
-
携程大数据平台开发专家,负责大数据离线平台的开发和维护工作,关注大数据领域生态建设
-
Apache Kyuubi (Incubating) Committer


当我们开始把大多数在 Hive 的查询和 ETL 作业迁移到 Spark,面临的几个问题是如何透明迁移 HiveServer2 服务以及如何保证稳定性。
与 HiveServer2 对应的 Spark Thrift Server 是 Apache Spark 社区基于 HiveServer2 实现的一个 Thrift 服务,目标是做到无缝兼容 HiveServer2。与 HiveServer2 类似,通过 JDBC 接口提交 SQL 到 Thrift Server。
”
 1.1 运行方式
1.1 运行方式
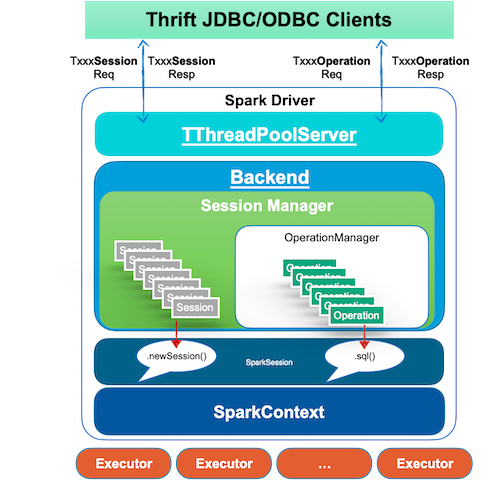
通过 ./sbin/start-thriftserver.sh 启动 Spark Thrift Server,它不仅仅包含了一个 Spark Driver,还提供了一个基于 Thrfit 协议的服务。
在 Servier 通过 SparkSQLSessionManager 管理所有 Client 对应的 Session,使用 JDBC 连接 Server 时,Server 使用 SparkSession.newSession 创建了一个隔离的 Session。
在 Server 通过 SparkSQLOperationManager 管理所有 Operation,之后 Client 提交每一条 SQL ,作为一次 Operation ,Server 通过 Client 绑定的 Session 使用 SparkSession.sql API 提交 SQL。
Server(Driver) 负责编译优化 SQL,生成 Job,提交到 Executor 执行,异步等待完成。
Client 轮询 Server SQL 是否完成,并拉取结果。
1.2 局限
相比于 HiveServer2,Spark Thrift Server 是比较脆弱的。
一般来说,Spark Driver 比 Hive Driver 更为繁忙一点。Hive 编译优化 SQL,提交 MapReduce Job,轮询结果,而 Spark Driver 不仅仅要做 Hive 的类似事情,还需要管理资源调度,增加和减少 Executors,调度 Job、Task 执行,广播变量、小表,这也导致了 Spark Driver 更容易有 OOM 的问题,当这个问题出现在 Driver 与 Server 绑定的同个进程中,问题就更为严峻,可能导致多个 Client 突然失败。
-
Server 单点问题
不支持类似 HiveServer2 通过 Zookeeper 实现 High Availability
https://issues.apache.org/jira/browse/SPARK-11100
-
不支持多个不同的用户
Thrift Server 不能以提交查询的用户取代启动 Thrift Server 的用户来执行查询语句,类似 HiveServer2 hive.server2.enable.doAs
https://issues.apache.org/jira/browse/SPARK-5159
-
不支持 Cluster 模式
基于上述原生 Spark Thrift Server 不能够满足需求,我们基于 Spark2 扩展了一些实现。
2.1 运行方式
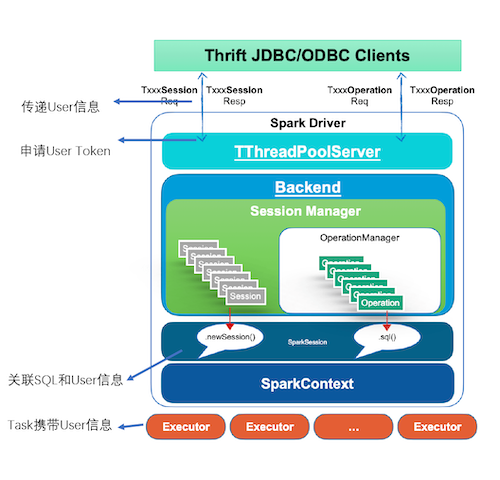
在 Client 发起 openSession 时, Server 在 SparkSQLSessionManager.openSession 对当前的 Session User 申请 HDFS DelegationTokens 和 Hive DelegationTokens。这一块 Token 传递和刷新和 Spark2 Streaming 更新 Token 逻辑类似。
在 DAGScheduler submit job 的时候关联 SQL,JobId,User 信息,并绑定到 Task。
在 Executor 使用 Task 对应的 UGI doAs 执行。
由于 Spark2 还有多处的实现用到了线程池,这里也需要模拟成不同的用户去执行。
-
BroadcastExchangeExec.executionContext 全局的线程池
-
UnionRDD.partitionEvalTaskSupport 全局的 ForkJoinPool
-
HIVE-13120 : propagate doAs when generating ORC splits
https://issues.apache.org/jira/browse/HIVE-13120
2.2 实现功能
-
支持多租户
支持多个 UGI 用户连到同一个 Server,并以不同的用户身份来连接 Hive Meta Store,执行 DDL,运行 Task
-
基于 Zookeeper 实现 High Availability
-
在 operationLog 实现查询进度条
-
支持只有 SELECT 类型才返回 ResultSet
-
针对 Ad-Hoc,报表场景对 SQL 自动增加 Limit
-
Limit 初始分区数可配置
加 Limit 之后,初化分区数默认从 1 开始,有时候提交多次 Job 才符合 Limit 条数
https://issues.apache.org/jira/browse/SPARK-37605
-
支持 Graceful stop
下线某台 Server,Client 无感知,不会报错
-
支持 YARN Cluster
原生的只支持 YARN Client 模式部署,支持 Cluster 可以更好利用 YARN 资源
-
支持 一个用户 多个 HiveCatalog
有时候一个 Session 执行的 SQL 可能会导致单个 HiveCatalog 卡住,导致其它 Session 可能只是简单的 DDL、DML 响应比较慢
-
使用 STS 过程了也遇到一些问题并修复
[SPARK-26992][STS] Fix STS scheduler pool correct delivery
https://issues.apache.org/jira/browse/SPARK-26992
[SPARK-26598][SQL] Fix HiveThriftServer2 cannot be modified hiveconf/hivevar variables
https://issues.apache.org/jira/browse/SPARK-26598
-
…
2.3 局限
1. 在 YARN 层面 App 对应的用户是超级用户,不能细粒度划分资源
2. Spark Jars、Files 是全局共享的,这导致了 UDF 隔离性不是很好
3. 扩展特性对 Spark Core 、SQL、ThriftServer 模块改动较多,与 Spark 版本深度绑定
当我们开始从 Spark2 迁移到 Spark3 的时候,开始调研 Apache Kyuubi,决定用来替换 Spark2 Thrift Server。
目前已经上线大半年,从早期的 1.3,1.4 到现在 1.5 版本,承接原先 Spark2 80% 查询量。
在早期调研和灰度上线,发现了一些问题,修复之后也回馈了社区。
-
Engine 闲置退出还会重试提交,导致 Engine 没有释放
-
简化客户端连接串,方便迁移 HiveServer2 应用(kyuubi.ha.zookeeper.publish.configs)
-
自动加 Limit 的 Rule 数据不准确
-
开启超时 Query 自动 Kill 能兼容低版本 JDBC Client
-
…
另外也基于原先 Spark2 二次开发的一些特性,对 Kyuubi 做了一些改造。
3.1 运行方式
Apache Kyuubi 的架构分为两层,一层是 Server 层,一层是 Engine 层。
Server 层和 Engine 层都有一个服务发现层,Kyuubi Server 层的服务发现层用于随机选择一个 Kyuubi Server,Kyuubi Server 对于所有用户来共享的。
Kyuubi Engine 层的服务发现层对用户来说是不可见的。它是用于 Kyuubi Server 去选择对应的用户的 Spark Engine,当一条用户的请求进来之后,它会随机选择一个 Kyuubi Server,Kyuubi Server 会去 Engine 的服务发现层选择一个 Engine。如果 Engine 不存在,它就会创建一个 Spark Engine,这个 Engine 启动之后会向 Engine 的服务发现层去注册,然后 Kyuubi Server 和 Engine 之间的再进行一个内部连接。所以说 Kyuubi Server 是所有用户共享,Kyuubi Engine 是用户之间资源隔离。

3.2 优点
-
设计上天然多租户,支持 Cluster 模式
-
不与 Spark 具体版本绑定,支持 N 个大小 Spark3 版本
-
隔离性好,支持资源队列隔离,Engine 隔离
可以按代理用户提交到用户的 YARN 资源队列,通过指定kyuubi.engine.share.level,kyuubi.engine.share.level.subdomain 还可以实现 Engine 隔离
-
Engine 支持 Long Running,Server 管理所有用户 Token 更为优雅
-
使用 Explain 模式,可以预解析 SQL
通过设置 kyuubi.operation.plan.only.mode ,可以把通过 Lineage Plugin 收集的 Spark2 所有 SQL ,使用 JDBC 提交到 Kyuubi 进行解析 ,对升级 Spark 版本检查 SQL 语法兼容性有很大的帮助
-
自带不少基于 Spark 的优化规则,通过 SparkSessionExtensions 注入
-
通过 kyuubi-ctl 实现 Server、Engine graceful stop
升级 Kyuubi 或者 Spark 版本,使用 kyuubi-ctl 下线 Server、Engine 节点,终端用户无感知
-
可以按不同的用户进行个性配置
使用 ___{username}___.{config key} 可以很方便对每个用户进行个性化的配置,还支持使用 SessionConfAdvisor Plugin 动态覆盖配置。
3.3 局限
现在 Kyuubi 使用 kyuubi.engine.share.level 配置项,用来控制 Engine 不同场景的隔离级别。
-
CONNECTION
每次创建连接都会启动一个 Engine,不共享,连接断开,销毁 Engine,适合 ETL 或者隔离性要求较高的任务。
-
USER
默认值,同一个用户会共享同一个 Engine,不同的连接关闭后 Engine 不会销毁,通过 kyuubi.session.engine.idle.timeout 配置来控制 Engine 闲置多久后自动销毁,常用于 Ad-Hoc,报表查询场景。
-
GROUP
使用连接用户对应的 Group(Hadoop Groups Mapping)创建 Engine,属于同个 Group 可以共享同个 Engine。
-
SERVER
使用启动 Kyuubi Server 的用户创建 Engine,每个连接都可以共享同个 Engine。
我们常用的模式是 USER,当我们有很多不同的用户的时候,会创建不少 Engine,第一次 Engine 创建和启动会相对慢一些。
并且使用 kyuubi.engine.pool.size 来控制每个 USER 能创建几个 Engine,由于目前社区版本使用随机算法来选择 Engine,当 pool size 设置比较大,可能会创建不少 Engine,有时候每个 Engine 的负载并不高。
目前这一块社区计划优化中。
以上是根据基于内部使用场景的一些简单的概括对比,Apache Kyuubi 社区还有更详细的比较:
https://kyuubi.readthedocs.io/en/latest/overview/kyuubi_vs_thriftserver.html
Apache Kyuubi 项目的目标是 建立在企业级即席 SQL 查询服务,基本上做到了开箱即用,同时也带来了不少实用的 Spark 引擎扩展,一些 watchdog 实现,限制查询的分区数,限制查询的结果数,此外还有小文件合并,Z-Order 等强大功能。
最新 Release 1.5.2 版本 已支持 Spark SQL,Flink SQL,Trino,还支持 Scala 代码片段提交。
在未来 1.6 版本还支持 Hive Engine,提交 Jar 任务,Spark 支持 Ranger 鉴权插件,TPC-DS 、TPC-H Connector,未来可期!
本文转载自 陈少云 Apache Kyuubi,原文链接:https://mp.weixin.qq.com/s/JBDdi0kHwfiH2ZHuzedT7g。