+
摘要:本文整理自阿里巴巴高级技术专家朱翥、阿里巴巴高级技术专家贺小令在 9 月 24 日 Apache Flink Meetup 的演讲。主要内容包括:
-
Adaptive Batch Scheduler
-
Speculative Execution
-
Hybrid Shuffle
-
Dynamic Partition Pruning


Flink 是流批一体计算框架,早些年主要用于流计算场景。近些年随着流批一体概念的推广,越来越多的企业开始使用 Flink 处理批业务。
虽然 Flink 在框架层面天然支持批处理,但在实际生产使用中依然存在问题。因此在近几个版本中,社区也一直在持续改进 Flink 批处理问题,这些改进体现在 API、执行与运维三个层面。
在 API 层面,我们一直在改进 SQL,完善其语法,并使其能够兼容 HIVE SQL;我们也在完善 DataStream 接口来更好的支持批处理作业开发。在运维层面,我们希望 Flink batch 能够更易于在生产中使用,所以我们完善了 history server ,以更好地展示作业在运行中以及结束后的状态,同时也引入了兼容 Hive 生态的 SQLGateway。在执行层面,我们对于算子、执行计划、调度、网络层都进行了性能与稳定性的改进。
其中一个主要思路是根据运行时信息,比如数据量、数据模式、执行时间、可用资源等,自适应地优化作业执行,包括根据数据量自动为作业节点设置合适的并发度,通过预测执行来发现与缓解慢节点对作业的影响,引入自适应数据传输方式来提高资源利用率与处理性能,对多分区表进行动态分区裁剪来提高处理效率。
这些改进,有的使得 Flink 批处理更易于使用,有的对批处理作业的稳定性提供了保障,有的提升了作业执行性能,或是兼而有之。
此前,作业上线前都需要进行并发度调优。对于批处理作业的用户而言,他们遇到的情况是这样的:
-
批处理作业往往非常多,对作业进行并发度调优会是非常大的工作量,费时费力。
-
每日数据量可能都在变化,特别是大促期间数据会有数倍乃至数十倍的增长,因此很难预估数据,导致调优困难。同时,如果要在活动前后更改并发度配置,也会更加耗费人力。
-
Flink 由多个计算节点串联而成的执行拓扑组成。中间节点由于算子复杂性以及数据本身的特质,难以预判数据量,很难进行节点细粒度的并发度配置。而一个全局统一的并发,则可能导致资源浪费,乃至额外的调度部署、网络传输的开销。
-
此外,SQL 作业,除了 source 和 sink 外,只能配置全局统一的并行度,没法进行细粒度并行度设置,因此也会面临资源浪费与额外开销的问题。
为了解决问题,Flink 引入了自适应批处理调度器,用户可以配置希望每个并发实例处理的数据量, Flink 会根据运行过程中实际各个节点的数据量自动决定各个逻辑节点的实际并发度,从而保证每个执行并发处理的数据量大致符合用户预期。
以上配置方式的特点是配置与数据作业的数据量无关,因此比较通用,一套配置可以适用于很多作业,不需要单独为每个作业进行调优。其次,自动设置的并行度能够适配每天不同的数据量。同时,因为可以在运行时采集到每个节点实际需要处理的数据量,所以能够进行节点粒度的并行度设置,实现更优的效果。
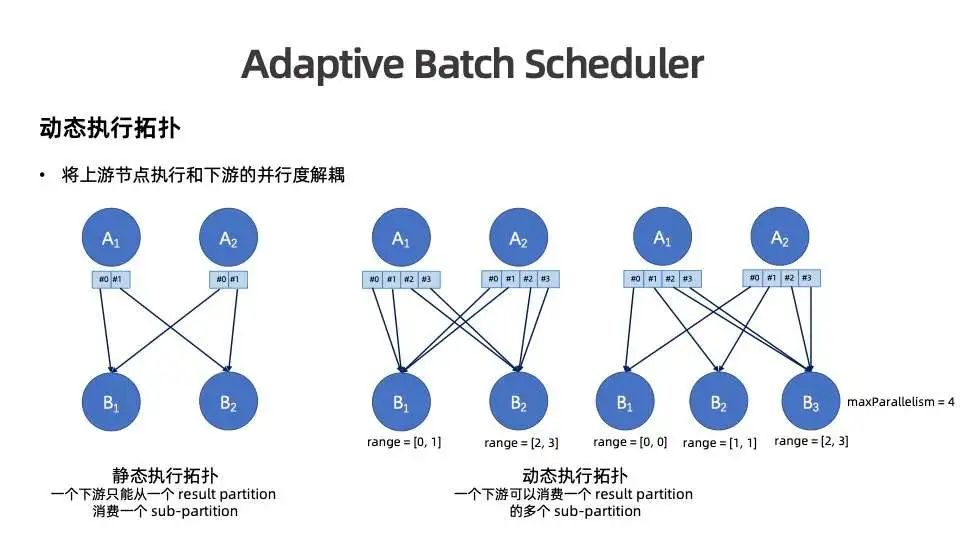
其流程如上图所示:当上游逻辑节点 A 的所有执行节点执行完并产出数据完毕后,可以采集产出数据总量,即节点B要消费的数据量。然后将信息交给并行度计算策略组件计算合适的并行度,动态生成执行节点拓扑进行调度与部署。
在传统 Flink 执行中,执行拓扑是静态的,作业提交过程中即已知所有节点的并行度,因此上游在执行时即可为下游每一个消费它的执行节点划分单独的数据子分区。下游启动时只需读取对应数据子分区即可获取数据。但是在动态并发度的情况下,上游执行时下游并发度还未确定,因此需要解决的主要问题是使上游节点的执行与下游节点的并发度解耦。
为了支持动态执行拓扑,我们进行了以下改进:上游节点产出的数据分区数不由下游并发度决定,而是根据下游最大分并发度来决定。
如上图右侧所示,下游可能有四个并发,可以将 A 产出的数据分为四份,则下游实际决定的并发可能会有一个、两个、三个、四个,然后再为每个节点分配消费的分区范围。比如下游并发为 2 时,各自消费两个数据分区;下游并发为 3 时,可能有的消费一个数据分区,有的消费两个。最终使得上游节点执行不再受到下游并发度的制约,能够进行灵活的数据分配,动态执行拓扑的理念也得以实现。
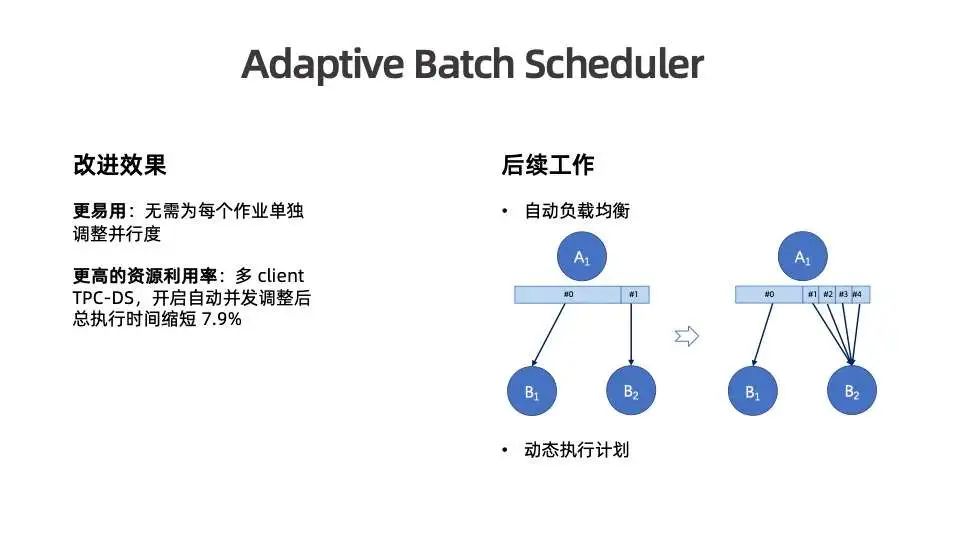
自动并发度能够实现两方面的效果:其一,用户不再需要为每个作业单独配置并行度, Flink batch 的使用更简单;其二,细粒度并发度设置可以提高对资源的利用率,避免无意义的大并发度。我们通过多 client TPC-DS 尽可能打满集群进行测试,开启了自适应并发度设置后,总执行时间缩短 7.9% 。
自适应批处理调度也为后续优化提供了很好的基础。基于灵活的数据分区与分配方式,能够采集各个数据分区的实际数据量,从而在比如有数据倾斜导致各个分区大小不一的情况下,可以将小分区合并,交给同一个下游处理,使下游节点处理的数据比较均衡。
其次,由于引入了动态执行拓扑的能力,可以根据执行时的信息来动态制定更优的执行计划。比如可以根据 join 节点两端各自的数据量大小来决定应该采用何种 join 方式。
生产中的热点机器无法避免。比如用户生产中作业会跑在混部集群或批作业的密集回刷等都可能导致某些机器负载特别高,使得运行在该节点上的任务远远慢于其他节点上的任务,从而拖慢整个作业的执行时间。同时,偶发的机器异常也会导致同样的问题。这些缓慢的任务会影响整个作业的执行时间,使得作业的产出基线无法得到保障。成为了部分用户使用 Flink 来进行批处理的阻碍。
因此,我们在 Flink 1.16 中引入了预测执行机制。
开启预测执行之后,如果 Flink 发现批处理作业中有任务明显慢于其他任务,则会为其拉起新的执行实例。这些新执行实例会与原来的慢任务实例消费同样的数据并且产出同样的结果,而原先慢任务的执行实例也会被保留下来。最先完成的实例会被调度器认可为唯一完成的实例,其数据也会被下游发现与消费。而其他实例会被主动取消,数据会被清除掉。
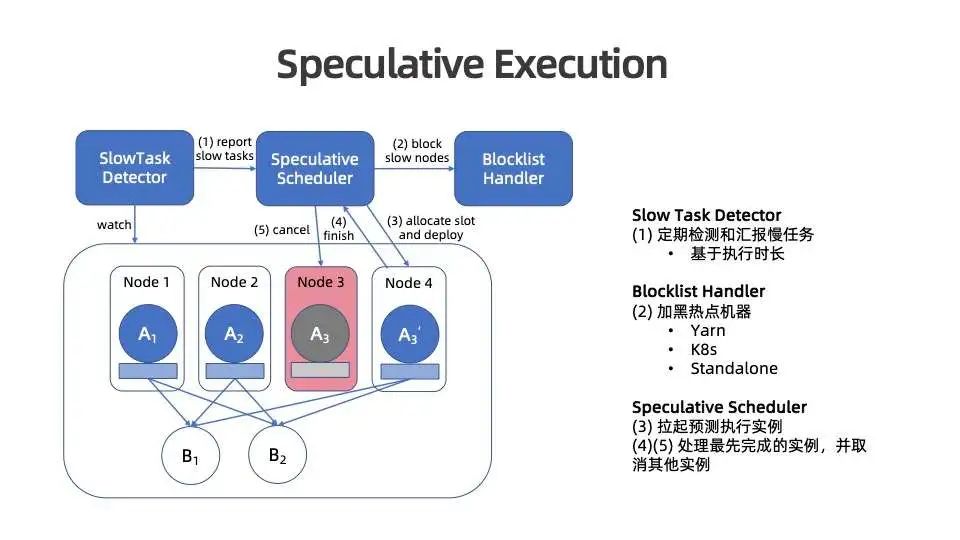
为了实现预测执行,我们为 Flink 引入了以下组件:
Slow Task Detector 主要用于定期检测与汇报慢任务。
在目前的实现中,当逻辑节点的某个执行节点特别慢,超过其大部分节点执行时长中位数的某个阈值后,则会被认为是慢节点。预测执行调度器会接收到慢节点,并将慢任务所在机器节点识别为热点机器。通过黑名单机制(Blocklist Handler),将热点机器加黑,使得后续调度的新任务不会落到加黑的机器上。黑名单机制目前支持 Yarn、 K8s 与 standalone 等Flink 目前最常的用部署方式。
如果慢节点运行中的执行实例数量没有达到配置上限,则会为其拉起预测执行实例直至数量上限,并部署到没有被加黑的机器上。任何执行实例结束后,调度器会识别是否有其他相关的执行实例也在运行中,如果有,则将其主动取消。
结束的实例产出的数据会被展现给下游,并触发下游节点调度。
我们框架层面支持了 Source 节点的预测执行,保证同一个 Source 并发的不同执行实例总是可以读取到相同的数据。基本思路是引入缓存来记录各个 Source 并发已经获取到的数据分片以及每个执行实例已经处理的分片。当一个执行实例处理完该 Source 并发当前被分配的所有分片之后,可以请求新分片,新分片也会被加入缓存中。
因为在框架层面进行了统一的支持,目前大部分已经存在的 Source 不需要进行额外修改即可支持预测执行。只有在使用了新版 Source 并且其使用了自定义 SourceEvent 的情况下,需要 SourceEnumerator 实现额外接口,否则在开启预测执行时会抛出异常。该接口主要用于保证用户自定义的事件可以被交给正确的执行实例。因为开启了预测执行后,一个并发可能会有多个执行实例同时运行。
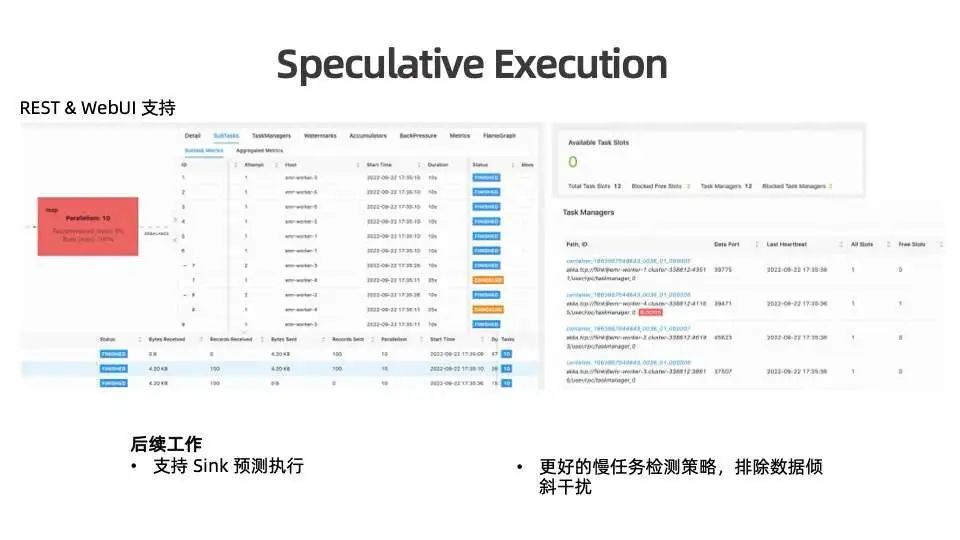
我们在 Rest 与 WebUI 层面也对预测执行进行了支持。预测执行发生时,可以在作业节点详细界面看到预测执行并发的所有执行实例。同时也能在资源总览卡片上看到被加黑的 TaskManager 数量,以及没有被占用但是被加黑所以也无法被使用的 slot 数量,用户可以借此评判当前资源的使用情况。此外,在 TaskManager 界面能够查看当前被加黑的TaskManager。
当前版本中,Sink 暂不支持预测执行,后续我们会优先完成对 Sink 节点预测执行的支持。其中需要解决的问题为保证每个 Sink 只会 commit 一份数据,并且其他被取消的 Sink 产生的数据可以被清理掉。
此外,我们也在计划进一步改进慢任务检测策略。当前,一旦发生数据倾斜,个别执行并发的数据量可能会大于其他执行并发,因此执行时长也会大于其他节点,但此节点可能并不是慢任务。因此需要能够正确识别处理该情况,从而避免拉起无效预测执行实例浪费资源。目前的初步思路为:根据各个执行实例实际处理的数据量对任务执行时长进行归一化,这也依赖于前文提到的 Adaptive Batch Scheduler 对各个节点产出的的数据量的采集。
-
流式 Pipeline Shuffle:其特点为上下游会同时启动,空对空传输数据,不需要落盘,因此在性能上具有一定优势。但是它对资源需求量比较大,往往需要作业能够同时获取到数倍于单节点并行度的资源方能运行,而这对于生产批处理作业而言难以满足。同时,因其有批量资源的需求,没有同时获取到则作业无法运行,多个作业同时抢夺资源时,可能会发生资源死锁。
-
批式 Blocking Shuffle:数据会直接落盘,下游直接从上游的落盘数据中读取。交换方式使得作业对于资源的自适应能力比较强,理论上不需要上下游同时运行,只要有一个 slot 则整个作业都可以执行完成。但是性能相对较差,需要等到上游 stage 运行完之后才能运行下游 stage,同时数据全部落盘会产生 IO 开销。
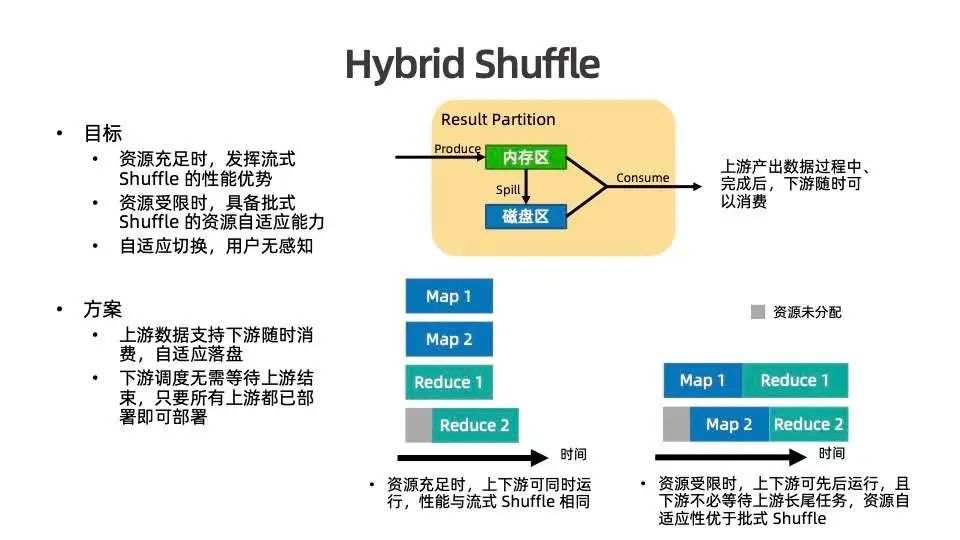
因此,我们希望有一种 Shuffle 模式能够将两者优势结合,在资源充足时,可以发挥流式 shuffle 的性能优势;而在资源受限的情况下,可以让作业具备批式 shuffle 的资源自适应能力,即使只有一个 slot 也能运行 。同时,适配资源的能力自适应切换,用户无需感知,无需进行单独调优。
在该模式下,上游产出结果的 Result Partition 接收到 shuffle 数据时,会将其缓存在内存中。如果上游已经启动并且与下游建立了连接,内存中的数据即可通过网络层空对空直接传输给下游,无需进行落盘;而如果下游还未启动并且上游产出的数据已经将内存填满,数据也可以 Spill 到磁盘上,使上游可以继续产出数据,不会造成反压影响上游进而导致上游无法继续处理。
Hybrid Shuffle 模式不再要求上下游必须同时运行,同时,如果下游连接时上游数据已经落盘,下游仍然可以在上游往 partition 中写数据的同时读取已经落盘的数据。如果下游处理性能够高,比上游产出速度更快,落盘数据读完之后可以继续从上游内存区读取数据,又回退到空对空的数据传输方式,达到一种较优的性能。
通过这样的方式,下游无需等待上游数据产出后再进行调度,上游产出数据的同时即可将下游拉起,只要有充足的资源即可与上游同时运行并读取其产出的数据。在资源有空闲的情况下,可以提高整个集群的资源利用率。需要注意,下游仍然需要在所有上游都已部署之后才能部署,一旦下游先于上游部署完成,可能还是会发生调度死锁。
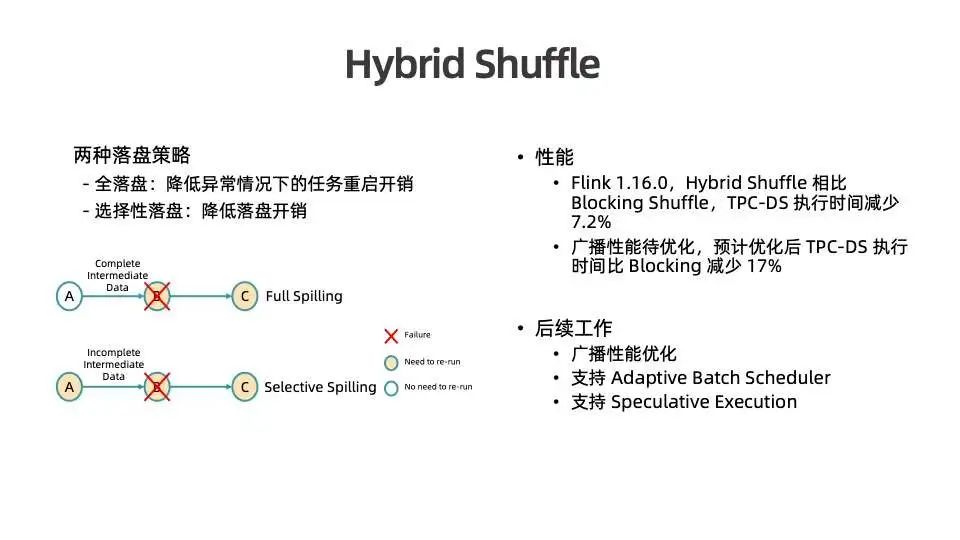
Hybrid Shuffle 引入了两种落盘策略:
-
全落盘:降低异常情况下的任务重启开销。出现异常后,只需重启出现问题的节点与其下游节点即可,无需重跑上游节点,适合集群不稳定或非常容易触发 failover 的场景。
-
选择性落盘:降低落盘开销。如果下游可以先拉起,数据则无须落盘走空对空传输;如果下游未拉起,则数据可以 spill 到磁盘上。比较适合对作业性能要求较高或集群资源数比较多而用户又希望批作业能够尽快处理完成的场景。
在 Flink1.16 中,Hybrid Shuffle 相比 Blocking Shuffle ,TPC-DS 执行时间减少 7.2%。但 Hybrid Shuffle 对于广播处理场景的性能有待优化,预计在 Flink1.17 中将解决该问题,整体执行时间预计将比 Blocking Shuffle 减少 17% 。
其次,当前 Hybrid Shuffle 是基于 Default Scheduler 实现的,因此不兼容自动并发设置以及预测执行。为了更好地支持批处理,还需要进行整合。
Dynamic Partition Pruning
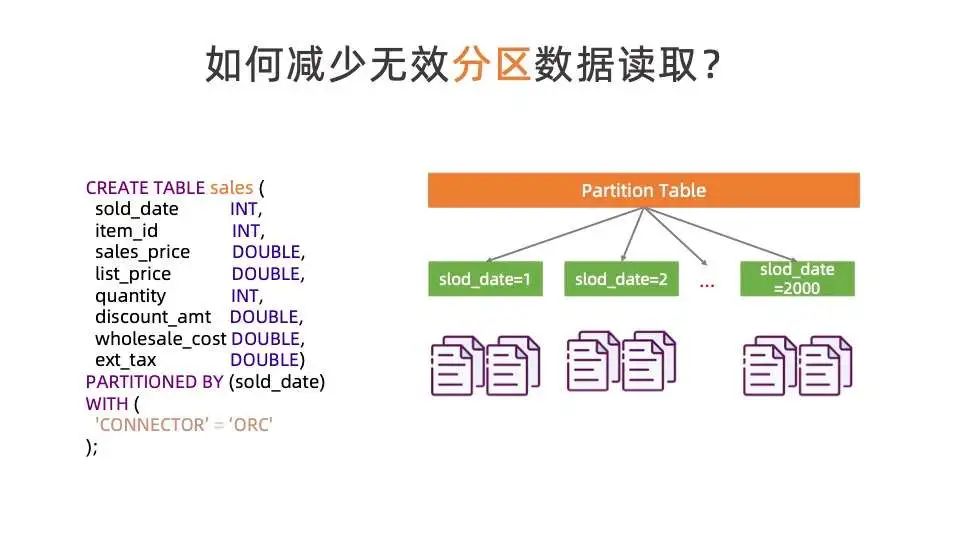
优化器很重要的工作就是避免无效计算和冗余计算。Partition 表在生成中被广泛使用,这里我们将介绍在分区表中如何减少无效分区的读取。
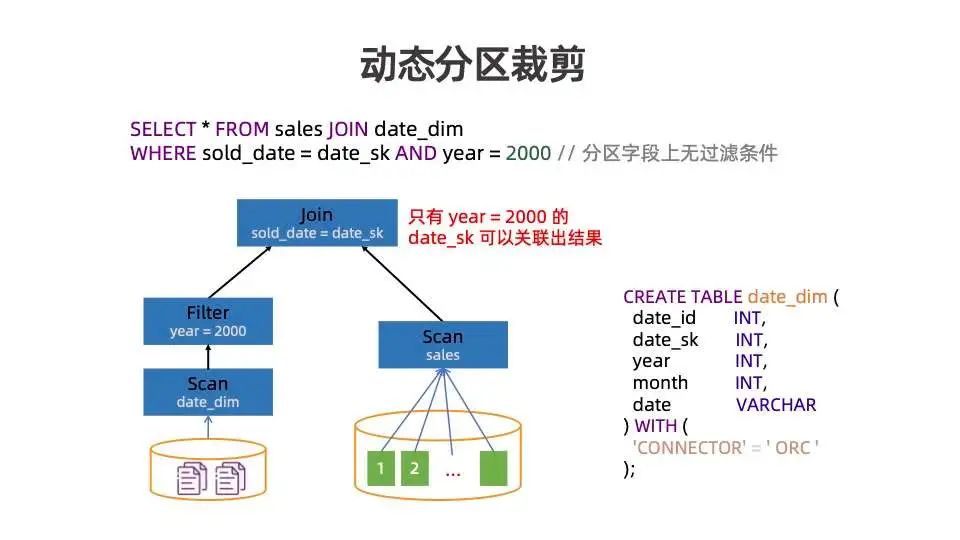
我们以几个从 TPC-DS 模型中简化的例子来介绍该优化。如上图所示,有一张 sales 表,partition 字段名为 slod_date ,该表共有 2000 个分区。
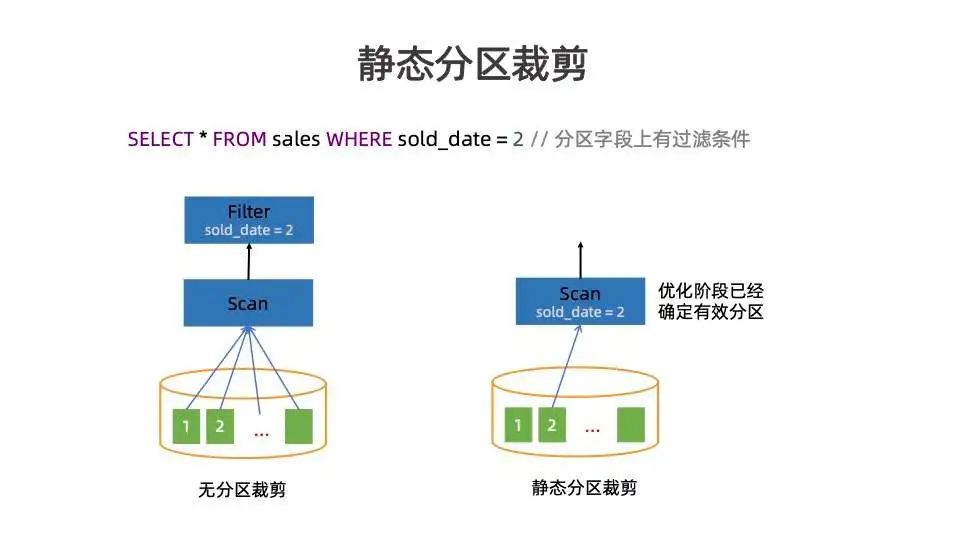
上图中 SQL 语句指从 sales 表里面选择 slod_date=2 的数据。没有分区裁剪的情况下,需要读取所有 partition 数据,再做 filter ;有静态分区裁剪的情况下,在优化阶段即可通过 filter pushdown 等各种优化将确定的分区告知 Scan 节点。Scan 在执行过程中,只需读取特定分区,大大减少了读 IO,加快了作业执行。
上图有两张表,分别是事实表 sales 表和维度表 date_dim,两张表做 join。有一个 filter 条件作用在维度表上,因此无法执行静态分区裁剪的优化。
维度表 date_dim 会读取所有数据并做 filter,事实表 sales 表会读取所有 partition 再做 join 。这里只有 year = 2000 并且 sold_date = date_sk 相关数据可以被输出,可以推导出知很多 partition 数据都是无效的,但这些分区没法在静态优化阶段分析出来,需要在运行阶段根据维度表的数据动态分析出来,因此叫动态分区裁剪。
-
第一步,执行 join 维度表测算子,比如 Scan(date_dim)、Filter。
-
第二步,将第一步的 Filter 结果发给分区表算子 Scan。
-
第三步:将步骤二的数据过滤掉无效分区,只读取有效数据。
-
动态分区裁剪与静态分区裁剪的区别在于,动态分区裁剪无法在优化阶段确定哪些 partition 数据有效,必须在作业执行之后方能确定。
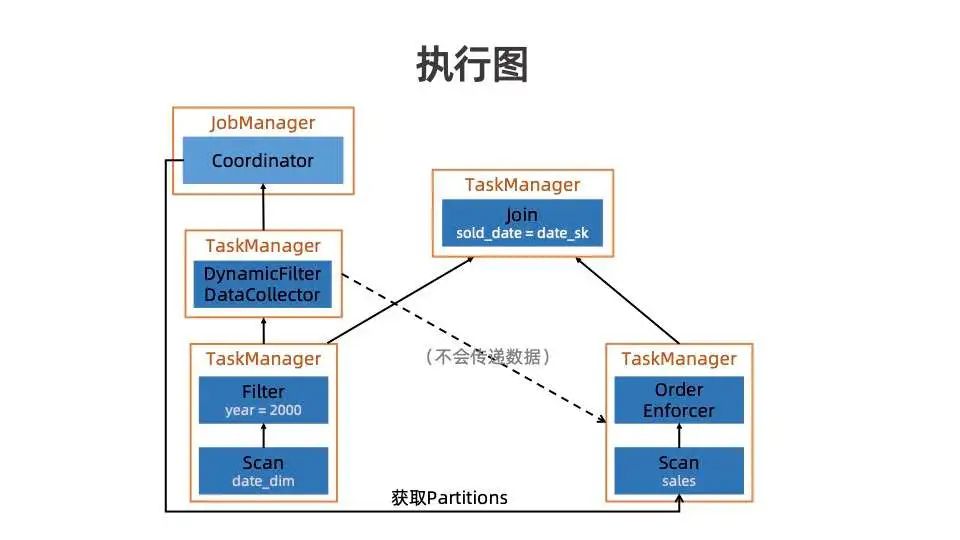
首先会在 Physical Plan 上加一个特殊节点 DynamicFilterDataCollector(以下简称 DataCollector),作用为将 Filter 数据进行收集并去重,只保留相关字段并发给分区表 Scan。分区表 Scan 获取到数据之后进行分区裁剪,最后完成 Join 。在 Streaming Graph 上, Source 算子(对应 Scan 节点)没有 input ,但我们希望 Source 算子能够接收 DataCollector算子传来的数据,同时维表侧 data_dim Scan 和year=2000 的Filter与右边 sales Scan 调度上没有依赖关系,可能会导致右边算子先被执行,左边算子后被执行,从而无法完成动态分区裁剪优化。
因此,我们引入了 OrderEnforce 节点,其目的是为了告知调度器它们之间的数据依赖关系,从而确保左边算子优先被调度,以确保动态分区裁剪优化能够被正确执行。
后续,我们也计划从框架层面来解决上述调度依赖的问题使Streaming Graph 变得更优雅。
左侧 data_dim Scan与 Filter 先执行,将数据发给 DataCollector 和 Join。为了解决 Source 算子没有 input 边的问题,我们使用了 Flink Coordinator机制,DataCollector 收集完数据之后会发给 Coordinator 并完成无效分区的裁剪,分区表 Scan 再从 Coordinator 获取有效的分区信息。Sales Scan 节点执行完后,再进行最后的 Join。
DataCollector 与 OrderEnforce 中间也有一条数据边,数据边内不会有真实的数据传输,仅用于通知调度器 DataCollector 比 OrderEnforce 先被调取起来。
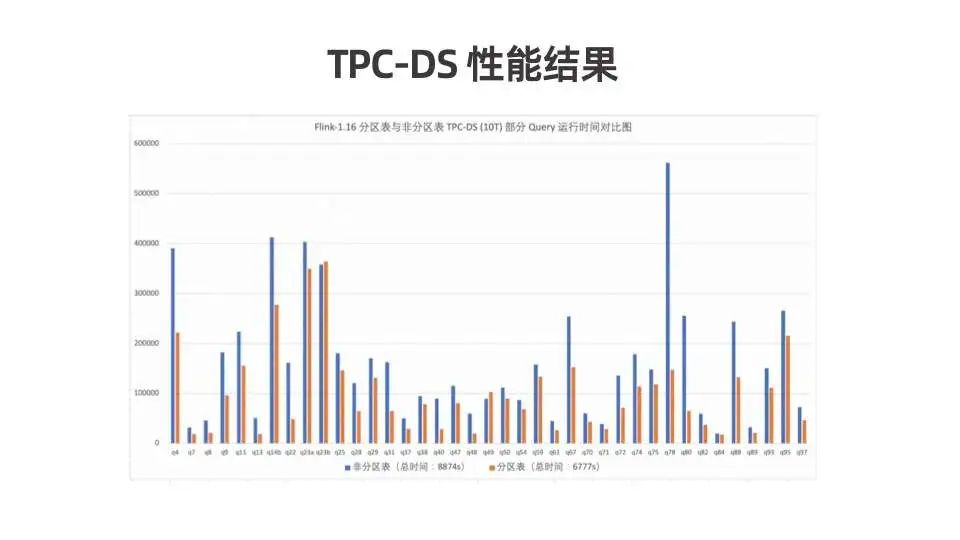
上图为基于 TPC-DS 10T 数据集优化前后的性能对比,其中蓝色是非分区表,红色是分区表。优化后时间节省约 30%。
更多 Flink Batch 相关技术问题,可扫码加入钉钉交流群~

Q&A
Q:热点机器产生慢任务时,会分配其他机器拉起实例,再重新执行慢任务。再次拉起实例时,是否还会产生热点?
A:理论上有可能,因为预测执行本身是通过资源换时间的一种策略。但是生产实践证明这种机制有效,相比额外资源开销以及进一步引发热点, trade off 依然是划算的。
Q:推测执行是根据数据量来判断吗?
A:当前的策略是根据执行时长来判断。比如大部分任务的执行时间中位数是一分钟,有任务执行超过了 1.5 分钟,则会被认为是慢任务。具体数值可配。
Q:慢节点检测是可配的吗?
A:该策略目前是硬编码,暂时还不支持配置策略。后续等策略稳定后,可能会开放给用户,用户可通过二次开发或插件的形式更改慢任务检测策略。
Q:推测执行机制对 DataStream API 与 Flink SQL 都能提供支持吗?
A:是的。
Q:拉黑机制上,是否会存在拉黑太多或拉白不及时而导致资源浪费?
A:目前预测执行下的加黑比较保守,加黑默认只会持续 1 分钟。但是如果慢任务持续出现,则会不断刷新加黑时间,因此慢任务所在的慢机器节点也会一直在加黑列表中。
本文转载自朱翥 & 贺小令 Apache Flink,原文链接:https://mp.weixin.qq.com/s/eOjObL7NbfeWVfOirWOgfQ。