


背景
总体架构
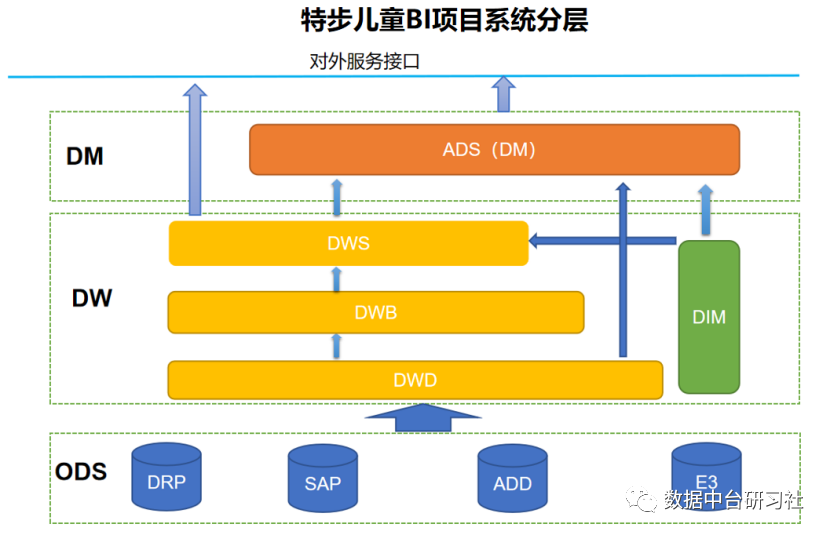
数据仓库分层逻辑如下:
DWD 模型层:关联维度数据的加工和明细数据的简单整理,包括头行表结构的合并、商品拆箱处理、命名统一、数据粒度统一等。DWD 层的销售、库存明细数据均按照系统加工,每个系统的加工逻辑创建一张视图,结果对应一张物理表。DWD 层大部分采用 Duplicate Key 模型,部分能明确主键的采用 Unique Key 模型。
DWB 基础层:保留共性维度,汇总数据到业务日期、店铺、分公司、SKC 粒度。销售模块 DWB 层合并了不同系统来源的电商数据、线下销售数据、库存明细数据,还关联了维度信息,增加数据过滤条件,加工了分公司维度,确保 DWS 层可以直接使用。DWB 层较多采用 Duplicate Key 模型,便于按照 Key 删除数据,也有部分采用 Aggregate Key 模型。
DWS 汇总层:将 DWB 层加工结果宽表化,并按照业务需求,加工本日、本月、本周、本年、昨日、上月、上周、上年及每个标签对应的同期数据。DWS 层较多采用 Duplicate Key 模型,也有部分采用 Aggregate Key 模型。DWS 层完成了指标的汇总和维度的拓展,为报表提供了统一的数据来源。
ETL 实践
批量数据导入我们采用的是目前最主流的开源组件 DataX。自研的 DataOps 大数据管理平台在开源 DataX 的基础上做了很多封装,我们只需要创建数据同步任务,选择数据来源和数据目标表,即可自动生成字段映射和 DataX 规范的 Json 配置文件。
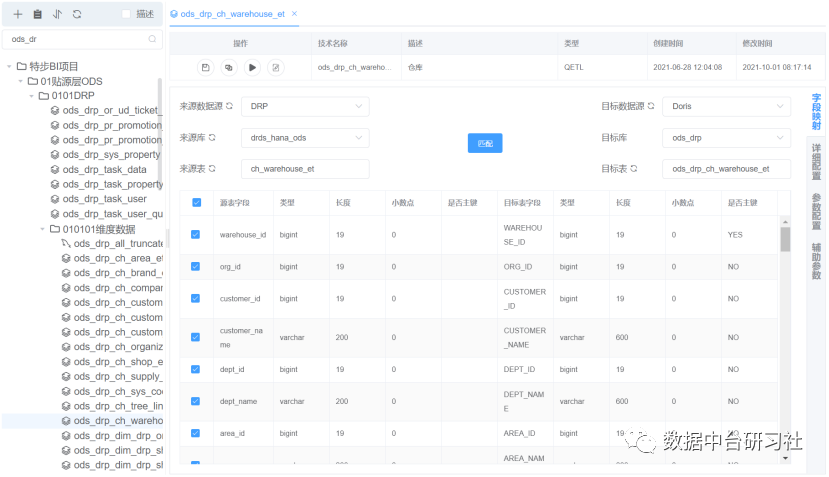
批量数据同步还支持增量模式,通过抽取最近 7 天的数据,配合 Doris 的主键模型,可以轻松解决大部分业务场景下的增量数据抽取。
ALTER TABLE DS_ORDER_INFO ENABLE FEATURE "BATCH_DELETE";CREATE ROUTINE LOAD t02_e3_zy.ds_order_info ON DS_ORDER_INFOWITH MERGECOLUMNS(order_id, order_sn, deal_code, ori_deal_code, ori_order_sn,crt_time = now(), cdc_op),DELETE ON cdc_op="DELETE"PROPERTIES("desired_concurrent_number"="1","max_batch_interval" = "20","max_batch_rows" = "200000","max_batch_size" = "104857600","strict_mode" = "false","strip_outer_array" = "true","format" = "json","json_root" = "$.data","jsonpaths" = "["$.order_id","$.order_sn","$.deal_code","$.ori_deal_code","$.ori_order_sn","$.type" ]")FROM KAFKA("kafka_broker_list" = "192.168.87.107:9092,192.168.87.108:9092,192.168.87.109:9092","kafka_topic" = "e3_order_info","kafka_partitions" = "0","kafka_offsets" = "OFFSET_BEGINNING","property.group.id" = "ds_order_info","property.client.id" = "doris");
truncate table xtep_dw.dim_shop_info;insert into xtep_dw.dim_shop_infoselect * from xtep_dw.dim_shop_info_v;
truncate table xtep_dw.dwd_god_allocation_detail_drp;insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2020-01-01' and '2020-06-30';insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2020-07-01' and '2020-12-31';insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2021-01-01' and '2021-06-30';insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2021-07-01' and '2021-12-31';insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2022-01-01' and '2022-06-30';insert into xtep_dw.dwd_god_allocation_detail_drpselect * from xtep_dw.dwd_god_allocation_detail_drp_vwhere UPDATE_DATE BETWEEN '2022-07-01' and '2022-12-31';
#!/usr/bin/python# -*- coding: UTF-8 -*-import pymysqlimport jsonimport sysimport osimport timeif sys.getdefaultencoding() != 'utf-8':reload(sys)sys.setdefaultencoding('utf-8')BACKUP_DIR='/data/cron_shell/database_backup'BD_LIST=['ods_add','ods_cdp','ods_drp','ods_e3_fx','ods_e3_jv','ods_e3_pld','ods_e3_rds1','ods_e3_rds2','ods_e3_zy','ods_hana','ods_rpa','ods_temp','ods_xgs','ods_xt1','t01_hana','xtep_cfg','xtep_dm','xtep_dw','xtep_fr','xtep_rpa']if __name__ == "__main__":basepath = os.path.join(BACKUP_DIR,time.strftime("%Y%m%d-%H%M%S", time.localtime()))print basepathif not os.path.exists(basepath):# 如果不存在则创建目录os.makedirs(basepath)# 连接databaseconn = pymysql.connect(host='192.168.xx.xx',port=9030,user='root',password='****',database='information_schema',charset='utf8')# 得到一个可以执行SQL语句的光标对象cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示for dbname in BD_LIST:##生成数据库的文件夹dbpath = os.path.join(basepath ,dbname)print(dbpath)if not os.path.exists(dbpath):# 如果不存在则创建目录os.makedirs(dbpath)sql1 = "select TABLE_SCHEMA,TABLE_NAME,TABLE_TYPE from information_schema.tables where TABLE_SCHEMA ='%s';"%(dbname)print(sql1)# 执行SQL语句cursor.execute(sql1)for row in cursor.fetchall():tbname = row[1]filepath = os.path.join(dbpath ,tbname + '.sql')print(u'%s表结构将备份到路径:%s'%(tbname,filepath))sql2 = 'show create table %s.%s'%(dbname,tbname)print(sql2)cursor.execute(sql2)for row in cursor.fetchall():create_sql = row[1].encode('GB18030')with open(filepath, 'w') as fp:fp.write(create_sql)# 关闭光标对象cursor.close()# 关闭数据库连接conn.close()
#备份数据库,每天执行三次,8、12、18点各一次0 8,12,18 * * * python /data/cron_shell/backup_doris_schema.py /data/cron_shell/logs/backup_doris_schema.log
实时需求响应
--批处理任务(每日夜间执行一次)truncate table xtep_dw.dwb_ret_sales;insert into xtep_dw.dwb_ret_salesselect * from xtep_dw.dwb_ret_sales_v;--微批任务(白天8-24点每20分钟执行一次)delete from xtep_dw.dwb_ret_sales where report_date='${curdate}';insert into xtep_dw.dwb_ret_salesselect * from xtep_dw.dwb_ret_sales_vwhere report_date='${curdate}';
--批处理任务(每日夜间执行一次)truncate table xtep_dw.dws_ret_sales_xt_swap;insert into xtep_dw.dws_ret_sales_xt_swapselect * from xtep_dw.dws_ret_sales_xt_vwhere date_tag in ('本日','本周','本月','本年');insert into xtep_dw.dws_ret_sales_xt_swapselect * from xtep_dw.dws_ret_sales_xt_vwhere date_tag in ('昨日','上周','上月','上年');ALTER TABLE xtep_dw.dws_ret_sales_xt REPLACE WITH TABLE dws_ret_sales_xt_swap;--微批任务(白天8-24点每20分钟执行一次)truncate table xtep_dw.dws_ret_sales_xt_swap;insert into xtep_dw.dws_ret_sales_xt_swapselect * from xtep_dw.dws_ret_sales_xt_vwhere date_tag in ('本日','本周');ALTER TABLE xtep_dw.dws_ret_sales_xt ADD TEMPORARY PARTITION tp_curr1 VALUES IN ('本日','本周');insert into xtep_dw.dws_ret_sales_xt TEMPORARY PARTITION (tp_curr1) SELECT * from xtep_dw.dws_ret_sales_xt_swap;ALTER TABLE xtep_dw.dws_ret_sales_xt REPLACE PARTITION (p_curr1) WITH TEMPORARY PARTITION (tp_curr1);
其他经验
结束语
– 作者介绍 –
杨宏武
特步零售数据仓库项目架构师,Apache Doris 活跃 Contributor,负责公司产品研发和 Apache Doris 应用方向的落地和推广。
王春波
特步零售数据仓库项目技术经理,《高效使用Greenplum:入门、进阶与数据中台》的作者,“数据中台研习社”号主,零售数仓项目实施专家。
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/bigdata/doris/doris-usage/4964/