
一 业务背景

-
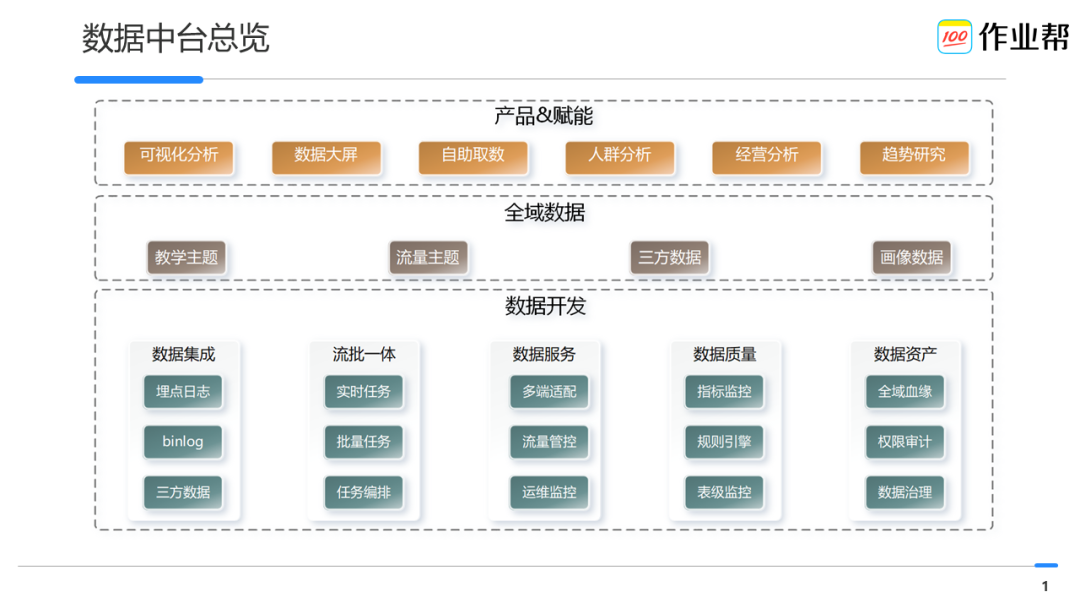
第一层是数据产品以及赋能层
-
第二层是全域数据层
-
第三层是数据开发层
二 问题&痛点
-
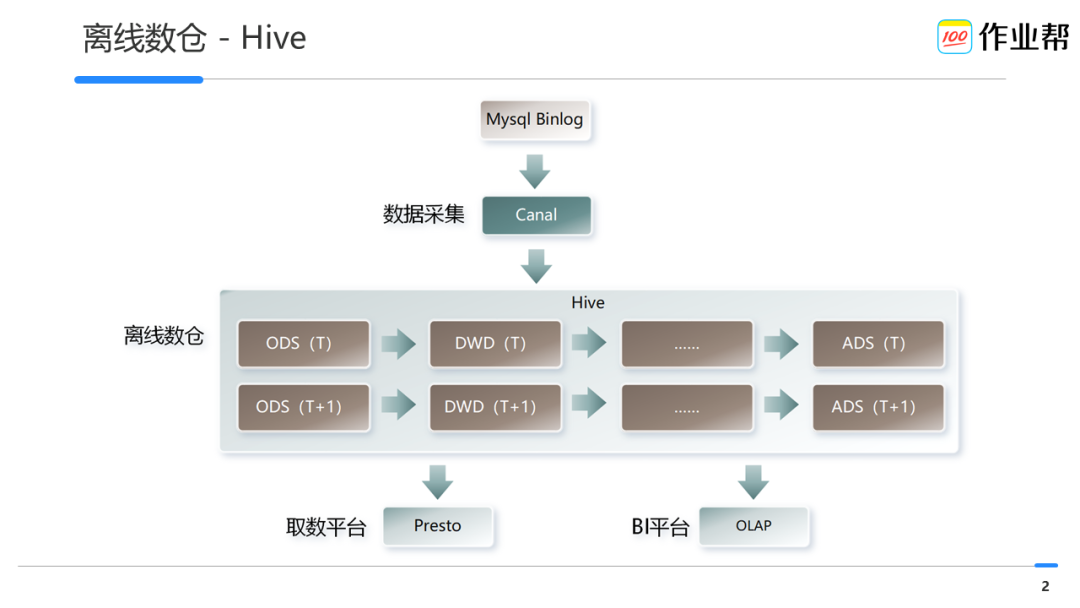
ADS 表产出延迟越来越长
-
小时级表需求难以承接
-
数据探查慢、取数稳定性差
三 解决方案
3.1 问题分析
-
链路计算慢的原因:由于 Hive 不支持增量更新,而来自业务层数据源的 Mysql-Binlog 则包含大量的更新信息,因此在 ODS 这一层,就需要用增量数据和历史的全量数据做去重后形成新的全量数据,其后 DWD、DWS、ADS 均是类似的原理。这个过程带来了数据的大量重复计算,同时也带来了数据产出的延迟。 -
数据查询慢的原因:由于 Hive 本身缺少必要的索引数据,因此不论是重吞吐的计算还是希望保障分钟级延迟的查询,均会翻译为 MR-Job 进行计算,这就导致在数据快速探查场景下,查询结果产出变慢。
3.2 方案调研
-
基于 HBase+ORC 的解决方案
-
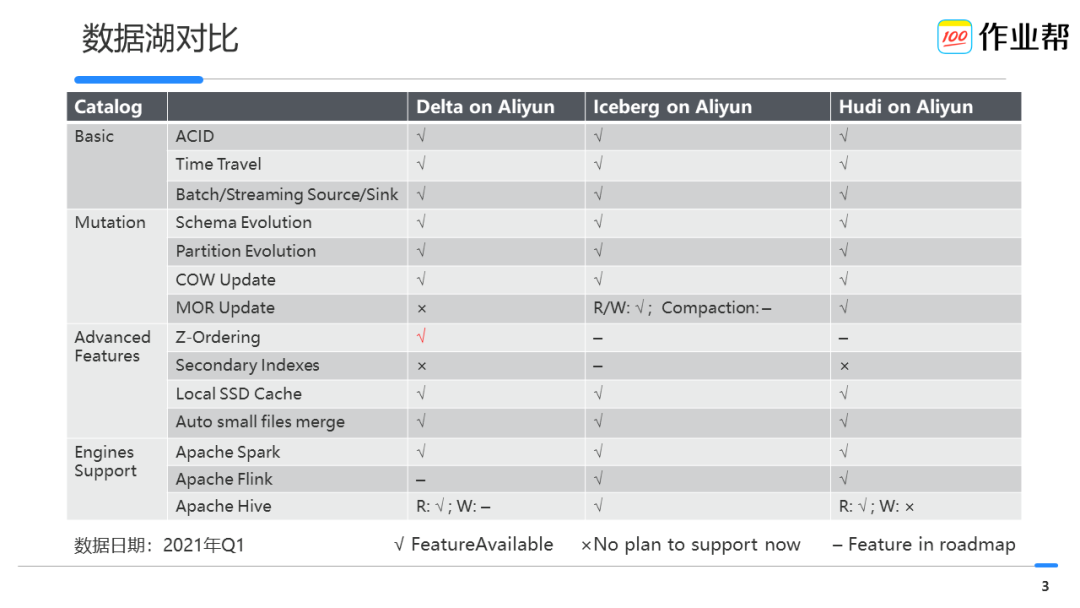
数据湖
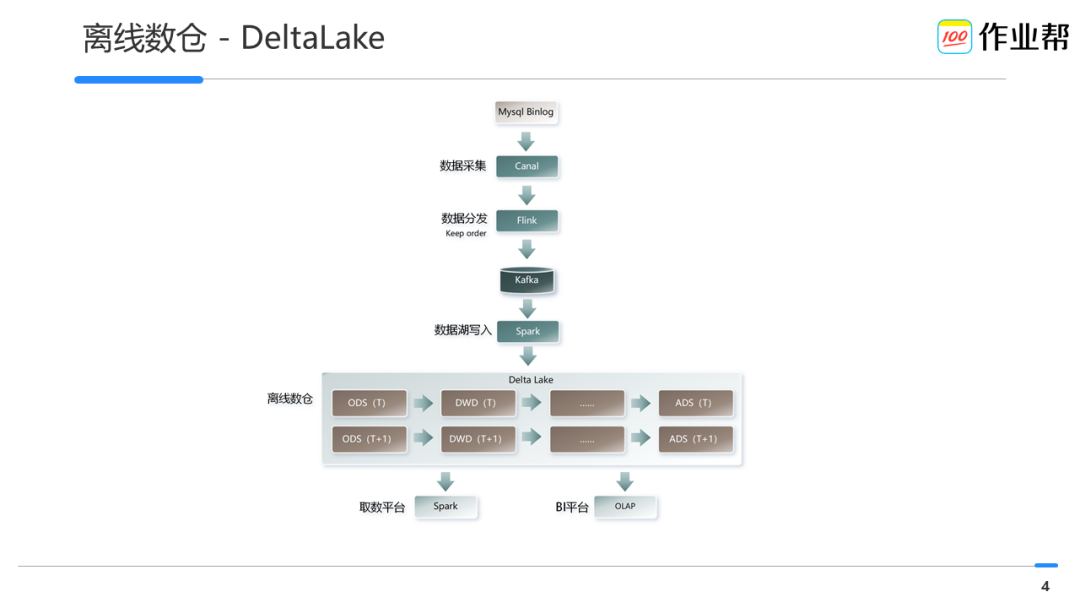
四 基于 DeltaLake 的离线数仓
4.1 流数据转批
1. 如何界定数据完全就绪
-
流数据有序后界定批数据边界 -
保障流数据有序的机制

-
设定数据表的逻辑分区字段 dt 以及对应的时间单位信息。

-
当 Spark 读取某一个 batch 数据后,根据上述表元数据使用数据中的 event time 生成对应的 dt 值,如数据流中 event time 的值均属于T+1,则会触发生成数据版本T的 snapshot,数据读取时根据 snapshot 找到对应的数据版本信息进行读取。
2. 如何解决流数据的乱序问题
-
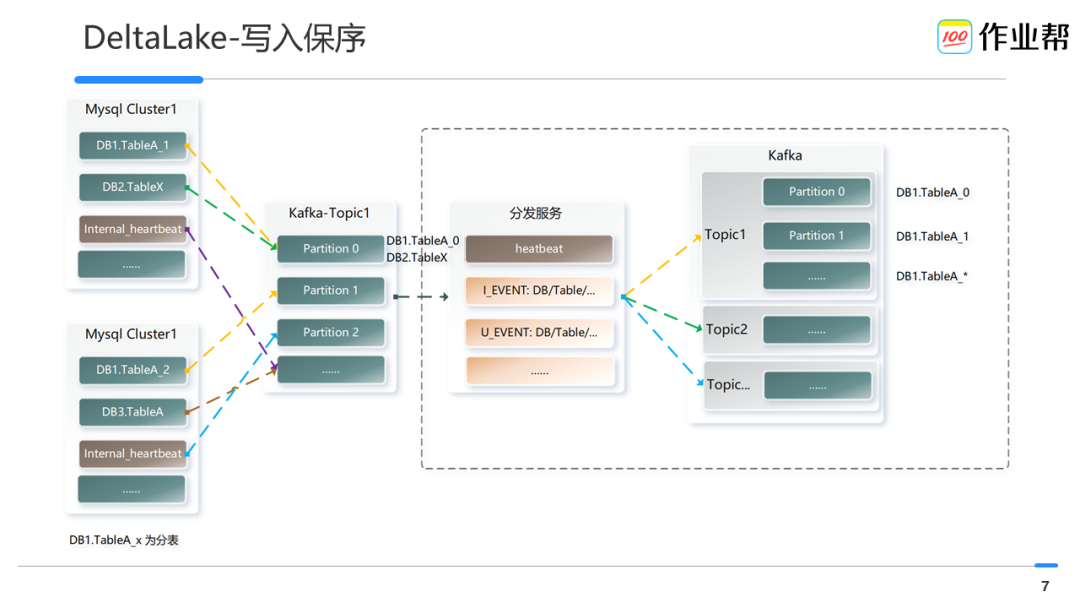
保障分库分表,甚至不同分表在不同集群的情况下,数据写入到 Kafka 后的有序性。即写入 DeltaLake 的 Spark 从某个 topic 读取到逻辑表的数据是 partition 粒度有序的。 -
保障 ODS 表就绪的时效性,如区分无 Binlog 数据的情况下,ODS 层数据也可以按期就绪。
-
将逻辑表名(去分表_*后缀)的数据写入到对应的 topic,并使用物理表名进行 hash。保障单 partition 内部数据始终有序,单 topic 内仅包括一张逻辑表的数据。 -
在 MySQL 集群内构建了内部的心跳表,来做 Canal 采集的延迟异常监控,并基于此功能设置一定的阈值来判断当系统没有 Binlog 数据时是系统出问题了还是真的没数据了。如果是后者,也会触发 DeltaLake 进行 savepoint,进而及时触发 snapshot来保障 ODS 表的及时就绪。
4.2 读写性能优化
1. 通过 DPP 提高写性能

-
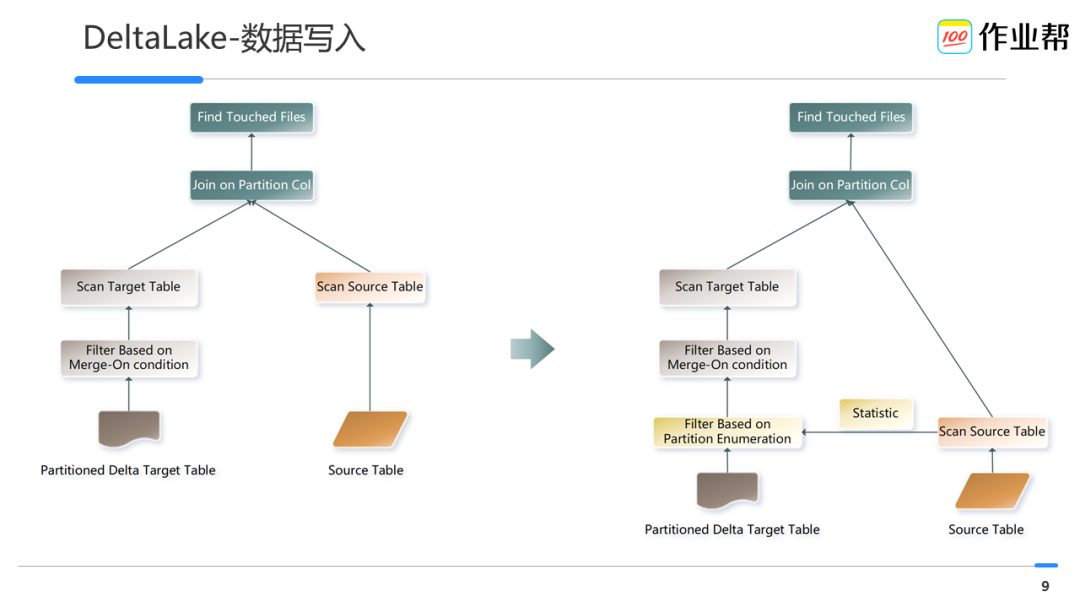
定位到要更新的文件,默认情况下需要读取全部的文件和 Spark 内 batch 的增量数据做 Join,关联出需要更新的文件来。 -
Merge 后重新写入这些文件,把老的文件标记为删除。
-
分析 Merge-on 条件,得到 source 表中对应到 DeltaLake 表分区字段的字段。 -
统计得到分区字段的枚举列表。 -
将上步结果转化成 Filter 对象并应用,进一步过滤裁剪数据文件列表。 -
读取最终的数据文件列表和 batch 的 source 数据关联得到最终需更新的文件列表。
2. 使用 Zorder 提高读性能
-
Dataskipping
-
DeltaLake 会按照文件粒度统计各个字段的 max/min 值,用于直接过滤数据文件。
-
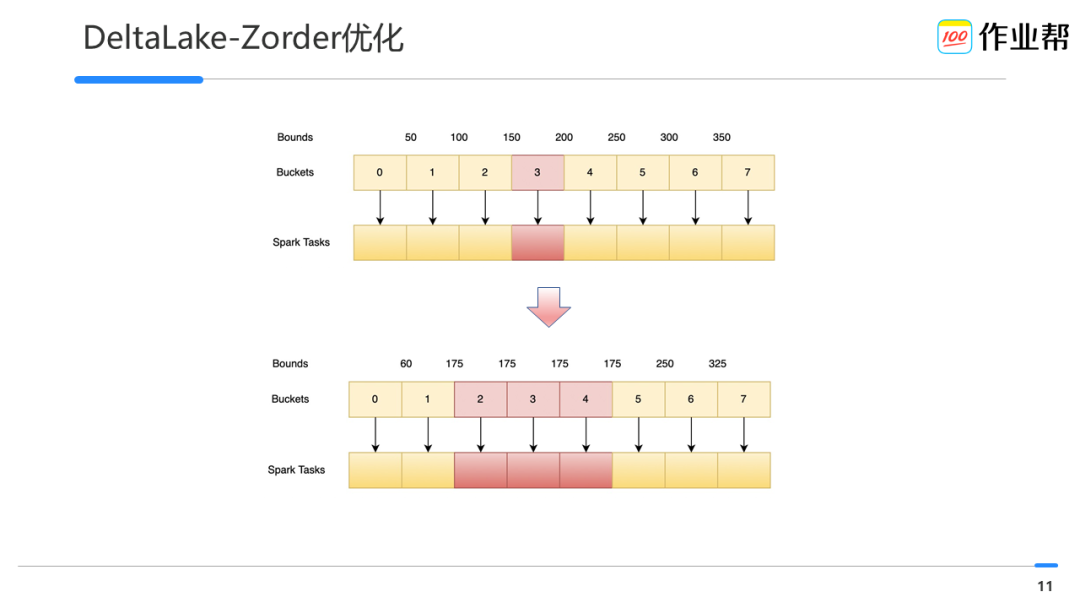
Zorder
-
一种数据 layout 的方式,可以对数据重排列尽可能保证 Zorder 字段的数据局部性。
-
常规情况下,对于多列的 Zorder,由多次遍历数据集改为遍历一次数据集来提升构建效率。构建时长从平均~30mins降低到~20mins。 -
数据倾斜下,对于倾斜列所在的 bucket 做了热点分散,构建时长从平均~90mins降低到~30mins。
4.3 总体效果
-
就绪时间更快:ODS 替换到 DeltaLake 后,产出时间从之前凌晨2:00 – 3:00 提前到凌晨00:10左右,产出时间提前了2个多小时。 -
能力扩展更广:大数据具备了支持小时全量表的能力,利用 DeltaLake 增量更新的特性,低成本的实现了小时全量的需求,避免了传统方案下读取全量数据的消耗。目前已经应用到了部分核心业务中来,构建小时级全量表,同时时效性上保障从过去的~40mins降低到~10mins。 -
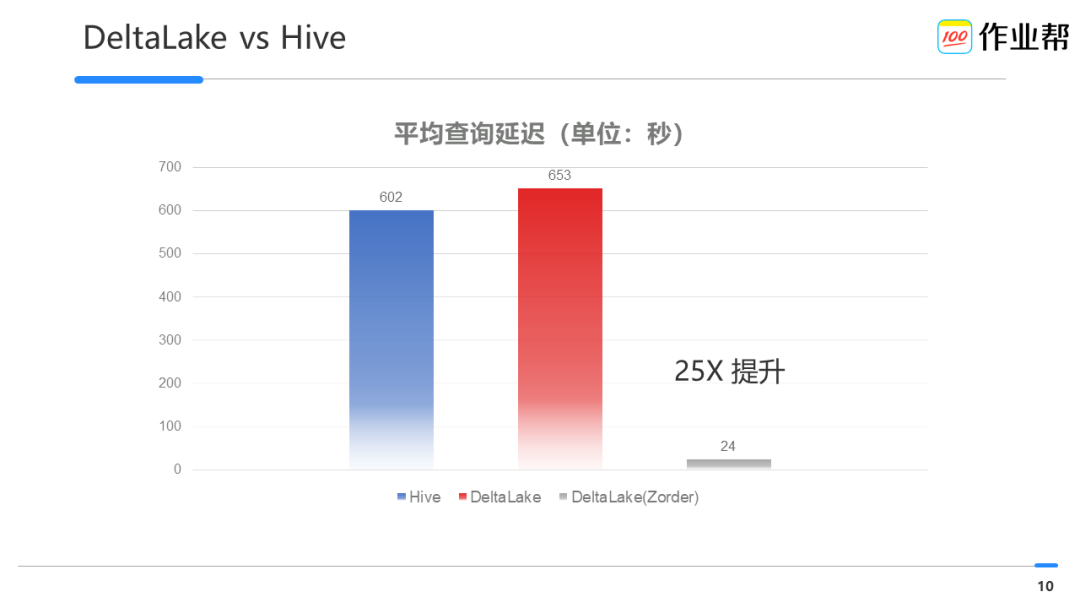
查询速度提升:我们重点提升的分析师的即席查询效率,通过将分析师常用的数仓表迁移到 Deltalake 之后,利用 Zorder 实现了查询加速,查询速度从过去的数十分钟降低到~3mins。
五 未来规划
-
提高修数效能。
-
使用 Hive 时我们可以方便的针对某个历史分区独立修复,但是 DeltaLake 表修数时需要通过回退故障版本后的所有版本。
-
完全支持 Hive 引擎。
-
目前我们使用 DeltaLake,主要解决了过去使用 Hive 查询慢、使用 Presto 限制复杂查询的问题,在复杂查询、低延迟上提供了解决方案,但前面提到的 GSCD、Dataskipping 等特性 Hive 还不支持,导致用户无法像使用 Hive 一样使用 DeltaLake。
-
支持 Flink 接入。
-
我们流计算系统生态主要围绕 Flink 构建,引入 DeltaLake 后,也同时使用 Spark,会导致我们的流计算生态维护成本加重。
六 致谢
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/8201/