
概要速览
Meta公司(前“Facebook公司”,下文统称“Meta”)的Presto团队一直在与Alluxio 合作为Presto提供开源数据缓存方案。该方案被用于Meta的多个用例,来降低从诸如HDFS等远端数据源扫描数据产生的查询延迟。实验证明,使用Alluxio数据缓存后,查询延迟和IO扫描都得到了显著优化。
我们发现,Meta架构环境中的多个用例都得益于Alluxio数据缓存。以Meta的一个内部用例为例,其各分位的查询延迟分别下降了33%(P50)、54%(P75)和48%(P95)。此外,远端数据源扫描数据的IO性能提升了57%。
Presto架构
Presto的架构允许存储和计算独立扩展,但是扫描远端存储中的数据可能会产生昂贵的操作成本,也难以达到交互式查询的低延迟要求。
Presto worker只负责对从独立(通常是远端)数据源扫描的数据执行查询计划片段,而不会存储任何远端数据源的数据,因此计算可以进行弹性扩展。
下面的架构图清晰地展示了从远端HDFS读取数据的路径。每个worker都会独立地从远端数据源中读取数据,本文将只讨论对远端数据源读取操作的优化。
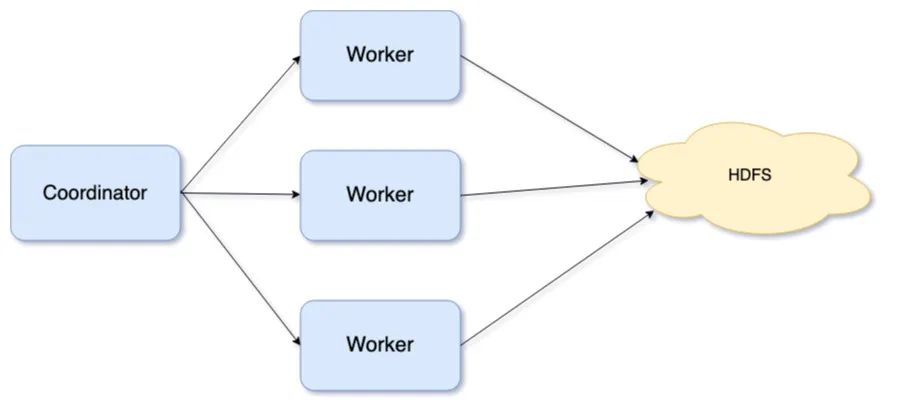

Presto +数据缓存架构
为了解决用例的亚秒级延迟问题,我们决定进行多种优化,其中一个重要的优化就是实现数据缓存。数据缓存作为一种传统的优化方式,能让工作数据集更靠近计算节点,减少对远端存储的访问,从而降低延迟并节约IO开销。
其中的困难在于,如果从远端数据源访问PB级别的数据时没有固定访问模式的话,如何能实现有效的数据缓存,此外,有效数据缓存的另一个要求是在Presto等分布式环境中实现数据的亲和性。
添加数据缓存功能后,Presto的架构如下所示:
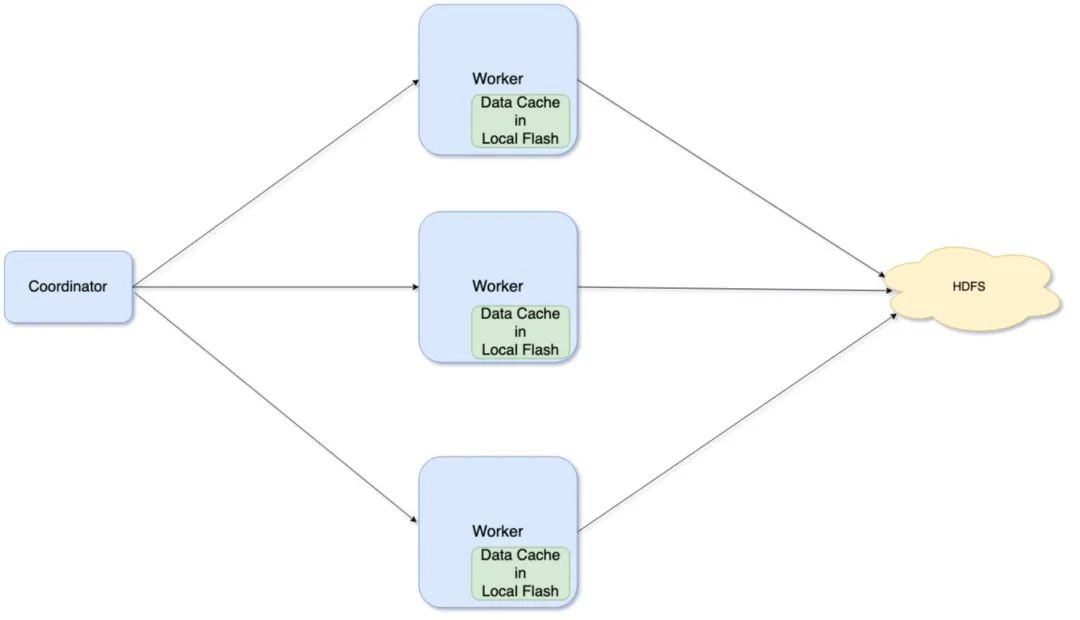
关于数据缓存,后面会有更详细的说明。
软亲和调度
Presto目前的调度器在分配分片时已经把worker的负载纳入考量,因此该调度策略使得工作负载在worker之间均匀分配。但从数据本地性的角度来看,分片是随机分配的,不能保证任何亲和性,而亲和性恰恰是实现有效数据缓存的必备条件。对Coordinator而言,每次把分片分配给同一个worker至关重要,因为该worker可能已经缓存了分片所需的数据。
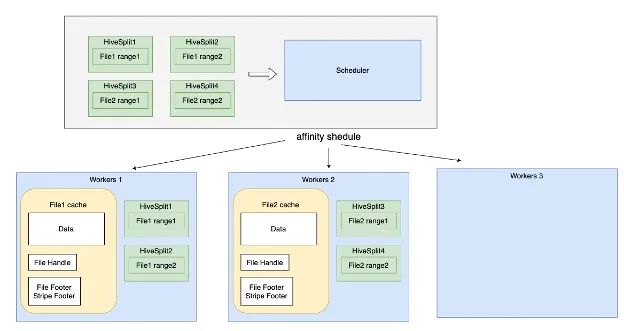
上图说明了亲和性调度是如何给worker分配分片的。
执行软亲和调度策略时,会尽可能将同一个分片分配给同一个worker。软亲和调度器使用分片的哈希值来为分片选择一个首选worker,软亲和调度器:
为分片计算其首选worker。如果首选worker有充足的可用资源,那么调度器会把该分片分配给首选worker。
如果首选worker处于忙碌状态,那么调度器就会选择一个备选worker,如果该备选worker有充足的可用资源,调度器就会把分片分配给它。
如果备选worker也处于忙碌状态,那么调度器就会把分片分配给当前最空闲的worker。

确定一个节点是否忙碌可通过两项配置来定义:
当某一节点上的分片数超过上述任一配置的限制时,该节点就被视为忙碌节点。可以看出,节点亲和性对于缓存的有效性至关重要。如果没有节点亲和性,同一分片可能会在不同的时间被不同的worker处理,这会导致冗余的分片数据缓存。
出于这个原因,如果亲和性调度器没能把分片分配给首选worker或者备选worker(因均处于忙碌状态),调度器就会向被分配的worker发出信号,让其不要缓存分片数据。这意味着只有分片的首选或备选worker才会缓存该分片的数据。
数据缓存
Alluxio文件系统是一个经常用作Presto分布式缓存服务的开源数据编排系统。为了在架构中实现亚秒级的查询延迟,我们希望进一步降低Presto和Alluxio之间的通信开销。因此, Alluxio和Presto的核心团队进行合作, 从Alluxio服务中发展出一个单节点的嵌入式缓存库。
具体而言,Presto worker通过标准的HDFS接口查询位于同一个JVM内的Alluxio本地缓存。当缓存命中时,Alluxio本地缓存直接从本地磁盘读取数据,并将缓存数据返回给Presto;否则,Alluxio将访问远端数据源,并将数据缓存在本地磁盘上,以便后续查询。该缓存对Presto来说是完全透明的。一旦缓存出现问题(如本地磁盘发生故障),Presto还可以直接从远端数据源读取数据,该工作流程如下图所示:
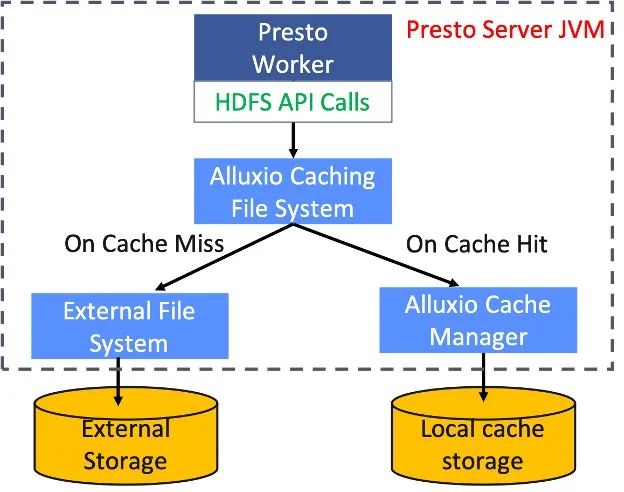
本地缓存的内部构成和配置
Alluxio数据缓存是位于Presto worker节点上的库,它提供了一种与HDFS兼容的接口“AlluxioCachingFileSystem” ,作为Presto worker进行所有数据访问操作的主要接口。Alluxio数据缓存包含的设计选项有:
根据Alluxio的经验以及Meta团队早期的实验,以固定的数据块大小来进行数据读写和清理是最有效的。为了减少元数据服务的存储和服务压力,Alluxio系统中默认的缓存数据块大小为64MB。由于我们采用的Alluxio数据缓存只需要在本地管理数据和元数据,所以我们大大调低了缓存的粒度,把默认缓存粒度设置成大小为1MB的 “page(页面)”。
Alluxio本地缓存默认将数据缓存到本地文件系统。每个缓存page作为单独的文件存储在目录下,目录结构如下:
LOCAL表示缓存存储类型为LOCAL(本地)。Alluxio也支持RocksDB作为缓存存储。
1048576:代表数据块的大小为1MB。
BUCKET作为各种页面文件的bucket的目录。之所以创建bucket是为了确保单一目录下不会有太多的文件,否则可能会导致性能很差。
PAGE代表以页面ID命名的文件。在Presto中,ID是文件名的md5哈希值。
每个Presto worker包含一组线程,每个线程执行不同的查询任务,但共享同一块数据缓存。因此,该Alluxio数据缓存需要具备跨线程的高并发度,以提供高吞吐量。也就是说,数据缓存需要允许多个线程并发地获取同一个page,同时还能在清除缓存数据时确保线程安全。
当worker启动(或重启)时,Alluxio本地缓存会尝试复用已经存在于本地缓存目录中的缓存数据。如果缓存目录结构是兼容的,则会复用已缓存数据。
Alluxio在执行各种缓存相关操作时,会输出各种JMX指标。通过这些指标,系统管理员可以轻松地监控整个集群的缓存使用情况。
基准测试
我们以运行在某个生产集群上的查询来进行基准测试,该集群被当作测试集群来使用。
查询数:17320
集群大小:600个节点
单节点最大缓存容量:460GB
清除策略:LRU
缓存数据块大小:1MB, 意味着数据按1MB的大小读取、存储和清除。
查询执行时间优化(单位:毫秒):
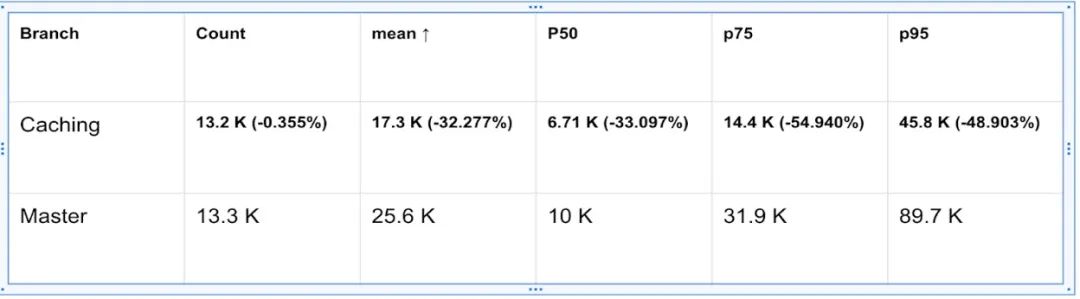
从表格中可以看出,查询延迟有显著改善,其中P50的查询延迟降低了33%,P75降低了54%,P95降低了48%。
Master分支执行过程的总数据读取大小:582 TB
缓存分支执行过程的总数据读取大小:251 TB
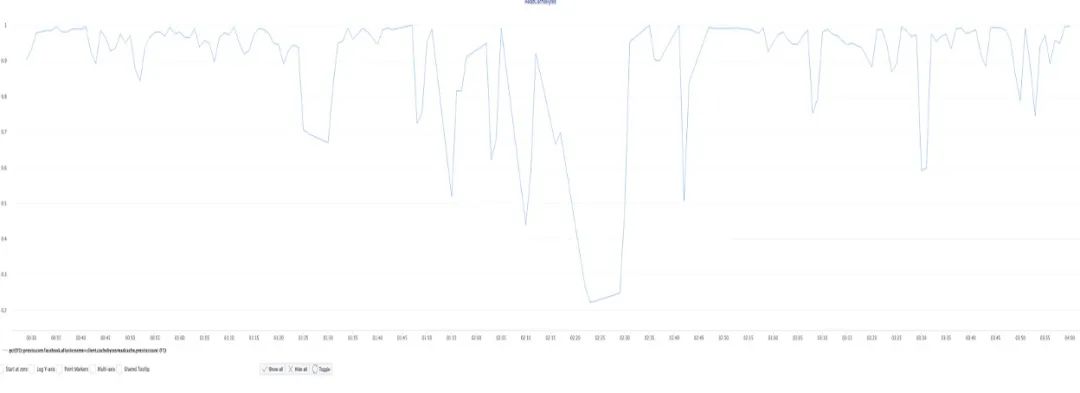
在实验过程中,缓存命中率基本稳定地保持在较高的水平,多数时间维持在 0.9 和 1 之间。中间可能是由于新查询扫描大量新数据的原因出现了一些下降。我们需要添加一些其他算法来防止出现访问不太频繁的数据块相较于访问频繁的数据块更容易被缓存的情况。
如何使用?
使用数据缓存前,我们要做的第一件事就是启用软亲和调度策略,数据缓存不支持随机节点调度策略。
要启用软亲和调度策略,在coordinator 中需要进行如下配置:
“hive.node-selection-strategy”, “SOFT_AFFINITY”
要使用默认(随机)节点调度策略,则设置如下:
“hive.node-selection-strategy”, “NO_PREFERENCE”
要启用Alluxio数据缓存,在worker节点采用如下配置:
Coordinator 配置(可用来配置忙碌worker的定义):
设置单任务最大待定分片数:node-scheduler.max-pending-splits-per-task
设置单节点最大分片数:node-scheduler.max-splits-per-node
Worker 配置:
启用Alluxio缓存指标(默认:true): cache.alluxio.metrics-enabled
Alluxio缓存指标的JMX类名(默认: alluxio.metrics.sink.JmxSink): cache.alluxio.metrics-enabled
Alluxio缓存使用的指标域名:(默认: com.facebook.alluxio): cache.alluxio.metrics-domain
Alluxio缓存是否要异步写入缓存(默认: false): cache.alluxio.async-write-enabled
Alluxio缓存是否要验证已有的配置(默认: false): cache.alluxio.config-validation-enabled
Alluxio数据缓存为其缓存操作输出各种JMX指标。扫描下方二维码查看指标名称的完整列表。

扫码查看
下一步工作
实现通过限速器(rate limiter)控制缓存写入操作的速率,从而避免闪存耐久性问题;
实现语义感知缓存,提高缓存效率;
建立清理缓存目录的机制,用于维护或重新启动。
可执行“dry run”模式
文章贡献者:
Meta:Rohit Jain, James Sun, Ke Wang, Shixuan Fan, Biswapesh Chattopadhyay, Baldeep Hira
Alluxio: Bin Fan, Calvin Jia, Haoyuan Li
原文内容发布于:2020/6/16
本文转载自alluxio,原文链接:https://mp.weixin.qq.com/s/qbFDwo1rPh8OUWDyheCvew。