


分享嘉宾:张佳煌 虎牙 大数据架构师
编辑整理:刘兆磊 枣庄学院
出品平台:DataFunTalk
导读:大家下午好,我叫张佳煌,来自于虎牙大数据平台,主要负责大数据的存储和计算。虎牙公司作为国内知名的直播平台,在直播游戏化技术、虚实融合、虚实互动内容生产领域持续创新,这也得益于离在线混部计算资源的支持。
今天给大家分享的是大规模离在线混部在虎牙的落地实践,主要分为几个部分:
-
背景
-
架构以及落地效果
-
关键技术实现
-
未来展望
01
背景
1. 资源侧存在的问题
① 资源利益率低

第一张图是在线业务的资源使用情况,在凌晨以及白天在线业务的资源利用率低,晚上的资源利用率慢慢提高,全天的平均利用率只有17%。离线业务大部分业务主要都集中在凌晨,所以凌晨的CPU利用率很高,全天平均利用率55%。另外是我们目前AI训练在用的GPU训练机器,这部分机器的使用时间不太可控,CPU利用率全天都比较波动,全天平均利用率15%。
以上主要是资源利用率低的一个问题。
② 资源交付不及时

除了资源利用率低的问题,当前还存在资源交付不及时的问题。
对于在线业务的场景,比如比赛场景,在比赛时间段是资源使用的一个高发期,需要大量的资源,或者某个主播需要入住虎牙,这时的流量突增需要大量资源的扩容,如果在线业务无法获得大量的资源扩容,各种故障就会频发。有比赛时会用到很多的资源,没有比赛时资源很富余,这样全天的CPU利用率会更低。
离线业务也是同样的问题,比如老板突然需要数据,或者今天的一些营收数据需要重新跑,就需要快速增加资源把数据跑出来,到周末没有adhoc查询时,就会有很多资源富余。
以上主要是资源交互的一个问题。
2. 我们的解法思路
针对资源利用率低,以及资源交互的问题,有什么解法?
-
针对资源利用率低问题,我们的解法思路是通过分时复用将资源的利用率全部填满。我们引入了多种不同的业务场景,通过时间差异的方式打平全天的资源利用率。
-
针对资源交互的问题,我们需要对现有的资源做改造,完成资源的弹性调度,并解决弹性面临的存储计算分离的问题。
在线业务与离线业务资源打平,并结合弹性资源,我们称这两种结合为离在线混部。离在线混部有一个重要的问题,就是稳定性的保障。对于离线业务小波动的影响可能不大,对于在线业务稍微有一点波动,影响面就会很广,可能会出现各种延迟,各种请求超时。
02
架构以及落地效果
针对稳定性保障问题,我们虎牙现在的整体架构是怎样的?首先看一下整体架构,以及我们针对整体架构的落地效果。
1. 容器化技术方案选择
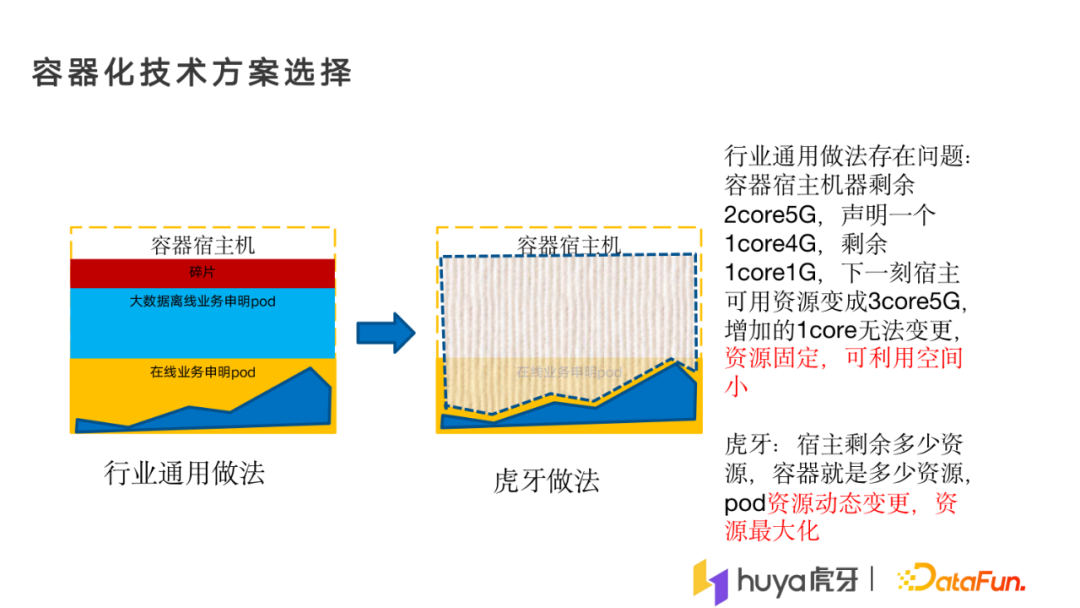
在容器方案的选型上,行业一般会采用声明式的方式,即申请多少资源,就在容器启动多少资源的pod,这种方式会存在碎片资源太多的问题,最终会同在线业务一样抢宿主机的资源,导致整体利用率不高。
虎牙的解法是,不论在线业务在容器的宿主机上用了多少资源,剩余的真实资源给离线业务用。这样可以保证离线业务时刻都能拿到最大资源而不浪费。这种做法的资源是动态变更的,要一直去保证资源的调整。
行业的选型相对固定,基本上固定可利用空间很小,因为资源申请多少就时多少,所以看一下我们在架构层面上的实现是怎样的。
2. 架构实现-资源层
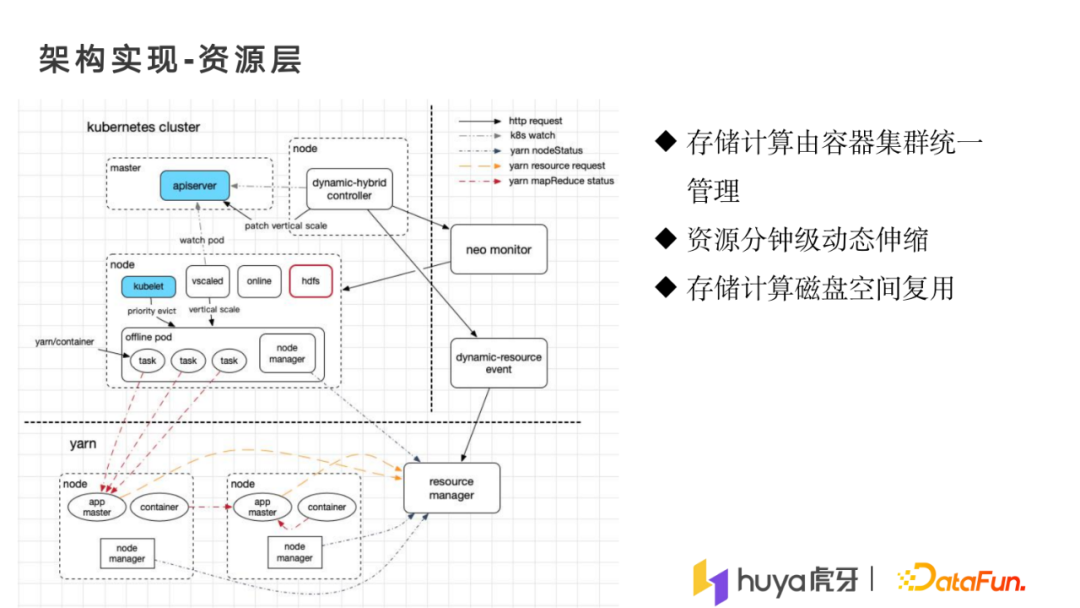
资源层上层的容器化主要由容器化团队负责,我们负责容器化后怎样使用全部资源,并把资源使用好。我们将大数据的存储与计算节点全部做了容器化,在资源层面上,容器会定时从neo秒级监控系统获取资源信息,然后将资源的可利用空间通过动态的方式返回给大数据平台,最后根据资源信息去动态地调整yarn集群资源,以保证资源的动态。
在做容器化改造时,很多老的大数据机型都没有磁盘空间,所以在资源层面上,我们将磁盘做了复用,保障了hdfs与yarn容器化之后,计算操作依然有磁盘空间使用,解决了老机型改造问题。
以上是我们在资源层面上,资源调整的实现方式。
3. 架构实现-隔离
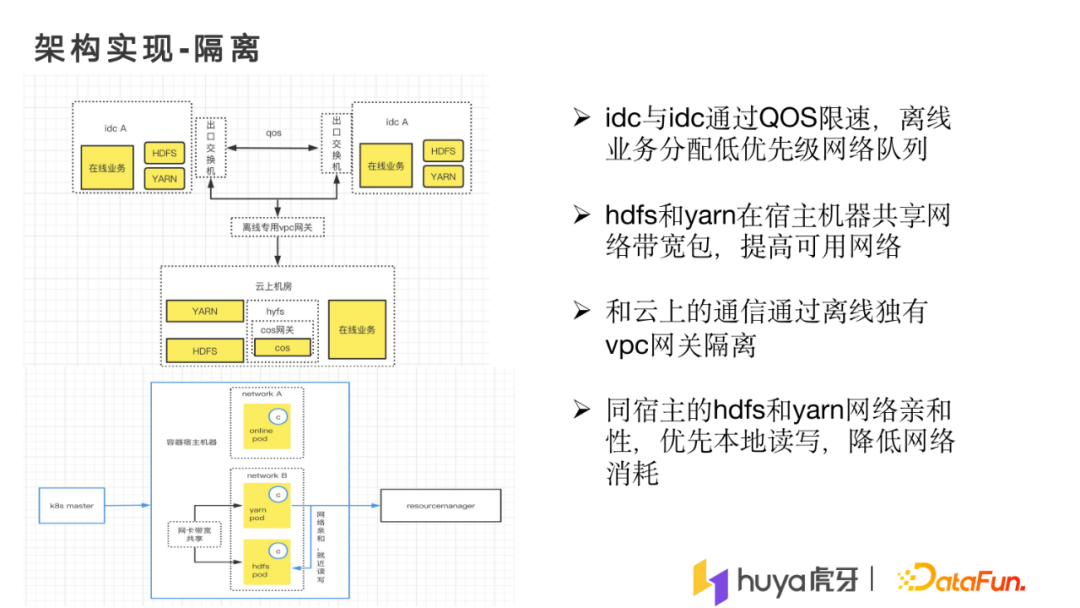
大家都知道离在线混部会面临网络的问题,而且我们为了消化多个机房的资源问题,需要架构设计能解决网络上相互影响的问题,来保证业务的稳定。
机房实现层面上,我们在机房与机房之间做了QOS限速,离线业务会放在低优先级的队列跑,如果在线业务的带宽突增,QOS就会将离线业务带宽限制下来,保障在线业务的网络稳定。
另外就是要解决多机房的问题。除了idc与idc的问题,还要解决idc与云上机房的问题。因为云上机房的交换机由云厂商控制,所以idc与云上机房通信的网络方式无法通过QOS限速。我们采用了离线专用vpc网关,让离线业务与云上资源的带宽通过vpc网关传输,这样就保障了离线业务与在线业务的隔离,使用网络时就不会发生冲突。
在hdfs与yarn容器化时,如果hdfs存储节点资源受影响,将会变成慢节点并较大的影响稳定性。我们在宿主机层面上做了网卡带宽共享,如果hdfs带宽用得少,yarn的带宽就可以用得多,相当于两者之间有一个共享带宽包,可以将最大的资源使用完。另外一个问题是容器化之后,从原有模式变成存储计算分离的模式,带宽消耗会更高。我们在hdfs与yarn的层面做了优先本地读取,也会去适配hdfs与yarn之间机架的问题以及就近问题,这样带宽消耗就不会那么高。
以上主要是我们资源层面上的架构,以及网络隔离上面的架构。
4. 落地效果
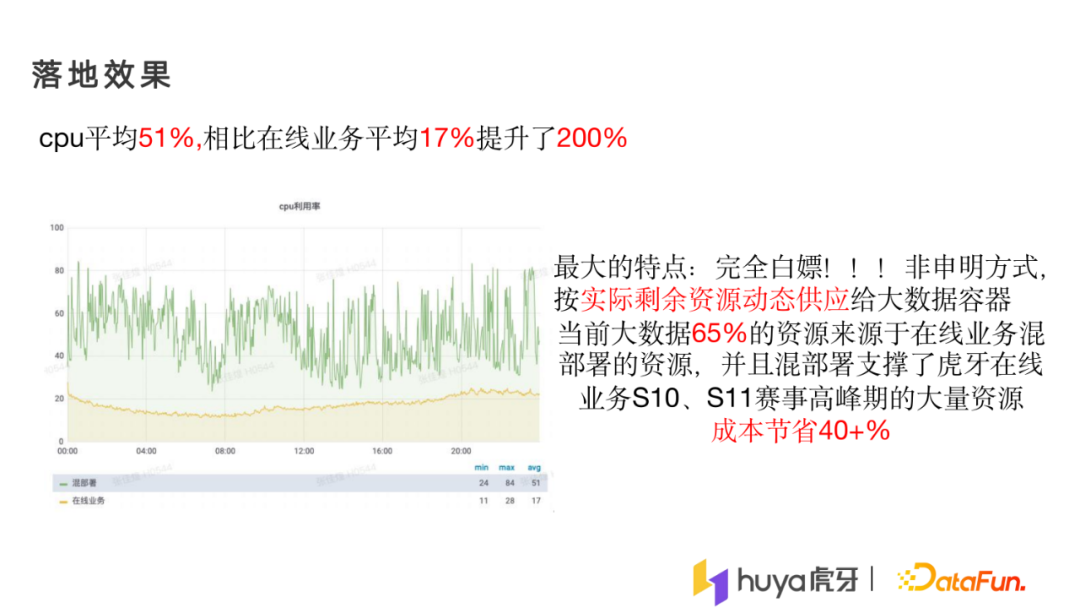
让我们看一下通过我们虎牙的架构,最终落地下来的效果怎样。
黄线是在线业务的资源使用情况,上面是混部后的资源使用情况,混部后CPU平均利用率达到51%,相比于在线业务原本的17%,提升200%。将实际剩余资源动态的供应给大数据容器,相当于将在线业务原本用不上的资源使用上。目前我们65%的资源来自于离在线混部,并且支撑了当年的S10赛事,离线在线业务成本节省40%多。离线的资源消耗情况是很大的,40%多的成本已经是很庞大的成本节省。
03
关键技术实现
接下来看一下关键技术的实现,以及我们遇到了哪些问题,解决了哪些问题。
1. 混部改造挑战

第一个难点是在线业务的资源分布广,在线业务以两地三中心的方式部署,多中心的机房用来保障资源的稳定性,这意味着使用在线业务的资源,还需要解决多机房使用的问题。
第二个难点是资源复杂。虎牙除了大数据在线业务,还有云游戏和AI的一些GPU机器,云游戏、AI都是window系统。AI的GPU机器磁盘空间很低主要做训练,所以整体的资源表现很复杂。
第三个难点是网络隔离。离在线混部从原本单一业务的部署,变成在线业务与离线业务混合部署,本地读写模式变成存储计算分离的模式,在线业务与离线业务共用网卡,还要解决网络隔离,保障在线业务不受影响。
最后一个难点是稳定性保障。因为hdfs的稳定性比yarn的稳定性要求更高,它的每个节点基本上都是有状态的模式,所以这种模式下要保障hdfs不受影响,因为它的等级已经与在线业务的等级一样高。
2. 多机房部署
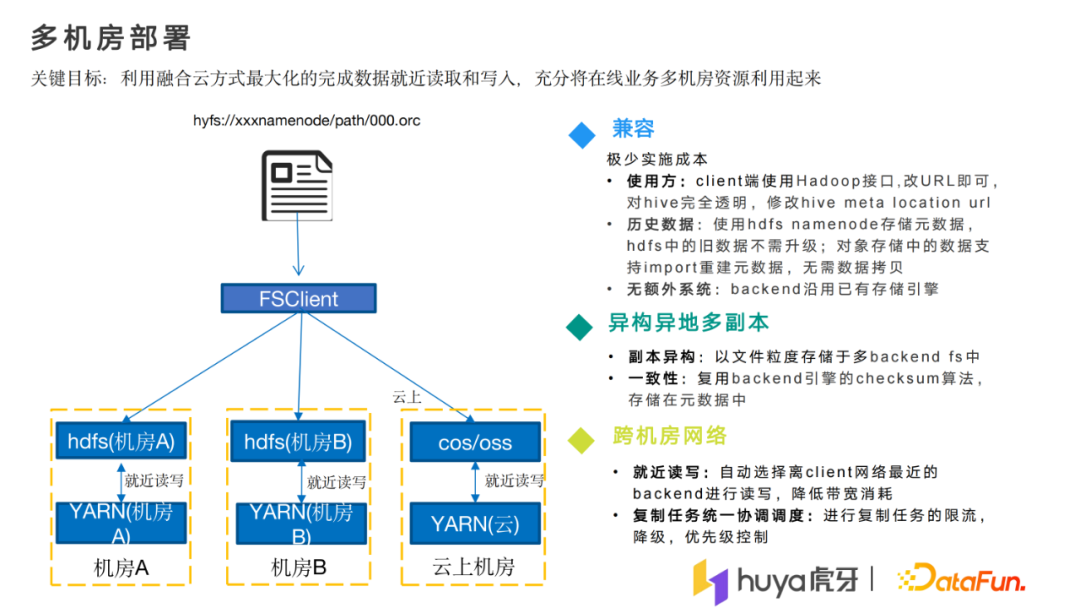
接下来看一下多机房资源问题的解决。
我们的多机房有多idc和多云厂商的模式,如果按照hdfs原有的使用模式,很难将云上的资源利用起来,如果要利用起来意味着在线业务的机房没有存储。如果要将资源用起来,还可以将带宽通过专线传输,但是在计算的节点没有存储,全部是传输的模式,专线带宽承受不住,对离线业务也有影响。因为在云上的机房计算,然后时刻把数据写回idc的中心机房,性能会比就近写数据慢特别多。我们引进了自己改造的一个屏蔽底层存储的hyfs协议,上层全部访问sys协议,包括原数据全部都存储在虎牙hyfs里面,访问协议时就可以实现就近读写的方式,比如在云上计算,存储时就可以利用云厂商的对象存储功能,将数据就近的存储在云厂商的对象存储。多机房部署的云数据是我们自己管理的,意味着我们要能保证数据使用的就近问题。
对于使用方也很方便,hive只需要改location就可以,其他地方不需要变更,使用方式简单,还能解决多机房的存储问题。
3. 异构资源利用
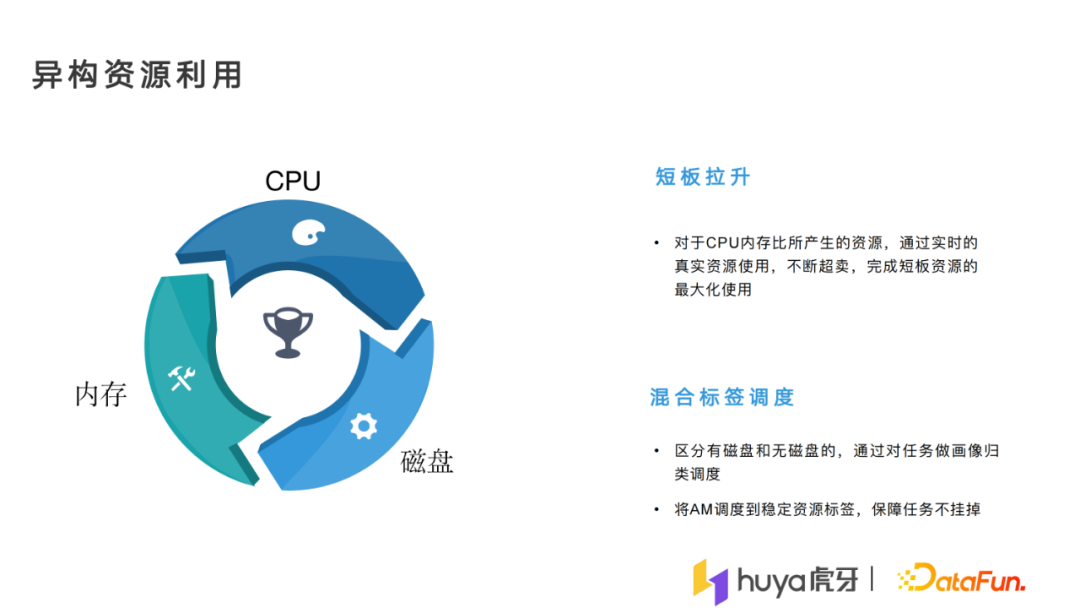
针对cpu内存的比例差异,我们采用的是捆绑的方式拉伸,如果给的CPU配比较少,但内存比较多,我们会实时的检测资源使用情况,然后对资源进行超卖,尽量将短板资源的资源量全部用完,这样资源使用就更充足。
另外一个磁盘问题,我们将一些在线业务以及云游戏机器复用时,有些机器原本没有磁盘。对于需要shuffer的任务,我们会在任务提交时,对任务做画像的归类调度,运行任务时判断小范围内有没有shuffer,然后将磁盘消耗小的任务调度到无磁盘的机器上面,这就是混合标签的调度。为了保证资源的使用,我们会让任务既能调度到无磁盘的标签队列里,又能调度到有磁盘的标签队列里,这样就不存在某个标签使用完后,剩下的资源其他任务不能使用的情况。
弹性调度可能会让计算节点资源不稳定,而ApplicationMaster是有状态的,如果ApplicationMaster被Kill,整个任务又需要重新运行,那么我们在标签调度时将AM调度到稳定的资源队列里,就保障容器弹性伸缩的同时,保证任务不受影响。
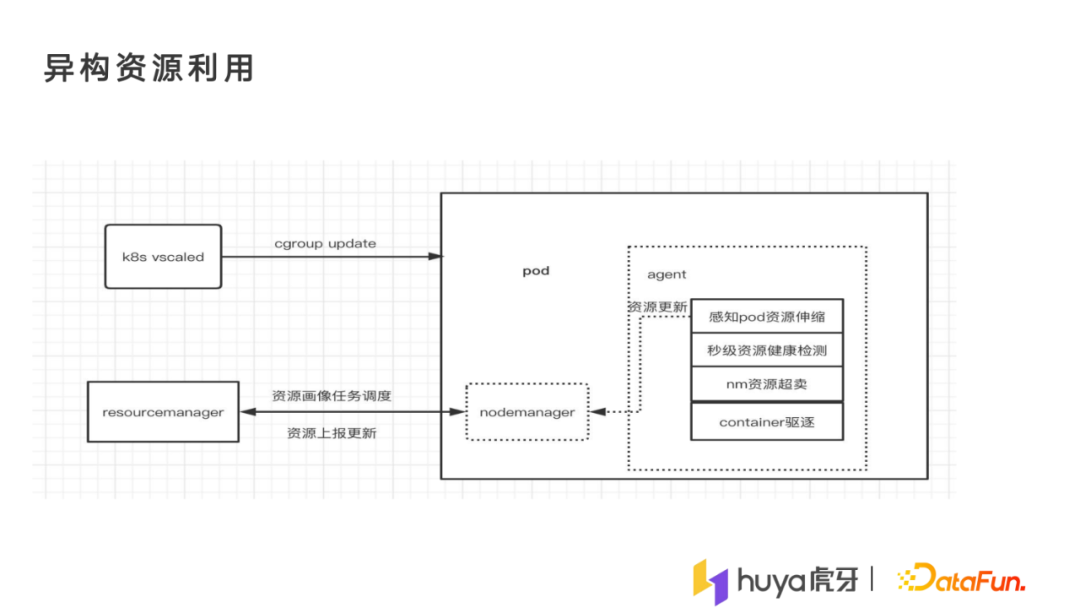
我们的k8s会不断地做cgroup 的update调整资源。我们在每个pod里都会感知资源多少的变化,然后针对资源去做更新,把它的最大资源上报,不断去调整资源量。pod也会对资源做健康检测,查看资源的实际使用情况,然后不断地对资源进行超卖,尽量将资源跑到真实的物理最大值。
4. 稳定性保障

以下是稳定性保障实现时遇到的问题:
-
机器负载高。hdfs和yarn一起启动后,整台宿主机的负载高。主要原因是hdfs使用的group的cpu分片模式,在使用过程中频繁的切换分片导致负载发生溢出。解决办法是将hdfs与固定的cpu绑定实现性能和负载的保障。
-
网卡带宽不够。在线业务与离线业务放在一起,整台宿主机的网卡资源基本上被占用满,在线业务会出现各种丢包等问题。针对网卡带宽的问题,我们做了QOS限速,并引入共享带宽包来隔离带宽。
-
机房内部带宽满。将宿主机容器化之后,识别hdfs与yarn时ip是不一样的,数据读写由本地读写变成存储计算分离的模式,机房整体带宽被拉高。为了避免跨平面传输导致的带宽问题,我们也是使用QOS的方式进行限速。
因为我们做了资源超卖的逻辑,而且pod资源是动态调整的模式,意味着pod资源如果超卖或者调整过度,可能会导致整个pod直接发生OOMKilled,所以也做了稳定性的保障,保证pod在资源调整的情况下,也不会发生OOMKilled的驱逐。
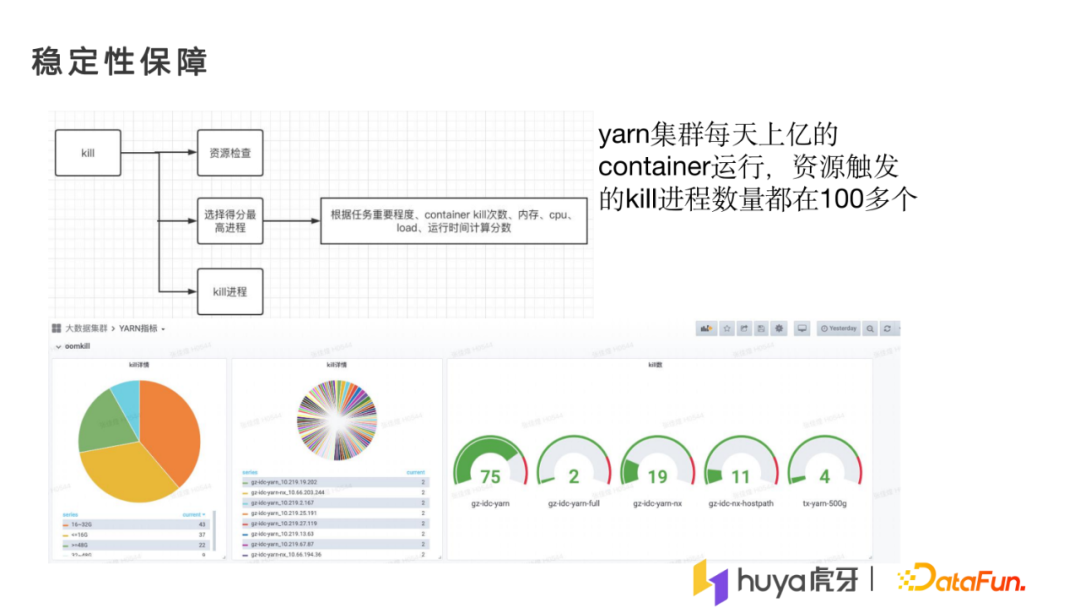
以下是做资源超卖以及资源伸缩时实现的一些保障。
如果资源用得比较高,必须要kill进程时,我们会秒级地对pod资源做使用检查,然后通过container进程的内存、cpu、load以及运行时间去计算一个分数,选择一个得分最高的进程并kill进程,来保证运行在pod上面的其他进程不受影响,从而保障整体资源的稳定性。
可以看到我们当前控制的比较稳定,在每天上亿个container运行的情况下,任务触发的kill进程只有100多个,并没有因为资源超卖和弹性伸缩,导致每天大量的container一直在发生kill的操作。
04
未来展望

最后讲一下离在线混步我们还有哪些事情可以做。
在资源混部的情况下,我们的资源利用率还不够平稳,由于超卖时不知道container级别的资源使用细节,所以我们用的是边使用边调整的模式,因此资源的利用率会比较波动。我们希望未来将资源利用率做得更平稳。
虎牙现在有很多机房落地在二三线城市,在未来我们也希望将边缘机房做混部,将机房的资源利用起来,复用到我们自制的分析计算或者实时的分析计算里。
今天就分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

本文转载自张佳煌,原文链接:https://mp.weixin.qq.com/s/86DjQvMwbDbjga0gqlvC8w。