
背景:Kubernetes(k8s)/ack是一个开源的容器集群管理系统。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。
由于大数据集群资源使用庞大,成本高。资源使用存在潮汐现象,同样公司的业务体系也存在潮汐现象,并且对比资源使用情况,大数据集群和业务体系服务器正好形成错峰资源使用状态。线上业务只有白天会吃资源比较多,晚上所占的服务器资源比较空闲,这样可以让资源紧张的大数据生态去充分利用业务体系的空闲资源。结合k8s动态伸缩特性可以支持晚上大数据生态弹性错峰调度业务体系资源,达到资源共享目的,有效的节省成本,提高服务器资源利用率。
01
在离线混部实现方案
1、目标
-
资源共享,缓解“潮汐现象”;
-
推进云原生方案快速落地;
-
集群快速的弹性伸缩。
2、在离线混部方案
通过k8s的弹性扩缩能力,实现nodemanager的弹性扩缩容。具体方案图如下:
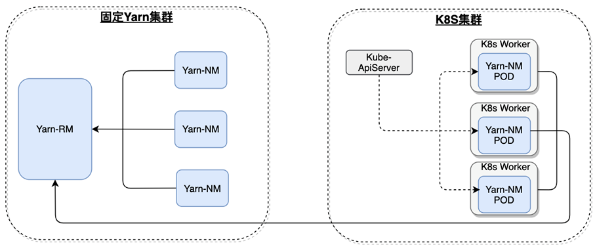

在离线混部方案实现过程
改造RM支持pod-NM的注册,主要解决了node_allow、nm address地址识别、网络、keytab自动生成等问题。完成RM的改造,k8s启动的pod-NM在RM中可以识别到并可以通过RM调度。
Pod镜像的适配由CDH安装部署方式调整为由pod中脚本拉起方式,主要解决了目录适配、权限适配、ldap适配、kerberos适配等。
Yarn node lable的实现,在FSAppAttempt assign container里面实现,添加检查:如果是k8s队列,判断当前节点是否是k8s节点,如果是分配container。
3、错峰调度方案
错峰调度方案是在离线混部方案的升级版本,主要实现了和业务错峰使用资源,具体方案如下:
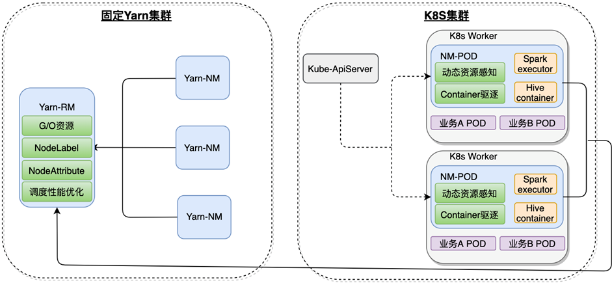
错峰调度方案是在离线混部方案的基础上增加了定时拉起pod-NM功能和定时驱离pod-NM功能。
02
Yarn和k8s压测对比数据
考虑到yarn集群和k8s的集群的特性,是否对job执行效率有影响,这次主要针对做的是hive和spark。
为了让业务稳定且不影响效率的前提下,任务运行到k8s上,需要科学的压测。经调研,业界有代表性的压测工具是TPC-DS和Terasort,这两个压测工具可以准确的压测反馈出集群的性能。
1、TPC-DS测试
1.hive组件压测
说明:分别用52个有效sql进行1TB、3TB、10TB的压测数据统计汇总对比,其中每个sql都会用到sum、avg、group by、order by、子查询、join等语法
a)1TB数据测试
总时长,yarn:5时35分58秒,k8s: 5时35分29秒,k8s快29秒,如下图
52个sql执行时间对比图如下: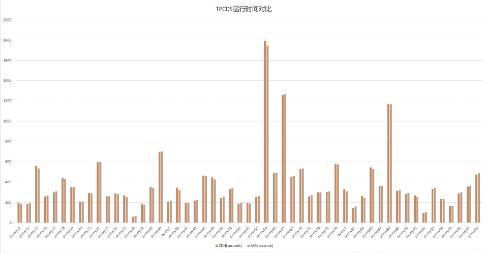
b)3TB数据压测
总时长,yarn: 7时42分31秒,k8s: 7时46分41秒,yarn快4分10秒,如下图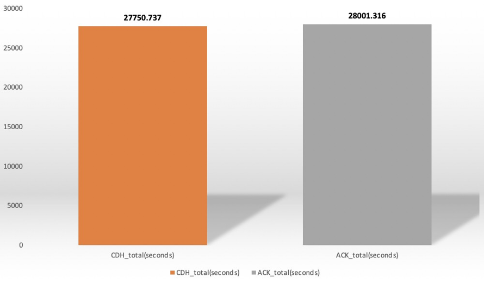
52个sql执行时间对比图如下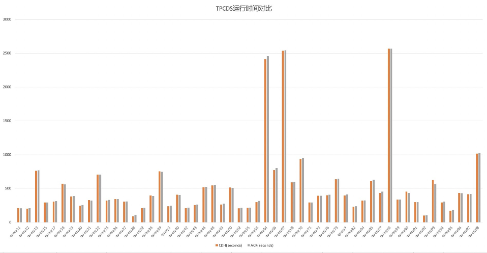
c)10TB数据压测
总时长,yarn: 12时42分24秒,k8s: 12时51分52秒,yarn快9分28秒,如下图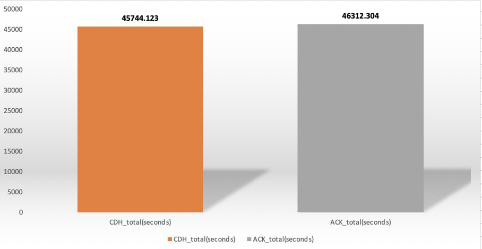
52个sql执行时间对比图如下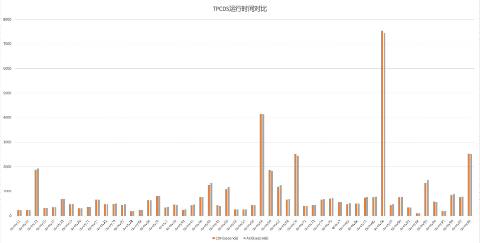
小结:tpc-ds分别在yarn和k8s计算节点上压测hive 52个sql的1TB、3TB、10TB数据,从分析统计数据和如上图看出,1TB数量的情况k8s有明显的优势,3TB和10TB的数据yarn具备优势,但是总体yarn和k8s节点环境hive作业执行效率差距不大,10TB以内的数据相差范围在1.5%以内,如下图: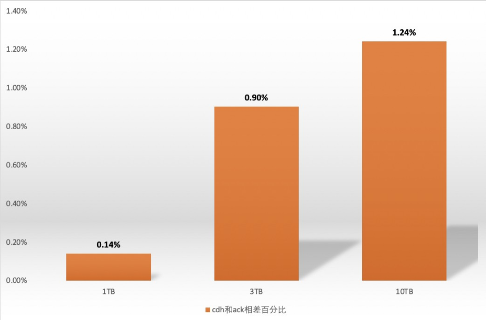
2.spark组件压测
说明:程序分别进行1TB、3TB、10TB数据的压测数据汇总分析。
yarn执行时间分别是:1时8分30秒、2时50分27秒、8时51分49秒,k8s执行时间分别是:1时7分59秒、2时48分59秒、8时47分26秒,k8s分别快了31秒、88秒、263秒。
yarn和k8s压测1TB、3TB、10TB数据对比图如下: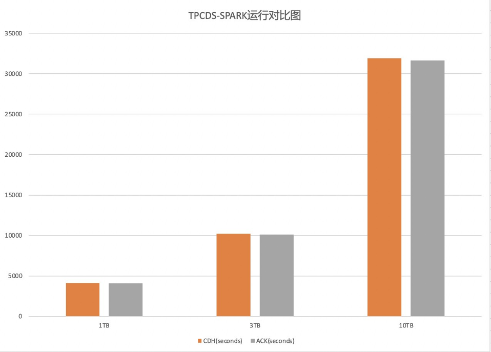
小结:tpc-ds压测spark 程序运行1TB、3TB、10TB数据,从分析统计数据和如上图看出,由于spark是内存计算型,因此yarn和k8s节点上spark程序执行效率相差不大,10TB以内的数据相差百分比范围在1%以内,如下图: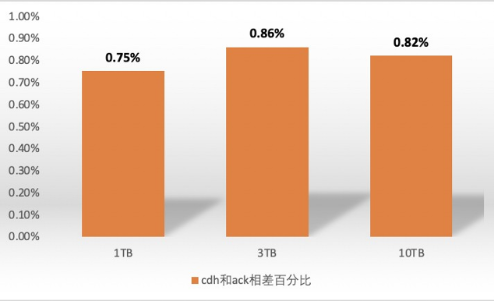
2、Terasort压测
说明:terasort按照10TB数据进行压测
hadoop组件压测,计算使用了90000map数和10000reduce数,执行平均时间yarn: 4时2分11秒,k8s: 5时19分9秒,10TB数据平均相差了1时26分10秒,两环境压测对比图如下: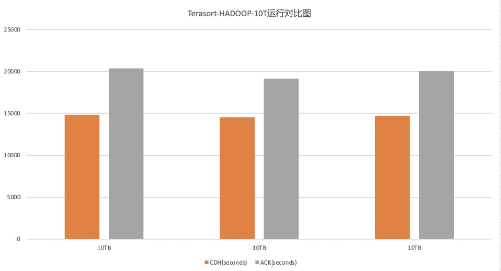
小结:terasort 10TB数据压测hadoop组件,由于在yarn上执行存在短路读现象,因此yarn要比k8s快了一个半小时.
1.spark组件压测
执行时间yarn:3时19分2秒,ack:2时27分1秒,k8s节点执行快了52分1秒,cdh和ack节点压测对比图如下:
小结:terasort压测hadoop和spark 10TB 数据,k8s执行效率快了52分1秒,但是总体差距不大。
3、压测总结
在yarn和k8s测试对比来看,MR程序在yarn(存在数据短路读)中有一定优势,从测试数据看会快1.5%。SPARK程序在yarn和k8s中耗时相当,从整体测试看在离线混部yarn和k8s相差不大,任务可以稳定的运行在yarn和k8s.
03
在离线混部生产运行情况
目前在离线混部方案,生产环境k8s有1000vcore资源,每天稳定运行600+任务。
生产环境已经完成驱逐container测试,可以在不影响任务的情况下驱逐pod-NM,为错峰调度实现提供了环境。
生产环境k8s任务和yarn任务时长对比,从图中可以看出,k8s队列和yarn队列任务运行时长大部分集中在5分钟以内。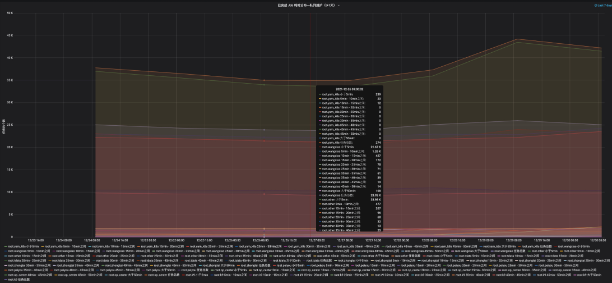
04
未来规划
1、存在问题
pod-NM资源固定:目前独立使用k8s为主,没有形成自动扩缩容。
规则固定:上线下线pod-NM不够灵活安全。
2、未来规划
云原生已经在整个互联网行业形成越来越明显的优势,大数据生态正在加速拥抱云原生。从成本角度和技术角度如何做好大数据生态的云原生?灵活的动态伸缩,智能化的动态预判,全链路的大数据生态和k8s监控。组成有效,可控的大数据在离线混部方案。逐步形成计算与存储分离,根据任务和数据的动态扩缩容。
本文转载自 常刚 好未来技术,原文链接:https://mp.weixin.qq.com/s/3eshy3f2j3_QyD34qWEOyA。