



如果您已经采用或正在考虑测试 Apache Iceberg 作为组织和管理数据湖中所有原始数据文件(Parquet、ORC等)的表格式,那么现在,您可以直接对湖中的数据执行数据仓库级操作,如插入、更新和删除,尤其称赞的是,他们将以事务一致的方式执行!事情一切看起来非常良好——您的数据是完全开放的格式,多个引擎可以根据特定的用例使用数据,而且您不必为数据仓库支付高昂的成本。
但这只是您旅程的开始。从数据湖表查询数百PB的数据往往需要优化查询性能。您的查询也许今天看来很快,但随着时间的推移可能就不会了。随着越来越多的文件在数据湖中积累,您必须确保查询保持高效,因为随着时间的推移,您可能会出现以下情况
-
您的查询模式可能会更改
-
可能会添加新的查询模式
-
由于文件无组织,查询可能会很慢
要有效地响应查询请求,目标应该是让读取扫描尽可能少的数据。Iceberg 使用了分区、修剪和最小/最大过滤等技术,以跳过与查询谓词不匹配的数据文件。
使用 Iceberg 清单文件中的列级统计信息(此处示例)允许查询引擎跳过数据文件,从而实现更快的查询。然而,数据的物理布局对于有效来说非常重要。例如,考虑具有重叠度量的场景,如下面的场景。

正如您所看到的,这两个文件中的度量非常相似。文件1具有 A-J 范围内的 Em Name 列,文件2也具有相同的范围(A-J)。
让我们来看下查询:
SELECT * FROM Employee WHERE Emp Name = 'Dennis'由于此查询在 “Emp Name” 字段上有一个谓词,并且值 “Dennis” 介于 A-J 之间(这两个文件中都存在),因此查询引擎必须查看这两个文件。现在,这意味着文件的最小/最大统计信息在这个特殊的情况下并没有真正的帮助。
因此,对于这种情况,您是否能优化每个文件中数据的布局,并进一步补充数据跳过过程?当然,这也是本博客的重点。
解决上述重叠度量方案的常见策略是基于度量对文件中的数据进行排序。对整个数据集进行排序,以这样的方式重新排序数据,使每个数据文件最终为其排序的特定列提供唯一的值范围。当然,您还可以以分层的方式将其他列添加到已经排序的列中。因此,在此示例中,您可以对 “Emp Name” 列进行排序并重写文件,以便每个文件都有一个特定的范围,如下所示。
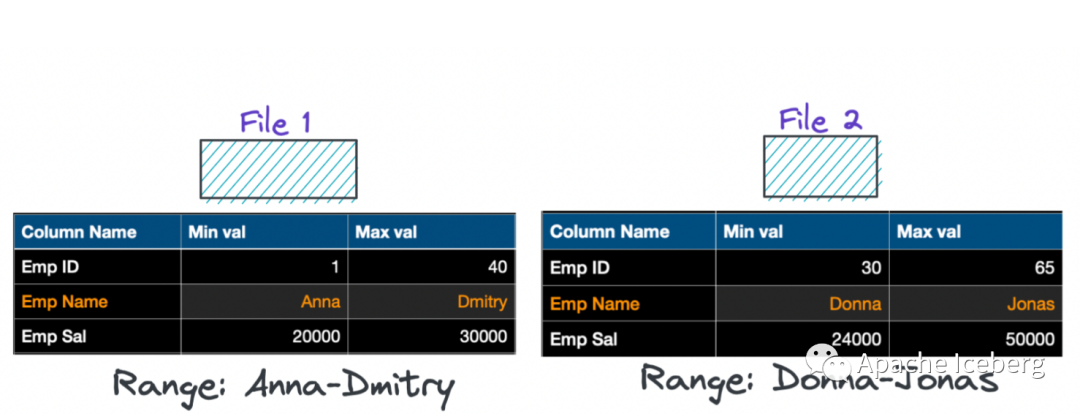
SELECT * FROM Employee WHERE Emp Name = 'Dennis'如果现在执行上述 SELECT 查询,查询引擎必须仅读取文件1,因为该文件中的 “Emp Name” 列的范围是 Anna-Dmitry。因此,通过使用排序等技术更改数据的布局,您可以通过只读取一半的数据文件来查询,这非常有帮助。
您还可以对列进行分层排序,即首先按“工程名称”排序,然后按“工程名称”和“工程ID”排序,如果您在所有三个字段上都有筛选器,例如:
SELECT * FROM Employee WHERE Emp Name='Dennis' AND Emp Sal=25000 AND Emp ID=22
引擎将采用每个谓词Emp Name=’Dennis’,Emp Sal=25000,Emp ID=22,并比较每列的最小-最大范围以筛选文件。
但是,对于在第一个排序列(即Emp Name)上没有过滤器的查询(见下文),其他列的最小-最大范围可能不适用于跳过数据文件。
SELECT * FROM Employee WHERE Emp Sal>18000为什么?
这是因为引擎将首先使用 Emp Name 对数据进行排序,然后根据 Emp Name 列分散其余数据(对于其他列)。让我们来看看一个假设的场景。考虑该表有两列:Emp Name 和 Emp Sal 。Emp Name 列的范围为[Anna-Julien], Emp Sal 的范围为【10000-20000】。

现在,如果您按 Emp Name、Emp Sal 的顺序对此表进行排序,并将其均匀地重写为四个文件,则这些文件可能如下所示:

因此,第一个文件包含 [A-*] 范围内的所有 Emp Name 和 Emp Sal [10K,20K]。类似地,第二个文件具有 [B-*] 范围内的 Emp Name 数据和 Em Sal [10K,20K]等等。
如果您运行相同的查询SELECT * FROM Employee WHERE Emp Sal>18000该查询在Emp Sal 列而不是第一个排序列上具有筛选器,则您现在又回到了同样的问题-引擎仍然必须扫描所有四个文件。
因此,在分层排序的情况下,只有在第一个排序列上有谓词时,您才会受益。如果谓词位于该层次结构中的其他字段上,则引擎无法利用。但是,当您有多个维度要过滤时,如何优化查询呢?
在同一文件中,就像它们在高维空间中一样。例如,请查看此表:

如果你看看 Anna 和 John 的两位员工,如果你用 Emp Sal 和 YoE 在两个维度上代表他们,他们就非常接近了。
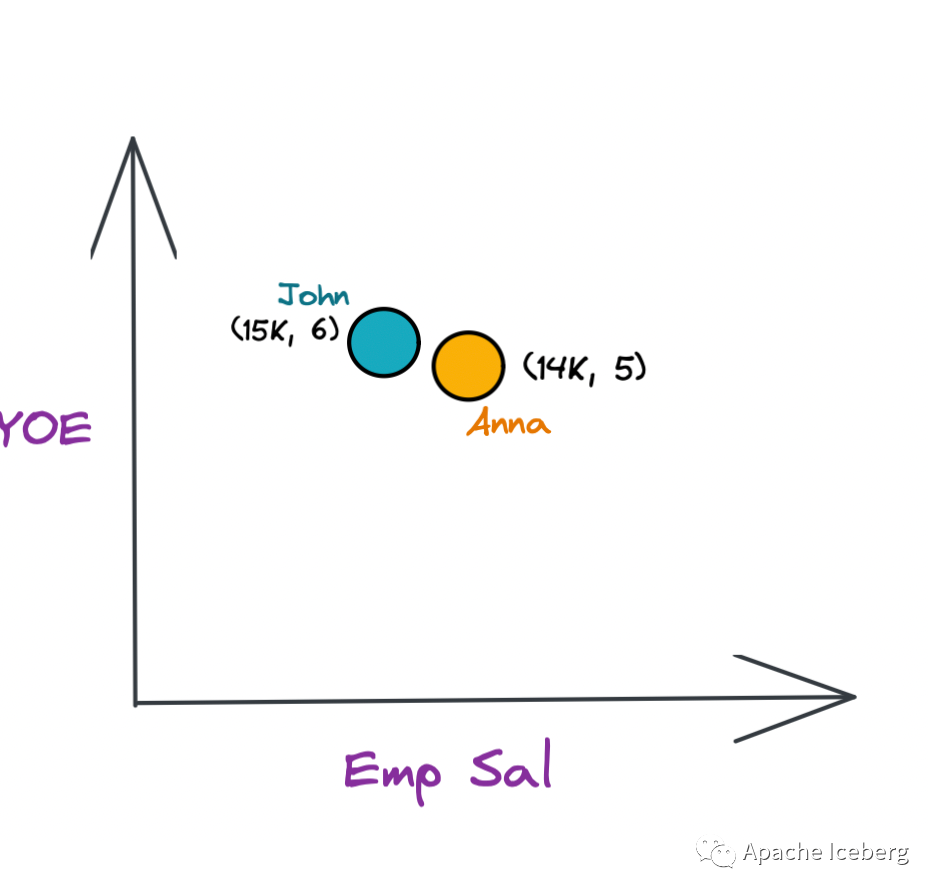
现在,假设您想在上表上运行查询,例如:“给我所有有5年以上经验且工资超过10000的员工”。此查询将要求您组合两个谓词(Emp Sal和YOE),以缩小查询搜索结果的范围。
在理想的世界中,当您通过排序对数据文件进行分组时,您希望所有具有相似数据点(Emp Sal和YOE)的员工都在同一文件中。否则,查询引擎必须从多个文件读取数据,这意味着更多的 I/O,这是无效的。因此,对于这样的查询,您希望能够保留点的局部性,这样即使它们投影到单个维时,它们也会保持接近。引入 Z-Order 曲线!
上面讨论了两个关键问题
– 重叠度量(文件中的最小/最大范围相同)
– 将相似的数据点保持在一起
这些问题最终归结为一个问题:您是否可以以更集成的方式(即一起)使用来自多列的信息,而不是独立地使用,以更好地按多个字段聚类数据,并实现有效的文件跳过?
好消息是,您可以使用Z阶聚类来实现这一目标。

根据定义,Z-Order 曲线是一种空间填充曲线,当从高维映射到低维(例如,3-D到2-D)时,它将相似的数据点保持在一起。
本文并没有深入探讨 Z-Order 背后的数学(你可以在这里阅读更多信息:https://tildesites.bowdoin.edu/~ltoma/teaching/cs3225-GIS/fall15/Lectures/gis_zorder.pdf),但在高层次上,其想法是通过绘制Z阶曲线穿过所有数据点(如上图所示)来触摸所有数据点,以保持类似的点更接近。
因此,现在,如果您回到雇员示例并基于 Z-Order 组织(群集)文件,您应该能够使用两列中的信息使用Z值对数据进行群集。如果您想现在运行相同的查询,以获取所有experience >5年、salary >10K的员工,引擎可以只从一个文件(文件2)中获取数据,如下图所示。
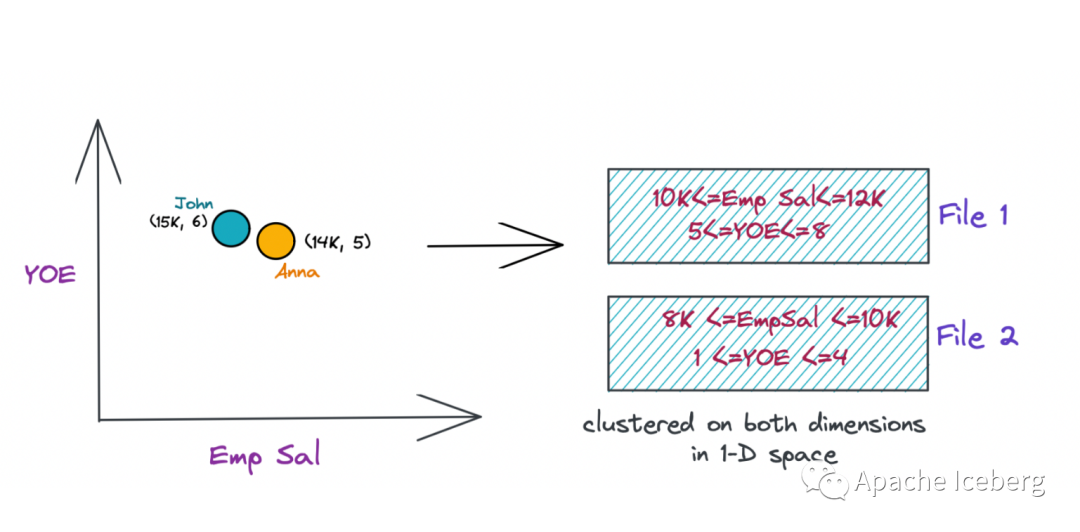
使用 Z-Order 聚类,您现在可以高效地处理多列上的谓词,并将类似的数据保存在一起。这使您可以获得更好的最小/最大修剪和 I/O 压缩,以便您可以有效地跳过数据文件,从而加快查询速度。
单个数据点的Z值使用交织位方法计算。您可以在 Z-order【https://en.wikipedia.org/wiki/Z-order_curve】上阅读更多信息。
Z-Order 是一种可以用于优化存储在数据湖表中的数据布局的技术。但是,重要的是要知道什么时候使用 Z-Order,什么时候不使用 Z-Order,以及在哪些列上。
一些常见的场景有:
-
当您希望使用多个维度过滤数据时,请考虑频繁运行的查询的Z-Order。如果您的大多数或所有查询仅在单列上过滤,则正常排序应该可以正常工作。
-
Z-Order 最适合具有相似分布和范围的数据。例如,地理空间、物联网数据。Z-Order 将相似类型的数据保留在同一文件中,以有效地跳过数据文件。这在正常/分层排序中是不可能的。
-
在分布范围非常小的字段上进行 Z-Order 是没有好处的,因为数据点已经彼此接近。在这种情况下,正常排序效果最好。
-
具有高基数(大量不同值)的列最适合Z排序。

Apache Iceberg 提供了使用 Z-Ordering 技术组织文件中数据布局的能力。
使用此优化策略的一种方法是利用 Spark 中的 rewrite_data_files 操作,该操作已经允许使用 bin-pack 和 sorting 等方法压缩较小的文件并组织文件中的数据。这种新的群集策略的添加通过补充min/max修剪等技术,使跳过文件的过程更加高效。
现在让我们将Z阶聚类方法应用于 Iceberg 表。为此,首先需要使用以下参数运行 Spark 操作 rewrite_data_files:

现在,当您运行下面的查询时,引擎只需扫描一个文件。
SELECT * FROM Employee WHERE Emp Sal>10000 AND YOE>5在现实环境中,考虑何时使用 Z-Order 优化数据文件是很重要的,因为这是一个相对昂贵的操作。因此,在所需的性能与 Z-Order 的成本之间通常存在权衡。根据组织的维护策略-每周、每月等- Z-Order 可以使用计划工具/作业自动执行。设置一些阈值也可能是一个好主意,例如使用元数据表、查询模式等查看小文件的数量,以自动执行 Z-Order 聚类。
在查询数据湖中存储的PB数据时,维护数据文件并优化其中的数据布局至关重要。通过利用 Apache Iceberg 的 Z-Order 聚类技术,您可以保留数据的位置,并高效地跳过数据文件,即使使用多个查询谓词。
本文转载自DipankarMazumdar Apache Iceberg,原文链接:https://mp.weixin.qq.com/s/jUgGxwldBN5UPn4Q8cz7Fg。