


公司介绍
中仑网络以零售技术为核心,为零售商户打造出集收银系统、中仑掌柜、微商城、汇邻生活平台、大数据平台、移动支付、智慧农贸、汇邻门店运营服务等为一体的新零售生态体系,实现线上线下全方位融合,为零售商家赋能增收。
业务背景
2020 年初,公司多个 BI 类系统的数据都存储在 MySQL 中,当时较大的表接近 1 亿的数据量,很多页面查询耗时较长,用户使用体验较差,有些实时多维分析页面甚至出现查询超时(耗时 >5min)的情况,为了解决这个问题,我们需要选择一款查询性能优越的开源数据库引擎。
一次偶然的机会,在朋友圈看到在美团工作的前同事分享的一篇介绍 Apache Doris 的文章,它的特性吸引了我的注意。于是我们团队开始研究 Apache Doris ,经过一个月左右的搭建集群和测试,最终决定引入这个开源项目。直至今天,Apache Doris 已经为我们的线上 BI 系统提供了一年半的服务。
选型调研
经过前期对 Presto、Druid、GreenPlum、Kylin、ClickHouse、Apache Doris 的全方位调研和借鉴行业大厂的使用经验,从查询性能、使用场景、运维成本这三个因素综合考虑,结合部门当前大数据平台的现状,最终选定 Apache Doris,多个组件相比之下,我们最为看重的是 Apache Doris 以下的优点:
-
集群搭建简单、运维成本低、扩容方便 -
单表查询和多表 Join 查询性能都很好 -
导入数据支持事务 -
支持实时导入
Doris 作为 BI 查询引擎
01 MySQL 迁移到 Doris
在 Doris 集群搭建完成并初步的测试后,我们首先做的是把 BI 类系统中原来存储在 MySQL 上的应用层表迁移到 Doris 上,之前从 Hive 同步到 MySQL 用的是 Sqoop,Hive 同步 Doris 则采用的是 Broker Load 方式,导入性能也比 Sqoop 快一些,而且不占用 Hadoop 集群的资源( Sqoop 任务是提交到 Yarn 上运行,Broker Load 是在 Doris 上运行),在凌晨 Yarn 资源紧张的情况下, Doris 承担了同步数据的任务,缓解了 Hadoop 集群的压力,在我们的架构中提升了整体数据链路的效率。
02 总体架构
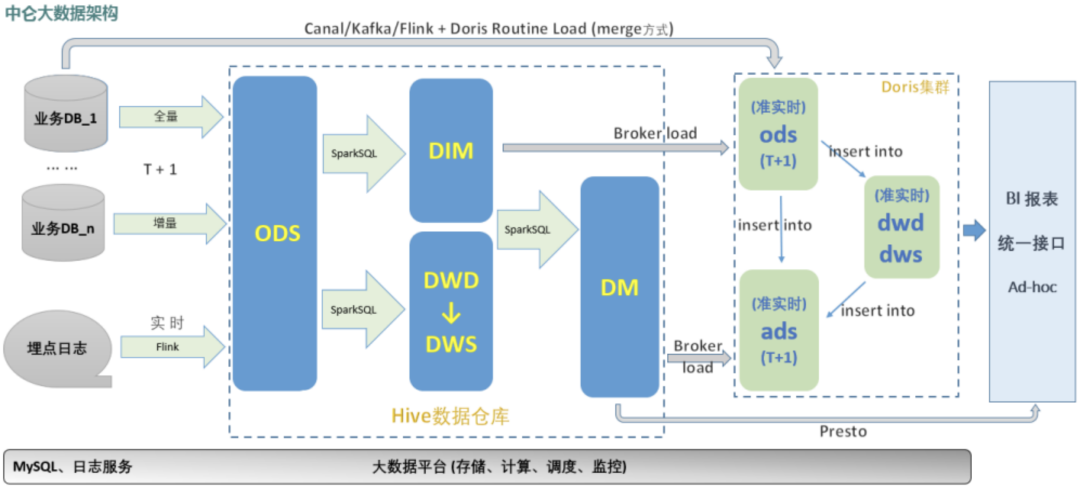
中仑大数据架构展示
03 优化总结
在使用 Doris 的过程中,我们反复研读 Doris 官方文档,遇到解决不了的问题也会在 Doris 社区和微信群里寻求帮助,都得到了及时的回复和解决,在这个过程中学会了一些优化技巧和参数设置,于是我们开始对线上运行的所有表进行优化,主要包括 数据模型优化、分区键字段调整、分桶数修改、前缀索引优化、创建物化视图 等,根据不同的业务场景合理使用三种数据模型,可以达到事半功倍的效果。
在过去的一年时间里,Doris 作为公司 BI 系统的查询引擎,整体查询性能得到很大的提升,目前绝大多数查询都是毫秒级,少数复杂些的实时多维分析查询在秒级,整体运行稳定,效果很好,相比之前性能有了质的飞跃。
基于 Doris 搭建准实时数仓与应用
Ⅰ.用户可以通过提交例行导入作业,直接订阅 Kafka 中的消息数据,以近实时的方式进行数据同步。Doris 自身能够保证不丢不重的订阅 Kafka 中的消息,即 Exactly-Once 消费语义。
Ⅱ. Doris 中存储的数据都是以追加(Append)的方式进入系统,这意味着所有已写入的数据是不可变更的。所以 Doris 采用标记的方式来实现数据更新的目的。即在一批更新数据中,将之前的数据标记为删除,并写入新的数据。
Ⅲ.在读取过程中,Doris 会自动处理这些标记数据(Merge-on-Read),保证用户读取到的是最新的数据。同时,Doris 后台的数据合并(Compaction)线程也会不断的对数据进行合并,消除标记数据,以减少在读取过程中需要进行的合并操作,加速查询。
Ⅳ.大部分对数据修改的场景仅适用于 Unique Key 数据模型,因为只有该模型可以保证主键的唯一性,从而支持按主键对数据进行更新。本文主要介绍如何使用 Unique Key 数据模型来进行数据更新操作。
Ⅴ.标记删除功能是对 DELETE 语句删除功能的一种补充。使用 DELETE 语句对数据删除,无法支持高频操作场景。另外,类似于 CDC(Change Data Capture)场景中,INSERT 和 DELETE 一般是穿插出现的。标记删除功能就是为了支持以上两种场景而做的功能。
开发流程
-
读取 MySQL 表的 Binlog 日志,过滤出 INSERT、UPDATE、DELETE 三种类型的操作日志; -
过滤出 Doirs 表所需的字段,并额外加上 0(更新/插入)和 1(删除)的标识字段,组装成标准 Json 格式(本次示例包含的字段有 shopcode, saledate, branchcode, ticketcode, orderstatus, billsource, tradeid,saletime, createtime, memberno, total, pdelete),Sink 到 Kafka Topic(命名为 demo); -
用处理好的 Topic 作为 Routine Load(merge)的数据源,在 Doirs 上创建 Unique Key 模型的目标表,然后创建 Routine Load 准实时( 30s/60s 频率)导入任务。
02 Doris 开发
Doirs 建表语句:
DROP TABLE IF EXISTS demo_rt_doris;CREATE TABLE demo_rt_doris (shopcode INT(11) NULL COMMENT "商户编号",saledate DATE NULL COMMENT "销售日期",branchcode VARCHAR(3) NULL COMMENT "门店编号",ticketcode VARCHAR(40) NULL COMMENT "订单编号",orderstatus INT(11) NULL COMMENT "订单状态",billsource INT(11) NULL COMMENT "交易渠道",tradeid INT(11) NULL COMMENT "交易类型",saletime VARCHAR(25) NULL COMMENT "销售时间",createtime VARCHAR(25) NULL COMMENT "创建时间",memberno VARCHAR(12) NULL COMMENT "会员卡号",total DECIMAL(18, 2) NULL COMMENT "订单总金额") ENGINE=OLAPUNIQUE KEY(shopcode, saledate, branchcode, ticketcode)COMMENT "订单表(实时)"PARTITION BY RANGE(saledate)(PARTITION p202106 VALUES [('2021-06-01'), ('2021-07-01')),PARTITION p202107 VALUES [('2021-07-01'), ('2021-08-01')),PARTITION p202108 VALUES [('2021-08-01'), ('2021-09-01')),PARTITION p202109 VALUES [('2021-09-01'), ('2021-10-01')),PARTITION p202110 VALUES [('2021-10-01'), ('2021-11-01')))DISTRIBUTED BY HASH(saledate) BUCKETS 1;
Doirs 参数设置
#显示隐藏列(删除标识)SET show_hidden_columns=TRUE;#启用标记删除功能ALTER TABLE demo_rt_doris ENABLE FEATURE "BATCH_DELETE";
创建 Routine Load 任务
CREATE ROUTINE LOAD zl_dwms.demo_rt ON demo_rt_dorisWITH MERGECOLUMNS(shopcode,saledate,branchcode,ticketcode,orderstatus,billsource,tradeid,saletime,createtime,memberno,total,pdelete),WHERE saledate>='2021-06-01',DELETE ON pdelete=1PROPERTIES("desired_concurrent_number"="3","max_batch_interval" = "60","max_batch_rows" = "200000","max_batch_size" = "104857600","format" = "json","strict_mode" = "false")FROM KAFKA("kafka_broker_list"="ip1:port, ip2:port, ip3:port","kafka_topic" = "demo","property.group.id" = "demo_group","property.kafka_default_offsets" = "OFFSET_BEGINNING");# OFFSET_BEGINNING可以改成指定的时间点
还可通过以下方式零代码构建实时 ODS 层,只需完成简单配置+SQL 就能实现
-
Flink CDC + Doris Flink Connector
-
Binlog Load (需 Apache Doris 0.15 以上版本)
-
用 Shell 脚本写了 Broker Load 任务监控(有错误状态会发出告警)和节点状态监控( palo_be/palo_fe 进程不存在的时候自动重启该节点)
-
基于 Prometheus + Doirs 社区的面板,搭建了一套监控系统,为 Doris 的运行提供了保障,在此不展开。
总结规划
目前公司数据仓库数据总量数十 TB ,正在保持快速地增长,Doris 集群近 10 台。HDFS 存储完整的全局数据(包含所有 ODS 表和全量历史数据),以 Spark SQL 离线批处理为主,每天离线作业 3000+ 。Doris 承担两个主要角色,一个是承接 Hive 上计算好的应用层结果表,作为 BI 类系统的查询引擎;另一个是作为实时数仓与应用的基础平台,值得肯定的是,这两个角色 Doris 都表现的很好,Doris Broker Load 每日任务 300+,Routine Load 任务 60+ 。作为 BI 查询引擎,查询性能较之前提升巨大;基于 Doris 构建的实时数仓与应用,极大简化了开发流程,并且提升了实时应用的稳定性。
随着公司业务的扩张,数据量正保持着快速增长,Doris 上的实时应用也在不断增加,基于 Doris 的实时方案正在应用到更多的业务场景中,为公司的运营决策提供更高的时效性。预计明年年初会对 Doris 集群进行扩容,我们也会紧跟社区的步伐进行版本升级,享受更多优秀特性带来的收益。最后衷心的感谢 Apache Doris 项目所有的贡献者。
– 作者介绍 –
王俊,大数据工程师,目前负责中仑网络科技有限公司大数据平台数仓建设,从事大数据相关工作7年,持续关注大数据开源项目,致力于湖仓一体方案的实践落地。
本文转载自Doris,原文链接:。