
本文介绍Safari学习框架(入围IEEE/ACM ICCPS 2022最佳论文候选者),一种基于物理模型的安全强化学习机制进行数据中心制冷系统的控制优化。
Part1 引言
深度强化学习作为深度学习与强化学习结合的产物,已在诸多复杂抉择领域取得了突破性的进展。例如,谷歌DeepMind团队于2015年提出AlphaGo击败世界围棋冠军后[1],又于今年提出了基于深度强化学习的核聚变控制智能体[2]。由于深度强化学习在高纬复杂系统决策方面所展现出的强大性能,近年来部分研究人员开始探索其在数据中心制冷系统的控制优化[3]。


目前,传统数据中心的制冷系统大多采用反馈闭环控制,通过调节包间内CRAC设定点温度或风速来带走IT设备所产生的热量,以保证设备的平稳运行。深度强化学习通过引入奖励函数学习机制,在控制温度的同时能进一步降低系统能耗,从而降低数据中心运维成本并实现碳中和。然而,现有的研究在关注深度强化学习所带来能效提升的同时,往往忽略了其在实际系统部署“安全性”的考量。在线训练过程中,深度强化学习智能体的收敛往往需要积累大量的探索性数据。例如,包间不同设定点温度下的数据。因此,在智能体探索过程中,不可避免地会出现包间内温度违反安全阈值。过高的温度可能会造成服务器宕机,甚至引发火灾[4],从而带来更大损失。因此,如何保证深度强化学习在探索过程中系统的安全性,是其在数据中心能否成功部署的关键。
Part2 研究现状
无论基于模型(model-based)还是无模型(model-free)的深度强化学习算法都广泛采用对不安全状态施加负奖励的方法(Reward Shaping),以实现在训练/探索过程中的安全约束[5][6]。然而,强化学习智能体往往需要经历足够多的不安全状态,才能够学会如何防止进入不安全状态。研究人员提出了基于备用控制器的机制(Simplex),使得一旦系统进入不安全区间,其控制权就立即转到安全且保守的备用控制器[7],但频繁的中断智能体会严重影响其学习效率和效果。此外,也有研究人员采用动作修正方法(Post-hoc rectification),以防止系统进入不安全状态为目标,基于一个线性的系统模型,探索对推荐动作的最小修正[8]。尽管此类修正可以得到闭合形式的动作修正解,但受限于目标系统的线性程度,对数据中心复杂非线性系统并不适用。
Part3 Safari 学习框架
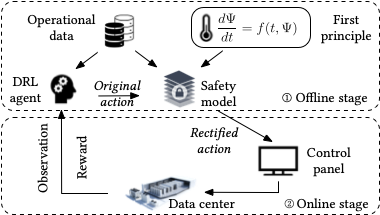
为解决上述问题,本项研究提出Safari学习框架,如上图所示。该框架通过离线模仿学习与在线动作修正来实现深度强化学习智能体在数据中心的在线安全部署。其中,为了更加准确地评估系统温度的动态变化,Safari引入数据中心热力学物理知识对温度动态进行建模。该模型可利用历史安全状态数据进行拟合,并在其未探索过的状态空间取得较好的预测性能,因此,无需采集不同温度下的探索性数据。
1. 离线模仿学习
传统深度强化学习在部署探索策略时,往往将网络参数进行随机初始化,以获得较大的探索空间。然而,随机初始化的策略往往收敛周期较长,且在探索初期容易做出违反系统安全的动作。为获得较为稳定的初始策略,Safari在部署深度强化学习策略之前先通过模仿学习对深度神经网络参数进行初始化。具体来说,我们通过某一安全控制器来生成一个周期的历史数据,并将其每一时刻的状态作为输入,动作作为标签,通过监督学习的方式来让神经网络模仿该控制器。最终,智能体在部署时将模仿控制器的动作,以保证初始动作的安全。
2. 在线动作修正
为进一步提升深度强化学习智能体的性能,在线部署阶段该智能体将探索更加节能的控制策略。在探索过程中,本研究分别引入线性、稳态、和瞬态模型对深度强化学习的推荐动作进行评估,并在此基础上,分别采用投影或启发式搜索的方法求得动作修正项的最优解,即修正动作在不触发系统不安全状态的同时,尽可能在欧氏距离上与原推荐动作相差最小。在修正过程中,本项研究进一步考虑基于领域知识的动作修正机制,以降低动作搜索空间的复杂度。例如,当模型评估当前决策造成包间温度过高时,搜索将沿增大空调的供风流量和降低空调送风温度的方向进行有针对性的迭代,直到动作被模型评估为安全为止。
Part4 实验结果
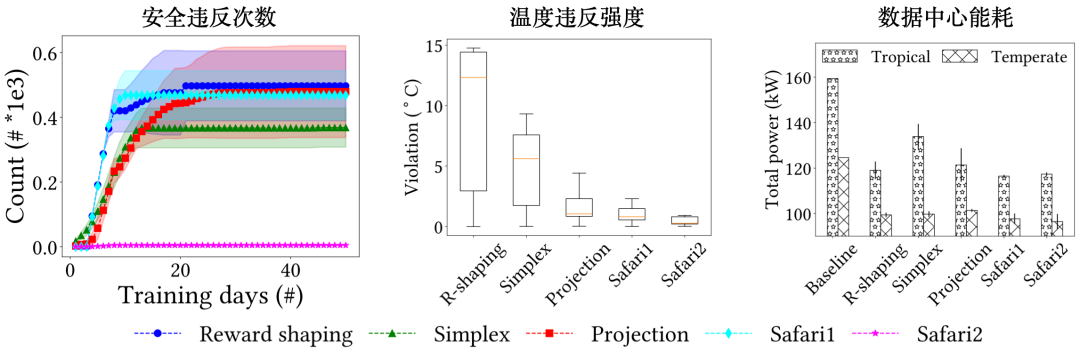
本项研究基于EnergyPlus搭建了单包间水冷数据中心测试平台,并利用DDPG算法对CRAC的出风温度和流速进行控制优化。实验评估方面分别引入线性、稳态、和瞬态模型对深度强化学习的推荐动作进行评估修正。实验结果如图3所示,与其他基线深度强化学习算法相比,基于瞬态物理模型的修正方法降低了94%到99%的温度阈值违反次数,同时相比传统控制器节省了22%到26%的系统能耗。
Part 5 总结
本项研究提出的Safari框架,通过离线模仿学习与在线动作修正提高了深度强化学习智能体在数据中心部署方面的安全性。在线动作修正通过引入物理知识,提升了动态模型在非探索性数据拟合下的准确度,从而能够更好地评估系统的安全性。
参考文献
[1] Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” nature 529.7587 (2016): 484-489.APA
[2] Degrave, Jonas, et al. “Magnetic control of tokamak plasmas through deep reinforcement learning.” Nature 602.7897 (2022): 414-419.
[3] https://deepmind.com/blog/article/deepmind-ai-reduces-google-data-centre-cooling-bill
[4] https://mp.weixin.qq.com/s/TC9S785ZL-EYaQWsVG4-Jw
[5] C. Zhang, S. Kuppannagari, R. Kannan, and V. Prasanna. 2019. Building HVAC scheduling using reinforcement learning via neural network based model approximation. In ACM BuildSys. 287–296.
[6] Y. Li, Y. Wen, D. Tao, and K. Guan. 2019. Transforming cooling optimization for green data center via deep reinforcement learning. IEEE Trans. Cybern. 50, 5 (2019), 2002–2013.
[7] H. Mao, M. Schwarzkopf, H. He, and M. Alizadeh. 2019. Towards Safe Online Reinforcement Learning in Computer Systems. In NeurIPS.
[8] G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Paduraru, and Y. Tassa. 2018. Safe exploration in continuous action spaces. arXiv:1801.08757 (2018).
本文转载自王睿航@南洋理工CAP组,原文链接:https://mp.weixin.qq.com/s/tvnmnaIMYYOwdWkGq2xqIA。