有文件的总大小,也包括与之前 Checkpoint 共享的文件。与通常的 Checkpoint 相比,Changelog 的格式没有被压缩过也不够紧凑,因此占用更多空间。
4.3 Window Workload
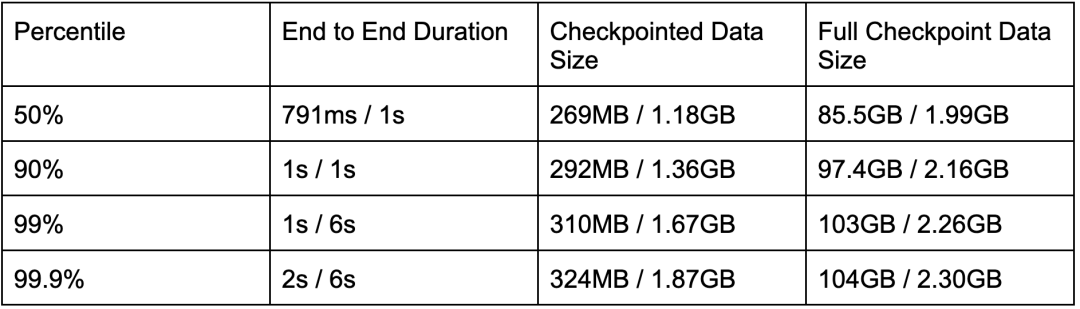
表3: 基于 Window Workload 的 Changelog(开启/关闭)的 Checkpoint 相关指标对比
-
对于 Sliding Window 算子,每条数据会加到多个滑动窗口中,因此为造成多次更新。Changelog 的写放大问题会更大。 -
前面有提到,如果底层 State Backend(比如 RocksDB)在刷磁盘前对同一个 key 的 更新去重能力越强,则快照的大小相对于 Changelog 会越小。在 Sliding Window 算子的极端情况下,滑动窗口会因为失效被清理。如果更新和清理发生在同一个 Checkpoint 之内,则很可能该窗口中的数据不包含在快照中。这也意味着清除窗口的速度越快,快照的大小就可能越小。
五、结论
state.backend.changelog.enabled: truestate.backend.changelog.storage: filesystemdstl.dfs.base-path: location similar to state.checkpoints.dir>
本文转载自梅源 & Roman@Apache Flink,原文链接:https://mp.weixin.qq.com/s/_E2AImwTKieo8BKf3J6Dzw。