
本文翻译自《Apache BookKeeper Insights Part 1 — External Consensus and Dynamic Membership》,作者 Jack Vanlightly,Apache BookKeeper Committer。
译者简介
感谢两位社区志愿者的翻译,合作产出本中文版博客:
· 葛桂荣,社区昵称 ahahage,杭州美创科技有限公司 Java 工程师。
· 王中兴,就职于 eBay 消息中间件团队,社区昵称 AlphaWang。
系列介绍
BookKeeper 复制协议非常有趣,它与人们在消息领域习惯使用的其他复制协议大不相同,例如 RabbitMQ Quorum Queues、Red Panda 及 NATS Streaming 使用的 Raft 协议和 Apache Kafka 使用的复制协议。但与众不同意味着人们往往无法完全掌握 BookKeeper 的各项玩法,例如当 BookKeeper 的运行方式不符合预期时不知如何解决,又或是没能充分利用 BookKeeper 的各项优势功能。
本系列文章旨在帮助大家了解那些使 BookKeeper 与众不同的一些基本见解,详细分析该协议的一些细微差别。我们将深入研究 BookKeeper 复制协议背后的设计考量,以及这些设计决策所带来的结果。
对比是描述设计决策的最好方法之一,可以让我们很好地讨论权衡、优缺点等等方面。本系列文章将同时使用 Raft 和 Apache Kafka 作为比较对象,但本系列并不旨在宣传或说服用户 BookKeeper 比其他协议更好,而是要探讨 BookKeeper 协议的机制及其衍生的结果。
另外请注意,本系列文章旨在通过对比更好地帮助大家理解 BookKeeper,而不是对 Raft 或 Kafka 进行深入研究。我们将有的放矢地尽量多地介绍这些协议,但也会跳过大量复杂的细节。如果想深入学习 Raft 和 Apache Kafka,可以参考其协议文档。
本系列的第一篇文章会为大家介绍 BookKeeper 和其他复制协议之间的最大区别,帮助大家理解本系列后续文章中会谈及的协议间的细微差别。
集成协调 vs 外部协调
Raft 是一个“集成”协议。这里的集成是指控制平面和数据平面都集成到同一个协议中,并且该协议由所有对等的存储节点执行。每个节点都将所有数据存储在本地持久化存储中。
Apache Kafka 也是如此。之前通过 ZooKeeper 存储 Kafka 的元数据,尽管新版本可在不需要 ZooKeeper 的情况下运行 Kafka (KIP-500),但也将依赖于 ZooKeeper 的控制器改造成了基于 Kafka Raft 的 Quorum 控制器。
Raft 在稳定状态时会执行数据复制,一旦出现扰动会触发选举。选举出 Leader 后,Leader 节点会处理所有客户端请求并将 Entry 复制到 Follower。
在 Raft 中,Leader 可以了解每个 Follower 在日志中的位置,并根据这些位置将数据复制到每个 Follower。由于 Leader 在本地拥有所有状态,因此无论 Follower 落后多远,它都可以检索到 Follower 当前的状态并将其后的数据传输给 Follower。
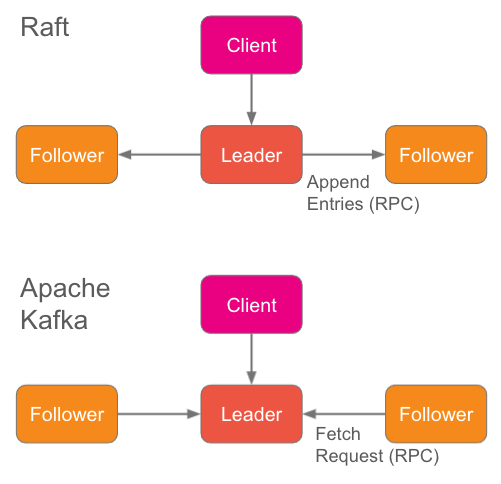

图 1. 集成复制协议,存储数据的有状态节点执行数据复制
在 Kafka 中,Follower 向 Leader 发送 fetch 请求,请求中包含它们的当前位置。Leader 因为在本地拥有所有状态,所以只需在本地检索下一个数据并将其发送回 Follower 即可。
有状态的完全集成节点执行复制时,集群成员相对静态。虽然用户可以执行集群操作来添加和移除成员,但这些操作不常发生且有限制。当协议正常运行时,可以认为 Raft 集群的成员和构成 Kafka 主题的副本没有发生变化。
BookKeeper 则不同,它将共识和存储分离开来。存储节点很简单,基本上仅存储和检索它们被告知的内容。这些节点本身与复制协议几乎毫无关联——复制协议位于存储节点的外部,封装在 BookKeeper 客户端中,由客户端将数据复制到存储节点。

图 2. 客户端执行复制
BookKeeper 旨在充当其他数据系统的分布式日志存储子系统,这个其他数据系统可以是消息系统或数据库。例如 Apache Pulsar 使用 BookKeeper 来存储主题和游标,每个 Broker 通过 BookKeeper 客户端从 BookKeeper 节点读取和写入数据。
客户端在存储节点外部且无状态,这会对协议其余部分的设计产生一些级联影响。例如,因为客户端在本地没有完整的状态,所以对待失败的处理方式就会不一样。
一个 Raft 节点宕机一个小时,也不会产生太大问题。当节点重新上线时,有状态的 Leader 很容易就能从该 Follower 离开的位置恢复复制数据。BookKeeper 客户端则没有这种功能。如果想恢复复制数据,它不可能将最后 X 小时的数据都存储在内存中,所以必须另寻他法。
因为复制和协调逻辑存在于存储节点的外部(即客户端中),所以客户端可以在发生故障时自由更改 Ledger 成员。这种动态成员机制是一个根本上区别于其他协议的功能,也是 BookKeeper 最引人注目的功能之一。
像 Pulsar 这样具有单独存储层的数据系统也有自身的缺陷,例如任何数据在到达磁盘之前需要额外的网络请求,并且必须运维单独的 Bookie 集群。BookKeeper 需要提供一些真正有价值的功能才能为 Pulsar 加码。幸运的是,BookKeeper 具有许多值得使用它的出色功能。
现在我们已经为大家搭建了认知,在后文中将进一步深入探讨如何将像 Raft 这样集成的、固定成员的协议与像 BookKeeper 这样外部共识、动态成员的协议进行比较。
提交索引
Raft VS Kafka VS BookKeeper
本文提到的三个协议每个都有提交索引(Commit Index)的概念,不过名称各不相同。提交索引是日志中的一个偏移量,在该偏移量及其之前的所有 Entry 都能在一定数量的节点故障中幸存下来。
对每个协议来说,Entry 都必须达到特定的复制因子才能被视为已提交:
-
• 对于 Raft 来说,复制因子是集群多数,保证已提交的 Entry 在任意少数节点(N/2)永久丢失后也能幸存下来。因此,Raft 要求多数仲裁确认 Entry 后才能认定该 Entry 已提交。
-
• 对于 Kafka 来说,复制因子取决于各种各样的配置。Kafka 通过使用客户端配置
acks=all以及 Broker 配置min-insync-replicas=[majority]支持多数仲裁确认机制。默认情况下,它只需要 Leader 持久化 Entry 即可确认该 Entry。 -
• 对于 BookKeeper 来说,复制因子是 Ack Quorum(AQ),保证已提交的 Entry 在(AQ-1)个节点永久丢失后也能幸存下来。
注意:由于每个协议都不同,我将 Entry 被认定为“已提交”所需的仲裁数称为提交仲裁数(Commit Quorum)。这是我自己为这篇文章发明的术语。
Raft 称日志中的这一点为提交索引(Commit Index),Kafka 称其为高水位(High Watermark),BookKeeper 称其为最后添加确认(Last Add Confirmed,缩写 LAC)。每个协议都依赖于这个提交索引来提供一致性保证。
在 Raft 和 Kafka 中,这个提交索引会在 Leader 和 Follower 之间传输,因此每个节点自己都保存了一份当前提交索引的值。Leader 总是知道提交索引的最新值,而 Follower 的值可能滞后,但这没关系。
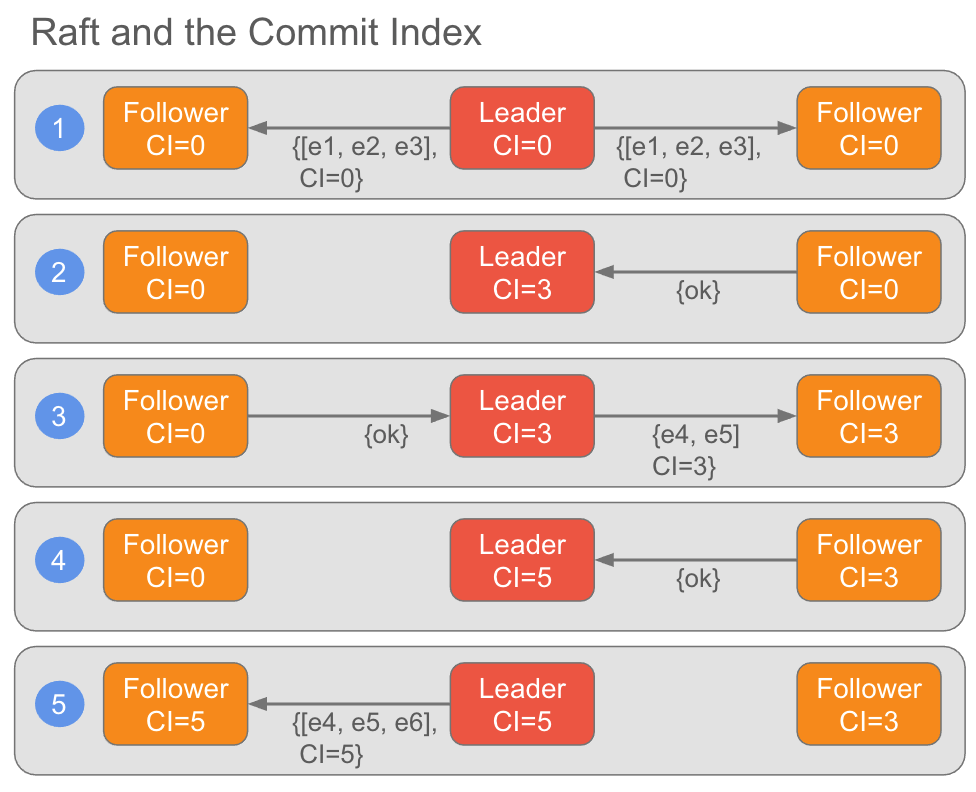
图 3. 所有节点都有自己的当前(有时数据滞后)提交索引的信息
在 Kafka 中,Leader 在其对 Follower 的 fetch 响应中包含高水位的信息。
在 BookKeeper 中,LAC 包含在发送到各存储节点的每个 Entry 中。存储节点本身几乎不会用到 LAC,但客户端之后可以检索此重要信息。因此,正在写入 Ledger 的客户端知道当前的 LAC,而存储节点的 LAC 信息可能有滞后,但这也没问题,复制协议会处理这种情况。稍后会详细介绍。

图 4. 客户端可检索当前最新的 LAC,而 Bookie 的 LAC 信息往往会滞后
超过提交索引的读取是脏读,无法保证能够再次读取到相同的 Entry。提交索引之后的 Entry 可能会丢失或被不同的 Entry 替换。出于这个原因,各个协议都不允许读取超过提交索引的数据。
特性和行为
Raft VS Kafka
对于基于 Raft 的系统,需要指定复制因子,这决定了 Raft 集群中有多少个成员。Kafka 也需要指定复制因子,这决定了主题有多少个副本。
固定成员
稳定状态下执行数据复制时,Raft 成员和 Kafka 副本固定不变。成员固定所带来的一个后果是复制因子、可用性和延迟之间的冲突。理想情况下,我们希望每个 Entry 在确认前都被完全复制。但是 Follower 可能宕机或者变慢,而大多数人都无法接受仅仅因为单个节点不可用就导致整个集群不可写。为此采取的折中办法是,略微降低安全性以获得较好的可用性和低延迟。在允许少数成员不可用的情况下仍然提供良好的数据安全性和持续的可用性。
这就是为什么 Raft 和 Kafka 需要一个低于复制因子的提交仲裁(Commit Quorum)。
安全性的降低通过增加复制因子即可缓解。如果想保证已提交的 Entry 在丢失 2 个节点后仍然存活,那么需要指定复制因子为 5。这会增加存储和网络开销,并稍微影响延迟,不过只需要 4 个 Follower 中最快的那 2 个确认 Entry 即可返回确认给客户端。因此即便有 2 个慢速节点,延迟也是可接受的,同时复制因子也达到最小。
属性
首先介绍一下不变量(Invariant)和活性属性(Liveness Property)的概念。不变量是指在任何时候都必须为 true 的事情。通过随时查看系统状态可以验证其状态是不是不变量。例如,一个不变量可以是任何已提交 Entry 都不会丢失。
活性属性则告诉我们在某个时刻一定会发生什么。例如,假定多数节点最终都能正常工作并对彼此可见,那么最终一定能选出 Leader。
本文讨论的集成日志复制协议至少具有以下不变量:
-
1. Entry 按照时间顺序追加到 Leader 的日志中。
-
2. Leader 按照相同顺序将 Entry 追加到 Follower 的日志中。
-
3. 只要大多数节点没有宕机并丢失所有数据,那么已提交的 Entry 永远不会丢失(仅适用于 Kafka 中 ack=all 且 min-insync-replicas=[majority] 的情况)。
-
4. 在 Follower 的已提交索引及其之前,Follower 节点上的日志与当前 Leader 的日志完全相同。
集成日志复制协议的一个活性属性是,假定所有节点都正常运行并对彼此可见,那么最终任何给定的已提交 Entry 都将被完全复制(前提是在此之前的日志也被完全复制)。换言之,日志尾部最终会达到所需的复制因子。

图 5. Raft 和 Kafka 日志的三种安全区域
我们可以认为 Raft 日志能分成 3 种安全区域。其一是“未提交区域(Uncommitted)”,指处于日志头部、在已提交索引之外的危险区域,这里的 Entry 没任何保证,可能会丢失。剩下两个区域),分别是已达到多数仲裁但尚未完全复制的“已提交头部(Committed Head)”,以及已完全复制的“已提交尾部(Committed Tail)”。
Prefix RF >= Entry RF >= Suffix RF对于任意给定的日志偏移量,该点之前的必定达到相同或者更高的复制因子,该点之后的必定达到相同或更低的复制因子。
那么这一切对管理员意味着什么呢?
当一切运行顺利时,预计未提交区域很小,已提交头部很小,而已提交尾部则非常大。然而事情并不总是顺利,已提交头部/尾部可能是任意长度——尾部长度可能为 0,意味着没有完全复制的条目。这可能是因为 Follower 太慢(并超过了数据保留期),或者 Follower 刚刚灾难性地宕机并重启。
这里的关键点在于复制因子并不是一个保证,而是一个期望的目标。唯一能保证的是提交仲裁。所以说提交仲裁是最小能保证的复制因子。作为管理员,需要围绕该值而不仅是复制因子来规划流程和计划。这就是为什么有些人使用复制因子 5 来运行 Raft 和 Kafka。
故障恢复
使用集成复制协议的系统可以“相对”简单地从整个磁盘故障中恢复。空的 Follower 可以通过当前 Leader 重新填入数据,这个过程和大多数追赶的 Follower 完全相同。数据复制保证了能从故障中成功恢复。
易于推理
上述这些特性使得对 Raft/Kafka 日志状态的推理变得相对简单:
-
• 因为成员是固定的,所以可以确认数据的位置。
-
• 仅日志头部的副本可能等于或少于提交仲裁。
-
• 如果失去一个成员,可以通过复制协议从有状态的对等方重新恢复。
-
• 复制因子是一个目标而非一个保证,因为已提交头部和已提交尾部可能是任意长度,所以可能需要将复制因子设为一个较大的值。
现在让我们同样来看看 BookKeeper。
BookKeeper 的特性和行为
BookKeeper 也有类似的配置来表示期望的复制因子以及提交仲裁。
注意:本文假设 Ensemble Size 和 Write Quorum 相等,因为条带化会降低读取性能,在实践中不值得采用。
Write Quorum(WQ)是 BookKeeper 的复制因子,Ack Quorum(AQ)则是 BookKeeper 的提交仲裁。大多数人简单地将 Ack Quorum 设置为多数仲裁,如果 Write Quorum 为 3,则 Ack Quorum 设为 2。因此可以合理地预期在 BookKeeper 内设置 WQ = 3 且 AQ = 2 的话,其行为与 Raft 或 Kafka 相同。
然而实际上是 WQ 和 AQ 在 Raft 或 Kafka 中并没有对等概念。想要理解其原因,我们需要更仔细地研究外部共识和动态成员协议。
外部无状态客户端
BookKeeper 的复制和共识逻辑封装在客户端内。而客户端是无状态的,在 Bookie 可用之前,它无法将数据保存在内存中(无论保存多久都不行)。因此它灵活简单地选择一个新 Bookie 来替代无法写入数据的 Bookie,然后继续工作。这种动态的成员变化称为 Ensemble Change。

图 6. 客户端写入 bookie3 失败后,执行一次 Ensemble Change
这种 Ensemble Change 基本上就是对 ZooKeeper 中 Ledger 的元数据进行一次更新操作,并将所有未提交的 Entry 重新发送到新 Bookie 上。
Ensemble Change 的结果是,Ledger 可以被认为是由一系列 mini-log(我们称之为 Fragment,即片段)构成的更大的日志。每个片段都有一系列连续的 Entry,其中每个 Entry 都共享相同的 Bookie(即 Ensemble)。每当客户端写入 Bookie 失败时,都会进行一次 Ensemble Change,并继续写入。这就创建出了由一个或多个片段组成的 Ledger。
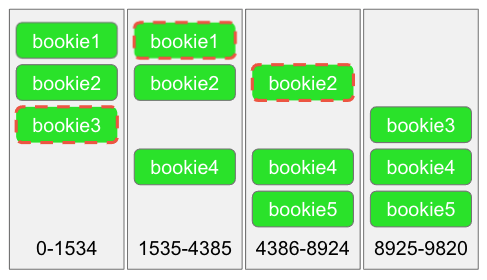
图 7. 一个由 4 个片段组成的 Ledger。
如果细究每个片段,就会看到类似 Raft 日志和 Kafka 主题分区的模式。当前片段也可以被分为与其相同的三个区域:已提交尾部、已提交头部和未提交区域。

图 8. 活跃片段的三个安全区域
当发生 Ensemble Change 时,当前片段终止于已提交头部的末尾(即那些已经达到 Ack Quorum 的 Entry)。新片段则开始于未提交区域的开头。
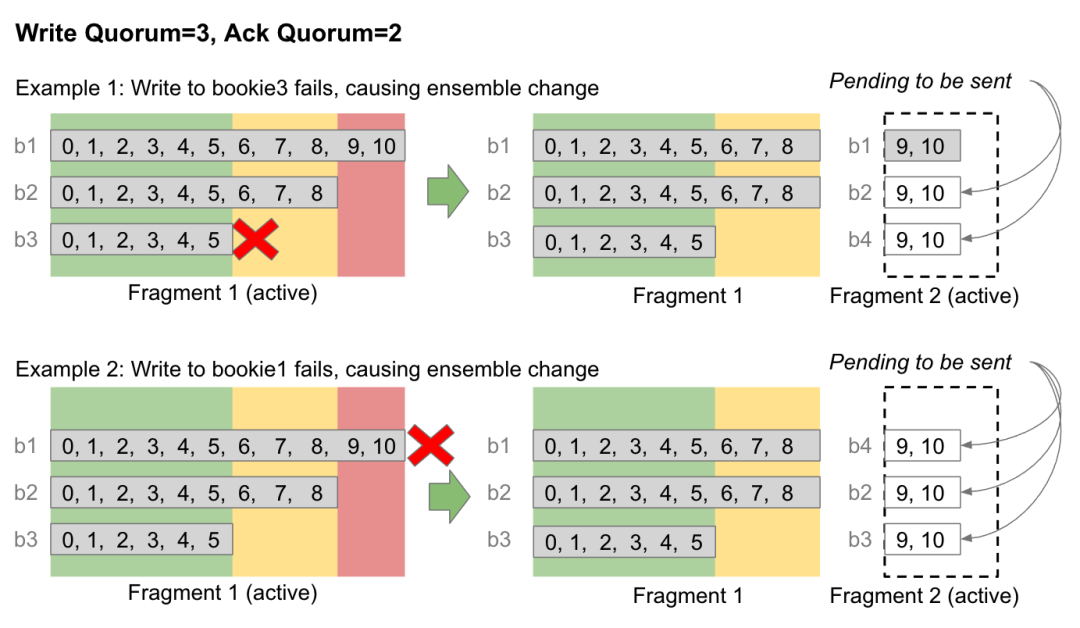
图 9. Ensemble Change 将未提交 Entry 移动到下一个片段
这样非活跃片段就会包含保留在 Ack Quorum 中的 Entry。与 Raft 或 Kafka 不同,BookKeeper 核心复制协议不会最终复制这些 AQ Entry 以达到 WQ——它们将保留在 Ack Quorum 中。这些 Entry 只能通过单独的恢复过程进入 WQ,而这个恢复过程并不是核心协议的一部分(如果启用恢复过程,则默认情况下每天运行)。Ledger 可能如下所示:
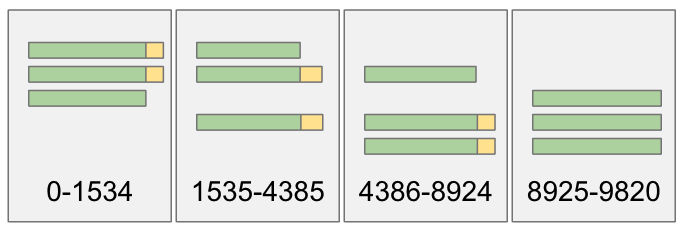
图 10. Ensemble Change 只将未提交 Entry 移动到下一个片段,而将已提交 Entry 保留在原始片段
不仅 Ledger 头部有 AQ Entry,Ledger 其他部分也会有这种低于复制因子的 Entry。

图 11. Ensemble Change 将 AQ 复制块留在 Ledger 中间
与 Raft/Kafka 只有头部有 AQ Entry 的模式不同,BookKeeper Ledger 中间的部分可能包含 AQ Entry。需要注意的是 Raft 和 Kafka 日志可能有任意长度的已提交头部,其中的 Entry 仅达到提交仲裁但未达到复制因子。所以无论是对 Kafka 还是 BookKeeper 管理员来说,提交仲裁才是最重要的。
刷新你的 Ack Quorum 认知
BookKeeper 使用外部复制机(即客户端),因此选择提交仲裁时有很大不同。本质上,BookKeeper Ack Quorum 与 Raft 和 Kafka 中的 Ack Quorum 并不真的相似。
如前所述,由于 Raft 和 Kafka 是固定成员的,所以它们确实需要一个低于复制因子的提交仲裁,否则会有严重的可用性和延迟问题。提交仲裁是在安全性和可用性/延迟之间的一个折中办法。
然而 BookKeeper Ledger 则不同,它并没有固定成员。如果一个 Bookie 不可用,我们会将其换成另外一个并继续。这使得 Ack Quorum 并不等同于 Raft 的多数仲裁或者 Kafka 中配置的仲裁。
对于 BookKeeper,我们可以将提交仲裁设置为等于复制因子,即 WQ = AQ。如果我们设置 WQ = 3、AQ = 3,一个 Bookie 宕机后可以选择一个新 Bookie 继续。请注意当 WQ = AQ 时,没有已提交头部、已提交尾部及未提交等三个区域,当前状态下的 Entry 或是完全复制并提交,或是完全未提交。
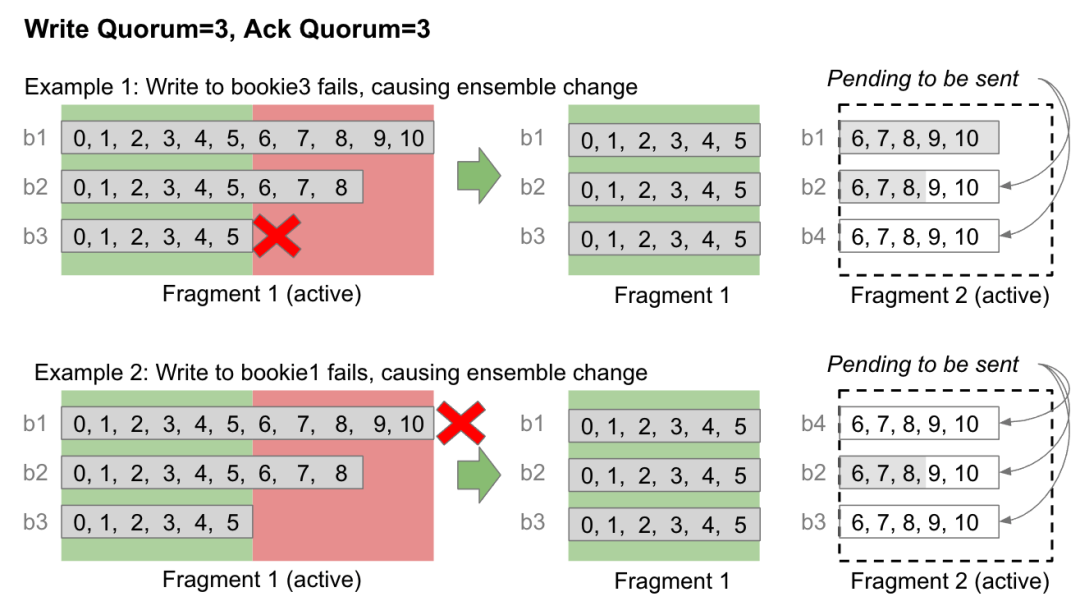
图 12. 当 WQ = AQ 时,Entry 要么完全复制,要么完全未提交。Ensemble Change 后原始片段处于完全复制状态
这也意味着 Ledger 中间不存在低于复制因子的部分,整个日志尾部都达到了 WQ。
这样很大地保证了数据安全。BookKeeper 不需要靠多数仲裁即可保证高可用,我们可以让 BookKeeper 只确认那些完全复制的 Entry。
当然,在将 AQ 从多数仲裁切换到复制因子之前,需要考虑一些限制和影响。
首先,使用 WQ = AQ 同时又不损失可用性仅适用于 Bookie 足够多的场景。如果只有 3 个Bookie 并且设置 WQ = 3,那么就跟 Raft 一样是固定成员。如果有 4 个 Bookie,那么一旦一个 Bookie 宕机,就会再次降到 3 并成为固定成员。所以 Bookie 数量要远大于 3,建议选择更多的小 Bookie,而不是更少的大 Bookie。如果 Bookie 数量小于或等于 5 个,那么最好还是设置 AQ
其次,设置 WQ = AQ 时,可用性会受到少许影响,因为可用性还取决于随后对 ZooKeeper 的操作。一旦写入 Bookie 失败,我们必须能够完成一次 Ensemble Change,以便可以恢复并确认 Entry。不同于 Raft 和 Kafka 理论上无上限的日志,Ledger 是小而有界的日志。Ledger 由日志片段组成,会不断地被创建和关闭(需要成功地操作元数据),所以如果不更改元数据,则无法长久运行。
最后,因为 Ensemble Change 会增加写入延迟,所以写入延迟的变化会更大。通常情况下 Ensemble Change 会非常快,但如果 ZooKeeper 负载很大,那么 Ensemble Change 则可能变慢,从而导致写入延迟出现毛刺。因此,如果对延迟要求非常高的话,那么就需要将 AQ 设为多数仲裁。
当复制因子 = 2
为什么 Raft 集群的成员不能是 2 个?因为在这种情况下,单个节点宕机会导致整个集群无法工作。虽然有冗余,但却比单节点的可用性更差。与 Kafka 类似,我们可以设置复制因子为 1 或者 3,但不能是 2。为了保证复制因子为 2,需要设置 min-insync-replicas = 2。因此当一个副本宕机,就会遇到和 Raft 一样的问题。
然而在 BookKeeper 内可以将复制因子设为 2。简单地设置 WQ = 2 且 AQ = 2,既能获得冗余又不会在单个节点宕机的情况下失去可用性。
总结
这是本系列的第一篇文章,重点介绍了 BookKeeper 的外部共识和动态 Ledger 成员,并将其与 Raft 和 Apache Kafka 这种固定成员的传统完全集成协议进行对比。
BookKeeper 的动态成员机制让它不需要降低安全性和可用性/延迟任一性能。如果保守地配置 Raft 的话,可能会设置复制因子为 5,来保证 2 个节点宕机时仍能存活;对于 BookKeeper 来说,设置复制因子为 3 就能达到类似结果。甚至可以选择 WQ = 4、AQ = 3 来减少慢速 Ensemble Change 带来的额外延迟。在设置 Write Quorum 和 Ack Quorum 时,BookKeeper 的用户自由度非常大。
当 AQ
BookKeeper 与 Raft 和 Kafka 等集成协议的区别绝不仅仅是这些。要详细理解 BookKeeper 复制协议的话需要考虑更多。
最后,本文乃至本系列文章的目的都不是试图进行两两比较来评判系统的优劣。其他集成协议与 BookKeeper 只不过是有不同的权衡与侧重,不能单纯地评估二者优劣。本文中的对比仅为以更易懂的方式普及概念。
本文转载自 Jack ApachePulsar,原文链接:https://mp.weixin.qq.com/s/i2CzmL8k2EKbjxNlW0OG6w。