
导读:
本文主要介绍网易数帆NDH在Impala上实现的虚拟数仓特性,包括资源分组、水平扩展、混合分组和分时复用等功能,可以灵活配置集群资源、均衡节点负载、提高查询并发,并充分利用节点资源。
接着上一篇。对于高性能分析型数仓,除了需要有优秀的执行引擎能够让查询尽快完成外,还需避免因为查询间的相互干扰导致查询性能下降的问题,比如对计算和IO资源的竞争等。上节提到Impala可以通过资源池来进行计算资源的管理。但在使用时发现光有资源池还不够,仍然会出现不同的资源池竞争同一个计算节点上内存资源等问题。
基本概念
“虚拟数仓”来源于Snowflake的“virtual warehouse”,简称VW。虚拟数仓能够按需进行水平和垂直扩缩容,是一种高效的资源调度方法,是存算分离设计架构下,计算资源弹性伸缩非常好的验证案例。如下图所示,该Snowflake集群有两个虚拟数仓,分别服务于BI和ETL用户。其中BI虚拟数仓为了应对报表查询的高低峰,采用了单元化的水平扩缩容模式,ETL主要关注计算能力,采用了改变虚拟数仓规格的模式。


NDH的Impala组件也具备类似的能力,在开始之前,先结合Impala的实际来介绍两个基本概念,首先是社区版Impala已有的executor group(执行组)。然后是为支持虚拟数仓而引入的node group(节点组)概念。
Executor group
下图是CDP文档中关于Impala执行组的示意图,执行组是Impala进行弹性伸缩的基本单位,用户可以配置执行组规格(XSMALL, SMALL, MEDIUM, or LARGE)。若启用自动伸缩,则CDP每次会按指定的规格扩展或缩小Impala的executor节点个数。
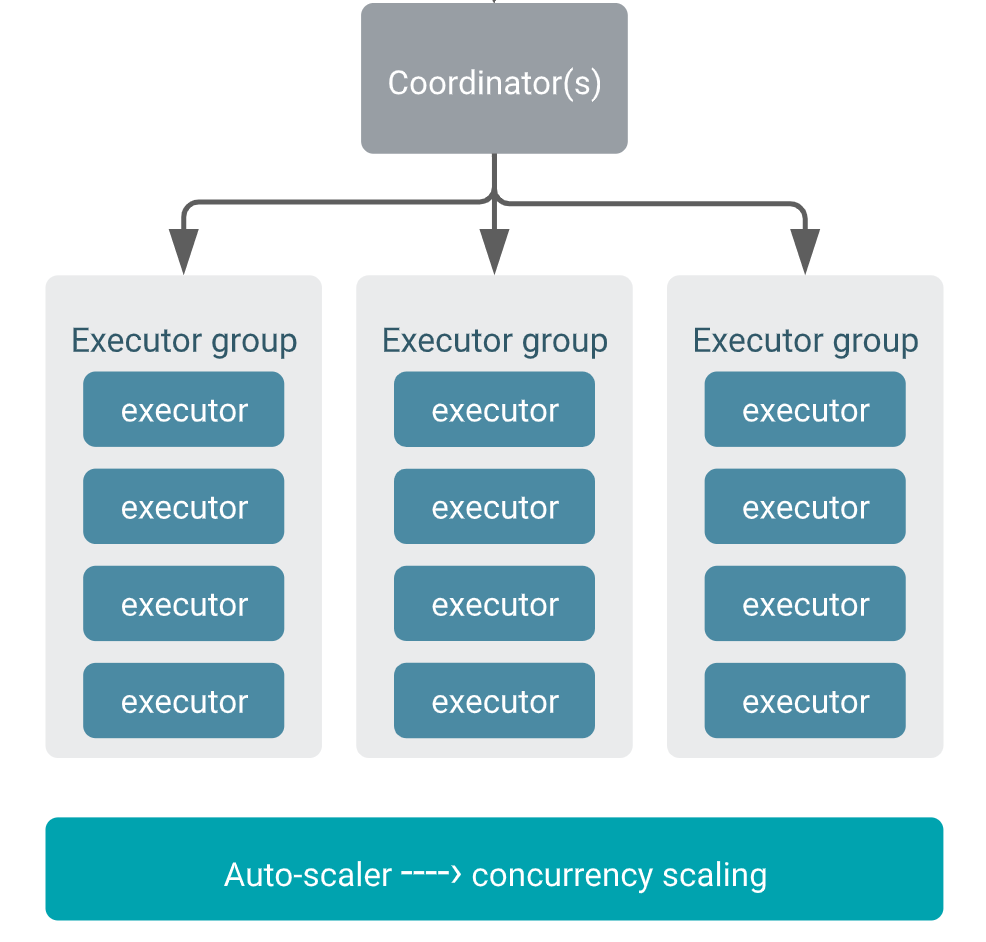
执行组为Impala集群提供了水平扩缩容的能力。但与Snowflake所述的虚拟数仓还是有不小的区别,从目前的介绍看,执行组是对用户透明的概念,用户无法通过执行组将Impala集群划分为不同用途的计算单元,如前述的用于BI和ETL。因此,NDH Impala引入了node group(节点组)的概念。
Node group
NDH Impala集群的impalad节点可以被划分成多个独立分组,我们称之为节点组。节点组可以仅有executor组成,也可以有coordinator节点。

上图Impala集群包含3个节点组,每个节点组的impalad中必须至少有一个executor节点。此外还有2个coordinator节点独立于节点组之外。独立的coordinator节点可以将请求路由到任一节点组中的executor,节点组中的coordinator只能将请求分发给本分组内的executor节点执行。根据查询路由规则的差异,有两种虚拟数仓实现方式。
实现方式
NDH Impala支持两个虚拟数仓实现,分别是基于zookeeper地址的静态配置方案和基于会话(session)参数的动态配置方案,下面分别展开介绍。
2.1 静态配置
该方案将不同节点组的coordinator节点注册到不同的zookeeper地址上,Hive JDBC客户端连接不同的zookeeper地址即可获取到不同业务组的coordinator,从而进行连接并下发SQL请求。此种方式中每个节点组都会拥有自己独有的一到多个coordinator节点,负责将SQL生成的执行计划下发给组内的executor节点执行。

上图所示集群有3个虚拟数仓:group 1,group 2和group 3。它们共用相同的statestored和catalogd,共用同一份数仓元数据。虚拟数仓间的impalad资源是物理隔离的,某个虚拟数仓的coordinator节点只会将查询下发到组内的executor节点。在生产环境中,可通过配置多个虚拟数仓来接收不同类型业务的查询请求,以便不同业务的查询在计算资源的使用上互相隔离,互不影响,图中group 1用于进行ad-hoc查询,group 2用于有数BI报表,group 3用于有数BI自助取数。相比多集群方式,多虚拟数仓的方式所需要资源更少,配置更灵活。
2.2 动态路由
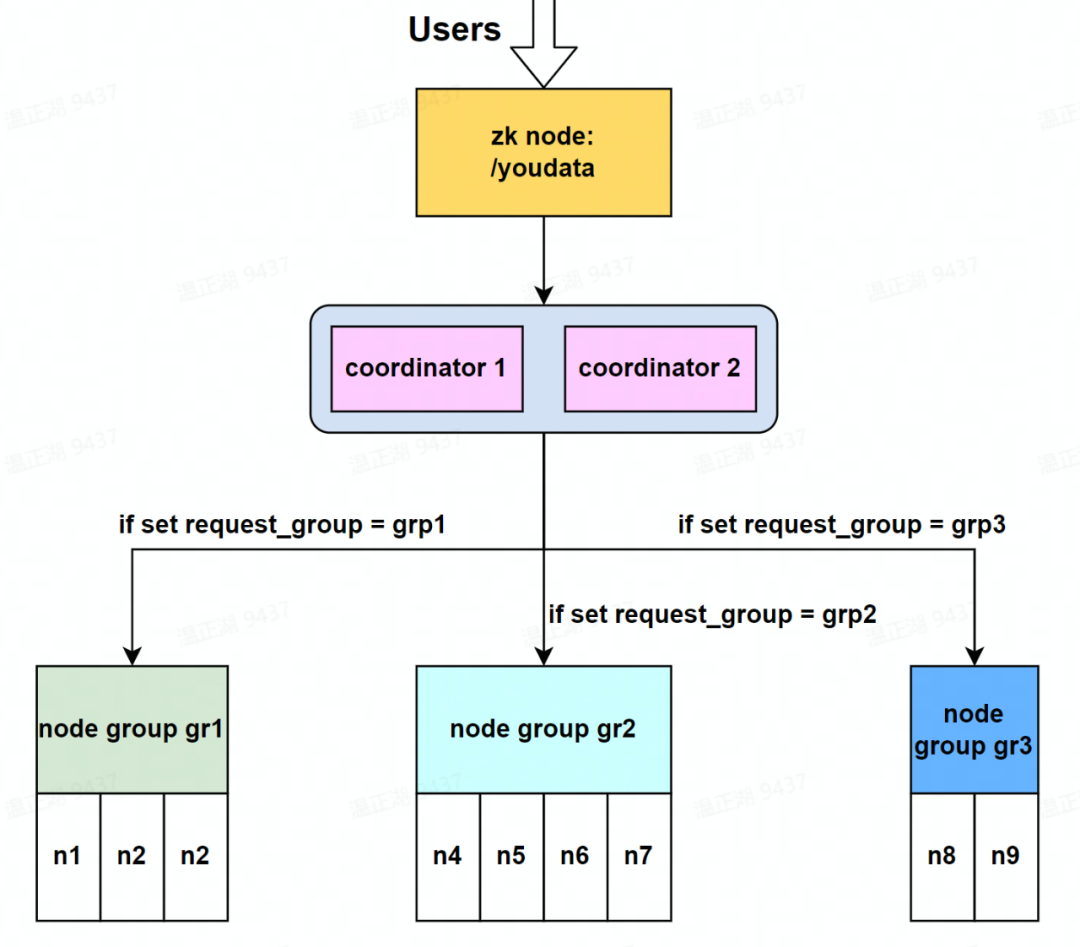
本方案在会话连接中增加一个query option参数request_group,通过set request_group=xxx语句,coordinator会自动将查询路由到指定分组上执行。request_group默认为default,对应group_name的默认值也为default。换言之,若不指定request_group,那么查询会下发到默认的default分组执行。
在本方案中coordinator节点是公共的,仅对executor节点进行分组,在实现上更类似Snowflake的虚拟数仓。如下图所示,有2个公共的coordinator,3个分组,由于不存在default分组,可将默认分组配置为grp1。可以通过参数动态配置,相比基于zookeeper的方案更加灵活,用户能够根据需要自由地将查询在不同的虚拟数仓上切换。
上述两种方案均已实现,由于NDH的生产环境一般通过Hive JDBC连接zookeeper来访问Impala,前者的使用方法兼容性更好,目前线上主要使用以该方式部署虚拟数仓。本小节接下来介绍的虚拟数仓进阶特性也主要围绕前者展开。
主要特性
3.1 水平扩展
若虚拟数仓的单个节点组资源和并发数已经达到瓶颈,单纯在组内增加节点无法有效提升查询并发数,此时可以新增一个规格相同或相近的节点组加入该虚拟数仓中,需将新节点组中coordinator的zookeeper地址配置成与原节点组相同。借助Hive JDBC在选择zookeeper下coordinator地址时的随机性特点,可将查询负载均衡到新旧节点组上。这种方式可以接近线性地提升集群的查询并发数。

上图所示Impala集群有2个虚拟数仓,对应的节点组分别为group1和group3,承接的业务分别是业务的有数BI报表和ABTest场景。假设group1为原分组,有3个impalad节点(1个coordinator,2个executor)。新增分组group2,也是3个impalad节点,使用与group1相同的配置,即可起到水平扩展的效果。
3.2 透明伸缩
NDH Impala可根据各虚拟数仓的负载情况,在线增加或减少虚拟数仓节点组中的impalad节点数,从而实现分组间的资源动态伸缩。通过Impala提供的graceful shutdown方式下线节点组中impalad进程时,会先禁止新的查询请求发送到该impalad节点上,并等待其上正在执行的查询片段(fragment)完成后再关闭。因此不会导致其上正在执行的查询异常终止,做到对用户无感。在生产环境中,配置了多个虚拟数仓的NDH Impala集群,可通过分析历史查询规律并结合分组中impalad节点的系统负载情况,在虚拟数仓间动态增减节点数,以求更充分得利用各节点资源。

举网易云音乐为例,有数BI自助取数(easyfetch)的查询一般发生在工作时间,有数BI报表需要在用户上班前进行大量报表结果预加载操作(提前下发报表查询SQL并缓存查询结果从而提升报表查看体验)。我们可将easyfetch和BI报表两种场景配置为同一个NDH Impala集群的两个虚拟数仓,在上班前,将easyfetch虚拟数仓的大部分impalad节点挪到BI报表虚拟数仓上,这样可以大大提高报表的预加载效率。
当然,透明伸缩不仅仅适用在虚拟数仓之间。对于云上环境,通过k8s或类似调度机制,在负载高峰时可以便捷地申请容器或虚拟机资源,快速补充到线上。待高峰过后,再将所增加的资源释放给云厂商。
进阶功能
相比Impala资源队列,虚拟数仓的节点组中coordinator节点绝对不会使用到其他组的计算资源(executor),资源隔离更加彻底,使得不同业务模块的查询性能不会相互影响。但不同虚拟数仓所属的业务会存在负载差异,可能导致资源利用不充分。为了提高空闲节点组的资源利用率,对虚拟数仓特性做了进一步增强,引入混合分组、分时复用等功能。
4.1 混合分组
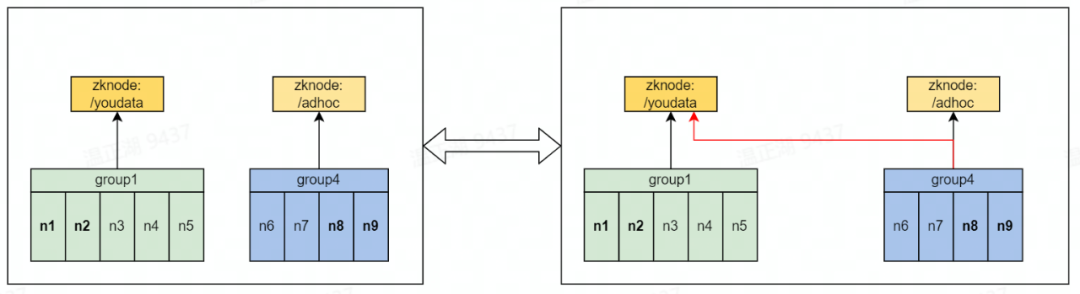
混合分组就是让一个executor节点同时在2个或以上的节点组中,如下图所示。左子图为普通模式,假设NDH Impala集群分为有数BI报表和Ad-Hoc查询2个虚拟数仓,Ad-Hoc查询有明显的时间性,查询集中在工作时间,且查询的并发度较低。通过混合分组,可将虚拟数仓部署方式改造为右子图的模式。

图中,n1~n2为group1节点组coordinator节点,其会注册到zookeeper路径youdata上,Hive JDBC客户端从该路径获取任意coordinator节点向其提交查询,coordinator将查询进行解析,优化并指定分布式执行计划,最终下发给n3~n7执行。n6~n7同时还是group4的executor节点,group4的coordinator为n8~n9,其会接收从zookeeper路径Ad-Hoc进入的查询,指定分布式执行计划,并会发送到n6~n8上。
4.2 分时复用
分时复用是另一个能够提高资源利用率的进阶功能。通过在特定的时间段自动配置集群的分组资源,缓解某些高负载分组的查询压力,提升用户体验。
在实现上,支持将同一个coordinator注册到多个zookeeper地址下,且可以配置注册到每个地址的有效时间,如上图所示,可以每天晚上八点到早上八点将Ad-Hoc虚拟数仓的n8和n9两个coordinator(或其中一个)注册到BI报表虚拟数仓相同的zookeeper地址下,分摊BI报表的查询负载。
与混合分组相比,分时复用功能仅适合在规格相似的节点组之间使用,确保不同分组上的查询性能没有明显的差距。
4.3 基于负载的节点选择
executor节点会出现多种原因导致计算资源使用不均衡的问题,比如数据倾斜导致某些executor节点需要消耗更多计算资源扫描和处理数据,或引入混合分组特性导致某些节点组上节点负载过高等等。
针对该问题,NDH Impala进行了两个优化。第一个是支持基于executor节点负载的查询分布式执行,实现方法为在为查询SQL确定分布式执行计划时,考虑executor节点当前可用的计算资源情况,剔除可用资源较少的executor节点;第二个是存在多队列时,限制同个队列上的查询请求在一个executor上的资源使用总量,避免executor资源被某个队列独占。
小结
本小节主要介绍了虚拟数仓概念的来源和实现,重点分析了NDH Impala在虚拟数仓这块的探索、思考和使用。目前虚拟数仓在网易互联网业务以及网易数帆的商业化客户集群上均有成功的应用案例。
笔者认为,虚拟数仓应该是新一代分析性数仓必备的一个能力,它能够剥离复杂多样的业务负载,充分发挥执行引擎自身的能力。最后需要指出的是,虚拟数仓是一种云原生的特性,计算资源能够灵活伸缩的环境能够最大化其价值。
荣廷,网易数帆数据库技术专家,10年+数据库相关工作经验,目前主要负责高性能数仓和云原生数据库研发工作。
本文转载自 荣廷 网易有数,原文链接:https://mp.weixin.qq.com/s/WaBPnA9IcFZGhmt4q_yXvg。