
-
云平台大数据建设背景 -
云平台大数据建设方案 -
应用实践 -
未来规划
云平台大数据建设背景


-
2019 年,我们的很多离线作业是基于 Hadoop 集群做的。基于这个集群之上,我们有一些 OLAP 查询场景,当时可选的组件不多,于是我们用了 Kylin、Druid。但是这只能应对一些简单的场景,复杂的场景还是没办法直接基于这些组件对外提供服务。 -
2020 年,引入了实时计算,当时用的是社区版 Flink,其中 ClickHouse 跟 ADB 主要是做 OLAP 的查询,另外的 ElasticSearch 是用来存储画像的数据。 -
2021 年,随着业务场景的需要,我们用到的组件也越来越多,所以不得不选用基于多数据源的查询引擎,于是引入了 Presto,这个时候可以基于 Presto 做一些联邦查询 ,Hive、MySQL、ADB、ClickHouse 等做一个打通关联。基于 Presto,我们会在上层做一个报表的查询。 -
2022 年,我们大数据全部上云了,只需要用到三个重要组件:MaxCompute、Hologres、Flink。
以上是我们大数据演进的过程,下面先分析一下 IDC 集群的情况。

-
第一、资源成本:
-
机器成本高; -
机房成本高,因为有一百台机器要有单独的机房; -
空闲时间多。我们的离线作业大部分在晚上运作,白天的时间基本上是比较浪费的。
-
第二,人力成本:
-
组件多,运维成本高。一个人要负责三四个组件的维护; -
组件学习成本高,一些业务开发的同学会使用我们提供的组件,对于他们来说,会有一定的学习成本; -
开发成本高。
-
第三,稳定性、扩展性:
-
IDC 集群做扩容时流程很复杂,从申请,到机器的采购,再到部署、上线等,至少要一个月的时间,扩展性很差; -
机房部署周期长; -
故障率较高。
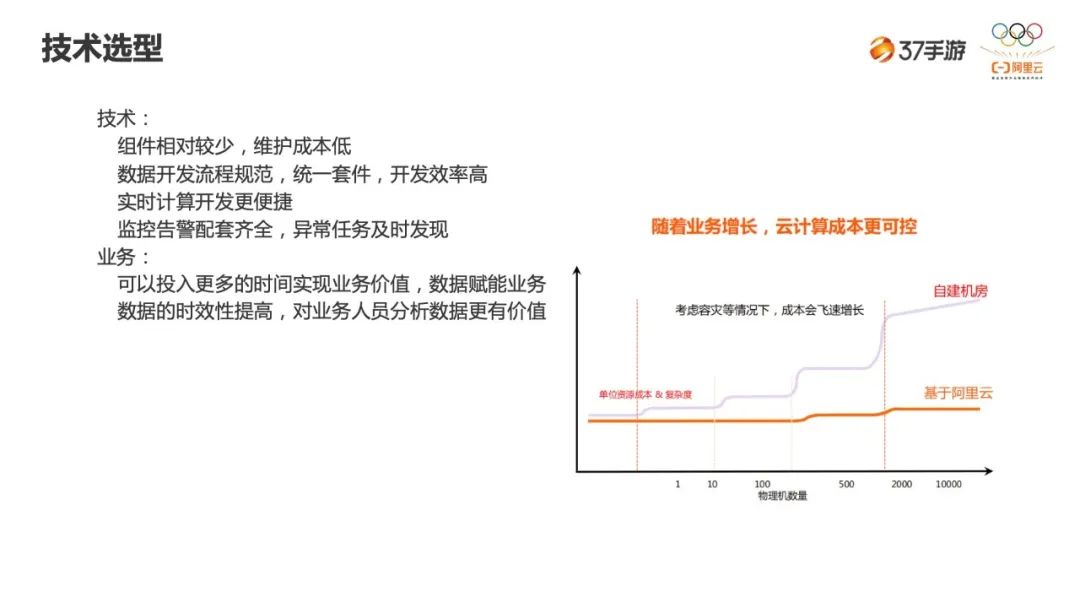
-
上云后用到的组件很少,维护成本低。 -
统一套件,统一开发流程,极大的提高开发效率。 -
实时计算开发更便捷。上面也讲到了,实时计算只需写一条 SQL 就可以了,快捷。 -
监控齐全。以前任务出现问题很难发现,现在有了配套的监控就可以及时的发现。
-
可以空出更多的时间做更有业务价值的东西,数据赋能业务。 -
数据的时效性。之前有的 15 分钟、30 分钟跑一次,现在是实时的,这是很明显的对比。

-
从流计算开始,Flink 社区版、Spark、Storm 直接用实时计算 Flink 替代。 -
第二是离线计算,之前用 Hadoop、hive、Spark,现在统一存在 MaxCompute。 -
最后一个是 OLAP 数据库,包括之前的 ClickHouse、Presto、Kylin、Druid 等,现在全部用 Hologres 替代。
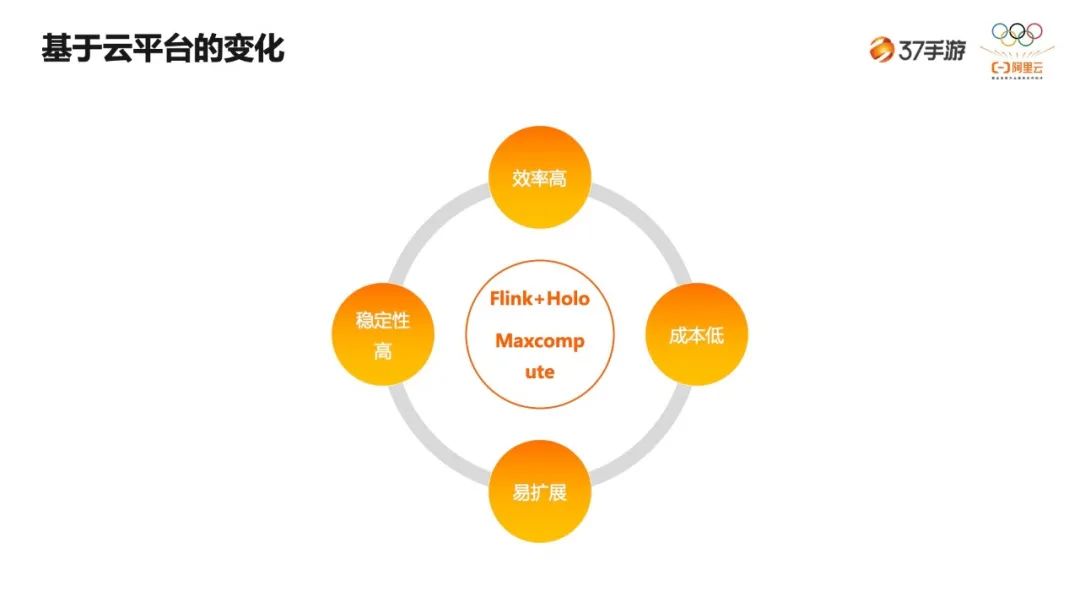
-
一是效率高。上云之后首先是效率的变化,不单单是机器扩展效率,还有包括开发效率。 -
二是成本低。我们也和 IDC 集群做了对比,上云之后整体成本会降低。 -
三是易扩展。现在不管加存储也好、内存或者 cpu 也好,几分钟即可完成扩展。 -
四是稳定性高。上云之后几乎还未出现过问题。
云平台大数据建设方案

-
第一条链路是实时流,从 Kafka 过来,经过实时计算,实时计算之后会落到 Hologres。但是有一些场景需要扩展维度,实时计算时会用到配置表,是在 Hologres 基于行存来存储的配置表,通过点查的能力,把配置信息取出来做实时关联,最终落到 Hologres。 -
第二条链路,可能也是大家常用的(传统的数据库还是要保留),我们会把传统的 MySQL 数据库通过 DataWorks 数据集成同步到 Hologres。 -
最后一条链路是离线的,Kafka 数据通过 DataWorks 写到 MaxCompute,写完之后会在 MaxCompute 每天定时跑任务来修整第一条线的实时数据,也就是做一个离线的修正。另外我们会把 MaxCompute 里画像数据推到另外两个组件。这里说明一下,这两个组件是为了考虑到双云部署,所以我们考虑到开源的组件,StarRocks 和 HBase,这两块主要是用在画像上。
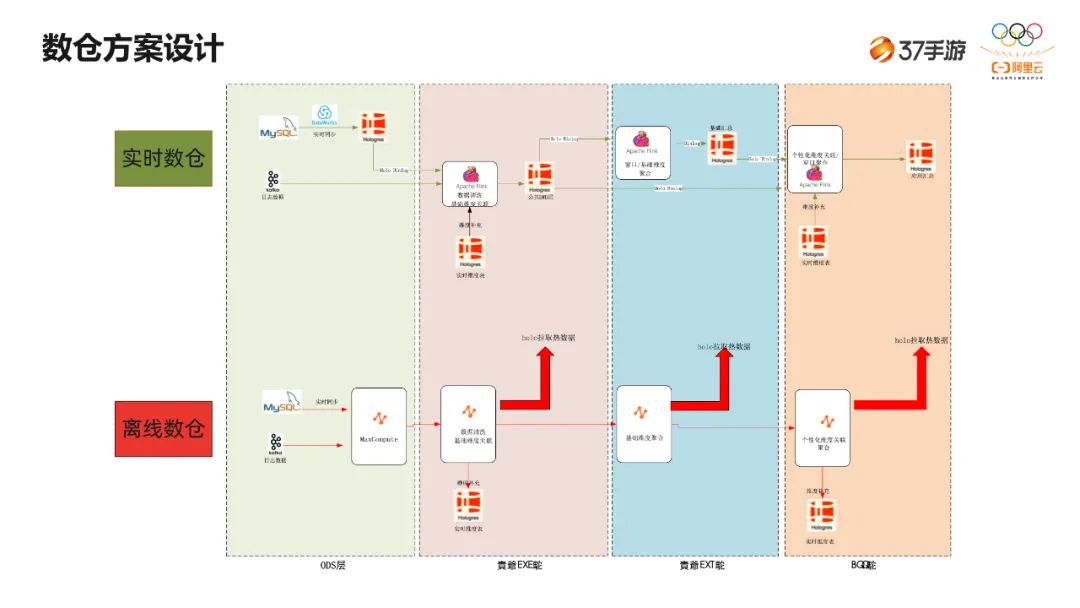
-
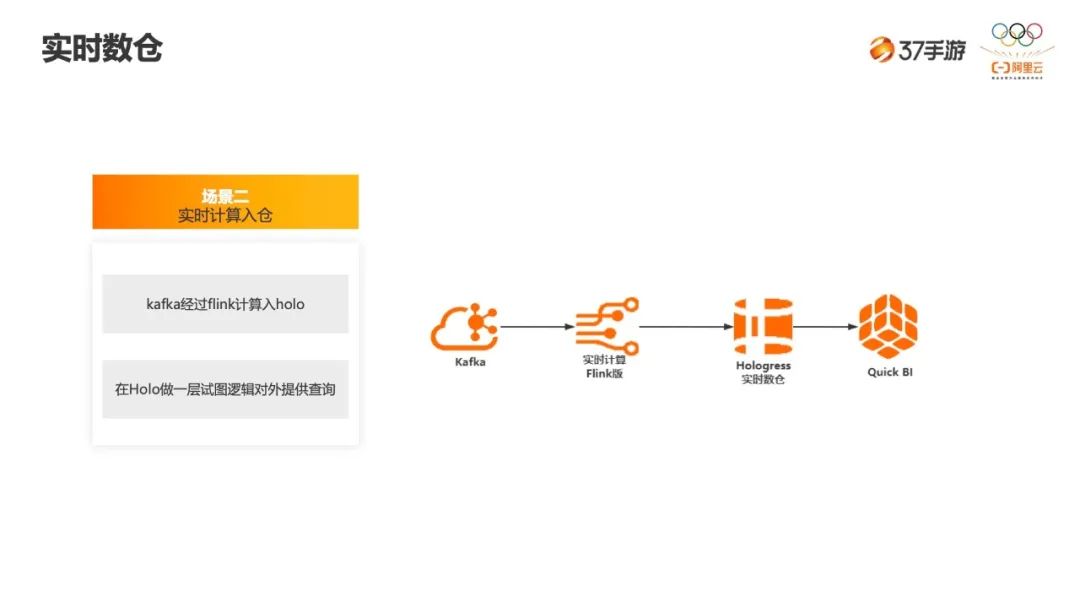
上面是实时数仓,可以看到主要来源于两个地方,一个是 MySQL,一个是 Kafka。两块数据是通过 Flink 落到 Hologres,从 DWD 到 DWS 再到 ADS 逐层清洗,最终落到 Hologres。 -
下面是离线数仓,通过 MySQL、Kafka 落到 MaxCompute,在 MaxCompute 逐步分层,最终落到 Hologres,离线这一层会修正实时的数据。

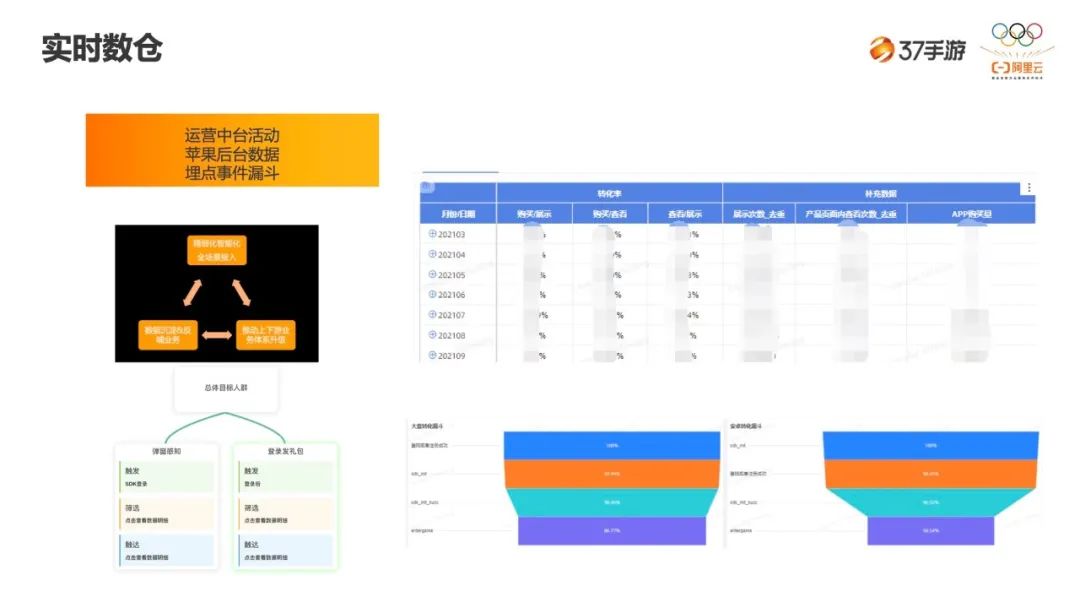
-
第一是运营中台的活动,我们在做一个游戏活动时,可能会分 A、B 两个人群做代金券或者礼包的发放,对 A、B 两批人在不同阶段(登录、激活、充值等)进行统计分析,进而分析这个活动效果与收益。 -
二是苹果后台的数据,通过实时计算得到不同阶段的转化率,包括从展示到购买,从查看到购买,从展示到查看等转化率。 -
最后是 SDK 埋点,做了一个漏斗的模型,也是看转化过程。从下载、激活、到登录等一系列流程转化率的展示。
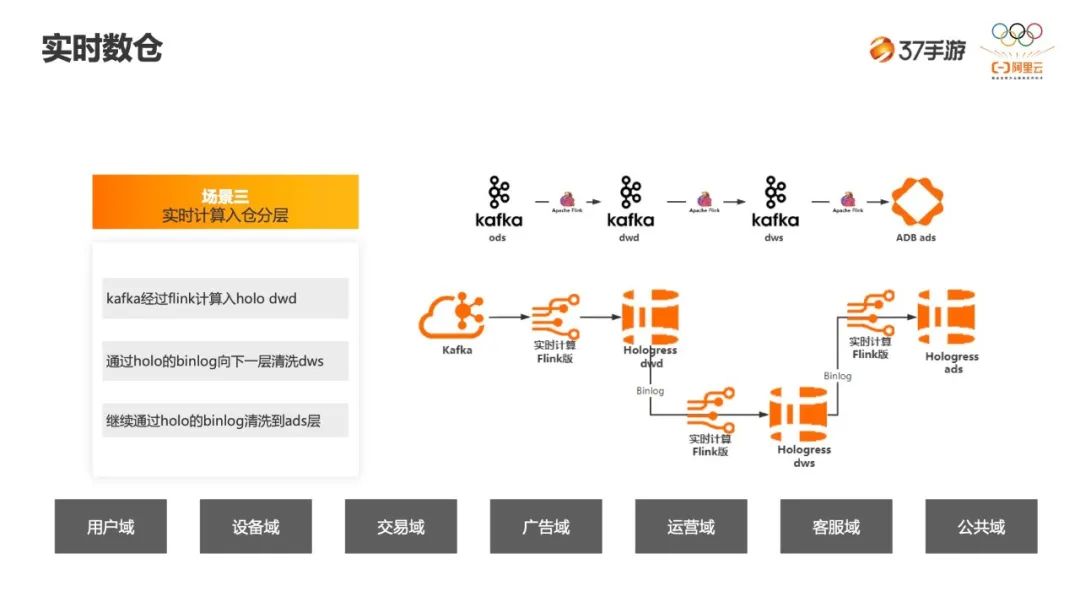
-
此前的方案是把 kafka 作为中间存储,中间层 DWD、DWS 都存储在 kafka 中。这种方案的缺点是很明显的,一旦数据不一致或者数据延迟,很难排查问题。 -
目前是基于 Hologres 来做的实时数仓,每一层数据都会实时落进去,有问题的时候比较容易追踪。
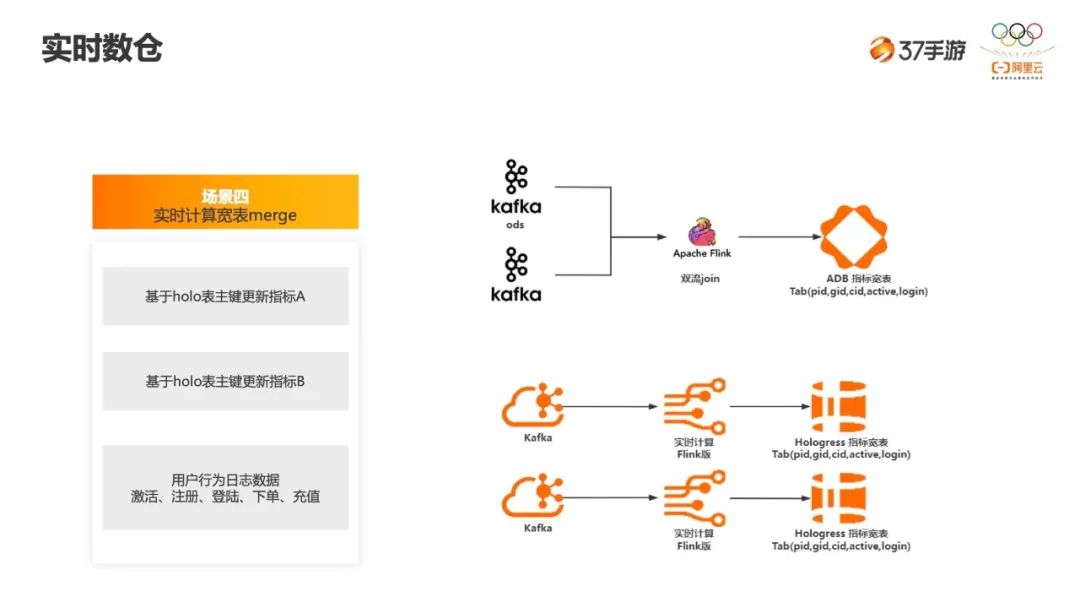
-
如右上图,多指标合并此前我们会通过双流 Join 来做,假设想通过这个表来看用户登录、激活,但它有两条流,登录是一条流,激活是一条流。我们之前可能是要把这两条流用 Flink SQL 写出来做一个 join,但是这个性能不太好,计算也会翻倍。 -
新的方案是基于 Hologres 的主键做局部更新,登录这条链路就只做登录分析,激活就只做激活的统计。source 是两个,但是 sink 到同一张表,基于 Hologres 宽表 merge 的能力来实现这个业务需求。
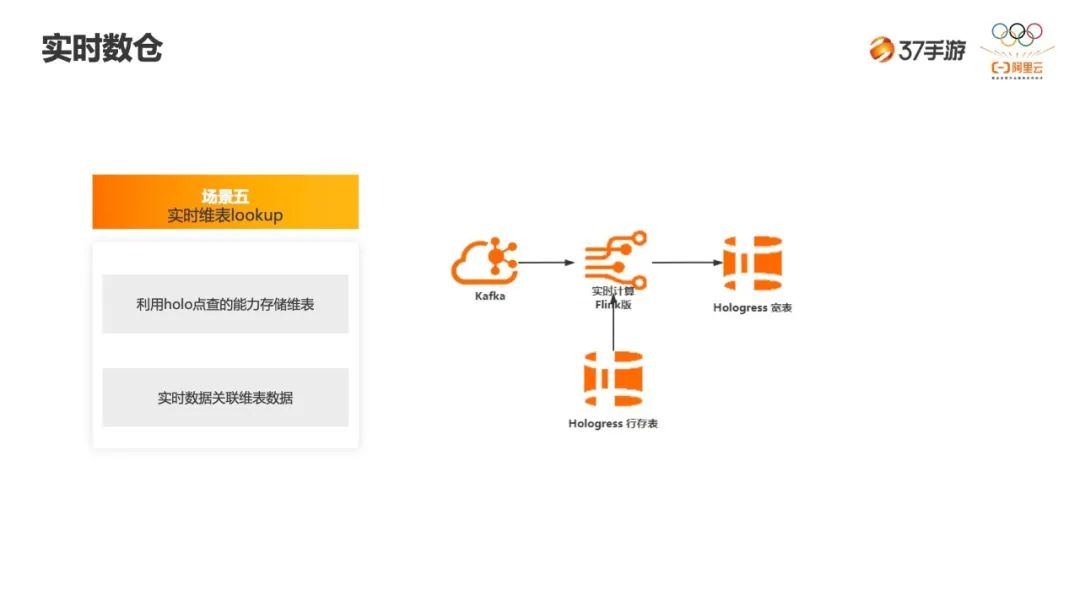
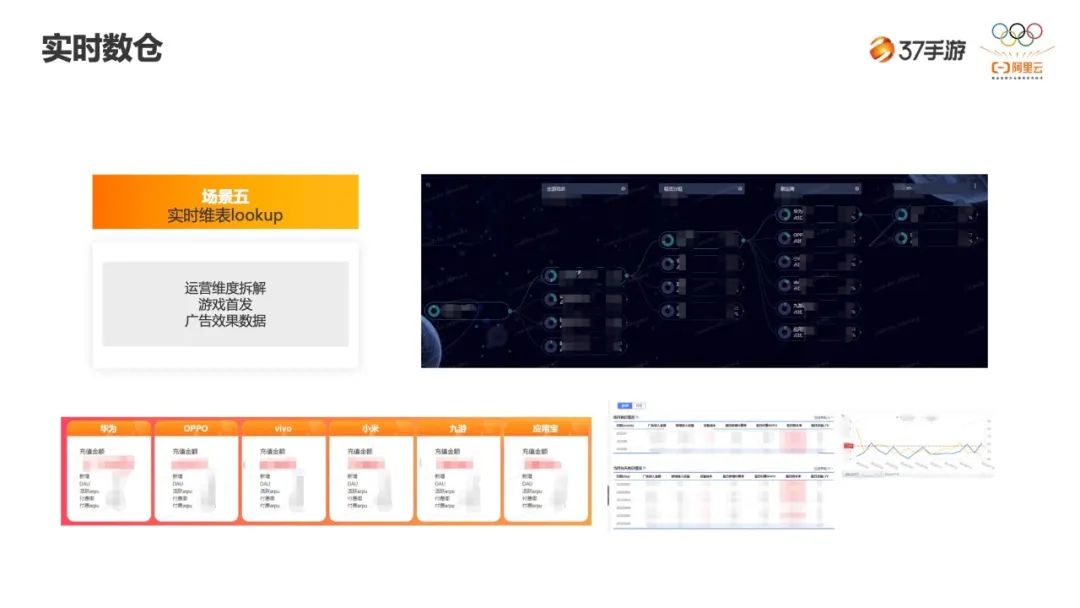
-
第一是运营维度的拆解。如何理解右边黑色的部分?在一款游戏发行之后,我们会基于某一个维度做下钻的分析,看某一个游戏,比如 A 游戏下哪个联运商的占比比较高,再根据这个联运商做进一步的下钻分析。 -
二是游戏首发时,我们可以实时地关注这个游戏的玩家动向。 -
最后是广告效果的数据,当投放一个广告,我们要知道这个广告后期的留存情况、LTV,以及媒体测的曝光、点击、下载等数据。
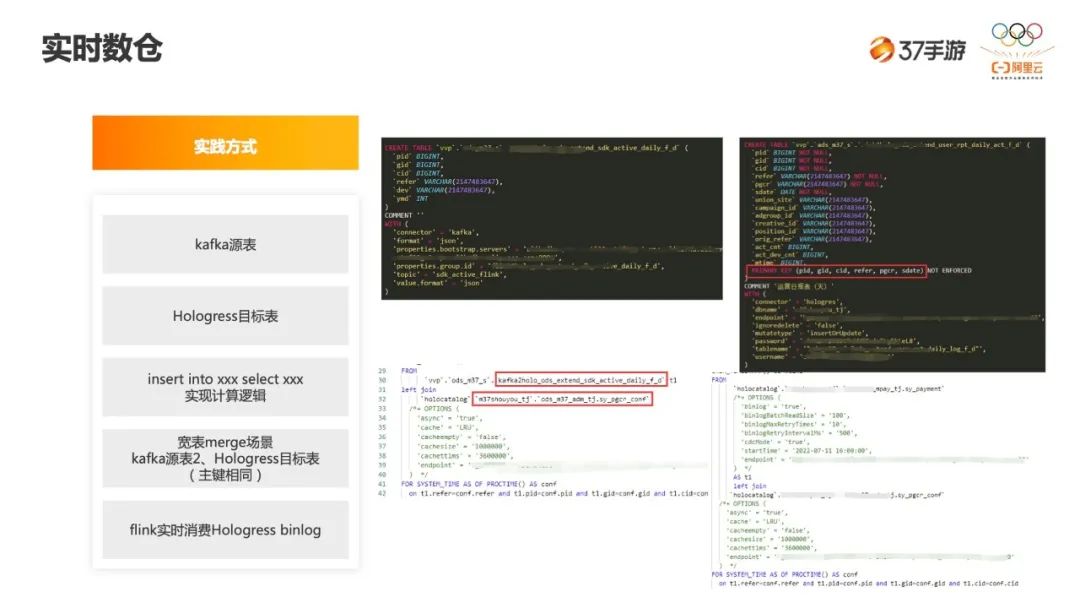
-
首先,上游是 Kafka 的源表。首先需要建一个 kafka 的源表,其次是建立 Hologres 目标表,最后是写一条业务逻辑 SQL,把数据 insert 到目标表,实时计算过程就完成了。 -
还有宽表 merge 场景,上面提到我们的源是有两个 Kafka,kafka 1 和 kafka 2,分别从两个 source 端读数据,然后 sink 到同一个 Hologres 的目标表,但是一定要保证主键是相同的。 -
第三是通过 Flink 消费 Hologres Binlog 的能力,这种场景一般是应用到充值类、订单类的数据。因为这种数据会变更,所以不像 Kafka 里面日志类的数据那么简单的处理,这时会用到 Hologres 的 Binlog,等于把 MySQL 的 Binlog 做了同步,所以 Hologres 也可以拿到 Binlog,可以直接通过这个能力去查这个表。
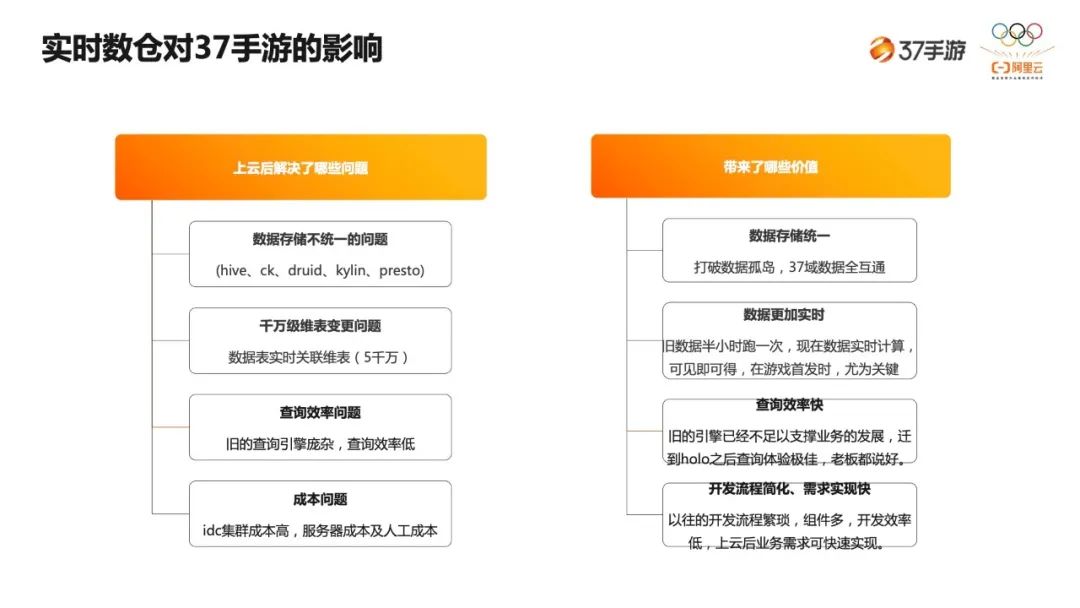
-
一是数据存储的问题,以前存储组件非常多,Kylin、Druid、MySQL、Presto 等,现在统一存到 Hologres。 -
二是千万级维表变更的问题,我们的量级非常大,大概能到 5000 万,数据要去关联 5000 万的配置表,并且要实时地做这个事情,这在之前很难做到。 -
三是查询效率的问题。对业务来说,查询的时候非常慢,这个问题能通过 Hologres 高性能的查询解决。 -
最后是成本问题,因为 IDC 集群的成本,包括维护成本,还有后期扩展成本都是很高的。
-
一是数据存储统一。打破了数据孤岛,37 域的数据是全通的。 -
二是数据更加实时。之前每天的数据会半小时或者十五分钟跑一次,现在是实时计算,所见即可得,尤其是游戏首发的时候我们对数据的实时性要求非常高。 -
三是查询效率。旧的引擎很难支撑业务的快速发展,新的数据库 Hologres 在查询性能上体验极佳。 -
最后是开发流程简化。我们之前的开发流程是很复杂的,现在只需要实时计算这块写一个 SQL 就可以搞定了。
应用场景
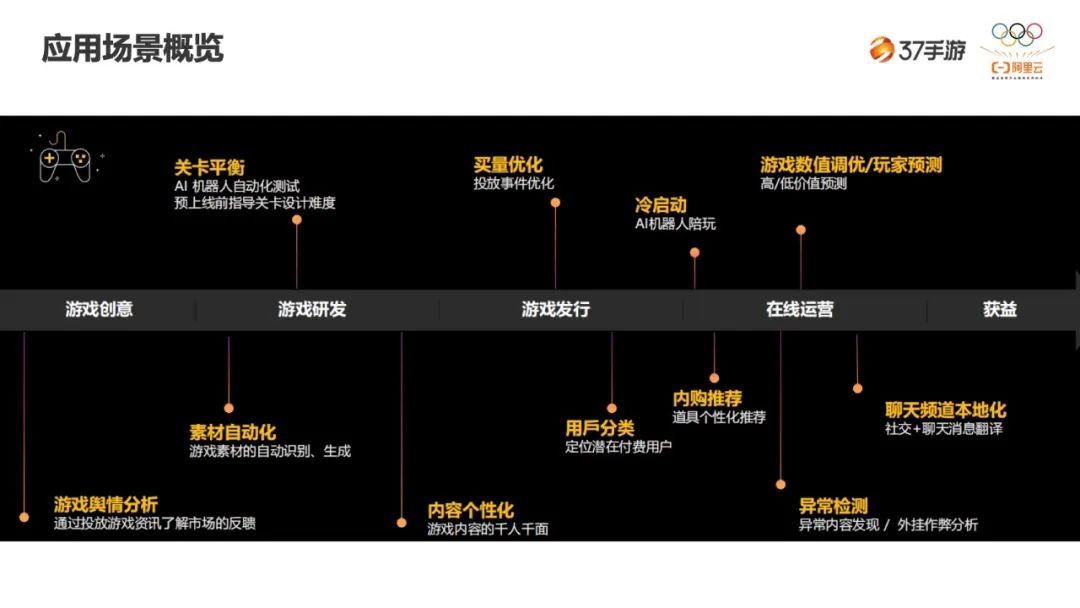
-
一个游戏的诞生首先是从创意开始,怎样策划一个游戏。 -
策划完第二步就是做研发,一个游戏能不能长期留住玩家,这一步是最关键的,包括关卡设置,关卡难度,游戏画面等等。 -
第三步是游戏发行,研发完成后即是游戏推广了,不然就算这个游戏再好玩,没人知道、没人玩也是没有收益的,酒香也怕巷子深。 -
发行完后最关键的就是如何留住玩家,如何长期留住玩家,在线游戏运营是重要的一个环节,维护一个良好的游戏生态。 -
最终是获益。
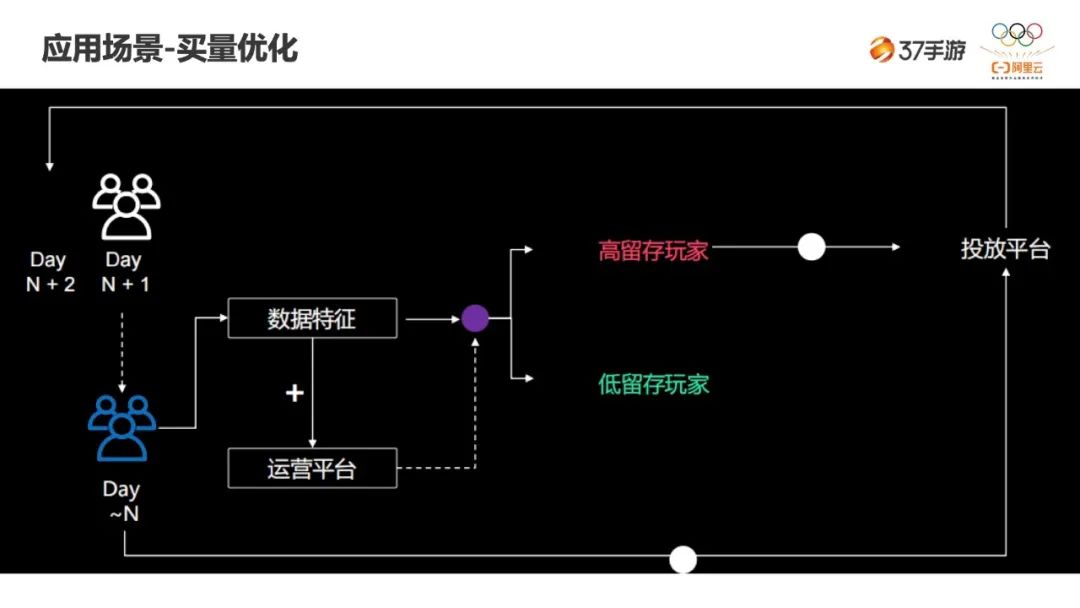
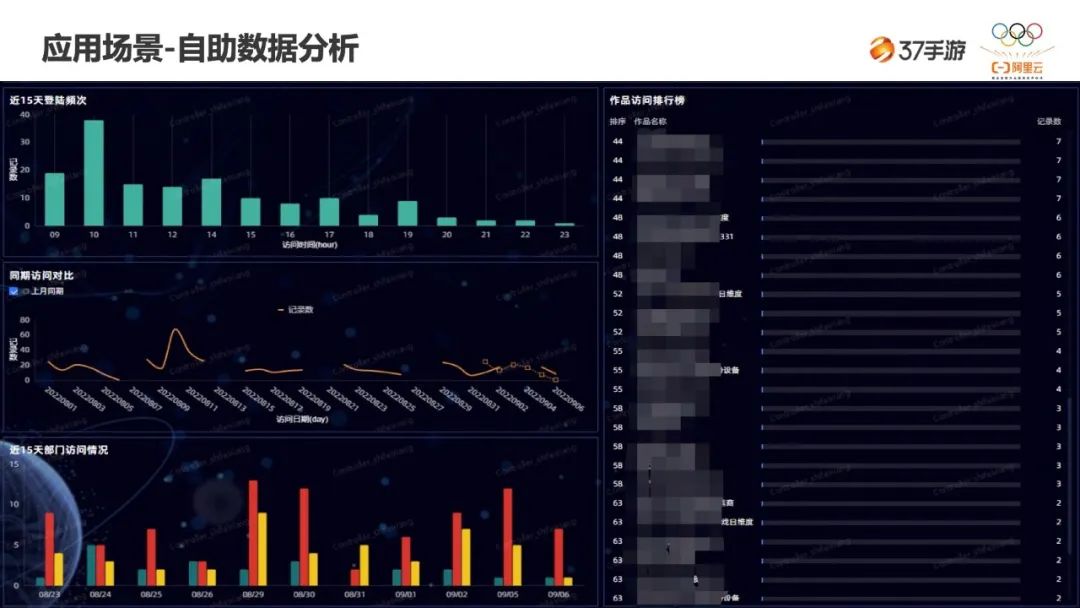
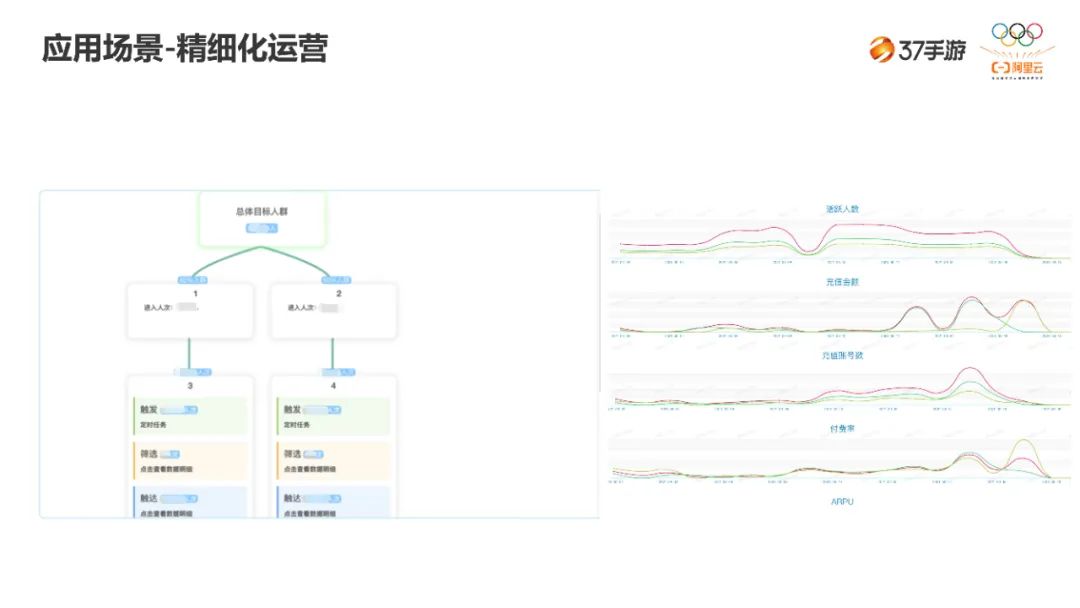


未来规划
-
首先,我们在智能投放方面做得还不够好,所以想在智能方面投入更多的精力和时间。比如 37 手游的用户数据跟媒体数据做一个打通,这样不但可以对自己已有的画像人群分析,还可以结合媒体画像指标做进一步分析。有了这些数据可能对投放的效果也会有很大的提升。 -
第二,智能运营。现在做的事情是每个人发送代金券、礼包,其实都是统一的,我们未来想做到千人千面,每个人发不同的代金券,不同的礼包,类似于个性化推荐,进而来提高收益。 -
第三,智能诊断、归因分析。在海量的数据,海量的指标中,数据波动异常如何及时发现;发现异常后如何分析导致异常的原因等。目前做的还是比较初阶,这也是我们未来重点突破的地方,智能归因、智能诊断、智能化洞察。
公司介绍:37 手游是 37 互娱的子公司,主要负责运营,也就是发行业务。在中国大陆地区 37 手游以 10% 占有率仅次于腾讯和网易排第三。现在在非中国大陆地区也已经进入月收入过亿的俱乐部,成功发行了包括《永恒纪元》、《一刀传世》、《斗罗大陆》这几款游戏,当前已经累计 4 亿用户。
Flink Forward Asia 2022

本文转载自史飞翔@37手游 Apache Flink,原文链接:https://mp.weixin.qq.com/s/p3eA2c0SmoruFZc9vSRdRQ。