
1. 背景
货拉拉作为一家数据智能驱动的科技物流型平台企业,内部分析师和研发人员等每天会通过大数据服务进行大量 ad-hoc 查询分析。通过 NPS 调研发现用户普遍反馈 ad-hoc 查询慢问题,对查询效率满意度较低。大数据使用 Hive on Tez 作为 ad-hoc 查询引擎,受限于引擎自身特点,在 ad-hoc 查询场景无法满足用户对时效的要求。为提升 SQL 查询效率,大数据引入更多类型引擎并自主研发了离线混合引擎服务来帮助用户查询提速。以下描述货拉拉大数据在离线 ad-hoc 查询场景下通过混合引擎服务进行提效的一些实践经验。
2. 业界调研
在业界调研过程中,我们也发现了一些类似的产品,例如腾讯的SuperSQL、阿里的DLA、华为的HetuEngine、360的Quicksql和网易开源的Kyuubi等,下面表格总结了它们各自的特点以及差异。
| 维度 | 腾讯SuperSQL | 阿里DLA | 华为HetuEngine | 360 QuickSQL | Kyuubi |
| 计算引擎 | Presto+Spark+Hive+StarRocks | Presto + Spark 二次改造 | 基于Presto改造 | Spark+Flink | Spark+Hive+Presto+Flink |
| 是否开源 | 否 | 否 | 否 | 是 | 是 |
| SQL语法 | SQL-2003标准,兼容Hive/SparkSQL/Presto 常用DQL/DML/UDF | MySQL 5.7绝大部分查询语法 | 部分兼容SQL92/2003 | 统一的SQL语言(基于ANSI SQL-2003标准) | HiveSQL |
| 数据源 | 8+ RDBMS:MySQL, PostgreSQL、Oracle, ClickHouse … 10+ NoSQL:Hive, Phoenix, ES, Kylin, Hermes … | RDBMS: MySQL, PG, SQLServer, Oracle NoSQL: TableStore, OSS, MongoDB, Redis | Hive, MPPDB, Oracle, MySQL, ES, Redis, Kakfka, HBase | Hive, MySQL, Kylin, Elasticsearch, Oracle, MongoDB, PostgreSQL, GBase-8s | hive |
| 跨数据源联邦查询 | 支持 | 支持 | 支持 | 支持 | 不支持 |
| 云原生程度 | 高,云原生的设计架构 | 高 | 高 | 无 | Kyuubi Server支持k8s部署 |
| 是否开源 | 否 | 否 | 否 | 是 | 是 |
总的来说,它们一般具备以下特点:
- 1. 多数据源能力:支持多种 BigData/RDBMS/NoSQL/FileSystem 数据源。
-
2. 多引擎路由能力:在不指定引擎的模式下,能够根据SQL特征分析,路由到最合适的引擎执行,并能智能降级。
-
3. SQL转换能力:上层提供单一的SQL语法,底层能够根据转换为不同引擎的SQL语法。
-
4. SQL优化能力:能够通过RBO/CBO/HBO等能力,优化SQL执行。
-
5. 联邦查询能力:在统一平台上能够进行多数据源之间的联邦查询。
3. 设计与实现
系统的设计目标需要考虑以下几个方面:
-
• 功能需求:研发一个能充分结合多引擎优点,实现多引擎智能路由,屏蔽引擎间差异性,多引擎间能自动降级,提供统一大数据SQL引擎的系统。
-
• 稳定性:系统需要具备良好的稳定性,以确保其在高负载和复杂场景下的稳定运行。
-
• 扩展性:系统需要具备一定的可扩展性,以满足未来业务的发展需求。
-
• 易用性:业务易接入,无需过多的改造工作。
-
• 正确性:无因多引擎间的兼容性导致的数据质量问题。在上述设计目标要求下,我们的服务架构采用典型的Master/Worker架构。Master角色实现HA部署来保证服务稳定性;Worker角色具备良好的扩展性,可基于请求量的大小而弹性调整服务的规模;在易用性方面,提供了SDK/JDBC/Cli等接入方式;在数据正确性方面,通过自研的多引擎数据对账工具来保证。在调研过程中,我们有发现一些案例是将所有功能都集成到一个SDK,然后让业务接入使用。但是我们没有采取这种方式,而是选择了做成一个独立的服务,主要是因为这样可以减少业务频繁升级带来的麻烦,并且也可以得到更多自主可控的能力。
3.1 功能架构
下图展示的是服务的整体功能架构图。


服务的功能架构从上到下分为以下几层:
-
1. 应用层:服务上面承载的业务有即席查询平台(BigQuery)、数据质量平台(大禹)、BI平台(云台)、ABTest平台等。
-
2. 接入层:提供SDK、JDBC、Shell等接入方式来提交SQL查询;提供认证、权限、限流、审计等功能。
-
3. 路由层:能够对SQL进行特征分析,选择出最适合的引擎,对SQL进行解析与转换提交到引擎执行,并在某个引擎执行失败后能够进行智能降级到其他引擎执行。
-
4. 执行层:能够将SQL投递到具体引擎并获取结果返回给客户端,并感知底层引擎算力;对资源(线程/内存/连接)进行管理。
-
5. 引擎层:具体执行SQL的引擎,目前包括Presto和Hive引擎。离线混合引擎服务的主要功能包括接入层、路由层和执行层。除此之外,我们还对服务提供了一些管理/辅助能力,主要包括:对服务配置进行管理,能够实时更新配置,动态上下线节点;提供HBO服务,记录SQL最近路由以及执行相关等信息;提供日志服务,让用户能够查询历史SQL执行日志;接入公司Monitor监控系统,对服务核心指标进行埋点,能够实时监控服务状态。
3.2 系统架构
系统角色包括Client/Master/Worker,角色之间通过gRPC进行通信。在系统设计与实现上,我们也充分参考了YARN的资源管理设计、HiveServer2的接口设计以及Query状态机设计等。下图展示的是角色之间的交互图。
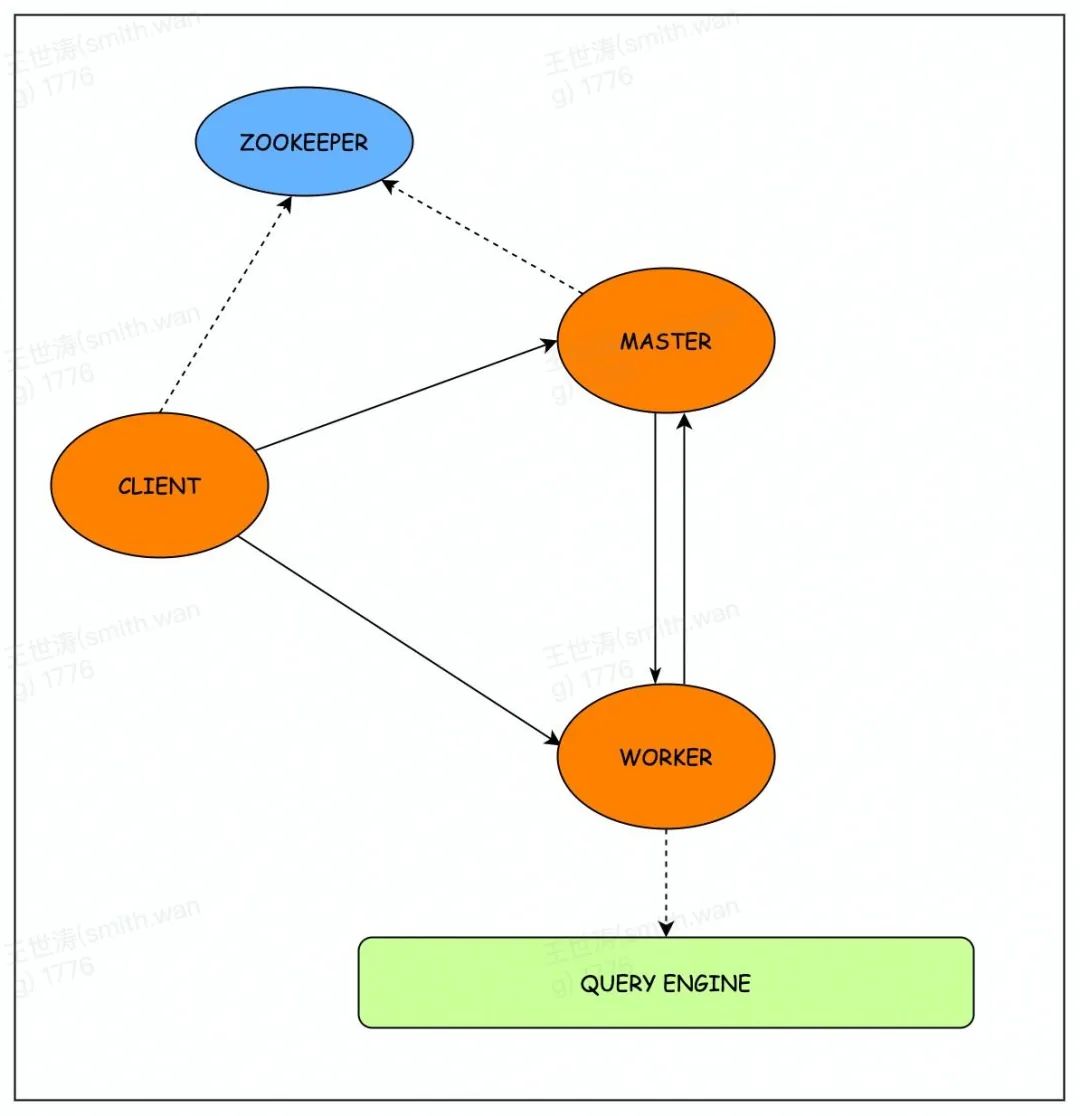
3.2.1 Master
Master通过Zookeeper实现HA部署来保证服务的高可用性,服务状态会持久化到外部存储,便于在服务宕机或者切主时能够恢复。主要包含以下几个功能:
-
1. 资源生命周期管理:为Client分配QueryId以及Worker Slot资源,并对其生命周期进行管理。
-
2. 负载均衡:通过心跳感知每个Worker资源现状,对新的请求实现负载均衡。
-
3. 服务上下线:Worker节点上线会向Master注册,加入资源池;可以通过Master修改节点状态下线节点。
3.2.2 Client
Client(SDK/JDBC/Cli)功能相对简单,负责提交SQL到Worker角色执行,等待SQL执行完成并获取结果返回。具体流程步骤为:首先通过Zookeeper获取Master地址并向Master申请资源,然后向指定Worker提交SQL,最后等待SQL执行完成并获取结果。
3.2.3 Worker
Worker是系统中较为复杂的部分,负责接收Client提交的SQL,经过一系列复杂的转换,最后提交到计算引擎执行,获取计算结果并返回给客户端。下图展示的是SQL在Worker内部的执行流程图。

-
1. Worker接收到SQL后会交给QueryManager进行管理,QueryManager主要负责管理Query信息、监听Query的执行状态以及投递SQL到执行引擎。
-
2. Dispatcher会对SQL进行特征分析,包括但不限于SQL类型、SQL扫描数据量、SQL中各种执行算子数量(GroupBy/Join/MapJoin等)、SQL是否包含特定关键字/UDF等,进而决定SQL投递到哪个计算引擎。
-
3. SQL Converter负责将源SQL转换为目标引擎的SQL语法。
-
4. 提交到QueryExecutor中执行,QueryRunner负责提交SQL到计算引擎中执行,获取SQL执行日志(保存在本地或者远端存储),并不断向QueryManager上报Query状态,最后获取计算结果并返回给客户端。
-
5. 如果投递到某个引擎执行失败之后,QueryManager会为该SQL降级到其他引擎中执行(兜底引擎是Hive),确保SQL最终能够执行成功。
3.2.4 Query的生命周期
Query的生命周期通过状态机进行流转,包含6种状态,流转图如下图所示:
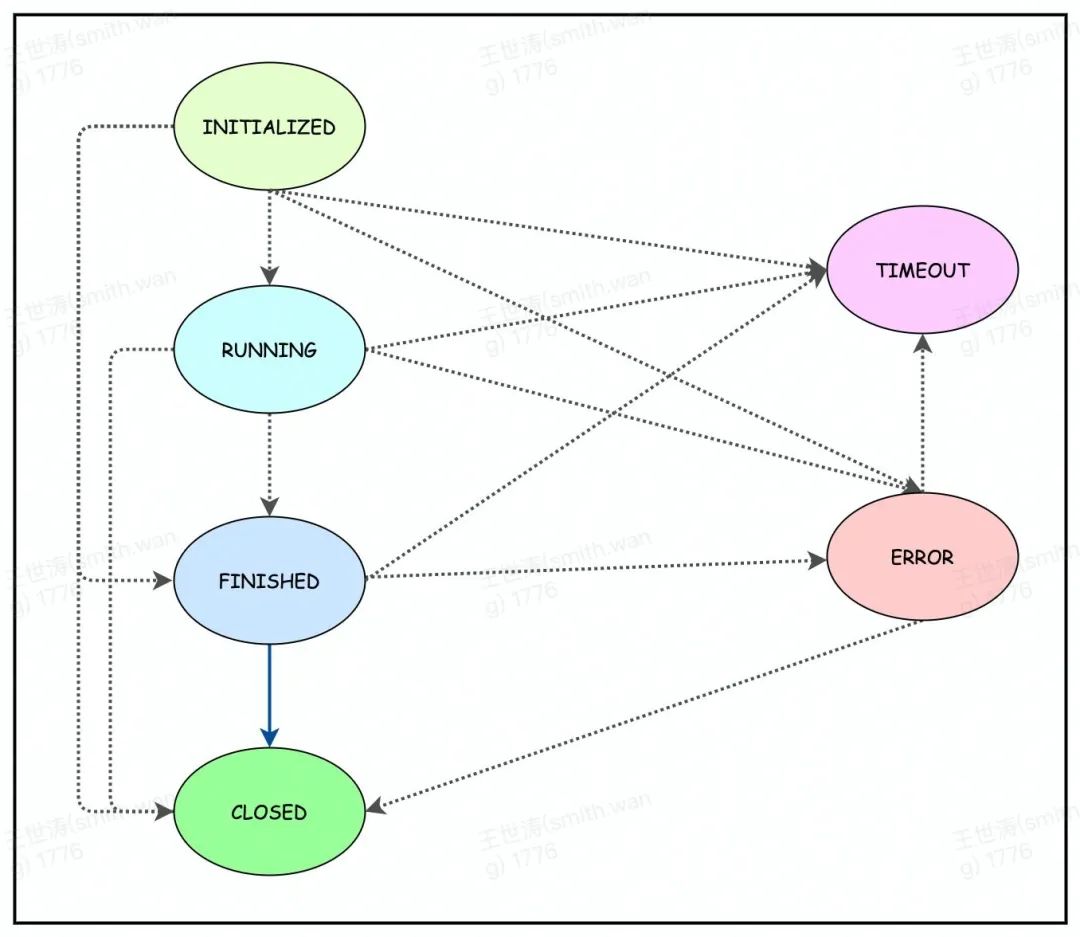
-
1. INITIALIZED:Query向Master申请到资源后被置为INITIALIZED状态,如果一直处于INITIALIZED没有得到Worker的ACK,该资源便会被Master回收掉。
-
2. RUNNING:Query提交到Worker便会被置为RUNNING状态,在多引擎间进行降级继续保持RUNNING状态。
-
3. FINISHED:在目标引擎上执行成功时便会被置为FINISHED状态。
-
4. CLOSED:Client主动close/cancel后便会被置为CLOSED状态。
-
5. TIMEOUT:Query查询达到用户设置超时时间或者该Query已经长时间没有操作。
-
6. ERROR:Query在计算引擎上执行失败且无法降级时便会被置为ERROR状态。
3.3 其他
在这个过程中也发现一些比较有意思的点:
-
1. Client端是根据Query的状态来驱动的,所以在更新Query状态的链路上一定要特别注意,减少不必要的性能损耗。
-
2. HBO服务:用户在一个小时间区间内(例如30min)可能会重复提交的一些SQL,所以可以缓存SQL的路由引擎和最后执行成功引擎等信息(设置一定TTL),这样用户提交重复SQL就不需要再次经过Dispatcher模块了,也可以减少一些时间损耗。
-
3. 引擎间执行方式兼容:比如Hive在SQL执行成功时,计算过程已完成且数据写到HDFS临时目录等待用户读取;但Presto是典型的Pipeline执行模式,数据会像流水一样返回给用户(一边计算一边返回结果),所以就可能会出现当计算结果数据量比较大时,到获取结果的最后阶段才出错。这种情况也需要被服务cover住,所以当数据量较小时,可以全部保存在内存中,但是当发现数据量过大时就需要溢写到磁盘或者外部存储,这样在执行过程中发现错误也能及时进行降级。
4. 上线效果
从2022年1月份上线以来,内部进行了多个版本的迭代,在查询提效这方面也取到了良好的效果。目前ad-hoc 即席查询取数:P65提速82%(50s-> 8s),P75提速64.1%(78s->28s),各个分位的效果提升如下图。
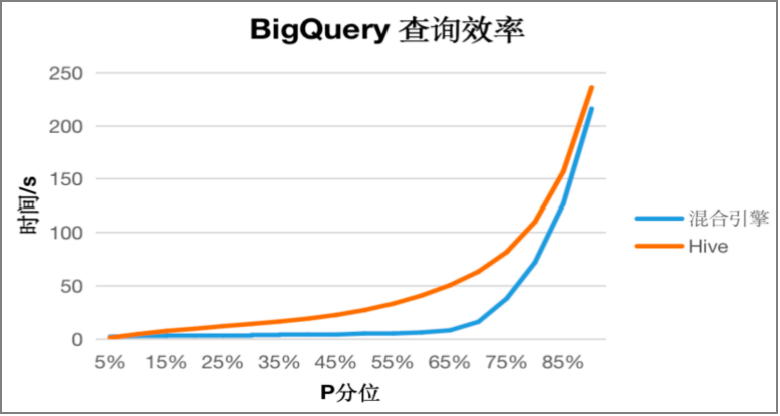
(BigQuery: 货拉拉自研的ad-hoc即席查询工具)
5. 未来规划
数据分析和开发人员更应该关注的是业务逻辑的实现,而不是底层计算引擎的选型与SQL调优。货拉拉离线混合引擎服务的长远规划,旨在为用户提供统一的计算入口,屏蔽掉底层计算引擎的复杂性,降低用户使用门槛,实现业务层与引擎层的解耦。当前混合引擎支持的场景还比较有限,比如不支持ETL和多数据源联邦查询等场景,距离构建统一的计算引擎还有一定的距离。结合业务需求以及技术演进需要,混合引擎的下一步规划,将从以下3个点来开展:
-
1. 更高的查询效率。目前混合引擎实现了对P65简单查询的10秒内响应,但是对于较为复杂的查询,其查询效率并没有得到提升。主要原因是这部分查询不满足路由规则,没有被路由到Presto上去执行。目前的路由规则(比如数据量大小、Join数等阈值)相对比较静态,不会根据引擎的负载情况而调整。后续将对路由规则进行优化,尽可能多的将查询路由到Presto,提升查询效率。
-
2. 支持ETL场景。引入Spark引擎,将离线链路的ETL任务无感迁移到Spark,并且保证任务的稳定性。
-
3. 支持多数据源联邦查询。打通多数据源,实现不同类型数据源(离线数仓、OLAP 数据、在线数据等)的数据联合分析/及时查询的需求,消除不同数据源之间的数据“孤岛”。
笔者介绍:朱耀概|高级大数据工程师,现就职于货拉拉基础架构组从事统一SQL引擎服务开发、大数据自动化运维系统开发以及HBase运维开发,Apache HBase Contributor
本文为从大数据到人工智能博主「bigdata_practitioner」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/13814/