
总览
Alluxio 提供了一个全面的指标系统来监控 Alluxio 的 master、worker 和 client 的状态。 Alluxio 的指标系统支持各种指标,例如 嵌入式 JSON 接收器和 Prometheus 接收器。 用户和开发者可以通过实现 Sink 接口轻松地创建一个 Alluxio 的自定义 sink。
此外,Alluxio 在 Web UI 中提供了一个指标页面,显示了 Alluxio 的一些关键信息,例如字节吞吐量和存储空间。 但是,如果您想要更灵活和通用的监控,则需要进行额外的工作。
本篇博客将在10分钟内介绍腾讯如何使用Prometheus和Grafana搭建Alluxio监控系统。
Alluxio 指标系统是如何工作的
以下框架描述了 Alluxio 的指标系统。


监控的类型
Alluxio 指标由不同的源生成并由接收器使用。 度量系统定期轮询源并将度量报告传递给接收器。
有两种类型的指标。
- 集群指标:从工人和客户端聚合,然后由leading master汇总。 集群指标提供 Alluxio 集群的快照。
- 进程指标:由每个Alluxio进程收集,包括master指标、worker指标和client指标。

指标命名模式
一般来说,Alluxio 的指标遵循两种命名模式。 第一个是主指标,由 Master、metricName 和一些标签(可选)组成。 例如,Master.GetFileInfoOps。 第二个是针对非主指标,由 processType、metricName、tags 和 hostnName 组成。 例如,下面是工作人员的 openExistingFile 指标。 processType 是worker,metricName 是openExistingFile,后跟三个标签:user、UFS location 和UFS type。 最后一部分是worker的hostName。

从 Worker 到 Master 的指标流
由于master需要从workers和clients收集metrics来计算集群的metrics,clients和workers需要将他们的metrics报告给master。 下面是从 worker 到 master 的指标流图。 Worker 和客户端通过心跳将指标发送到 Alluxio master。 右边的块是工作进程,左边是主进程。 它从右到左。

心跳进程受BlockMasterSync控制,将worker的metrics等信息传递给RpcClient,Rpc服务器接收心跳,由MetricMaster处理workers的metrics。 指标存储在 MetricsStore 中,稍后将被聚合和计算。
客户指标以类似的方式处理。 有关详细信息,请参阅 Alluxio 源代码。
如何实现自定义 Alluxio Sink
Alluxio 支持多种类型的 sink。 接收器指定将度量传递到的位置。 例如Alluxio有Http JSON sink,默认开启,所以我们可以在Alluxio web UI中以JSON格式查看Alluxio指标的dashboard。 此外,Alluxio 提供了方便灵活的 sink 接口,供开发者和用户实现自己的 sink。
passive sink和active sink
下面列出了 Alluxio 支持的接收器。 一般来说,这些sink可以分为两类:passive sink和active sink。

这两种接收器的区别在于我们获取指标的方式:
- 主动:左边的截图是控制台。 如果我们启用 consolesink,指标将被打印到标准输出文件中,例如 master.out 或 worker.out。 consolesink 会定期报告指标,因此您可以随时获取指标。 从 Alluxio 的角度来看,它是主动 sink。
- 被动:右边的截图是HTTP JSON sink,也就是passive sink。 被动接收器作为服务工作。 只有当我们将请求发送到服务器时,我们才能获得指标。 例如,如果我们访问 Alluxio 工作服务器中的 metrics/json 位置,我们可以得到以下 JSON 格式的指标。

ConsoleSink 和 Prometheus Sink 的工作原理
ConsoleSink 结构如下所示。 我们可以在 ConsoleSink 中找到 ConsoleReporter。 它安排定期报告指标的报告。 我们可以看到 ScheduledReporter 的方法,在报告中,不同类型的指标以特定格式打印。

Prometheus sink 以完全不同的方式运行。 没有 ScheduledReporter 来报告指标,所以我们需要自己获取指标。
被动 sink 需要实现 getHandler 方法,这样才能启动 master 和 worker 进程。 例如,在主进程的 StartServingWebServer 方法中,将 Prometheus 处理程序添加到 webserver。 我们可以访问master web server的具体位置,就可以得到Prometheus格式的metrics。
E.g. MasterProcess


Implement the Sink
我们需要做的第一件事是确定我们想要实现哪种接收器,被动的还是主动的。 例如,Alluxio 的 XmlSink 将指标打印到特定路径,因此我们知道它是一个活动接收器。 就像 ConsoleSink 一样,我们需要实现 sink 接口,还要构造一个 XmlReporter 来以 XML 格式报告指标。 这给了我们一个定制的水槽。 之后,我们需要通过将我们刚刚定义的 XmlSink 类添加到 metrics.properties 来启用我们的接收器。 此外,我们可以以这种格式向我们的接收器添加一些属性。
conf/metrics.properties

同样,如果要实现被动接收器,可以参考 JSON 接收器或 Prometheus 接收器。
如何在 10 分钟内设置 Alluxio 监控
Alluxio Web UI Monitor
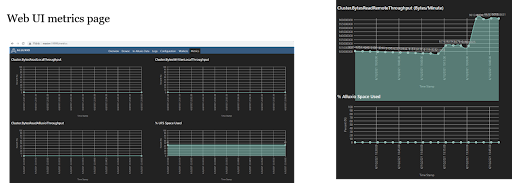
在 Alluxio Web UI 的 metrics 选项卡上,我们可以监控 Alluxio 集群的状态并获取有关 Alluxio 的一些关键信息。 尽管仪表板很方便,但有时可能会令人困惑(右侧的屏幕截图)。 此外,如果我们想要更多关于 Alluxio 的信息或具有更多视觉效果的仪表板,我们将需要另一个监控解决方案,这需要额外的努力。

我们使用 Prometheus sink 来连接 Alluxio 和 Grafana,因为 Alluxio 和 Grafana 都对 Prometheus 有很好的支持。 首先,Prometheus 从 Alluxio 服务器中抓取指标并将其转换为时间序列数据并存储它们。 然后 Grafana 服务器从 Prometheus 获取这个时间序列数据,之后 Grafana Web UI 将在仪表板中显示指标。
如何设置监控系统
设置此监控只需要四个步骤:
- 安装并启动 Prometheus 和 Grafana 服务器。 使用默认配置遵循教程非常简单。
- 将 Alluxio Jobs 添加到 Prometheus,它可以找到 Alluxio 服务器并自动抓取指标。 在 Grafana 部分,我们提供了 Grafana 仪表板模板,以便我们可以重复使用它来快速设置 Alluxio 仪表板。
- 下载并导入仪表板模板。
- 修改模板的变量,使其成为我们自己的仪表板。
这里 (16:03) 是有关如何导入仪表板模板的演示视频。
我们需要先将 Alluxio Jobs 添加到 Prometheus(参考指标部分中的 Alluxio 文档)。 现在我们在 Prometheus 中添加两个作业。 一个是Alluxio master,一个是Alluxio worker。 这里我们需要记录下job_name,用于导入Grafana仪表盘。

演示视频中的组件版本如下:
- Prometheus Version: 2.22.2
- Grafana Version: 7.5.6
- Alluxio Version: 2.5.0-3
以下是演示视频中设置的服务。 我们的集群中有两个节点,worker节点和master节点:
- Prometheus Server @ master:9090
- Grafana Server @ worker:3000
- Alluxio Master @ master
- Alluxio Worker @ worker
从下面的屏幕截图中可以看出,集群中有 8 个 live worker,监控系统运行良好,不同面板中的指标。


在仪表板中,我们还列出了不同行的标签。 可以在仪表板上轻松添加或删除面板。
- Alluxio IO 关键指标
- 阅读本地和阅读远程和活着的工人……
- 存储
- 已用空间和 UFS 已用空间……
- Workers区块
- 缓存块和驱逐块……
- 逻辑运算
- 挂载操作和文件固定…
- Alluxio 元数据操作
- 阻止心跳成本和获取状态成本……
- AsyncCache 块和操作
- AsyncCacheSuccessedBlocks 和 AysncCacheFailedBlocks …
- 掌握 JVM 内存
- 主堆内存和总内存……
总结
通过引入 Prometheus 和 Grafana,我们为 Alluxio 构建了一个更加灵活、敏捷、易用的监控系统。
本文转载自Alluxio,原文链接:https://www.alluxio.io/blog/how-to-set-up-monitoring-system-for-alluxio-with-prometheus-and-grafana-in-10-minutes/。