
随着大数据时代的到来,数据量不断增长,HDFS也成为了数据存储和处理的重要组成部分。然而,由于HDFS的设计原理和文件存储方式,HDFS系统中存在大量的小文件,这些小文件会导致HDFS的性能下降,增加管理和维护的难度,严重影响数据处理效率和数据质量。因此,HDFS小文件的治理变得越来越重要。


HDFS小文件通常指文件大小小于HDFS块(Block)大小(默认为128MB)的文件。在HDFS系统中,小文件会带来以下问题:
1.占用过多的存储空间:由于HDFS文件系统的特点,每个文件都会占用一个独立的Block,因此大量的小文件会导致内存空间的浪费,增加HDFS系统的内存开销;
2.影响数据处理效率:HDFS是为大量的数据处理而设计的,而小文件会导致数据处理效率下降,增加数据处理时间和开销;
3.增加管理和维护难度:当HDFS系统中存在大量的小文件时,管理和维护变得更加困难,需要耗费更多的精力和时间来维护系统。
针对HDFS小文件的问题,有以下几种治理方法:
1.合并小文件:将多个小文件合并为一个大文件,减少文件数量。这种方法需要注意文件的内容和格式,以免合并后的文件无法使用或者存在数据丢失等问题;
2.压缩文件:将多个小文件压缩为一个压缩包,减少存储空间。这种方法可以使用Hadoop自带的压缩工具,如gzip、bzip2等;
3.删除无用文件:删除不再需要的小文件,释放存储空间;
4.设置文件过期时间:对于不再需要的文件,可以设置其过期时间,自动删除过期文件;
5.使用SequenceFile:使用Hadoop自带的SequenceFile格式存储小文件,将多个小文件合并到一个SequenceFile中,以减少文件数量,提高处理效率。
以下是一些HDFS小文件治理的实践案例:
1.合并小文件:对于日志文件等大量的小文件,可以使用Hadoop自带的合并工具将多个小文件合并为一个大文件。下面是通过hive的重写方式合并小文件,核心参数如下;
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;set hive.merge.mapfiles = true;set hive.merge.mapredfiles = true;set hive.merge.smallfiles.avgsize=256000000;set hive.merge.size.per.task=12800000;set mapred.max.split.size=256000000;set mapred.min.split.size=64000000;set mapred.min.split.size.per.node=64000000;set mapred.min.split.size.per.rack=64000000;
2.压缩文件:对于大量的小文件,可以使用压缩工具将多个小文件压缩为一个压缩包,以减少存储空间。例如,使用gzip或bzip2压缩工具压缩文件,在HDFS上存储压缩文件,以减少存储空间和文件数量;
3.删除无用文件:对于不再需要的小文件,可以使用Hadoop自带的命令hadoop fs -rm命令删除文件,或者使用定时任务脚本定期删除过期文件;
4.设置文件过期时间:使用hadoop fs -touchz命令设置文件的过期时间,当文件过期后,自动删除文件。例如,使用hadoop fs -touchz命令设置文件的过期时间为30天,当文件超过30天未被访问时,自动删除文件;
5.使用SequenceFile:对于大量的小文件,可以使用SequenceFile格式存储文件,将多个小文件合并成一个SequenceFile文件。例如,使用Hadoop自带的SequenceFile.Writer类将多个小文件写入SequenceFile文件中,以减少存储空间和文件数量。

HDFS的fsimage是HDFS文件系统的一个重要组成部分,记录了HDFS文件系统的元数据信息,包括文件、目录、权限、块等信息。通过监控HDFS的fsimage,可以了解HDFS文件系统的整体情况,包括文件数量、文件大小、文件类型等信息,进而实现对HDFS小文件的监控和治理。
具体来说,可以通过以下步骤对HDFS小文件进行监控:
1.获取HDFS的fsimage:使用Hadoop自带的命令hdfs oiv -p XML -i fsimage命令获取HDFS的fsimage文件。该命令会将HDFS的fsimage文件以XML格式输出,包括HDFS中所有文件和目录的元数据信息;
2.解析fsimage文件:使用Python等脚本语言解析获取到的fsimage文件,提取其中的文件、目录、块等信息。可以使用Python的ElementTree模块等工具对XML文件进行解析,提取需要的信息;
3.统计文件数量和文件大小:根据解析后的文件信息,统计HDFS中小文件的数量和大小。通常可以根据文件大小和文件数量的阈值来定义小文件,例如文件大小小于128MB或文件数量小于1000个等;
4.可视化展示:使用可视化工具,如Grafana、Kibana等将统计结果进行可视化展示,以便于对HDFS小文件的监控和管理。
下面是解析HDFS的fsimage文件,导入hive表进行分析得到最终结果表导入clickhouse通过grafana进行数据展示;
解析fsimage文件为txt文件:
hdfs oiv -i fsimage_0000000192578352133 -o /data2/data/fsimage/$day/fsimage.txt -p Delimited -t /data2/data/fsimage/$day/tmpfsimage文件重要的字段释义:
INODE_ID:文件或目录的唯一标识符;NAME:文件或目录的名称;PARENT_ID:父目录的INODE_ID;MODIFICATION_TIME:最后修改时间;ACCESS_TIME:最后访问时间;BLOCK_IDS:文件的数据块ID列表;BLOCK_SIZE:数据块大小;NUM_BLOCKS:数据块数量;PERMISSIONS:文件或目录的权限信息;USER_NAME:文件或目录所属用户;GROUP_NAME:文件或目录所属用户组;SYMLINK:如果是符号链接,则包含符号链接的目标路径;UNDER_CONSTRUCTION:如果文件正在写入中,则为true;UNDER_RECOVERY:如果文件正在恢复中,则为true;FILE_LENGTH:文件长度;NS_QUOTA:命名空间配额;DS_QUOTA:磁盘配额;STORAGE_POLICY:存储策略。
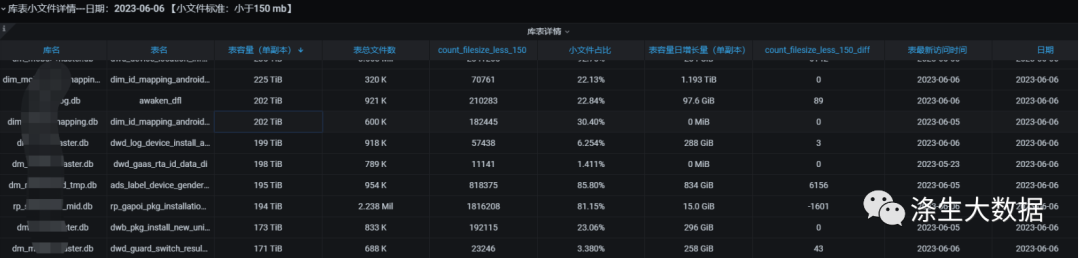
下面是基于解析后的文件映射到hive表最终处理后的数据表和最终数据样例:
CREATE TABLEtmp_fsimage_info_log_clean(pathstring,replicationint,dbstring,table_namestring,parttition_nm1string,parttition_nm2string,parttition_nm3string,file_namestring,modificationtimestring,accesstimestring,preferredblocksize_mbdecimal(20,5),blockscountint,filesize_mbdecimal(20,5),filesize_gbdecimal(20,5),usernamestring,groupnamestring)PARTITIONED BY (stat_daystring COMMENT '分区时间:yyyy-mm-dd')ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
同步hive数据到CK的工具使用的是seatunnel,下面贴一份相关的配置文件:
env {spark.app.name = "hive_to_clickhouse"spark.executor.instances = 10spark.executor.cores = 4spark.executor.memory = "12g"}source {file {path = "hdfs://ds01:8020/user/hive/warehouse/paas_test.db/db_table_file_all/stat_day="${day}""result_table_name = "db_table_file_all"format = "orc"}}transform {sql {sql = "SELECT '"${dayStr}"' as stat_day, _col0 as db, _col1 as table_name,_col2 as sum_filesize,_col3 as count_filesize,_col4 as count_filesize_less_10,_col5 as count_filesize_less_50,_col6 as count_filesize_less_150,_col7 as count_filesize_less_250,_col8 as count_filesize_less_300,_col9 as count_filesize_less_10_diff,_col10 as count_filesize_less_50_diff,_col11 as count_filesize_less_150_diff,_col12 as count_filesize_less_250_diff,_col13 as count_filesize_less_300_diff,_col14 as table_storage_increase,_col15 as count_filesize_diff,_col16 as latest_accesstime from db_table_file_all"}}sink {clickhouse {host = "ds03:8123"clickhouse.socket_timeout = 50000database = "fsimage_info"table = "db_table_file_all"fields = ["db","table_name","sum_filesize","count_filesize","count_filesize_less_10","count_filesize_less_50","count_filesize_less_150","count_filesize_less_250","count_filesize_less_300","count_filesize_less_10_diff","count_filesize_less_50_diff","count_filesize_less_150_diff","count_filesize_less_250_diff","count_filesize_less_300_diff","table_storage_increase","count_filesize_diff","latest_accesstime","stat_day"]username = ""password = ""}}
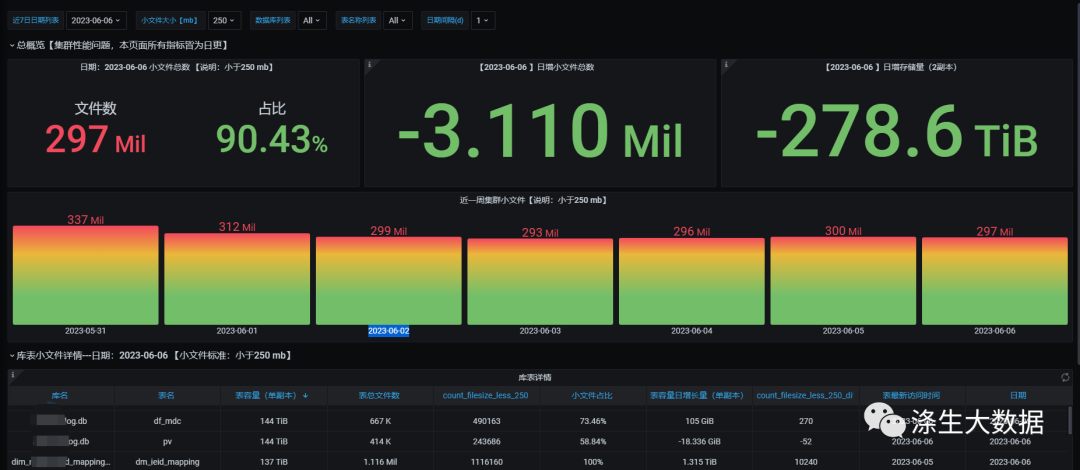
最终展示在grafana中效果:
本文转载自涤生-强哥 涤生大数据,原文链接:https://mp.weixin.qq.com/s/uobtDu5B3EQrCLnCwQhtsg。