
概览
在本节中,我们将解释 解释器(Interpreter)、解释器组和解释器设置在 Zeppelin 中的作用。 Zeppelin 解释器的概念允许将任何语言或数据处理后端插入 Zeppelin。 目前,Zeppelin 支持 Scala、Python、Flink、Spark SQL、Hive、JDBC、Markdown、Shell 等多种解释器。
请注意,下文Interpreter与解释器混用。
什么是Zeppelin Interpreters
Zeppelin Interpreters是一个插件,它使 Zeppelin 用户能够使用特定的语言/数据处理后端。 例如,要在 Zeppelin 中使用 Scala 代码,您将使用 %flink解释器等。
当您单击解释器页面上的 +Create 按钮时,解释器下拉列表框将显示您服务器上所有可用的解释器。
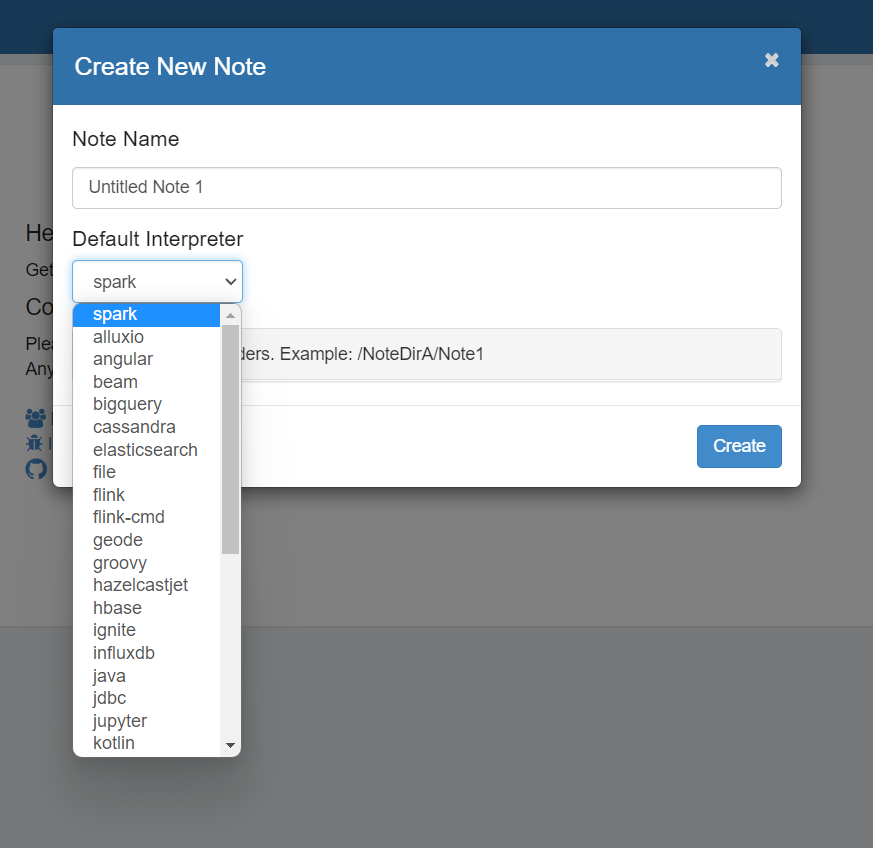

对于您在 Zeppelin 中编写的每个段落,您需要首先通过 %interpreter_group.interpreter_name 指定其解释器。 例如 %flink、%flink.ssql等。
如果您指定解释器,您还可以将本地属性传递给它(如果需要的话)。 这是通过在解释器名称后面的圆括号内提供一组键/值对来完成的,用逗号分隔。 如果键或值包含诸如 =、或 , 之类的字符,则您可以使用 字符对它们进行转义,或者将整个值括在双引号内 例如:
%cassandra(outputFormat=cql, dateFormat="E, d MMM yy", timeFormat=E, d MMM yy)Zeppelin解释器设置
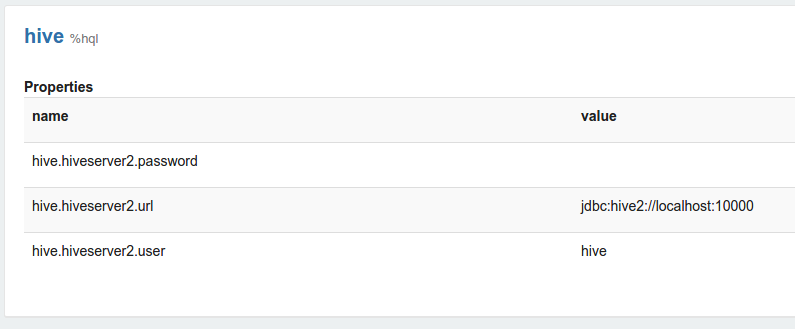
解释器设置是 Zeppelin 服务器上给定解释器的配置。 例如,需要为 Apache Hive JDBC 解释器设置某些属性才能连接到 Hive 服务器。
如果属性名称由大写字符、数字或下划线 ([A-Z_0-9]) 组成,则属性将作为系统环境变量导出。 否则,该属性将设置为通用解释器属性。 例如 您可以在 spark 的解释器设置中定义 SPARK_HOME 和 HADOOP_CONF_DIR,它们将作为 Spark 使用的环境变量传递给 Spark 解释器进程。
您可以通过在解释器属性值中添加 #{contextParameterName} 来使用来自解释器上下文的参数。 参数可以是以下类型:字符串、数字、布尔值。
Context Parameters
| Name | Type |
|---|---|
| user | string |
| noteId | string |
| replName | string |
| className | string |
如果上下文参数为空,则将其替换为空字符串。 下面的截图是我们将用户名作为 default.user 的属性值的一个例子。

什么是Interpreter Groups
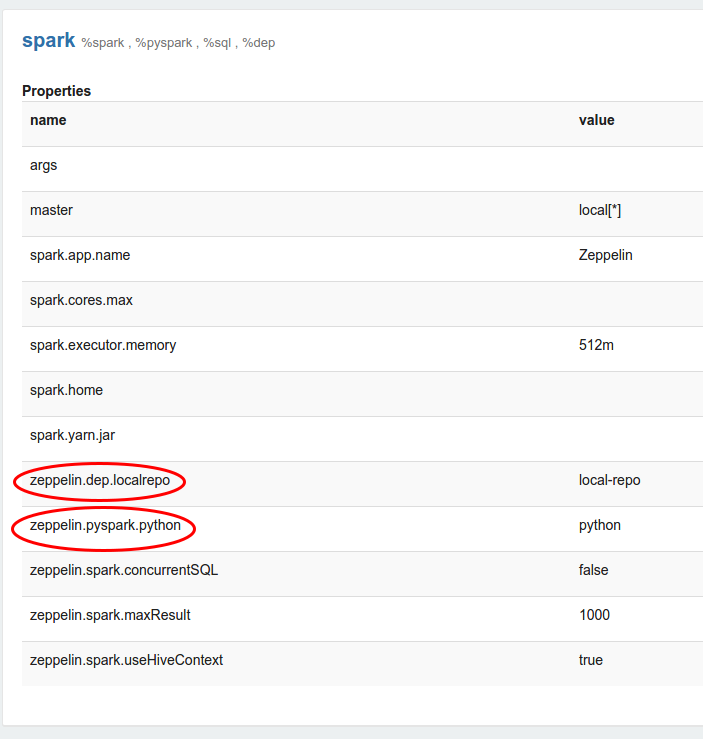
每个解释器都属于一个解释器组。 解释器组是在单个 JVM 进程中运行的解释器单元,可以一起启动/停止。 默认情况下,每个解释器都属于一个单独的组,但该组可能包含更多解释器。 例如,Spark 解释器组包括 Scala Spark、PySpark、IPySpark、SparkR 和 Spark SQL。
从技术上讲,来自同一组的 Zeppelin 解释器在同一个 JVM 中运行。 有关这方面的更多信息,请参阅有关编写解释器的文档。
每个解释器属于一个组并一起注册。 所有相关属性都列在解释器设置中,如下例所示。
Interpreter绑定模式
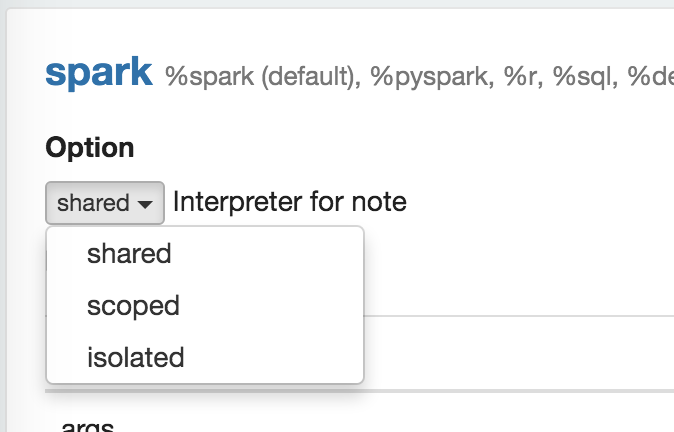
在解释器设置中,可以选择共享、作用域或隔离的解释器绑定模式之一。 在共享模式下,使用此解释器的每个笔记/用户将共享一个解释器实例。 范围和隔离模式可以在 2 个维度下使用:每个用户或每个注释。 例如 在 note范围模式下,每个note将在同一个解释器进程中创建一个新的解释器实例。 在每个note隔离模式下,每个note都会创建一个新的解释器进程。
Interpreter生命周期管理
在 0.8.0 之前,Zeppelin 没有解释器的生命周期管理。 用户必须通过 UI 显式关闭解释器。 从 0.8.0 开始,Zeppelin 提供了一个新的接口 LifecycleManager 来控制解释器的生命周期。 目前,有两种实现:NullLifecycleManager 和 TimeoutLifecycleManager。
NullLifecycleManager 不会做任何事情,即用户需要像以前一样自己控制解释器的生命周期。 TimeoutLifecycleManager 将在解释器闲置一段时间后关闭解释器。 默认情况下,空闲阈值为 1 小时。 用户可以通过 zeppelin.interpreter.lifecyclemanager.timeout.threshold 设置更改此阈值。 NullLifecycleManager 是默认的生命周期管理器,用户可以通过 zeppelin.interpreter.lifecyclemanager.class 更改它。
内联配置
Zeppelin 的解释器设置是所有用户和笔记共享的,如果你想有不同的设置,你必须创建一个新的解释器,例如 您可以创建 spark_jar1 用于运行具有依赖项 jar1 的 Spark 和 spark_jar2 用于运行具有依赖项 jar2 的 Spark。 这种方法有效,但不方便。 内联通用配置可以对解释器设置提供更细粒度的控制和更大的灵活性。
ConfInterpreter 是一个通用的解释器,可以被任何解释器使用。 您可以像定义 java 属性文件一样使用它。 它可用于为任何解释器进行自定义设置。 但是,ConfInterpreter 需要在该解释器进程启动之前运行。 该解释器进程何时启动由解释器绑定模式设置决定。 所以用户需要了解 Zeppelin 的解释器绑定模式设置,并注意解释器进程何时启动。 例如,如果我们将 Spark 解释器设置为每个note隔离,那么在此设置下,每个note将启动一个解释器进程。 在这种情况下,用户需要将 ConfInterpreter 作为第一段,如下例所示。 否则无法应用自定义设置(实际上会报错)。

预编码
解释器初始化后执行的代码片段(解释器的语言)取决于绑定模式。 要配置,请添加一个带有解释器类(zeppelin.<ClassName>.precode)的参数,JDBCInterpreter(JDBC 预编码)除外。

凭据注入
来自凭证管理器的凭证可以被注入到 Notebooks 中。 凭据注入的工作原理是将 Notebooks 中的以下模式替换为凭据管理器的匹配凭据:{CREDENTIAL_ENTITY.user} 和 {CREDENTIAL_ENTITY.password}。 但是,必须通过在解释器配置中添加布尔值 injectCredentials 设置来为每个解释器启用凭据注入。 从 Notebook 输出中删除了注入的密码,以防止意外泄露密码。


凭据注入示例
val password = "{SOME_CREDENTIAL_ENTITY.password}"
val username = "{SOME_CREDENTIAL_ENTITY.user}"Interpreter进程恢复(Experimental)
在 0.8.0 之前,关闭 Zeppelin 也意味着关闭所有正在运行的解释器进程。通常,管理员会关闭 Zeppelin 服务器进行维护或升级,但不想关闭正在运行的解释器进程。在这种情况下,解释器进程恢复是必要的。从 0.8.0 开始,用户可以通过将 zeppelin.recovery.storage.class 设置为 org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage 或将来可用的其他实现来启用解释器进程恢复。默认情况下它是 org.apache.zeppelin.interpreter.recovery.NullRecoveryStorage,这意味着没有启用恢复。 zeppelin.recovery.dir 用于指定存储恢复元数据的位置。启用恢复意味着关闭 Zeppelin 不会终止解释器进程,并且当 Zeppelin 重新启动时,它会尝试重新连接到现有运行的解释器进程。如果您想在终止 Zeppelin 后终止所有解释器进程,即使启用了恢复,您可以运行 bin/stop-interpreter.sh。
在 0.8.x 中,Zeppelin 服务器只会在您再次运行段落时重新连接到正在运行的解释器进程,但不会恢复正在运行的段落。 例如。 如果您在某个段落仍在运行时重新启动 zeppelin 服务器,那么当您重新启动 Zeppelin 时,尽管解释器进程仍在运行,您将看不到该段落正在前端运行。 在 0.9.x 中,我们通过恢复正在运行的段落来修复它。 这是一个运行的 flink 解释器段落如何工作的屏幕截图。

Interpreters选择
默认情况下,Zeppelin 将注册并显示文件夹 $ZEPPELIN_HOME/interpreters 下的所有解释器。 但是您可以配置属性 zeppelin.interpreter.include 来指定要包含的解释器或 zeppelin.interpreter.exclude 来指定要排除的解释器。 只能指定其中之一,不能一起指定。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/2101/