
概要速览
RaptorX是Meta(前“Facebook公司”,下文统称“Meta”)公司的一个内部项目名称,目的是为了降低查询延迟,让Presto的查询性能大大超越原生(vanilla) Presto,这篇文章介绍了RaptorX的关键模块——分层缓存。
有了分层缓存,我们能够将查询性能提升10倍。这一新的架构不仅可以完胜像Raptor之类以性能为导向的连接器,还具有向存储分离化(即存算分离架构)进行持续拓展和支持的额外优势。
存储分离化是行业朝着独立存算扩容发展的必然趋势,能够帮助云服务供应商降低成本。Presto本身支持这样的存算分离架构,而数据可以从部署了Presto的服务器之外的远程存储节点获取。
尽管如此,存算分离对查询延迟提出了新的挑战,因为在网络饱和的情况下,通过网络扫描海量数据会受到IO的限制。此外,元数据访问和操作路径也需要通过网络来获取数据的位置;几个元数据RPC来回就能轻易地把延迟抬高到一秒以上,下图用橙线表示Hive连接器的IO相关操作路径,每条路径都可能成为查询性能的瓶颈。
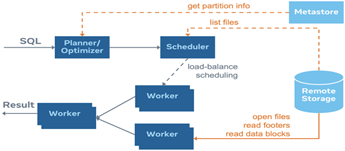

过去,为了解决网络饱和的问题,Presto通过内嵌的Raptor连接器,将数据从远端存储加载到本地的SSD(固态硬盘),从而实现快速访问,然而,这种解决方案与计算/存储共享节点差别不大,有悖于存算分离的理念。该解决方案的缺点很明显:要么因为worker节点的SSD空间已满而浪费CPU,要么因为CPU受限而浪费SSD容量。于是,Meta启动了RaptorX项目的开发。
RaptorX是为了将Presto查询性能提升至少10倍而开展的一个内部项目,其中分层缓存是RaptorX项目成功的关键。当存储节点与计算节点分离时,缓存的作用尤为显著。开发RaptorX的目的不是为了推出一个新的连接器或产品,而是构造一套内嵌的解决方案,让现有的工作负载无需迁移即可直接从中获益,该解决方案目前主要针对许多工作负载常用的Hive连接器。
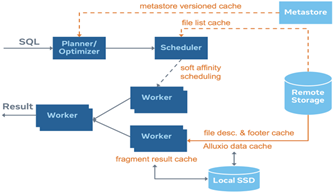
下图展示了缓存解决方案的整体架构,该缓存具有分层结构,本文会详细介绍:
✓
Metastore版本化的缓存方案:我们把表/分区信息缓存到coordinator中,鉴于元数据是可变的,就像Iceberg或Delta Lake那样,因此信息是被版本化的,我们只与metastore同步版本信息,并仅在当前版本失效时去获取最新版本。
✓
文件列表缓存:将来自远端存储分区目录的文件列表缓存起来。
✓
片段结果缓存:在leaf worker的本地SSD上缓存部分计算结果。由于查询会不断变化,所以我们需要运用裁剪技术来简化查询计划。
✓
文件句柄(file handle)和footer的缓存:在leaf worker内存中缓存打开的文件描述符(file descriptor)和stripe/文件footer信息,因为在读取文件时这些数据往往会被频繁访问。
✓
Alluxio数据缓存:在leaf worker的本地SSD上用对齐的1MB大小数据块来缓存文件段。该库(library)是通过Alluxio的缓存服务搭建的。
✓
亲和调度器:是指根据文件路径固定地向对应worker发送请求,从而使缓存命中率最大化的调度器(scheduler)。
Presto coordinator会缓存表的元数据(模式、分区列表和分区信息),以避免向Hive Metastore发起耗时很长的getPartitions调用,但是,Hive表的元数据是可变的,所以我们需要进行版本管理并确定已缓存的元数据是否有效,因此,coordinator为每个缓存的键值对赋予了一个版本号。当收到读取请求时,coordinator会查询Hive Metastore,获取(未被缓存的)分区信息,或者与Hive Metastore核对确认已经缓存的信息是否是最新的。虽然和Hive Metastore进行远程交互的操作不可避免,但与获取全部分区信息相比,版本匹配的成本相对较低。
Presto coordinator将文件列表缓存在内存中,从而避免对远端存储发起耗时很长的listFile调用。这只适用于封闭的目录, 而对于开放分区,为了确保数据的实时性,Presto不会缓存这些目录。开放分区的一个主要用例是支持近实时的数据导入和处理。在这种情况下,数据导入引擎(如微批数据micro batch)将不断向开放分区写入新的文件,以便Presto可以读取近实时的数据。其他诸如压缩、metastore更新或为近实时导入数据创建副本等详细信息不在本文的讨论范围内。
运行在leaf 阶段的Presto worker可以决定将部分计算结果缓存在本地SSD上,这么做是为了防止多次查询时进行重复计算。最典型的用例是将执行计划的包括扫描、过滤、投影和/或聚合的片段结果缓存在leaf阶段 。
例如,假设一个用户发送了以下查询,其中ds是一个分区列:
SELECT SUM(col) FROM T WHERE ds BETWEEN‘2021-01-01’ AND ‘2021-01-03’
对2021-01-01、2021-01-02和2021-01-03每个分区(更准确地说是相应的文件)计算的部分求和结果将被缓存在leaf worker上,形成一个“片段结果”,现在假设用户发送了另外一项查询:
SELECT sum(col) FROM T WHERE ds BETWEEN ‘2021-01-01’AND ‘2021-01-05’
现在,Leaf worker便可以直接从缓存中获取2021-01-01、2021-01-02和2021-01-03的片段结果(部分求和结果),并且只需要对2021-01-04和2021-01-05两个分区计算部分求和即可。
由于片段结果是基于leaf查询片段的,用户可以添加或删除过滤器或投影,因此非常灵活。上述例子表明,只包含分区列的过滤器很容易处理。但是为避免由于频繁变化的非分区列过滤器造成的缓存失效,我们引入了基于分区统计信息的裁剪策略,请看下述查询,其中time是一个非分区列:
SELECT SUM(col) FROM T
WHERE ds BETWEEN ‘2021-01-01’AND‘2021-01-05’
ANDtime > now() – INTERVAL‘3’ DAY
请注意:now()函数的值始终在变,如果leaf worker根据now()的绝对值来缓存计划片段,几乎不可能会命中缓存,但是,如果predicate(谓词条件) time > now() – INTERVAL ‘3’ DAY是对于大多数分区来说为真(true)的“宽松”条件,我们可以在调度时把该谓词从计划中删除。
例如,如果今天是2021-01-04,那么我们知道对于分区ds = 2021-01-04,predicate time > now() – INTERVAL ‘3’ DAY总是成立的。
如下图所示,一般而言,它包含一个谓词条件和3个分区 (A, B, C),以及各分区同谓词条件相关的最小值(min)、最大值(max)的统计信息(stats)。当分区统计域与谓词域没有任何重叠时(如分区A),我们可以直接裁剪掉该分区,不需要向worker发送分片(split)。如果分区统计域完全包含在谓词域中(如分区C),那么我们不需要该谓词,因为它对这个特定的分区总是成立的,我们可以在进行计划对比时省略该谓词条件。对于其他与谓词有一些重叠的分区,我们仍需要用给定的过滤器扫描整个分区。

Presto worker将文件描述符缓存在内存中,避免对远端存储进行耗时较长的openFile调用。此外,worker还会把经常访问到的列文件和stripe footer缓存在内存中。目前支持的文件格式是ORC,DWRF和Parquet。在内存中缓存此类信息的原因是footer作为针对数据建立的索引信息通常具有高缓存命中率。
Alluxio数据缓存是一个主要特性区别于被淘汰的Raptor连接器。Presto worker每次进行读取操作时将远端存储数据以它原始格式(经过压缩或者可能也经过加密)缓存在本地SSD上。对于将来的读取请求,如果读取范围内的数据已经缓存在本地SSD上,则该读取请求将直接从本地SSD返回结果。缓存库是我们与Alluxio和Presto开源社区共同搭建的。
缓存机制将每次读取对齐成1MB固定大小的数据块,这里的1MB是可以根据不同的存储能力进行配置的。比如,假设Presto发起一次从偏移量0开始的长度为3MB的读取请求,那么Alluxio缓存会检查0-1MB、1-2MB和2-3MB的数据块是否已经缓存在磁盘上,然后只远程获取尚未被缓存的数据块。缓存清除策略基于LRU,会从磁盘上删除最久没被访问过的数据块。Alluxio数据缓存为Hive连接器提供了标准的Hadoop文件系统接口,并且基于专门用来支撑规模达到Meta级别工作负载的高性能、高并发且可容错的存储引擎,以透明的方式对请求的数据块进行缓存。
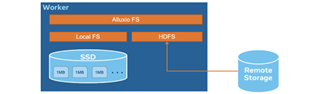
为了最大程度地提高worker的缓存命中率,coordinator需要将同一文件的请求调度给同一个worker。因为文件的一部分很有可能已经被缓存在那个特定的worker上了。调度策略是“软”的,也就是说,如果目标worker太忙或不可用,调度器会退而求其次,安排给它的备选worker进行缓存,或者在必要时直接跳过不予缓存。该调度策略确保了缓存不在关键路径上,但仍然能够提升性能。
Meta已经在公司内部全面部署了RaptorX缓存并进行了实战测试。为了与原生(vanilla) Presto进行性能比较,我们在一个包含114个节点的集群上进行了TPC-H基准测试。每个worker都有1TB的本地SSD,每个任务配置4个线程。我们在远端存储中准备了放大系数(scale factor)为100的TPC-H表。下图展示了Presto和装备了分层缓存的Presto之间的性能对比结果。
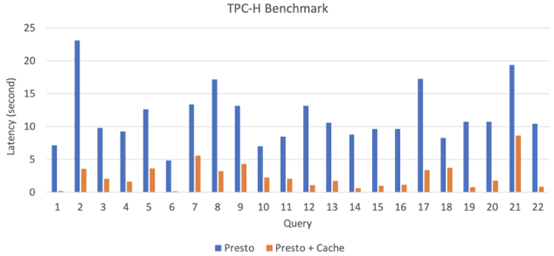
从基准测试结果来看,像Q1、Q6、Q12-Q16、Q19和Q22这样的重扫描或重聚合的查询都能实现超过10倍的延迟改善。甚至像Q2、Q5、Q10或Q17这样的重关联查询也有3-5倍的延迟改善。
要完全启用该功能,我们需要为worker配备本地的SSD,为了能够启用本文所述的各个缓存层,请进行以下配置:
调度(/catalog/hive.properties):
hive.node-selection-strategy=SOFT_AFFINITY
Metastore版本化的缓存(/catalog/hive.properties):
hive.partition-versioning-enabled=true
hive.metastore-cache-scope=PARTITION
hive.metastore-cache-ttl=2d
hive.metastore-refresh-interval=3d
hive.metastore-cache-maximum-size=10000000
文件列表缓存(/catalog/hive.properties):
hive.file-status-cache-expire-time=24h
hive.file-status-cache-size=100000000
hive.file-status-cache-tables=*
数据缓存(/catalog/hive.properties):
cache.enabled=true
cache.base-directory=file:///mnt/flash/data
cache.type=ALLUXIO
cache.alluxio.max-cache-size=1600GB
片段结果缓存(/config.properties and /catalog/hive.properties):
fragment-result-cache.enabled=true
fragment-result-cache.max-cached-entries=1000000
fragment-result-cache.base-directory=file:///mnt/flash/fragment
fragment-result-cache.cache-ttl=24h
hive.partition-statistics-based-optimization-enabled=true
文件和stripe footer 缓存(/catalog/hive.properties):
● 针对ORC 或DWRF格式:
hive.orc.file-tail-cache-enabled=true
hive.orc.file-tail-cache-size=100MB
hive.orc.file-tail-cache-ttl-since-last-access=6h
hive.orc.stripe-metadata-cache-enabled=true
hive.orc.stripe-footer-cache-size=100MB
hive.orc.stripe-footer-cache-ttl-since-last-access=6h
hive.orc.stripe-stream-cache-size=300MB
hive.orc.stripe-stream-cache-ttl-since-last-access=6h
● 针对Parquet格式:
hive.parquet.metadata-cache-enabled=true
hive.parquet.metadata-cache-size=100MB
hive.parquet.metadata-cache-ttl-since-last-access=6h
文章贡献者:
Meta:Abhinav Sharma, Amit Dutta, Baldeep Hira, Biswapesh Chattopadhyay, James Sun, Jialiang Tan, Ke Wang, Lin Liu, Naveen Cherukuri, Nikhil Collooru, Peter Na, Prashant Nema, Rohit Jain, Saksham Sachdev, Sergey Pershin, Shixuan Fan, Varun Gajjala
Alluxio: Bin Fan, Calvin Jia, HaoYuan Li
Twitter: Zhenxiao Luo
本文转载自Alluxio,原文链接:https://mp.weixin.qq.com/s/_NAFOfvceIoehMBcij4pHw。