
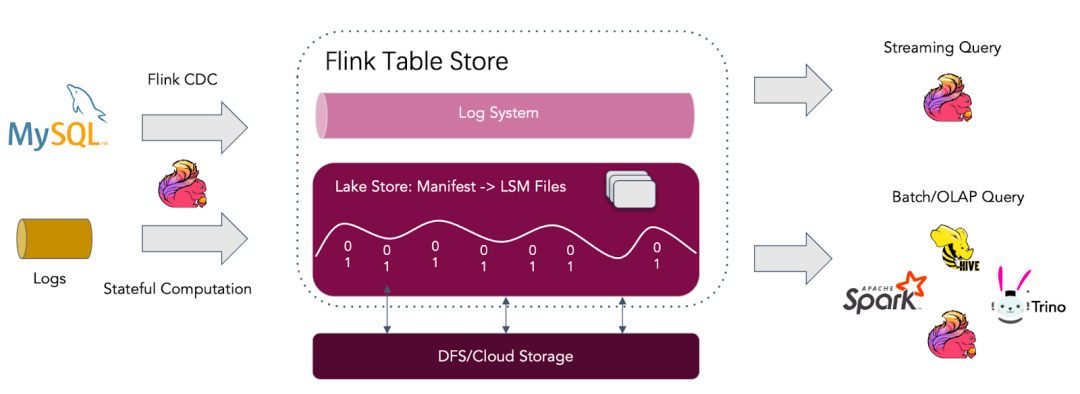
Flink Table Store 是什么
Flink Table Store是一个数据湖存储,用于实时流式 Changelog 摄取 (比如来自 Flink CDC 的数据) 和高性能查询。

-
大吞吐量的更新数据摄取,同时提供良好的查询性能。 -
具有主键过滤器的高性能查询,响应时间最快可达到百毫秒级别。 -
流式读取在 Lake Storage 上可用,Lake Storage 还可以与 Kafka 集成,以提供毫秒级流式读取。
功能
Catalog
CREATE CATALOG tablestore WITH ('type'='table-store','warehouse'='hdfs://nn:8020/warehouse/path',-- optional hive metastore'metastore'='hive','uri'='thrift://: ' );USE CATALOG tablestore;CREATE TABLE my_table ...当开启 Hive Metastore 时,你可以比较方便的使用 Hive 引擎来查询 Flink Table Store。 生态
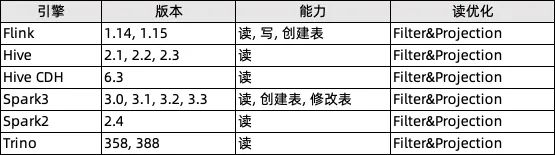
在本版本中,我们不仅支持 Flink 1.15,也支持了 Flink 1.14,并为多个计算引擎提供读取支持。 我们会保持 Flink 引擎和 Flink Table Store 的全面结合,构建完整的流批一体计算和存储的流式数仓。此外,Flink Table Store 也支持了更多的计算引擎,包括 Hive/Spark/Trino 等,从而可以兼容更多的生态,便于在现有生产环境中使用。
如果你有关于生态的需求和想法,比如想让 Spark 或 Hive 支持写入 Flink Table Store,欢迎通过扫描文末的二维码入群交流,或者在 Flink 社区创建 issue 进行讨论。
Append-only 表
Append-only 表功能是一种性能改进,只接受 INSERT_ONLY 的数据以 Append 到存储,而不是更新或删除现有数据,适用于不需要更新的用例(如日志数据同步)。
CREATE TABLE my_table (...) WITH ('write-mode' = 'append-only',...)流式写入 Append-only 表也具有异步 Compaction,从而不需要担心小文件问题。 Bucket 扩缩容
单个 Bucket 内是一个单独的 LSM 结构,Bucket 的数量会影响性能:
-
过小的 Bucket 数量会导致写入作业有瓶颈,吞吐跟不上写入速度。
-
过大的 Bucket 数量会导致有大量小文件,且影响查询速度。
性能测试
更新性能和查询性能是互相权衡的,所以在性能测试中不能单独衡量更新性能或者查询性能。
-
如果只考虑查询性能,那么 Copy On Write (COW) 是最适合的技术方案,但这种设计下更新时会覆写所有数据,因此是以牺牲更新性能为代价的。
-
如果只考虑更新性能,那么 Merge On Read (MOR) 是最适合的技术方案,但这种设计下会在读取时对数据进行合并,从而影响查询的性能。 -
Flink Table Store 目前只支持 MOR 模式,但通过 Data Skipping 等技术对查询性能做了优化。
-
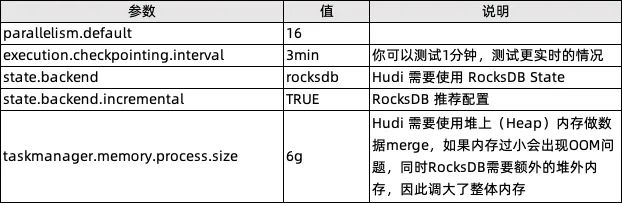
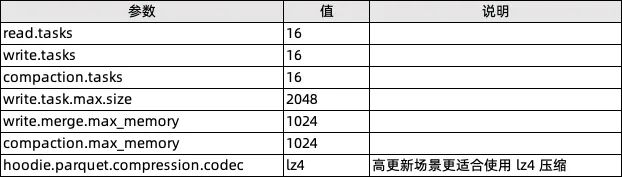
通过 Flink SQL 向定义了主键的表里写入定量的随机数据,测量耗时以及平均的 Cpu 消耗,以此衡量存储的更新性能。 -
通过 Spark SQL 查询写好数据的表,测量三种 Query:查询全部数据、查询主键的某个范围、点查某个主键,以此衡量存储的查询性能。
测试用例:
-
总量:数据总条数 5 亿条。
-
主键:随机的数据,随机范围是 1 亿。 -
大小:每条数据大概 150 字节。
-
Flink 版本: 1.14.5 -
Spark 版本:3.2.2 -
Flink Table Store 版本: 0.2.0 -
Hudi 版本:0.11.1 -
集群:三台物理机的 Hadoop 集群



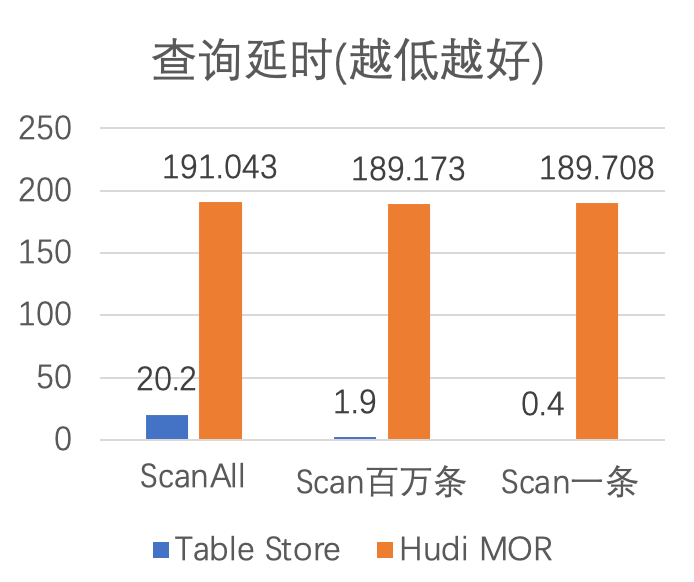
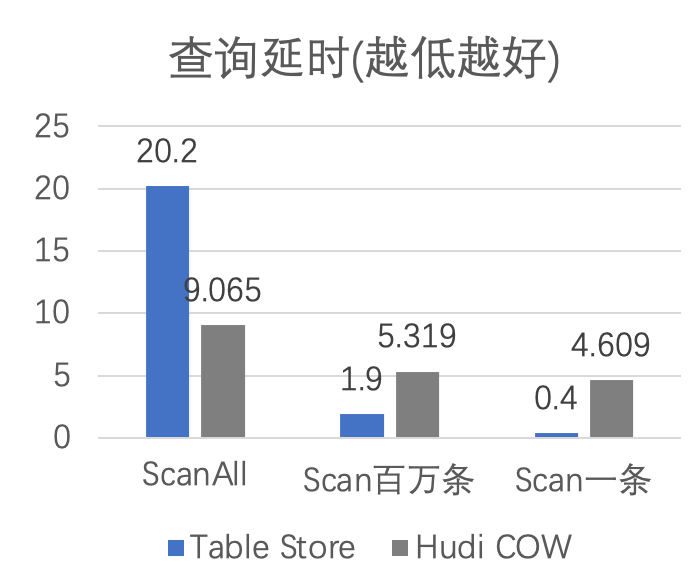
结论,面向此测试用例:
-
Flink Table Store 对比 Merge On Read 有着比较好的更新性能和查询性能。
-
Flink Table Store 对比 Copy On Write 有着比较好的更新性能,但是查询所有数据不如 COW,Flink Table Store 是一个 Merge On Read 的技术,有 Merge 的开销,但是 Merge 的效率非常高。 -
Flink Table Store 因为保持了有序性,直接查询表可以有很好的 Data Skipping,点查甚至可以达到 100ms 以内的延迟。
下一步
-
Lookup:支持 Flink Dim Lookup Join。(即将来临) -
并发更新:多个 Flink 作业写入同一张 Flink Table Store 表。 -
Compaction分离:单独的任务完成Compaction。
-
物化视图:Flink Table Store 提供预聚合模型。
-
变更日志生成:为各种 MergeEngine 生成准确的变更日志。
-
多引擎的写支持:支持 Spark、Hive 写入 Flink Table Store。
Flink Table Store 长期目标是满足批流一体对存储的所有要求,并构建实时低成本的 Streaming Data Warehouse。
交流
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/10205/