
导读 本文将分享 Alluxio 社区和 Presto 社区在数据湖方面的一些工作,主要聚焦 Iceberg。
文章包括以下几个部分:
1. Presto & Alluxio
2. Alluxio & Iceberg
3. 最佳实践
4. 未来的工作
分享嘉宾|王北南博士 Alluxio 软件工程师
编辑整理|唐洪超 敏捷云
出品社区|DataFun
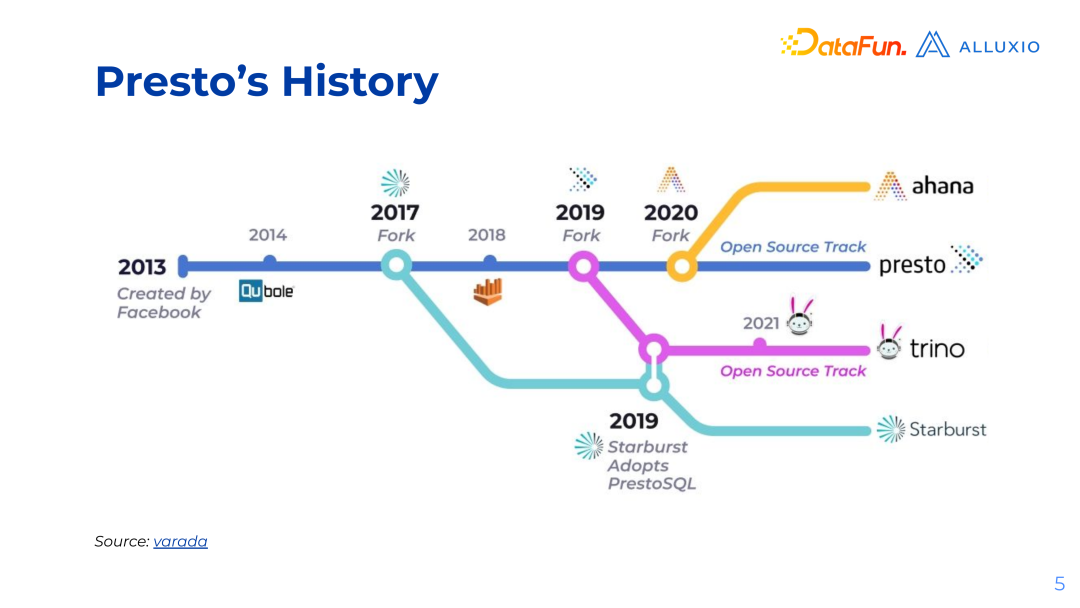
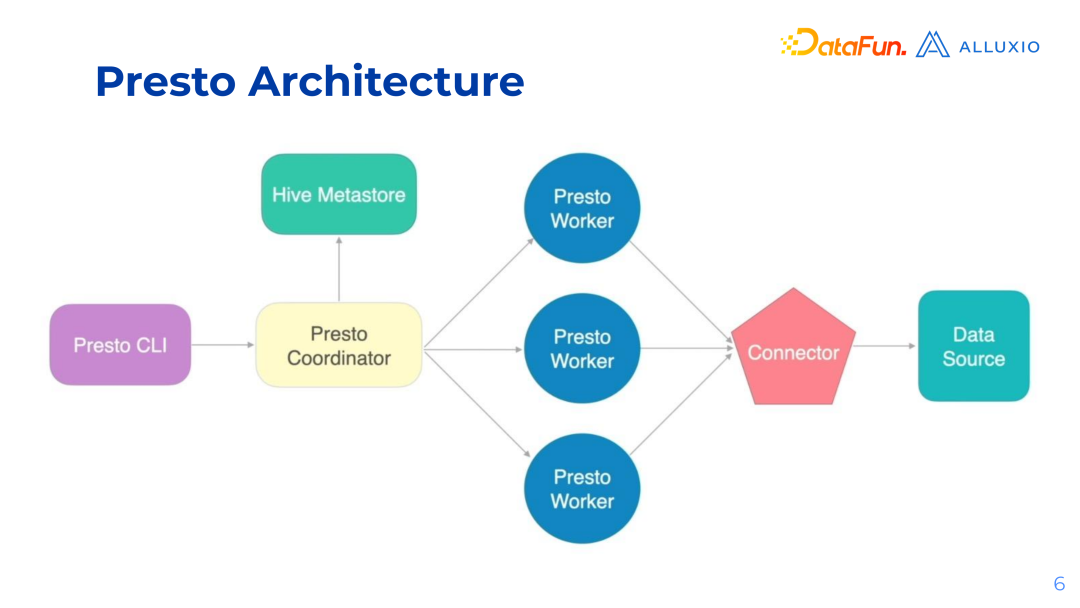
1. Presto Overview





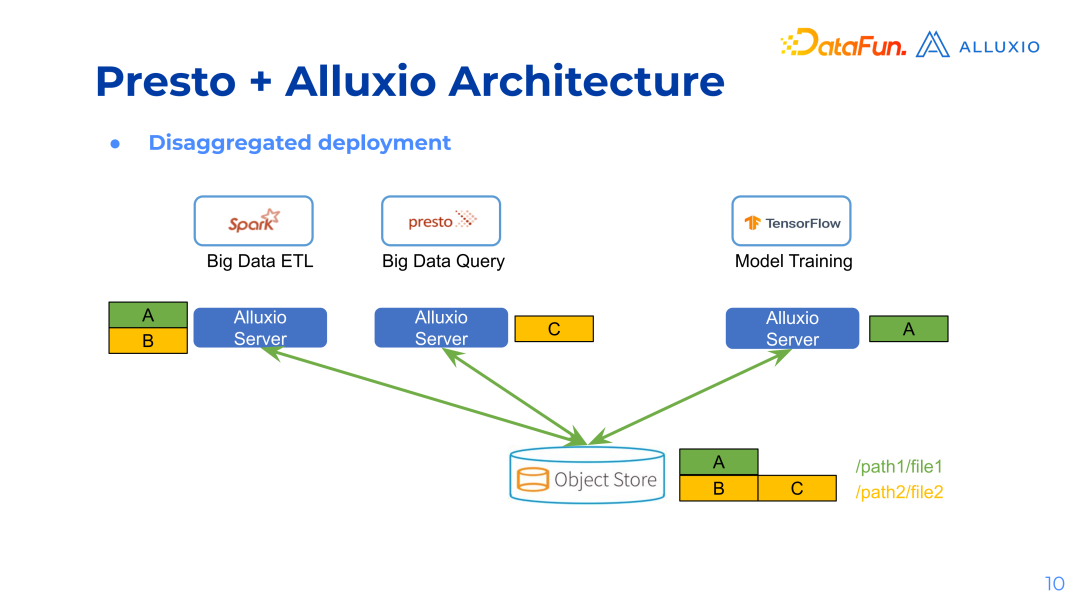


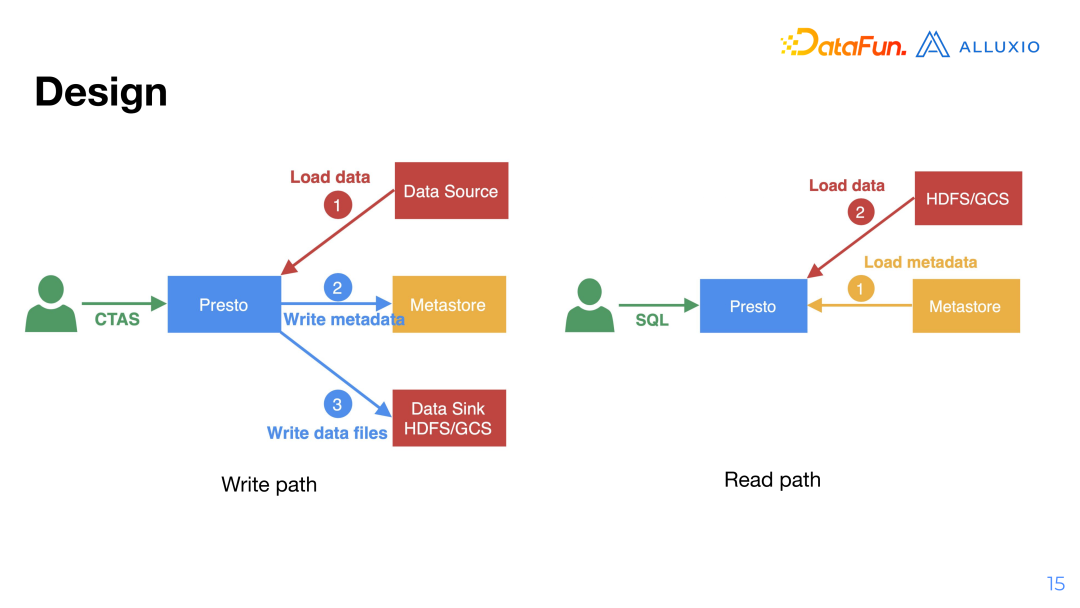
Architecture 方案
-
方案一:
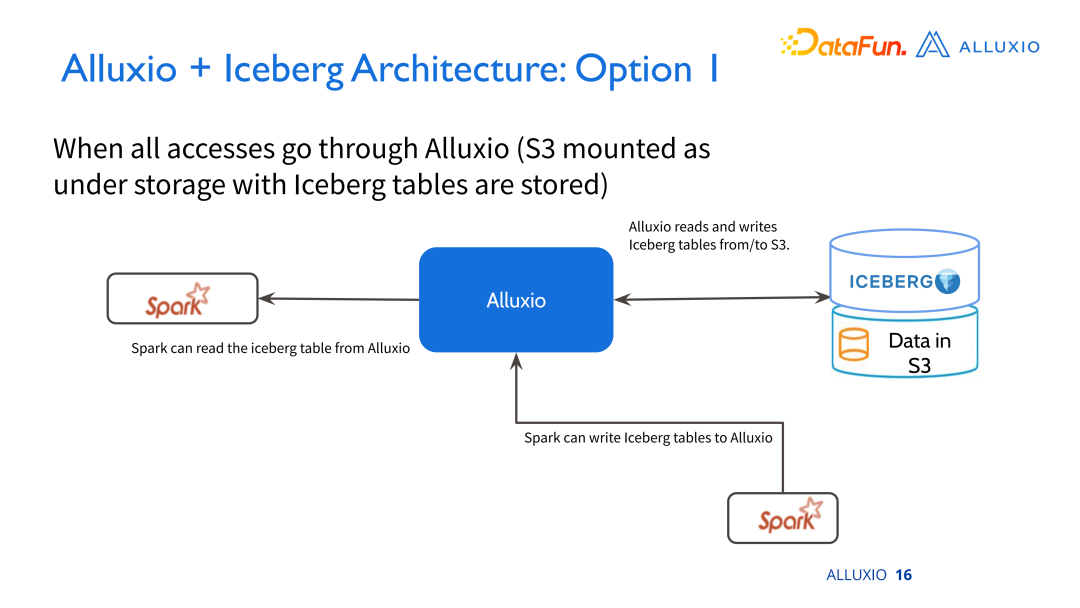
-
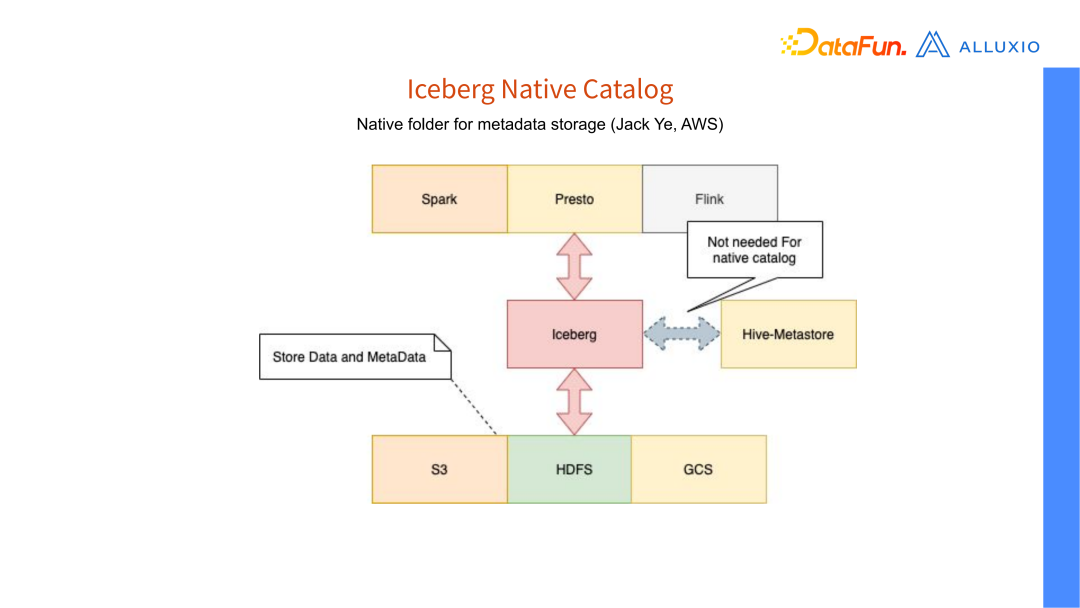
方案二:

connector 做 Local Cache,很容易就可以给 Iceberg connector 也来打开这个 Local Cache。相当于是 cache 了 parquet 的文件到 local 的 SSD 上,Prestoworker,worker 上的 SSD 其实本来是闲置的,通过它来缓存数据效果还是挺好的。它可以提速,但我们目前还没有特别好的官方 benchmark。
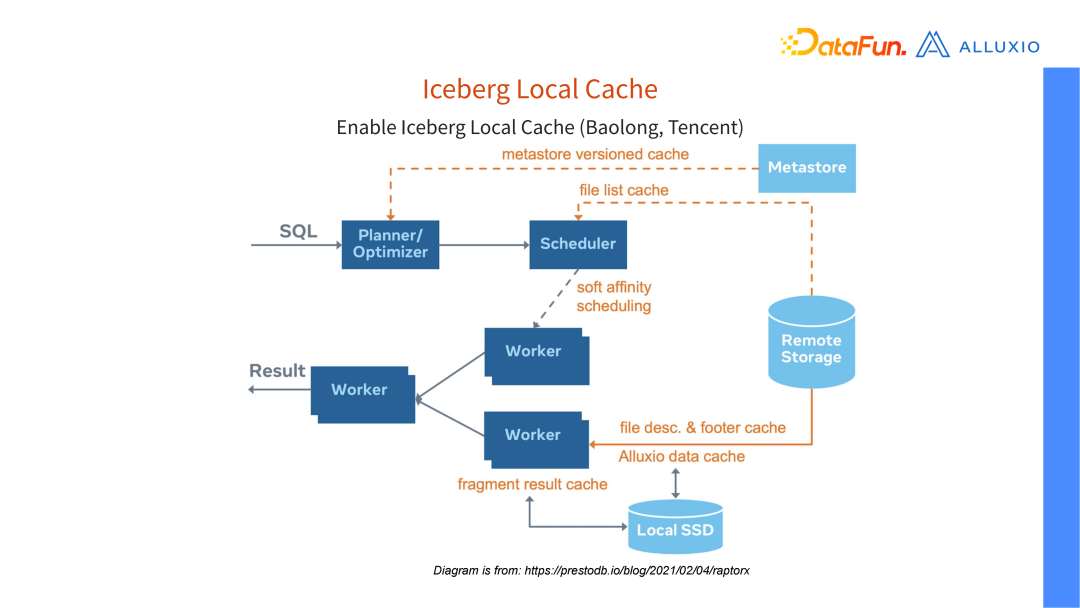
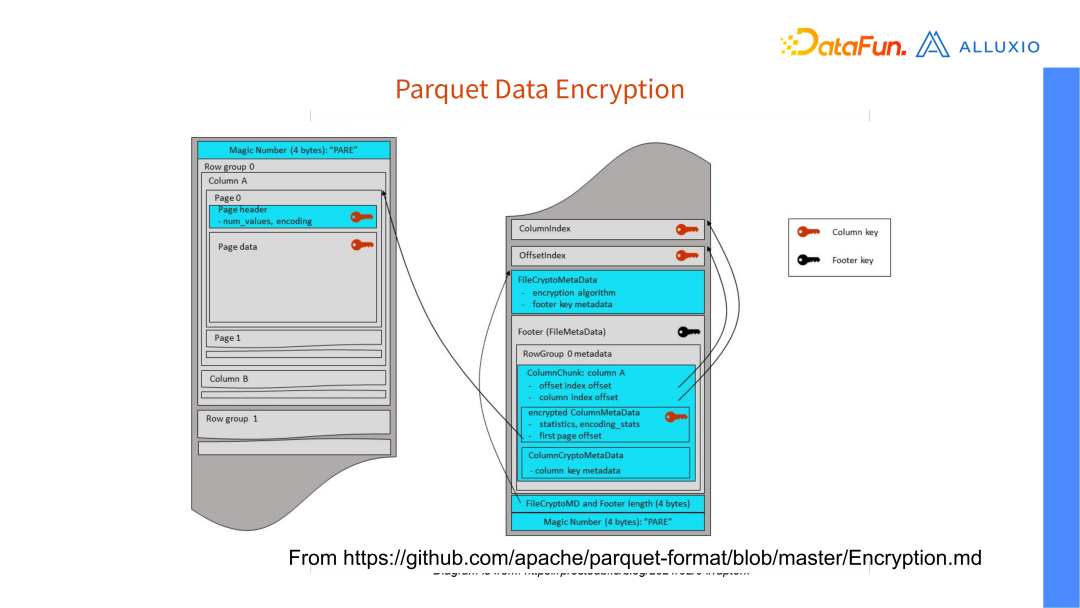
1 就代表第一个版本,现在增加了一个 magic number 即 pare 加密的版本,这个加密版本把一些加密的信和 metadata 存在 footer 里边,它可以选择对一些 column 和配置进行加密。加密好后,数据便不再是明文的了,如果没有对应的 key,就无法读取出数据。
cache 就可以满足数据加密的要求了。
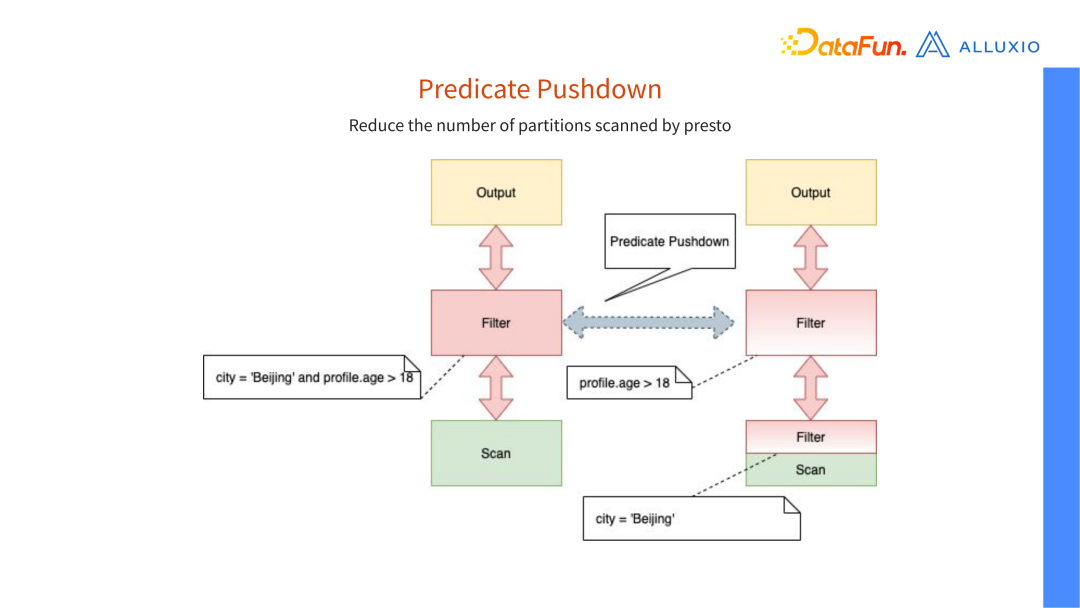
time 是 62 毫秒。谓词下推后,扫到了一条记录,查询时间极大的缩短,这也是对缓存的一个优化。开谓词下推(Predicate
Pushdown)功能后,我们发现,缓存层次够用,扫的文件少了很多,这意味着我们都可以缓存的下了,命中率有一个提高。

未来的工作

heap 的方式,将数据存在 heap 之外。此时不能 cache object 本身,需要 cache Arrow 或者 flat
buffer 格式,这两种格式反序列成本极低,又是二进制的流存在内存中,通过 off heap 把它装进来,然后在 Java 中再反序列化,这样可以达到一个很好的提速效果。
pushdown 一样,有些计算 push 到存储,存储返回来的结果特别少,它帮你计算,而且格式更好,它是 Arrow 并可以有 native 的实现,也可以向量化的计算。
heap 的缓存,可以把这个 Arrow 缓存到 off heap 上,然后在那里边需要的时候把它拿出来。然后反序列化成 page,然后给 Presto 进行进一步的计算。这个开发正在进行,可能在将来会给大家展现一部分的工作。其实就是为了降低 CPU 的使用和系统的延时,降低 GC 的开销,让系统变得更加的稳定。


分享嘉宾
INTRODUCTION

王北南 博士
Alluxio
Alluxio软件工程师
王北南 Alluxio工程师,毕业于复旦大学,获美国Syracuse 大学计算机工程博士学位。Prestodb 开源社区 Committer,Presto iceberg/druid/parquet 等模块的主要维护者。曾任 Twitter Presto/Hive team 的 Tech Lead,负责大规模分布式 SQL 的研发与维护,期间团队的上云相关工作获得 IC2E’21 最佳论文。目前负责 Alluxio 存储和本地缓存,是 Alluxio 的核心维护者之一。
本文转载自王北南 博士 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/p2ZiglnDvaQDv-5NbfhToQ。