


1.背景
◆1.1 业务背景
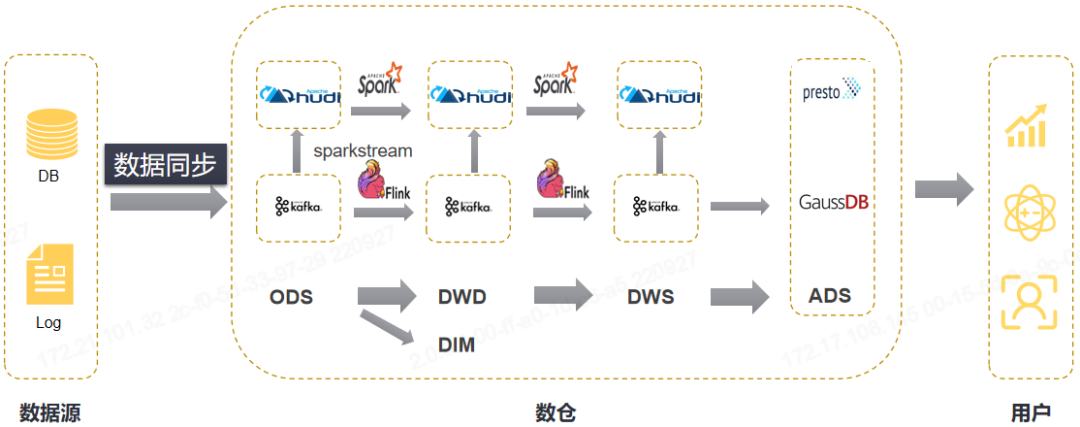 图一 数仓架构图
图一 数仓架构图◆1.2 技术背景
 图二 SparkStream写Hudi流程
图二 SparkStream写Hudi流程◆1.3 业务特征
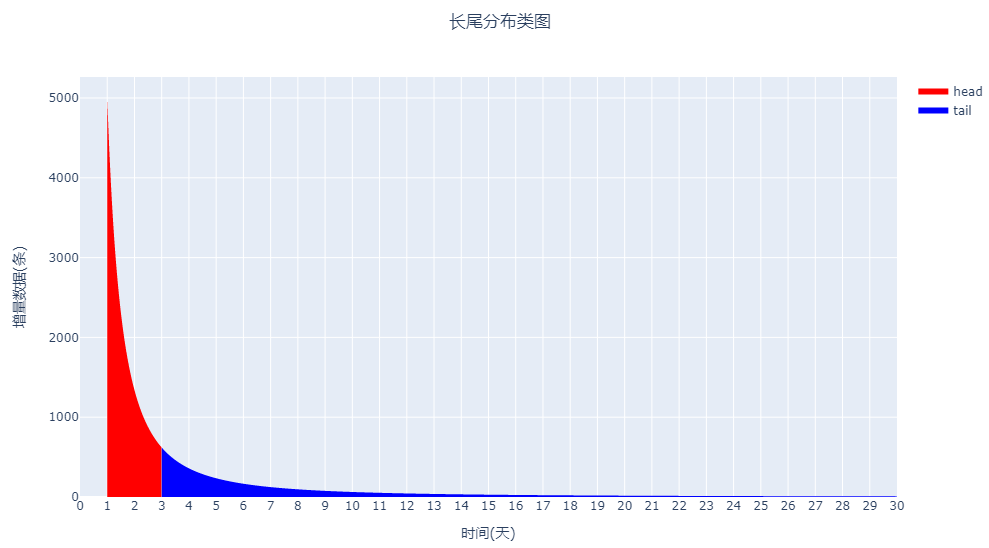 图三 长尾分布类图
图三 长尾分布类图◆1.4 总结
2.Hudi数据写入原理
◆2.1 COW(Copy on Write)写入原理
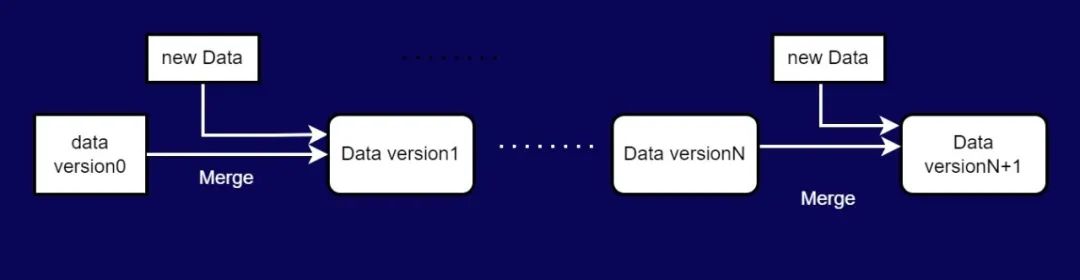 图四 COW格式表的数据写入原理
图四 COW格式表的数据写入原理◆2.2 MOR(Merge on Read)写入原理
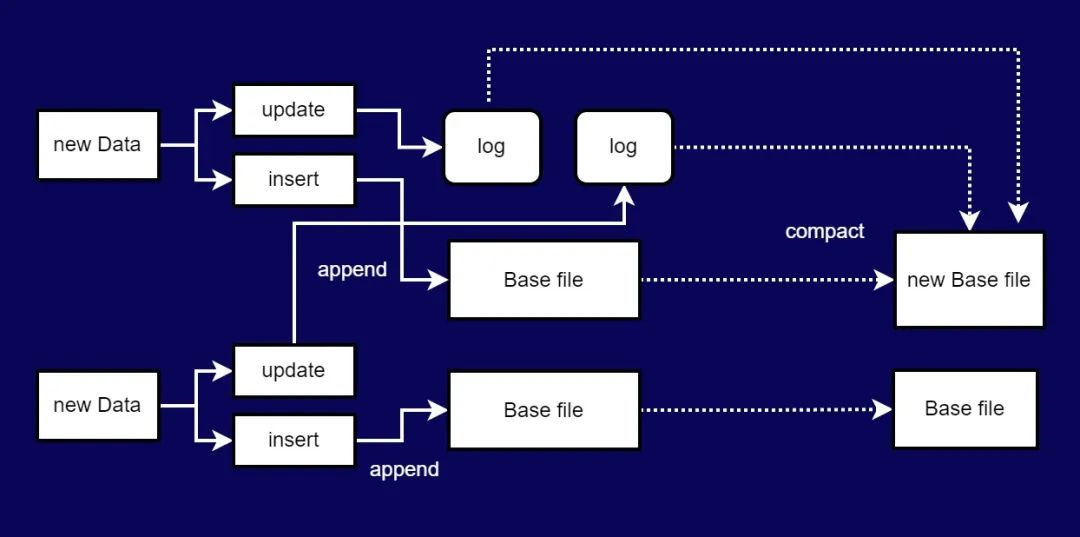 图五 MOR格式表的数据写入原理
图五 MOR格式表的数据写入原理◆2.3 总结
3.Hudi写入架构优化
◆3.1 整体架构
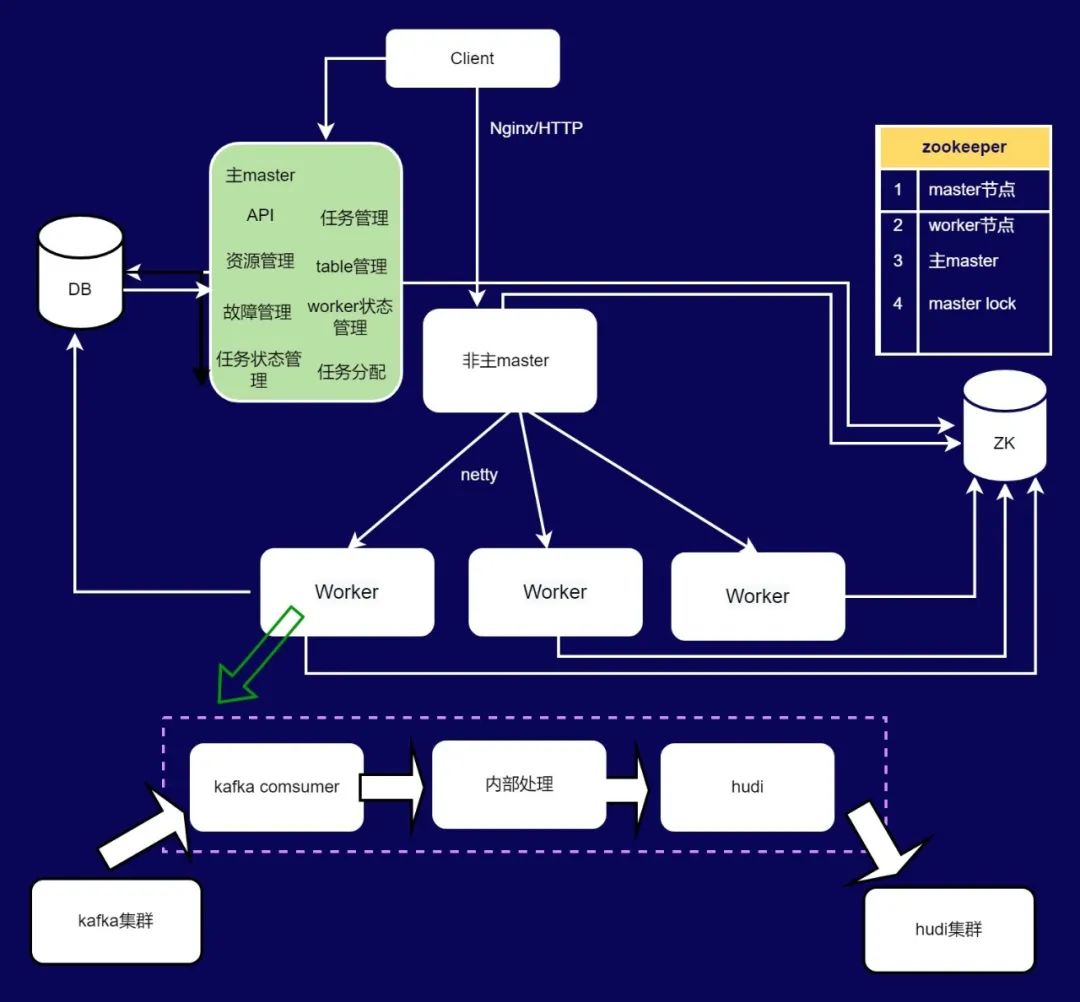 图六 Hudi服务化写架构
图六 Hudi服务化写架构-
数据通过客户端写入,或直接设置kafka consumer读取数据进行写入。 -
数据写入时会进行分区所属的确定,同时对于该条数据会查询对应分区的Index进行判断该数据是属于更新还是新增,更新和新增两个不同的数据分别写入不同的内存区域,同时更新Index数据并将数据写入WAL文件。 -
当数据达到一定规模或者时间达到一定阈值时,将内存的数据flush进入数据湖的文件系统中,新增数据写入insert文件中(同base文件),更新数据写入update文件(同log文件)。 -
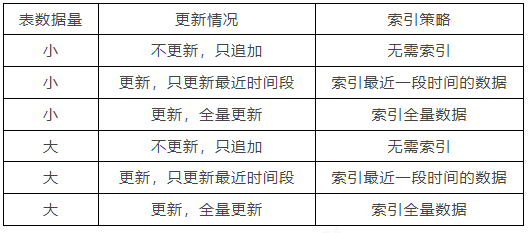
Index采用BloomFilter+RocksDB构建,按分区构建Index,Index只保留一段周期,一般为一周或一个月,定时删除历史分区的Index。 -
通过Java线程替换了Spark/Flink进程,对于小数据量的表节约了大量的资源。通过Index的优化,加速了tag过程。
◆3.2 Index构建处理
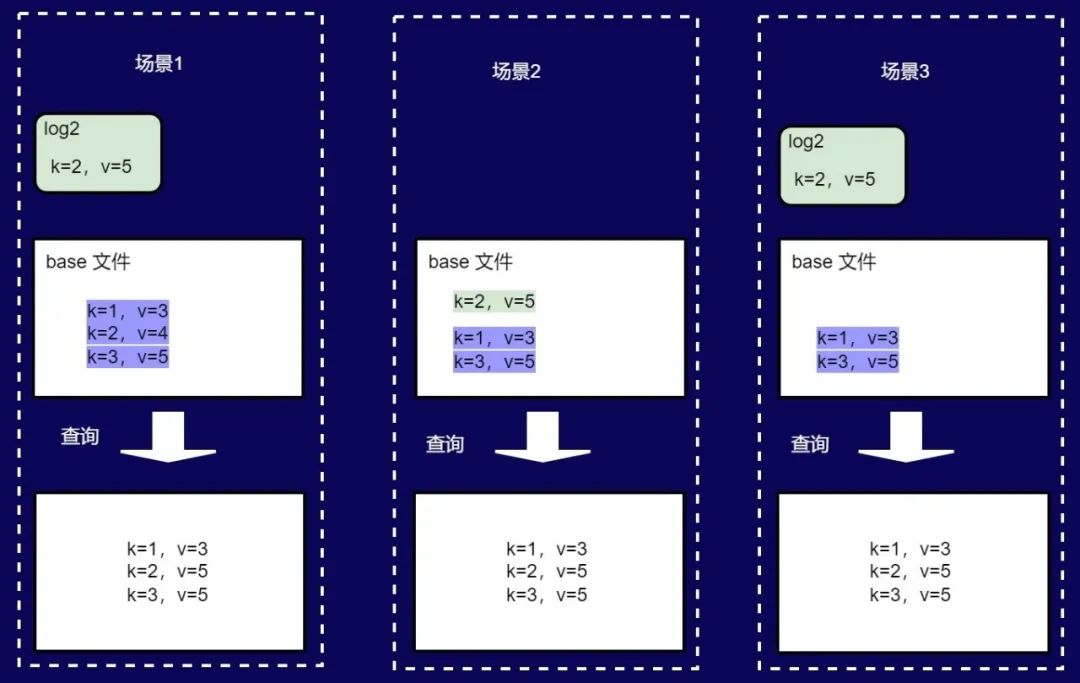 图七 MOR的三种数据场景
图七 MOR的三种数据场景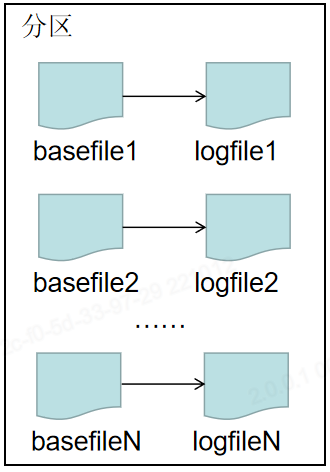
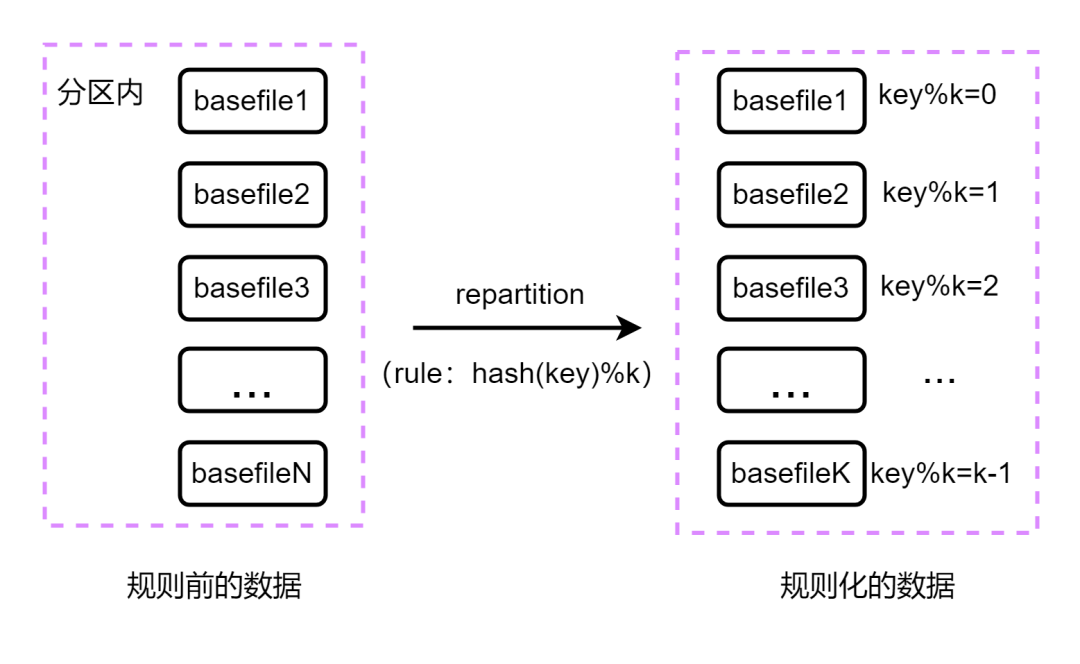 图九 基于hashrepartition过程
图九 基于hashrepartition过程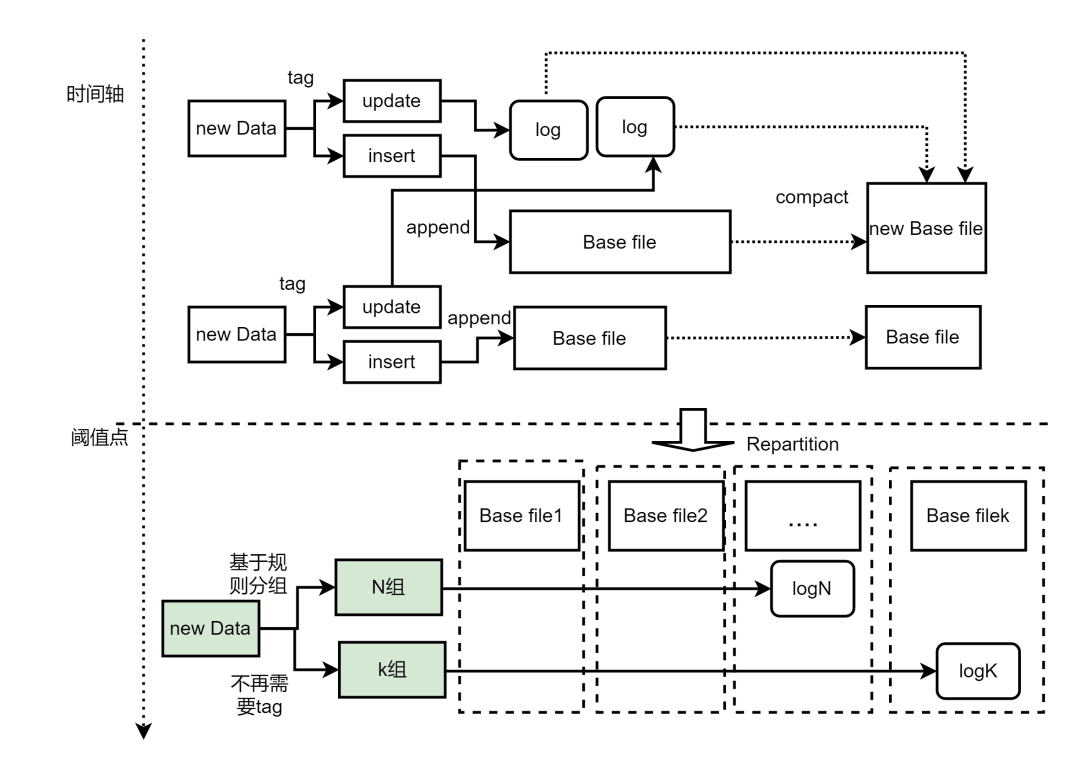 图十 repartition流程
图十 repartition流程◆3.3 优化效果评估
4.总结与展望
本文转载自兴盛优选技术社区,原文链接:https://mp.weixin.qq.com/s/A3uEw5bjnC0c-HAo0dRSfA。