
使用 Alluxio 运行 Presto 在社区中越来越受欢迎。 它通过利用 SSD 或内存缓存靠近 Presto 工作人员的热数据集,避免了从远程存储读取数据的长时间延迟。 Presto 支持基于散列的软亲和调度,强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的散列算法在集群大小发生变化时效果不佳。 本文介绍了一种用于软亲和调度的新哈希算法,一致性哈希,来解决这个问题。
软关联调度
Presto 使用一种称为软亲和调度的调度策略,将一个 split(最小的数据处理单元)调度到同一个 Presto worker(首选节点)。 split 和 Presto worker 的映射由 split 上的散列函数计算,确保相同的 split 始终被哈希到同一个 worker。 第一次处理拆分时,数据将缓存在首选工作节点上。 当后续查询处理相同的拆分时,这些请求将再次调度到相同的工作节点。 由于数据已经在本地缓存,因此不需要远程读取。
为了改善负载平衡和处理不稳定的工作节点,选择了两个首选节点。 如果第一个选项忙或没有响应,则使用第二个选项。 数据可能物理缓存在 2 个工作节点上。
有关软关联调度的更多详细信息,请阅读“使用 Alluxio 数据缓存降低 Presto 延迟”。
散列算法
软亲和调度依赖于散列算法来计算分裂节点和工作节点之间的映射。 以前,使用模块化函数:
WorkerID1 =Hash(splitID) % workerCount
WorkerID2 =Hash(splitID) % workerCount + 1
这种散列策略很简单,并且在集群稳定且工作节点没有变化的情况下运行良好。 但是,如果某个工作节点暂时不可用或停机,工作节点数量可能会发生变化,并且拆分到工作节点的映射将被完全重新洗牌,从而导致缓存命中率显着下降。 如果有问题的节点稍后重新上线,这种重新洗牌将再次发生。
为了缓解此问题,Presto 在使用模块化计算工作节点分配时使用所有工作节点计数而不是活动工作节点计数。 但是,这只能缓解临时工作节点离线引起的重新散列。 由于工作量波动,在某些情况下添加/删除工作节点是有意义的。 在这些情况下,是否仍然可以保持合理的缓存命中率而不引入大规模的重新散列? 解决方案是一致的散列。
一致散列
一致散列的概念是由 David Karger 在 1997 年引入的,作为在不断变化的 Web 服务器群中分配请求的一种方式。 该技术广泛用于负载均衡、分布式散列表等。
一致性散列如何工作
想象一下,哈希输出范围 [0, MAX_VALUE] 被映射到一个圆上(将 MAX_VALUE 连接到 0)。 为了演示一致性哈希是如何工作的,假设一个 Presto 集群包含 3 个 Presto 工作节点,并且有 10 个拆分被重复查询。
首先,工作节点被散列到散列环上。 对于每个拆分,它将分配给哈希环上其哈希值旁边的工作人员。
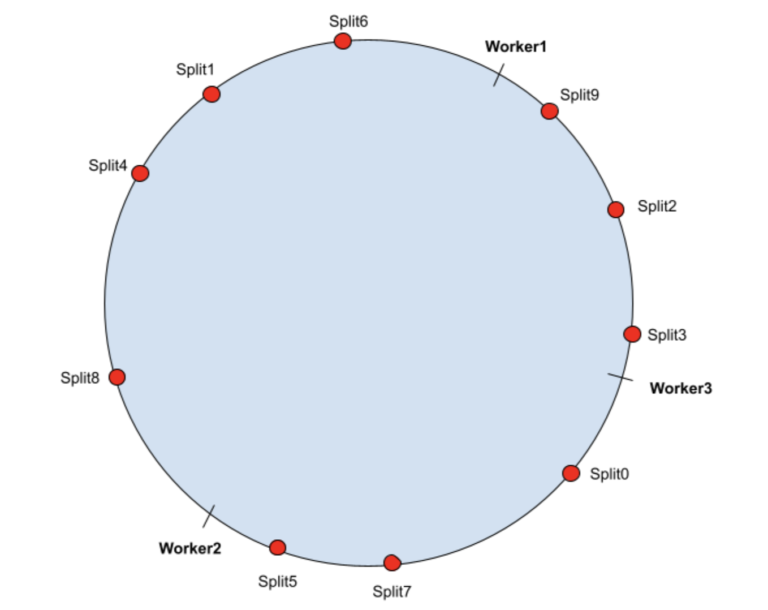

在上述场景中,拆分分配如下:
| Worker1 | Split1, Split4, Split6, Split8 |
| Worker2 | Split0, Split5, Split7 |
| Worker3 | Split2, Split3, Split9 |
删除worker节点
现在如果worker2因为某种原因下线了,按照算法,分裂0、5、7会被调度到下一个hash值的worker,也就是worker2:
| Worker1 | Split0, Split1, Split4, Split5, Split6, Split7, Split8 |
| Worker3 | Split2, Split3, Split9 |
只有散列到离线工作节点(在我们的示例中为 worker3)的拆分需要重新散列。 其他数据不受影响。 如果 worker3 稍后上线,Split 2、3 和 9 将再次被 hash 到 worker3,不影响其他 worker 的命中率。
增加worker节点
现在,如果工作负载增加并且需要将另一个工作节点 worker4 添加到集群中。 Worker4 的散列值在散列环上如下:

在这种情况下 split8 将落入 worker4 的范围内,所有其他 split 的分配不受影响,因此这些 split 的缓存命中率不会受到影响。 新的任务是:
| Worker1 | Split1, Split4, Split6 |
| Worker2 | Split0, Split5, Split7 |
| Worker3 | Split2, Split3, Split9 |
| Worker4 | Split8 |
虚拟节点
从上面可以看出,一致性哈希可以保证在节点发生变化的情况下,平均只需要重新哈希Nsplits / Nnodes个splits。 然而,由于工人分布缺乏随机性,分裂可能不会在所有工人节点之间均匀分布。 引入“虚拟节点”的概念来缓解这个问题。 虚拟节点还可以帮助在断开连接时将节点的负载重新分配到多个节点,从而减少由于集群不稳定导致的负载波动。
每个物理工作节点都有多个映射到它的虚拟节点。 虚拟节点放在哈希环上。 拆分将分配给哈希环上的下一个虚拟节点,从而路由到映射到虚拟节点的物理节点。 以下示例显示了每个物理工作程序节点具有 3 个虚拟节点的可能场景:
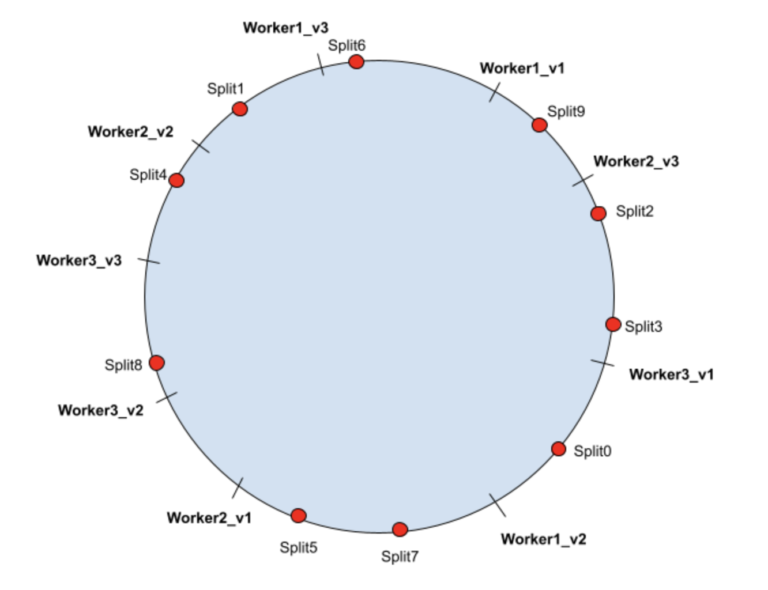
| Worker1 | Worker1_v1 | Split6 |
| Worker1_v2 | Split0 | |
| Worker1_v3 | Split1 | |
| Worker2 | Worker2_v1 | Split5, Split7 |
| Worker2_v2 | Split4 | |
| Worker2_v3 | Split9 | |
| Worker3 | Worker3_v1 | Split2, Split3 |
| Worker3_v2 | ||
| Woker3_v3 | Split8 |
随着散列环上节点数量的增加,散列空间更可能被均匀划分。
在某个物理节点宕机的情况下,该物理节点对应的所有虚拟节点都会被rehash。 但现在不再将所有拆分重新散列到同一个节点,而是将它们分布在多个虚拟节点上,从而映射到多个物理节点,提供更好的负载平衡。
下面显示了当 worker3 被移除时,Split2 和 3 被重新散列到 worker2,而 Split8 被重新散列到 worker1。

| Worker1 | Worker1_v1 | Split6 |
| Worker1_v2 | Split4, Split8 | |
| Worker1_v3 | Split1 | |
| Worker2 | Worker2_v1 | Split5, Split7 |
| Worker2_v2 | Split0, Split2, Split3 | |
| Worker2_v3 | Split9 |
如何在 Presto 中使用一致性散列?
这是我们最近为 Presto 贡献的一项实验性功能。 如果您对测试或合作感兴趣,请随时与我们联系。
要使用此功能,请首先按照本说明或本教程使用 Presto 启用缓存。
确保选择 SOFT_AFFINITY 作为调度策略。 在 /catalog/hive.properties 中,添加 hive.node-selection-strategy=SOFT_AFFINITY。
启用一致的哈希。 在 config.properties 中,添加 node-scheduler.node-selection-hash-strategy=CONSISTENT_HASHING。
结论
如上所示,当引入或移除节点时,一致的散列可以最大限度地减少工作负载分配的影响。当集群的工作节点发生变化时,基于一致的哈希调度工作负载可以最大限度地减少对现有节点缓存命中率的影响。这使得一致缓存成为一种更好的策略,可以在 Presto 的集群大小根据工作负载需求进行扩展和缩减的情况下使用,或者在部署无法完全控制硬件的情况下使用,并且工作人员可能会不时地重新定位。
在 Alluxio 社区,我们一直在不断改进 Alluxio 与数据应用程序(例如本文中的 Presto)之间的功能和可用性的集成。通过在 Presto 调度中引入一致性哈希,Alluxio 可以更好地利用 Presto 中软亲和的潜力,具有更高的数据局部性和缓存效率,这可以转化为更好的性能和成本效率。我们将继续为数据生态系统带来进一步的改进和优化。
本文转载自Alluxio,原文链接:https://www.alluxio.io/blog/using-consistent-hashing-in-presto-to-improve-caching-data-locality-in-dynamic-clusters/。