
上一篇文章中,我们介绍了EasyEagle作为一款大数据底层的智能监控诊断平台,是如何解决数据平台中的诸多痛点问题。而在本篇中,我们将从细粒度的任务维度入手,介绍EasyEagle产品如何诊断定位集群中运行的任务出现的问题。
作为数据平台的业务方,通过集群提交任务后,难免会遇到以下问题:
-
任务运行为什么这么慢,哪里出现了问题?
-
任务的资源使用是否合理,能否提升资源利用率?
-
任务是否能优化,加快产出?
-
……
本篇将承接上篇的内容,从任务视角出发,对任务监控、资源治理以及全链路诊断进行介绍,展示目前EasyEagle如何去发现、解决上述任务层面的各项问题,以及我们通过不断实践,汇总出来的任务优化治理经验。
任务监控
1.1 任务详情
对数据开发者来说,在任务上线后,经常希望能够感知任务的整体运行情况,尤其是在任务出现了异常,或是对任务的资源使用存疑的场景下。
EasyEagle除了提供任务的基础信息外,针对每个任务都提供了详尽的各项指标趋势图,如runningContainer趋势图、任务内存或CPU的使用趋势图、任务读写数据量趋势图等等。能够方便得知任务运行中的各项指标数据与时序数据,为定位任务出现的问题给出详细的参考价值。如下图例所示:
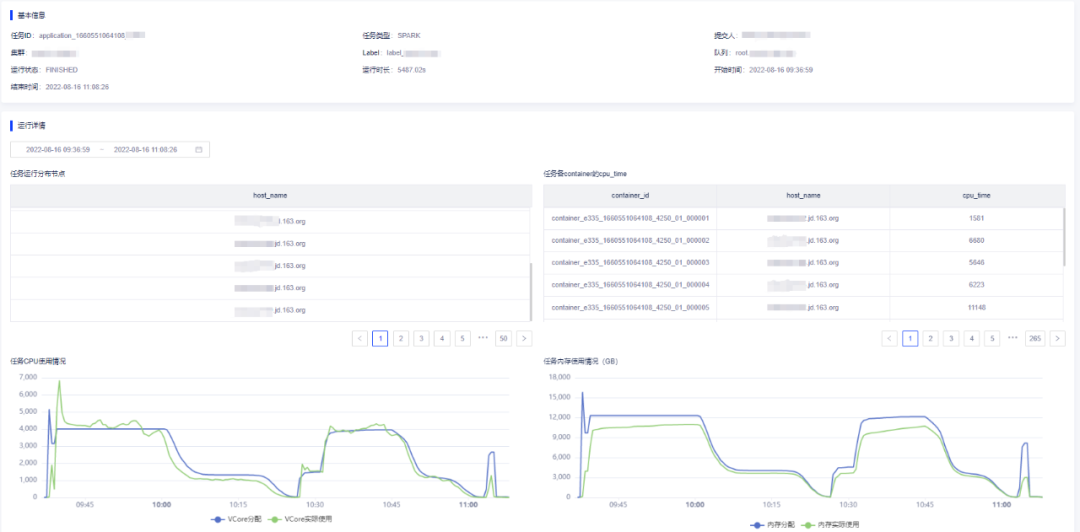

用户根据上述的任务详情页面,能轻松获取以下信息:
-
任务的基本概要信息,如作业名、提交用户、资源池等等信息;
-
任务生命周期内运行的各项指标:例如数据吞吐量、资源消耗情况、运行途中的各项关键指标的时序数据等。方便用户了解任务的运行状态,也能通过运行时指标快捷的定位问题。
1.2 任务历史运行情况对比
数开平台上运行的任务,大多数都是周期性调度运行的任务。针对此种类型的任务,会涉及到以下问题:
-
用户调整相关配置,会影响哪些指标,任务运行情况和之前是否有所不同?
-
任务目前感觉较历史运行缓慢,是哪些环节和历史有所不同?
针对上述问题,EasyEagle在任务详情页面下方设计了一个历史任务对比的功能模块,如下所示:
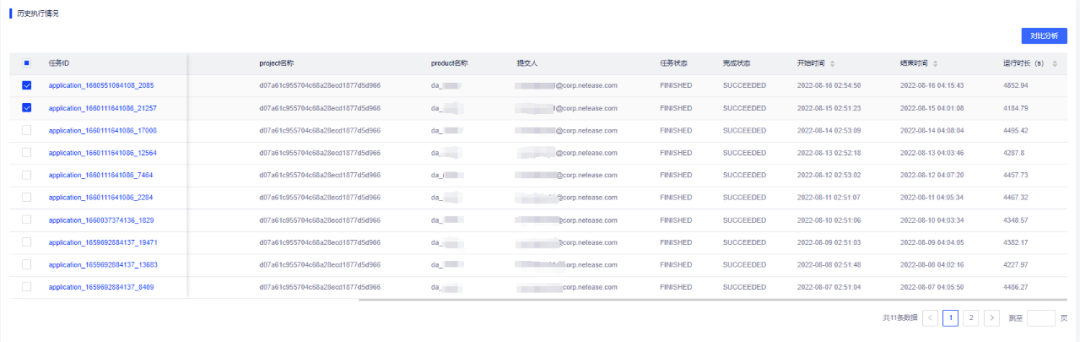
用户可以指定需要查询的任务,点击该任务的任意历史任务,进行对比查看,如下所示:
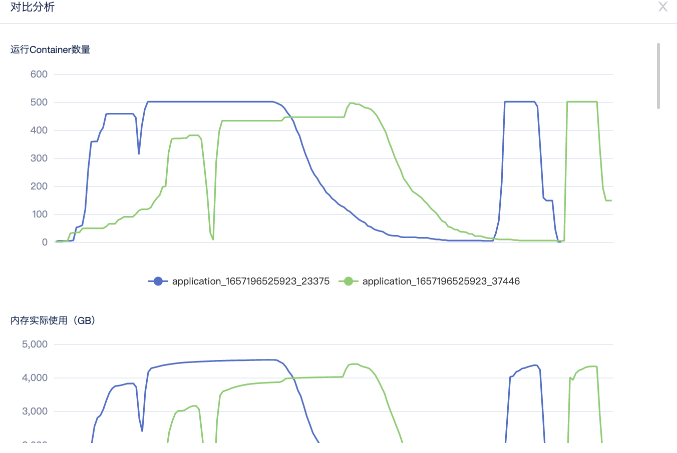
用户根据对比的历史情况,能快捷地了解到:
-
如调整任务配置后,哪些关键性指标有所变更,调整方式是有利还是有弊
-
任务运行较历史慢,是哪些环节出现的问题,如资源分配,还是数据吞吐量等
任务资源治理
在集群与队列篇中我们有提到,Yarn集群的队列若使用姿势不当,经常会出现资源浪费的情况,而想要提高队列的资源利用率,一定要从单个任务的治理优化入手。那么如何针对单个任务进行优化呢。
2.1 任务为什么会出现资源浪费?
在这里我们首先要明确一个问题,就是任务为何会出现资源浪费。在Hadoop系统中,不管是MapReduce框架(包含Hive),还是Spark任务,都是从YARN来分配资源的,每个任务都有对应的资源(Memory,VCore)请求描述,而任务对资源的请求描述都是通过Container来进行的。
因此每个任务都会预先设置申请的Container资源大小(Memory,VCore),所以任务出现了资源的浪费,从细粒度的来讲,一定是因为Container的资源申请出现了浪费。比如说,任务的每个Container最多只用2G的内存,但在请求资源时,却申请了的资源。那么每个Container都浪费了6G的内存,导致整个任务资源浪费情况严重。
2.2 哪些任务浪费资源最多?
明确了任务为何会出现资源浪费,那如何定位任务是否有资源浪费,又如何衡量任务资源浪费了多少呢?要回答这个问题,就要知道任务消耗的资源应该如何进行计算,这个涉及到两个概念。
-
任务申请的资源大小,已经占用资源的时间。
-
任务实际使用的资源大小,已经占用资源的时间。
这两个概念都涉及到两个部分,“资源大小”和“占用资源的时间”。我们依次来做一个阐释。
“资源大小”,即任务申请Container的资源大小总和。这个大小不是一个值,而是随时间变化的“一组连续的值”。任务生命周期中Container数量不是恒定不变的,因此占用的资源大小在每个时刻是会有变化的。将Container的资源信息聚合起来,就能得出任务申请资源及实际使用资源在每一时刻的数值。而“占用资源的时间”就很好理解了,也就是任务的运行时长。
这里我们引入了如下的指标用于衡量任务资源消耗:Memory*Second, VCore*Second,指的是任务每秒钟使用的内存(VCore),根据时间的积分值。同样的,我们还根据任务申请和实际使用等指标项,创新性地构造了如下几个指标,以内存为例:
ActualMemory*SecondsSpareMemory*Seconds
这两个指标分别代表的含义分别是:任务实际内存根据时间的积分值、任务空闲内存根据时间的积分值。
想要更直观的理解Memory*Second,ActualMemory*Seconds,SpareMemory*Seconds的关系,如下图所示,以横坐标为时间,纵坐标为资源使用量的坐标轴中,有资源申请大小的趋势曲线,和资源实际使用大小的趋势曲线。
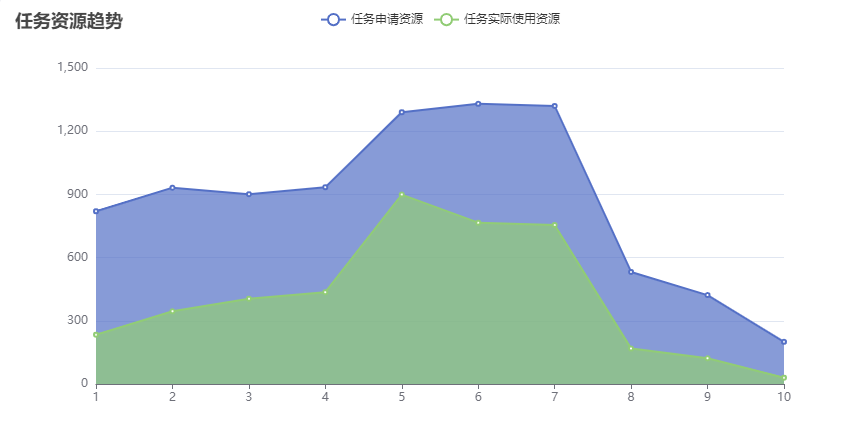
-
Memory*Second为资源申请曲线和坐标轴围成的蓝色面积
-
ActualMemory*Seconds为资源实际使用曲线和坐标轴围成的绿色面积
-
SpareMemory*Seconds为上述两个面积的差值。
用ActualMemory*Seconds:Memory*Second也能算出任务总体的资源利用率。
根据这些指标,我们能够有效地衡量任务资源浪费的情况,并能够优先从SpareMemory*Second最大的任务入手,去找到优化效益最大的任务。基于此,我们对每个任务均提供如下的资源指标以衡量任务的总体资源情况,以内存为例有如下三种指标:
-
MemorySeconds
-
任务内存利用率 ( ActualMemorySeconds / MemorySeconds)
-
Container最大内存利用率(Container最大使用内存 / Container申请内存)
这些指标能综合的衡量出任务资源情况。通俗的讲,MemorySeconds是任务消耗内存的“总量”;内存利用率则是消耗的资源中实际使用的资源比例;Container最大内存利用率是任务所有Container中内存利用率最高的那一个,以此为基准可以知道任务Container内存使用的上限是多少。依据这些指标,产品能够有效提供相关的任务优化参考。
在产品中查看队列中,空闲资源任务的排行榜如下图所示:
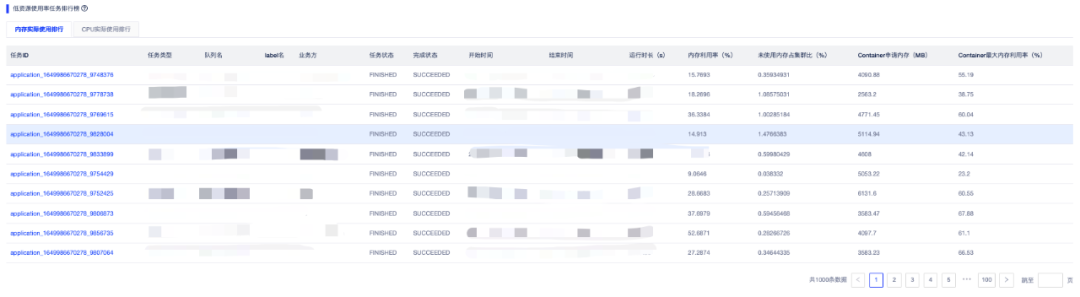
2.3 如何治理任务资源?
知道任务的资源浪费情况后,如何基于这些资源指标进行任务调优呢?这里提供一种最常见优化形式,也就是调整申请Container资源的比值。
还是上面的例子,如果任务的Container最高使用2G的内存,那么的资源申请,一定会造成浪费,将的资源,调节为即能保证任务的运行不受影响,同时任务的内存资源申请量就减少了一半。这样的优化方式,在我们内部的实践中也得到了多次的印证。
2.4 如何查看任务资源治理效果?
优化后的任务,想要了解相关优化效果的话,EasyEagle以接口的形式,提供了针对任务优化效果的对比分析接口功能,能够体现出任务优化前后,消耗的资源量,任务资源利用率,Container资源利用率等多项指标,帮助用户全面了解优化前后的对比。
用户根据此功能模块,能较快地解决以下问题:
-
通过任务资源诊断,快速了解任务的资源情况、调整任务资源配比,提升资源利用率;
-
任务的资源利用率提升,会释放更多集群或队列的闲置资源,能提升集群或队列的整体任务吞吐量;
-
任务资源利用率的提升,降低了集群或队列的负载水平,提升了集群的稳定性。
任务全链路诊断
用户层面除了对任务的资源有所监控外,也需要对其运行状况有所监控诊断:
-
任务运行是否正常,如不正常哪里存在问题
-
和历史运行情况对比是否有所差异,差异在哪里,什么原因造成的
-
任务若一直很慢,是否能有所优化等等
如何回答上面的问题?我们将任务运行的各个阶段进行了抽象,并结合内部运维的相关经验和排查回路,将其整理成一套切实可行的自动诊断服务。该功能模块主要有两个作用,问题定位以及性能优化。下面将会从这两方面进行相关介绍。
3.1 问题定位
以任务初始化阶段为例,我们将此阶段按照状态机的状态变化,划分以下检查项:
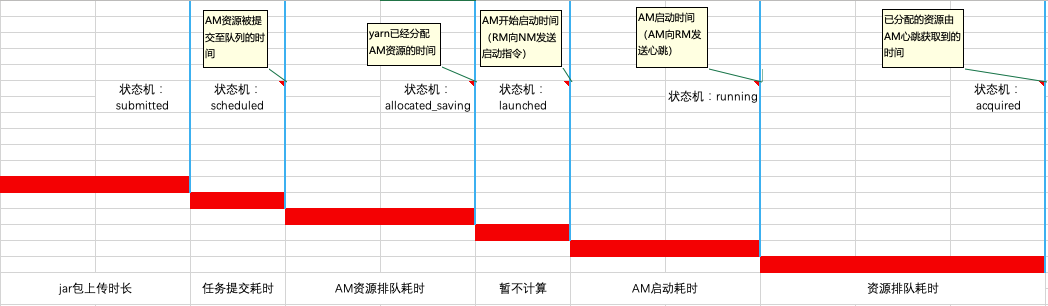
根据上面划分的检查项,我们能很快地诊断出在任务初始化阶段,哪个项出现问题,由什么原因造成。
以AM资源排队耗时这个检查项为例,我们是如何进行诊断分析:
-
获取任务该检查项的耗时;
-
与集群AM分配速率以及该任务此检查项的历史水平进行对比;
-
如发现不匹配集群的分配速率或超出历史统计模型设置的上限,则检查任务提交队列的AM资源水位;
-
将其原因进行记录并返回给用户。
通过上面的分析回路,能极快地将问题排查并通知给用户。
除此检查项外,我们将任务在Yarn上的全执行过程进行阶段拆分,共拆封成了AM分配耗时、AM本地化启动、Container分配、任务运行、结果提交这五个阶段。在产品中,对任务的全链路诊断,能直观的展示出任务各阶段的耗时,任一阶段出现异常都能快速定位,同时也方便将任务的历史任务的阶段耗时与本次执行时间进行对比,如下所示:
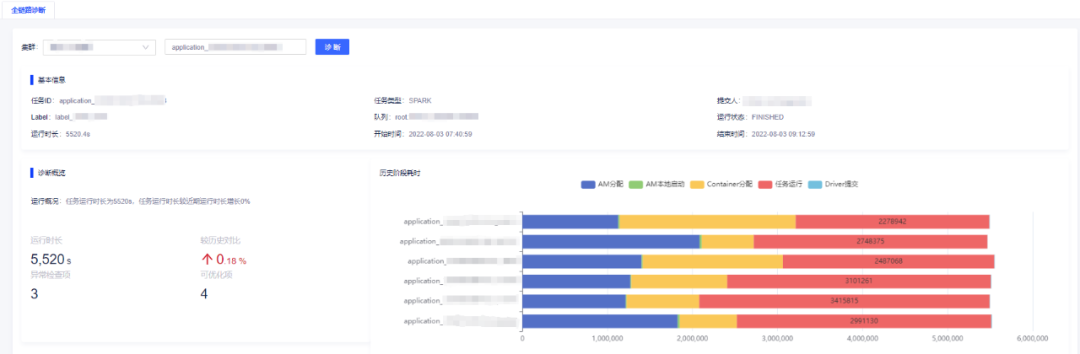
针对全链路这个概念,我们不仅仅指的是任务运行途径的各个服务,也包含任务运行所在的各个节点。
以实际案例进行介绍:业务方发现某个Spark任务运行时长相较于历史,有较大的增长。通过EasyEagle进行相关诊断,分析如下:
-
和该任务历史运行情况对比,发现各stage数据量没有变化;
-
某stage的shuffle read time有较大的增长,超出了统计模型的上限;
-
检查此stage的各个task运行情况,根据长尾task,获取运行的executor节点;
-
检查该节点的IO指标,发现节点IO异常;
-
将其原因进行记录并返回给用户。
用户根据此功能,能极快地定位问题原因,减少排查耗时对业务方的影响。
3.2 性能优化
EasyEagle在针对任务的全链路诊断中,不仅涉及到异常定位,也有针对任务的优化建议报告。在优化方面主要分两点:
-
资源优化
-
产出耗时优化
资源优化这块在上述的资源治理功能模块里面有详细的讲解,在此不再累述。针对产出耗时优化这块,EasyEagle目前将主要影响任务产出的各个阶段进行了抽象,并利用相关的统计模型以及历史数据进行分析,将其作为优化建议反馈给用户。
以线上一个实际任务为例:该任务的某个stage运行的task数量为60000,该阶段最多运行task数量为400,并且该stage的所有task的shuffle read数据量无明显倾斜,处理数据量较配置而言较少(10%左右)。
我们在针对上述问题时,会有针对性给出用户降低该stage的partitions数量的建议,提高每个task的数据处理量,减少此stage的运行轮数。进而加快此任务的产出。
上述举例的诊断分析,仅仅只是EasyEagle中部分诊断规则,并且在我们内部的实践中得到多次的印证。不论是问题定位还是性能优化,在任务全链路诊断模块中,都会将具体某一类的问题抽象成一个概括性的检查项,并直观的反馈给用户。

用户在使用EasyEagle的全链路诊断功能后,不需要企业对从业任务有较高的专业要求情况下,就能解决以下问题:
-
定位任务慢的问题原因
-
提高任务的资源利用率
-
加快任务的产出耗时
小结
本篇围绕着集群中微观的任务视角进行了相关的介绍。对于数据平台的普通用户来说,提交任务是他们使用数据平台的主要窗口,EasyEagle从此视角出发,从最基础的任务运行信息,到任务慢原因的全链路诊断,再深入到任务的资源优化、性能优化等方面,让用户用数据平台时能够清晰掌握任务的方方面面。
针对NDH智能运维平台EasyEagle的介绍到这里就暂时告一段落了,后续EasyEagle产品会持续更新迭代,打造出更加智能化、透明化的大数据底层监控与诊断平台。
感谢您的关注与支持~

本文转载自 黄一桐 网易有数,原文链接:https://mp.weixin.qq.com/s/2x4ba5gm7oYw6WdwjWmu9Q。