
导读 本文主要内容包括:
1. 云平台上统一 UDF 的实现
2. 字节内部平台的实现
3. 贡献到开源社区的相关内容
4. 未来工作
分享嘉宾|张砚炳 字节跳动 软件开发工程师
编辑整理|陈业利 英祐科技
出品社区|DataFun
01


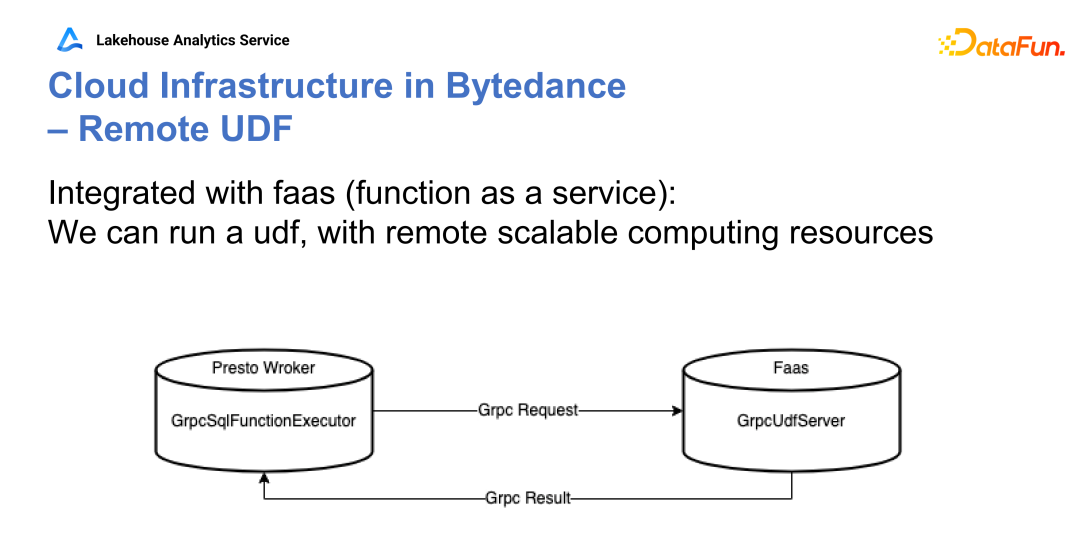
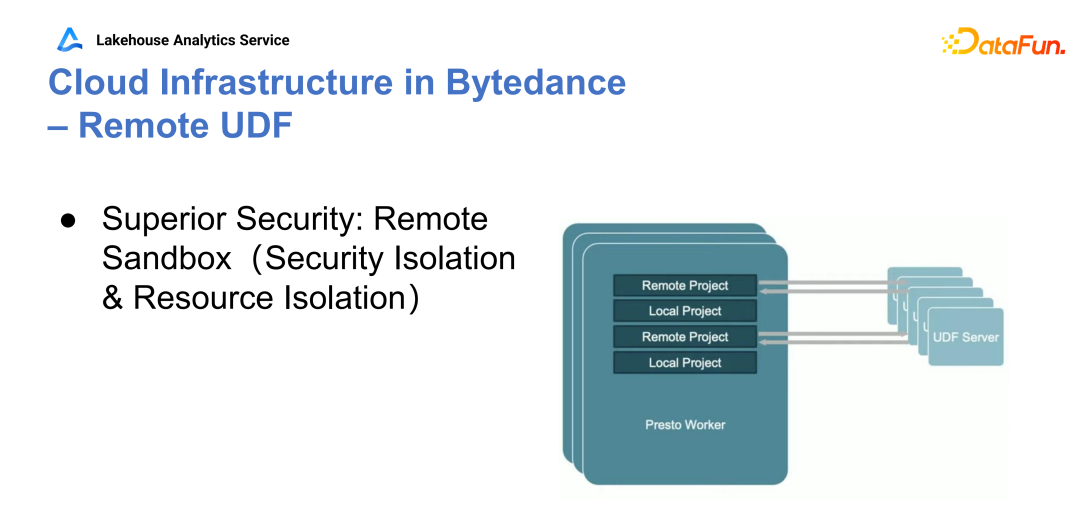


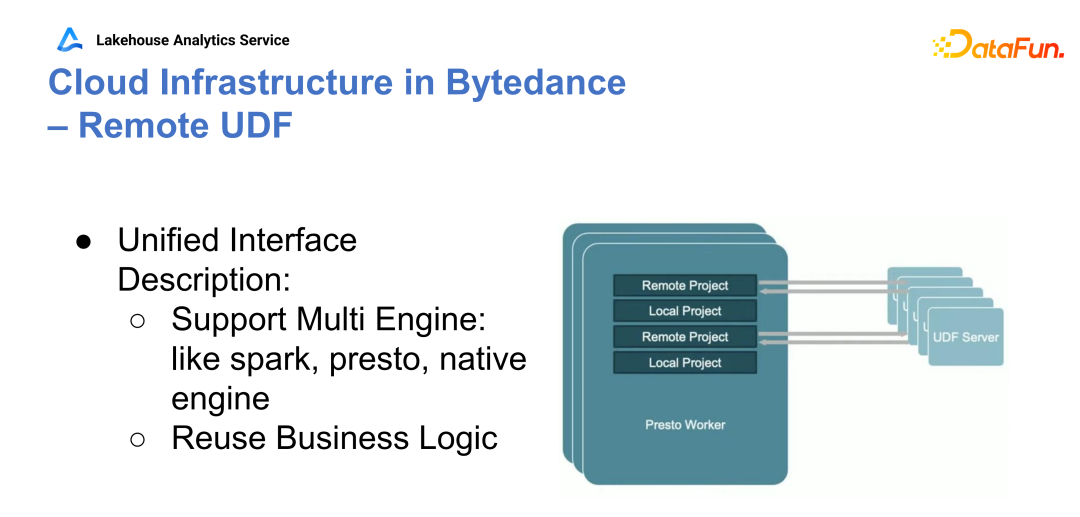






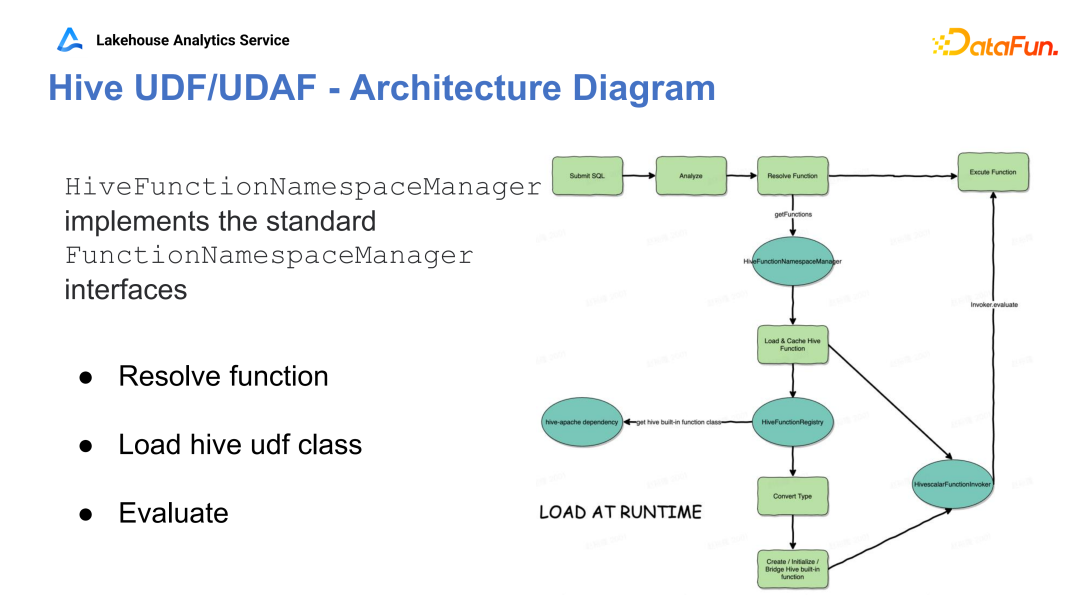





Q1:贡献的 PrestoDB 的 Hive UDF 的一部分,Hive 的支持函数?


分享嘉宾
INTRODUCTION

张砚炳
字节跳动
软件开发工程师
字节数据引擎部门、 Presto 相关研发。
本文转载自张砚炳 DataFunSummit,原文链接:https://mp.weixin.qq.com/s/K9UNRYObAwqtBeFGk2crvA。