
为贯彻落实工业和信息化部、国家互联网信息办公室、公安部联合印发的《网络产品安全漏洞管理规定》,2021年8月26日,工业和信息化部移动互联网App产品安全漏洞库发布会暨安全漏洞管理特设工作组成立仪式在京举办,旨在充分发挥移动互联网领域相关企业的技术优势,联合业界知名科研机构、高校、安全企业、网络产品提供者、网络运营者等,全力做好移动互联网App产品漏洞收集、认定、修补等工作,提高威胁应对与风险管理能力,保障国家网络安全。漏洞库平台搜集了多个具有相似特征的App产品漏洞,分析App漏洞数据库成为分析相似漏洞特征的一种重要手段。
大数据技术框架的出现给大量数据的存储分析提供了比较好的架构,利用大数据手段对漏洞库进行多维度漏洞数据分析成为一个有意义的研究方向。为了适应漏洞规模大、漏洞数据量激增的情况,利用大数据技术进行漏洞分析势在必行。
相关工作
大数据技术的发展已经产生了基于Hadoop的生态系统,常见的组件有HDFS、MapReduce、Hive、Hbase、Zookeeper、Spark等。目前,漏洞分析的研究一般有静态和动态分析方法,并从自动化到智能化方向发展,而且呈现大数据应用趋势。本文在分析了国内外漏洞分析系统算法现状的基础上,结合移动互联网App产品安全漏洞库平台,设计了基于大数据框架的漏洞分析系统,而后设计了一种漏洞分析算法,并在移动互联网App产品安全漏洞库平台中得到应用,实现了对系统的实时监控与分析。
基于大数据的漏洞分析架构设计
移动互联网App漏洞库系统平台可以分析包含各种类型的App漏洞,如源码安全漏洞、组件安全漏洞、数据安全漏洞、业务逻辑漏洞、服务端安全漏洞等。漏洞系统架构一般包括漏洞采集模块、漏洞存储模块、漏洞分析模块和分析结果展示模块。从图1可以看出,各个客户端通过接口把漏洞信息传送到云端数据采集中心,采集中心通过漏洞数据预处理,将格式化漏洞存储到Hbase库中,同时为了快速地查询处理建立基于ElasticSearch的漏洞索引库。建立Hadoop数据处理中心模块,处理结果通过结果分析模块进行可视化展示,同时把有用模式及规律存入模式库。模式库可以作为Hadoop数据处理中心的部分输入,指导数据处理中心算法的优化及算法训练。其中,客户端可以定期通过基本的HTTP协议传输漏洞协议;数据采集中心通过漏洞的归一化、去重、去噪等规格化数据,然后传输到Hbase存储及ES服务器建立索引;Hadoop数据处理中心可以通过频繁模式算法、聚类算法、分类算法等分析漏洞模式等,然后通过一定人工监控及需求分析把有用的结果加入到模式库,模式库可以作为算法训练的结果反作用于数据处理算法。


基于大数据的漏洞分析算法运行在Hadoop或Spark数据处理中心,为了达到智能漏洞分析识别漏洞模式的目的,可以实施一些数据挖掘相关的算法,如分类、聚类、频繁模式等。
基于大数据的漏洞分析算法及实施步骤
1.基于分布式的漏洞分析算法一般过程
基于分布式的漏洞分析算法一般由单机算法改进而成,在经过漏洞数据采集后,数据存储于漏洞数据库,然后经过数据分片,进入对每个数据分片的数据分析过程。对各个部分模式结果通过一定的规则整合成为模式库。基本过程如图2所示。
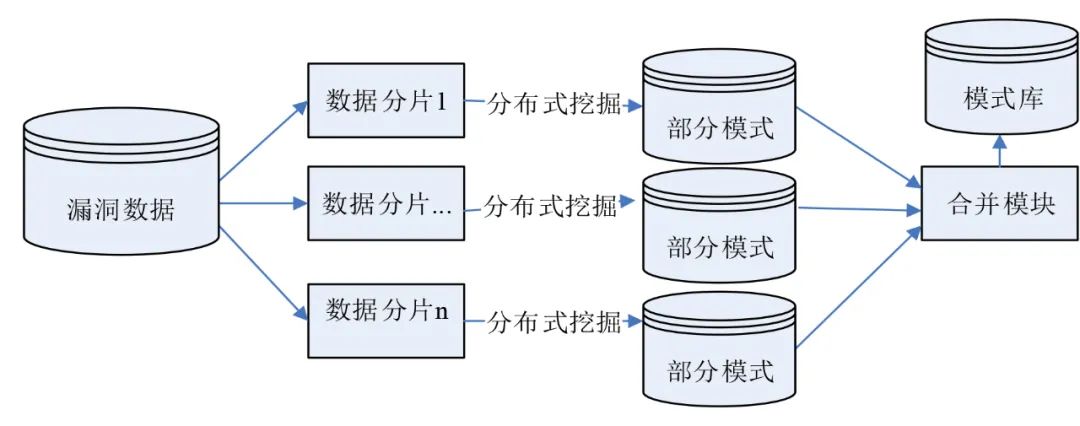
图2 分布式漏洞分析算法
2.基于分类算法的漏洞分析算法
常见的分类算法有决策树、贝叶斯分类、支持向量机、基于关联规则的分类,分类的目的是把一些目标数据划分到已知的类别中去。
决策树是一种常用的有监督的分类算法。监督分类即首先给定一定数量的样本,这些样本都包含相关的属性和类别,通过识别这些属性制作一个分类器,当新的包含相关属性的对象到来时,可以利用该分类器把对象划分到对应的类中。
贝叶斯分类是基于统计学的分类算法。该算法是计算待分类的对象出现的条件下各个类别出现的概率,并且把出现最大概率的类别作为待分类对象的类别。支持向量机也是一个基于统计学的分类算法,是一种二分类模型,是求定义在特征空间上间隔最大的线性分类器。
关联规则的分类是基于频繁模式及支持度与置信度的算法。这种算法求的是支持度及置信度大于给定阈值的对象。关联规则反映了给定数据集上属性和值对之间的强关联关系。
分类算法可以用于漏洞分析。首先,可以采用有监督的分类,通过标记漏洞属性,比如漏洞产生时间、漏洞来源客户端、漏洞接口信息、漏洞关联的App模块等,标记一定量的样本,把漏洞对应的安全问题级别标记为分类类别,制作分类器。然后,对后面采集的漏洞输入分类器进行分类,基本结构如图3所示。

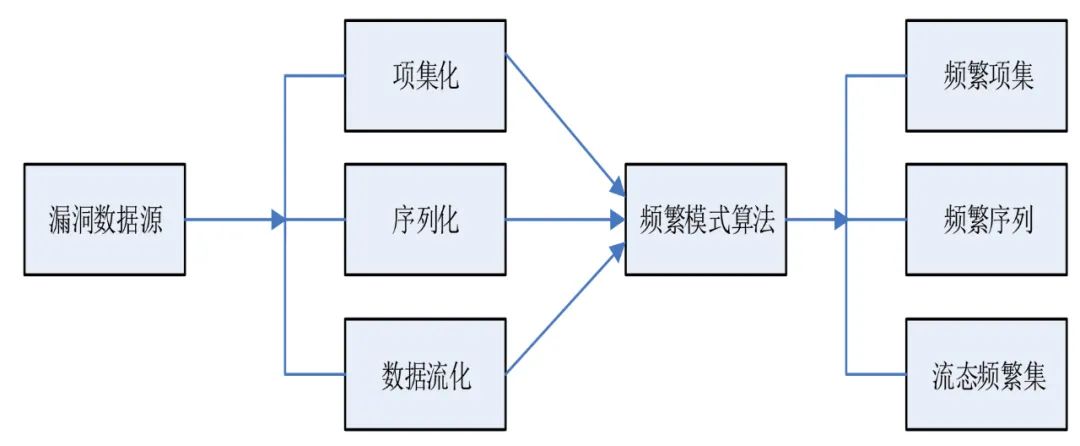
3.基于频繁模式的漏洞分析算法
频繁模式算法也就是求解支持度大于给定阈值的项目的过程。常见的频繁模式算法有基于序列的频繁模式算法,有基于项集的频繁模式算法,也有基于数据流的频繁模式算法。
基于项集的算法的数据来源于事务数据库,每条事务包含的数据也就是完成一次交互所包含的项的集合。通过对事务数据的扫描计算,获取出现频率达到要求的项及项集。常见的有Apriori、FP-Growth算法。
基于序列的算法的数据也是来源于事务型数据库,把执行每项事务所包含的项目进行有序排序组成序列,构成序列数据库,然后扫描序列数据库,获取出现频率达到支持度阈值的序列及其子序列。常见的算法有GSP、Prefix-Span算法等。
有些数据产生的形态不再是静态型的,而是随着时间无限产生,达到了数据流的形态,此时基于数据流的频繁模式算法也就产生了。一般基于数据流的算法可以采用基于时间的滑动窗口,把数据流分成不同的连续的数据片段,然后分别对这些片段进行序列的频繁率统计,获取支持度大于阈值的序列及子序列。同时,为了达到挖掘结果的连续性,也需要用后续数据片段的挖掘结果更新或合并先前的挖掘结果。
基于频繁模式的漏洞分析算法是很有意义的。首先,可以按照时序关系,将漏洞数据库中的漏洞转换成漏洞序列或漏洞项集, 然后统计项或序列的支持度,获取达到阈值要求的序列、项和子序列。其次,通过分析频繁出现的漏洞信息,可以获取系统中频繁使用的模块或时常出现异常问题的软件模块,有助于调整系统维护的重点及优化系统结构,模型结构如图4所示。
4.基于聚类的漏洞分析算法
聚类算法是对目标数据划分类别的过程,与分类算法相区别的是,聚类算法事先不知道数据可以具有的类别,而是通过计算目标对象与聚类中心的相似度,达到类别之内的对象相似度很大,而类别之间的对象相似度很小的目的。聚类分析一般可以分为基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法、基于模型的方法等。
基于划分方法的思路是构建目标数据的K个分类,把目标数据分配到给定的分类中去。首先随机的给定K个划分,把数据随机地分到K个类中,然后根据迭代的方法循环计算数据和类中心的距离,最后根据该距离,把数据重新调整到距离小的类中。为了计算类的中心,一般采用基于中心点的方法和基于K均值的方法。基于中心点的算法是把距离中心点最近的对象作为新的类中心;基于K均值的方法是把类中的平均值作为类的中心。
基于层次的方法可以分为自底向上和自顶向下的算法。自底向上的算法也就是首先每一个待分类对象作为一类,然后通过合并最近的组或对象,直到满足结束条件,如满足组数目的限定。自顶向下的算法是初始化所有的对象为一类,然后通过迭代进行类的分裂。
基于密度的方法的目的是在给定半径的邻域中必须至少包含一定数据的对象,这样可以发现任意形状的分类。基于网格的方法是把目标对象量化成网格结构。基于模型的方法为每个类定义一个数据模型,把具有最佳模型匹配的对象划分到对应的类中。
利用聚类方法可以在不假定类别各个属性的情况下对日志数据完成分类,然后分析类别内具有相似特征的数据达到识别各个系统模块所具有的相似特征或行为,实现系统各个模块问题的统一识别、定位和优化。分析模型如图5所示。
 图5 漏洞数据聚类算法模型
图5 漏洞数据聚类算法模型互联网App产品安全漏洞分析构想
App漏洞又可以分为源码安全漏洞、组件安全漏洞、数据安全漏洞以及业务逻辑漏洞等。组件安全漏洞主要记录Android四大组件或Webview等组件在被调用时未做验证或在调用其他组件时未做验证。漏洞模式挖掘的一种实现方法可以根据Android四大组件或Webview等组件之间的接口调用行为等进行处理。
1.基于App组件调用的漏洞模式分析
App软件漏洞库中收集记录了较大量的组件调用数据,通过组件间的调用行为可以定位和分析App漏洞的来源,分析App组件之间的调用模式可以挖掘App漏洞模式。
组件的调用行为可以用S=来表示。其中,Sn表示组件调用了软件中的某个操作,S表示了App组件调用的操作序列。例如,通过一定时间内的数据采集,可以得到类似表1的序列数据库。
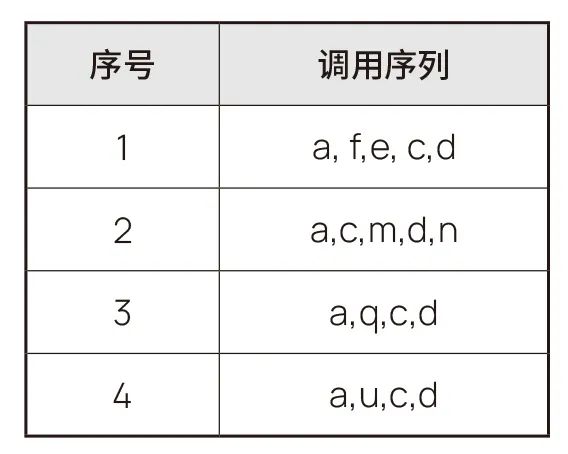
对于表1,可以通过序列模式算法进行分析,假定最小支持度阈值min_sup=50%,项Sn的支持度用Support(Sn)来表示。可以得到Support(a)=Support(a)=Support(c)=Support()=Support()=Support()=Support()=100%>50%。从这个例子可以得知App经常调用的是a,c,d三个操作,这三个操作是具有漏洞App的共同特征,表明这三个操作很可能造造成了软件漏洞。因此,可以通过这种方式查找漏洞模式,对现有的其他App进行软件漏洞预测。
2.基于App接口调用的安全漏洞问题预测
App系统内的接口调用是监控App产品是否稳定的有效手段,系统的访问量、访问频繁度、系统内部接口的响应时间等都是重要的数据采集点。系统的访问频率一般可以通过记录客户机的IP的方式来实现。内部接口的响应时间可以由记录调用的等待时间来确定。
App漏洞库中采集存储了具有漏洞软件的关键接口调用信息,可以通过预处理得到如表2和表3中的漏洞示例数据。其中,客户IP及接口名称为假定数据。
表2表示了客户对系统的访问示例,经过简单的统计可以看出IP为211.155.94.143的客户每1毫秒就访问一次系统,而且连续不停地访问。这样就可以断定系统有被恶意攻击的可能性,即可对访问方式这样的IP进行拦截。
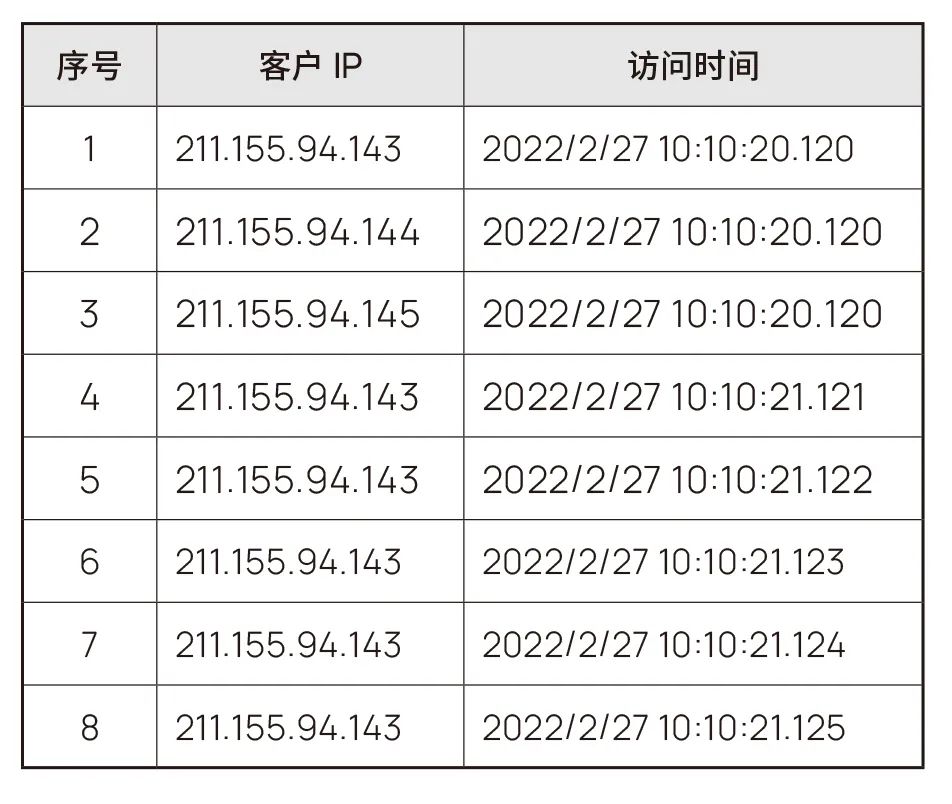
表3表示了接口的访问及返回时间。可以看出,api/login/userset接口发生过两次超时等待,api/login/reset接口的最长等待时间达到了10 s。而其他接口的响应时间在1 s以内。这样就需要重点调整这些接口,进行代码优化、服务器带宽、系统集群等方面的优化。

3.基于大数据的漏洞分析与预测
系统漏洞是监控App产品是否稳定的有效手段。以App漏洞库为漏洞信息的来源,按图1中的大数据架构的漏洞分析模型为依据,阐述一种基于源代码的漏洞应用实例。
首先,从软件漏洞库中采集源代码漏洞信息,特别是厂商提交的漏洞特征,并保存到云端存储于数据处理中心。
其次,对软件漏洞信息进行预处理,规范源代码中的函数成函数调用序列。
再次,利用基于Hadoop或Spark的大数据序列模式算法,挖掘频繁函数调用序列或子序列,得到函数序列模式。
最后,把得到的序列模式存储到模式库,辅助后来的软件开发和软件漏洞信息审核与预测。
结语
漏洞特征的分析算法研究、漏洞关联模式挖掘,成为预测分析App是否存在漏洞的重要方法。本文从大数据漏洞算法分析的角度,提出了移动App漏洞分析、预测和应用的解决方案。首先,分析了基于移动互联网App漏洞库、大数据及漏洞分析系统的研究现状及系统构建形式;其次,给出了一个基于Hadoop、HBase、Spark以及ElasticSearch等技术框架的通用漏洞系统架构模型;再次,给出了分布式漏洞分析算法一般流程及分类、频繁模式、聚类等算法在漏洞系统中的应用;最后,从移动互联网App漏洞库中算法应用的角度给出了App漏洞分析的应用流程及实例,展现了漏洞库建设的作用与优势。
来源:《网络安全和信息化》杂志
作者:中国软件评测中心网络空间安全测评工程技术中心 李维娜
(本文不涉密)
本文转载自网络安全和信息化,原文链接:https://mp.weixin.qq.com/s/RT-3yAW_YF9FAv9q-ESQww。