
摘要 · 看点
在 ACMMM 2021 上,我们提出了联邦无监督行人重识别系统 FedUReID,在不需要标签、不因汇聚数据而产生隐私问题的前提下,采用分布式联邦学习的方式(一个云端中心服务器联合多个边缘设备)共同训练行人重识别网络。此外,FedUReID 通过边云联合优化解决了多个边缘设备上行人重识别数据异构性问题,进一步提升了模型的性能。
论文名称:Joint Optimization in Edge-Cloud Continuum for Federated Unsupervised Person Re-identification
论文地址:https://arxiv.org/abs/2108.06493


Part 1 问题和挑战
行人重识别的训练通常需要收集大量的图片到一个云端中心服务器,这些图片中带有个人敏感信息,产生潜在的个人隐私泄露风险。随着隐私政策不断收紧,集中训练的方式将受到进一步的挑战。联邦学习是一种保护隐私的分布式训练方法,在 ACMMM 2020 提出的 FedReID [1] 将联邦学习应用在行人重识别上,通过传递模型参数而不是原始图片数据的方式,保护训练过程中的数据隐私问题。但是,FedReID 需要在每个边缘节点上对行人重识别数据进行大量标注,不仅费时费力费资源,还不利于进行大规模的应用。此外,联邦学习方案数据通常都是在边缘设备上做训练,边缘设备从多个摄像头收集数据。因为摄像头安装在不同街区、不同角度,他们采集的数据的数据量、行人数量、光照等环境因素都不同,从而带来了多个边缘设备之间数据异构性的问题。
Part 2 方法介绍
为解决上述问题,我们提出了联邦无监督行人重识别训练系统 FedUReID。FedUReID 提出了边云联合优化:边端上进行个性化聚类(personalized clustering) 和 个性化训练 (personalized epoch);云端进行 个性化更新 (personalized update)。下图是 FedUReID 的整体架构和训练流程图:
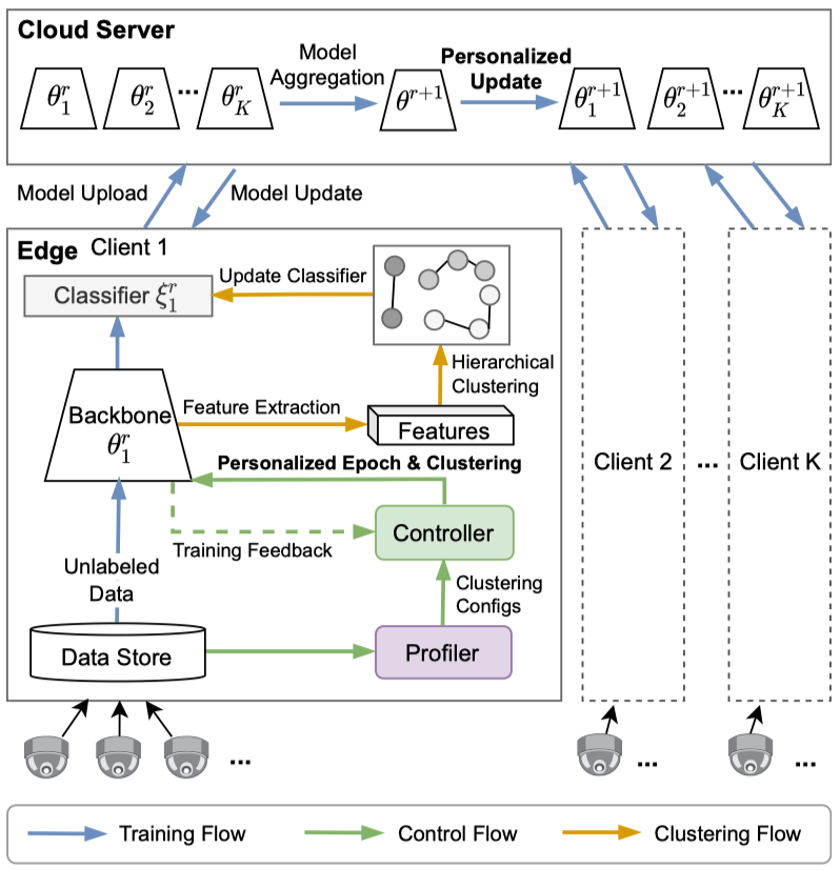
整个系统包括了三个数据流程:1)训练流;2)控制流;3)聚类流。
训练流程从云端模型初始化开始,之后每个回合的训练包括以下几个步骤:
1. 本地训练:边端利用本地无标签数据进行无监督模型训练。
2. 模型上传:边端将训练好的模型上传到云端。
3. 模型融合:云端聚合边端上传的模型,产生新模型。
4. 模型更新:在下一回合训练开始时,云端用产生的新模型,更新边端的本地模型。
聚类流程解决了数据无标签的问题。FedUReID 采用了 [2] 提出的层次聚类方法,每一回合本地训练结束后,用训练好的模型提取图片特征,使用控制流程中产生的聚类配置进行聚类,然后用聚类的结果作为无标签数据的伪标签。
控制流程有两方面的作用。第一回合的本地训练之前,FedUReID 设计了 Profiler 来预估每个边端训练聚类的最优配置,然后将配置发送给 Controller,去控制每个边端进行个性化的聚类;在本地训练过程中,控制流程通过 Controller 去控制每个边端进行个性化训练。
1. 个性化聚类(边端)
个性化聚类的核心是每个边端通过 Profiler 得到的最优聚类配置进行自底向上的聚类,而不是使用相同的参数进行聚类。
聚类的方法如下图所示。因为数据没有标签,每个数据都当成是一个单独的类,一共是 M 个类,每一回合训练结束后,聚合 m 个类后得到 M-m 各类,总共进行 N/m – 1 回合的训练和聚类,每次聚合百分比为 mp = N/m。在下图的例子中,一开始有 N=8 张图片,也就是 M = 8 个类,每次聚合 m = 2 类,聚合百分比是 25%。

2. 个性化训练(边端)
在联邦学习中,通常所有边端都采用固定的轮数,而 FedUReID 采用个性化训练,其核心是每个边端动态的根据训练反馈,调整本地训练的轮数。
每一回合训练包含多轮,每一轮训练包含多批数据。在第一回合训练中,FedUReID 训练较多轮以更好的适应没有标注的图片。从第二回合训练开始,FedUReID根据每一批训练的结果来调整回合数:当任何一批训练的精度达到100% 或者多批训练累计达到的精度达到95%时,即停止当前回合的训练。个性化训练让各边端能根据自身数据情况调整训练轮数,减少训练时间和计算量。
3. 个性化更新(云端)
除了边端的个性化聚类和训练优化外,FedUReID 在云端优化了模型更新。在联邦学习中,通常的模型更新是用云端融合后得到的新模型直接替换边端上的模型,而 FedUReID 采用了个性化更新,公式如下:
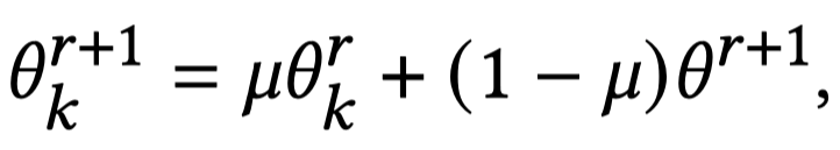
其中θ表示云端融合后在第 r+1 回合的模型,θk 表示边端 k 的模型,μ度量的是云端和边端模型每层参数的距离。直观的理解是,当两个模型越相似时,云端融合的模型在更新时所占的权重越大;当两个模型越不相同时,边端模型的权重越大,更多的保留边端模型的信息,以此达到个性化的目的。
Part 3 实验结果
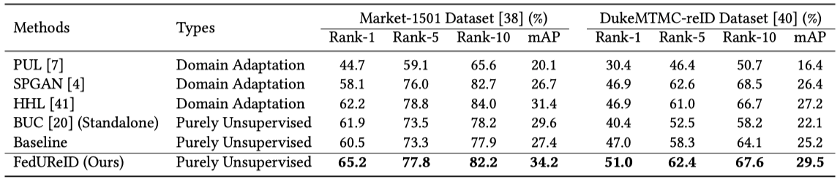

上面两个图定量的展示了 FedUReID 的有效性。其中,Standalone Training 是指边端只使用本地数据训练,Baseline 是没有使用边云联合优化的无监督联邦训练。使用 8 个行人重识别数据集上做训练和测试,FedUReID 的性能全面优于其他方法和 Baseline。
Part 4 消融实验

除此之外,我们在上面表格中对每种优化方法都做了消融实验:PC 是个性化聚类、PE 是个性化训练、PU 是个性化更新。单独一个优化方法都能带来整体性能的提升,边云联合优化取得了整体最好的性能。
Part 5 结语
在这项工作中,我们提出了联邦无监督行人重识别系统 FedUReID,实现了使用无标注行人重识别数据进行分布式联邦学习,同时还保护了数据隐私。不仅如此,我们采用边云联合优化的方法进一步解决了数据异构性的问题。我们的方法不仅提升了性能,和 Baseline 对比还降低了 29% 的计算量。这些设计可能还可以扩展到其他隐私要求比较高的视觉任务上,比如人脸、人群等。此外,系统异构性在这个场景中也是很重要的一个问题,感兴趣的同学可以进一步尝试解决。
参考文献
[1] Zhuang, Weiming, et al. “Performance optimization of federated person re-identification via benchmark analysis.” ACM MM, 2020.
[2] Lin, Yutian, et al. “A bottom-up clustering approach to unsupervised person re-identification.” AAAI, 2019.
本文转载自Zhuang Weiming@南洋理工CAP组,原文链接:https://mp.weixin.qq.com/s/wBuZ6obHgJ0vcb8ABNWYeA。