
你曾经使用过pandas的 pd.read_csv() 吗?如果你使用 parquet 而不是 CSV,那么该命令的运行速度可能会快约 50 倍[1]。


在这篇文章中我们将讨论 Apache Parquet,一种极其高效且得到良好支持的文件格式。这篇文章面向数据从业者(ML、DE、DS),因此我们将专注于高级概念并使用 SQL 来讨论核心概念,但可以在整个帖子和评论中找到更多资源的链接。
Apache Parquet 是一种开源文件格式,可提供高效的存储和快速的读取速度。它使用混合存储格式,顺序存储列块,在选择和过滤数据时提供高性能。除了强大的压缩算法支持(snappy、gzip、LZO[2])之外,它还提供了一些巧妙的技巧来减少文件扫描和编码重复变量。
如果关心速度,则可以考虑Parquet。下面讨论为何考虑Parquet?
1. 数据存储问题
假设我们是数据工程师,正在寻求创建一个促进在线分析流程 (OLAP) 的数据架构,这些流程只是针对数据分析的选择性查询。在 OLAP 环境中优化的数据功能的一些示例是探索性数据分析或决策科学。但是我们应该如何将数据存储在磁盘上呢?
在考虑转换时有很多考虑因素,但对于 OLAP 工作流,我们主要关心两个……
- • 读取速度:我们从二进制文件中访问和解码相关信息的速度有多快
-
• 磁盘大小:二进制文件需要多少空间
请注意文件压缩算法还有其他衡量成功的标准,例如写入速度和元数据支持,但我们现在只关注上述两个。那么 Parquet 相对于 CSV 文件的性能如何?它占用的空间减少了 87%,查询速度提高了 34 倍(1 TB 数据,S3 存储)— src[3]
2. Parquet 核心功能
Parquet 如何比 CSV 和其他流行的文件格式更有效呢?第一个答案是存储布局……
2.1. 混合存储布局
当我们将二维表转换为 0 和 1 的序列时,我们必须仔细考虑最优结构。应该写第一列,然后是第二列,然后是第三列吗?还是我们应该顺序存储行?传统上,有三种主要布局转换二维表:
-
• 基于行(Row-based):顺序存储行 (CSV)。
-
• 基于列(Column-based):顺序存储列(ORC)。
-
• 基于混合(Hybrid-based):顺序存储列块(Parquet)。
我们可以在图 2 中看到每种格式的图形表示。
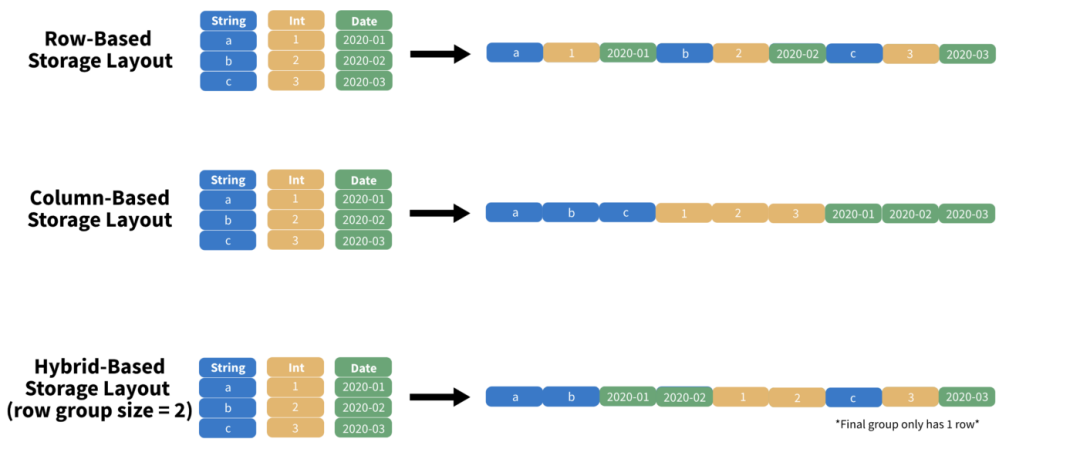
混合布局对于 OLAP 工作流非常有效,因为它们同时支持Projection投影和Predicates谓词。
Projection投影是选择列的过程——可以将其视为 SQL 查询中的 SELECT 语句。基于列的布局最好地支持投影。例如如果我们想使用基于列的布局读取表的第一列,我们可以只读取二进制文件中的前 n 个索引,反序列化它们,然后将它们呈现给用户,效率非常高。
Predicates谓词是用于选择行的条件——可以将其视为 SQL 查询中的 WHERE 子句。基于行的存储最好地支持谓词。如果我们想要根据某些条件(例如 Int >= 2)的所有行,我们可以按 Int(降序)对我们的表进行排序,扫描直到我们的条件不满足,然后返回该无效行之上的所有行。
在这两种情况下,我们都希望尽可能少地遍历文件。而且由于数据科学通常需要对行和列进行子集化,基于混合的存储布局为我们提供了列式和基于行的文件格式之间的中间地带。注意Parquet通常被描述为列存。但是由于它存储列块,如图 2 底部所示,混合存储布局是更准确的描述。因此如果我们想要提取数据,我们可以只存储连续的列块,通常可以获得非常好的性能。但是这种方法可以扩展吗?
2.2 — Parquet 元数据
Parquet 利用元数据跳过可以根据我们的谓词排除的部分数据。

以图 3 中的示例表为例,我们可以看到我们的RowGroup行组大小为 2,这意味着我们存储给定列的 2 行、下一列的 2 行、第三列的 2 行,依此类推。
在我们用完列之后,我们移动到下一RowGroup组行。请注意我们在上表中只有 3 行,因此最后的RowGroup行组将只有 1 行。
假设我们实际上在RowGroup行组中存储了 100,000 个值而不是 2。如果我们要查找 Int 列具有给定值(即相等谓词)的所有行,最坏的情况将涉及扫描表中的每一行。
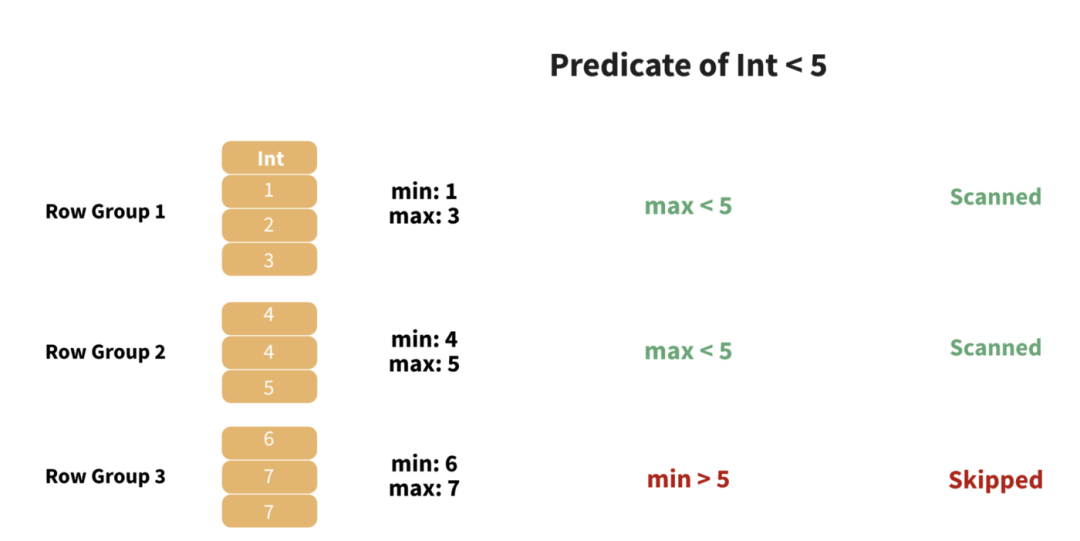
Parquet 通过存储每个行组的最大值和最小值解决了这个问题,允许我们跳过整个RowGroup行组,如图 4 所示。但这只是一部分!由于 Parquet 经常将许多 .parquet 文件写入单个目录,因此我们可以查看整个文件的列元数据并确定是否应该对其进行扫描。
通过包含一些额外的数据,我们能够跳过数据块并显着提高查询速度。有关更多信息请参见此处[4]。
2.3 — Parquet 文件结构
所以我们已经了解了数据是如何从二维格式转换为一维格式的,但是整个文件系统是如何构建的呢?
如上所述,Parquet 一次写入可以写入许多 .parquet 文件。对于小型数据集,可能应该在写入之前对数据重新分区,对于较大数据集,将数据子集写入多个文件中可以显着提高性能。
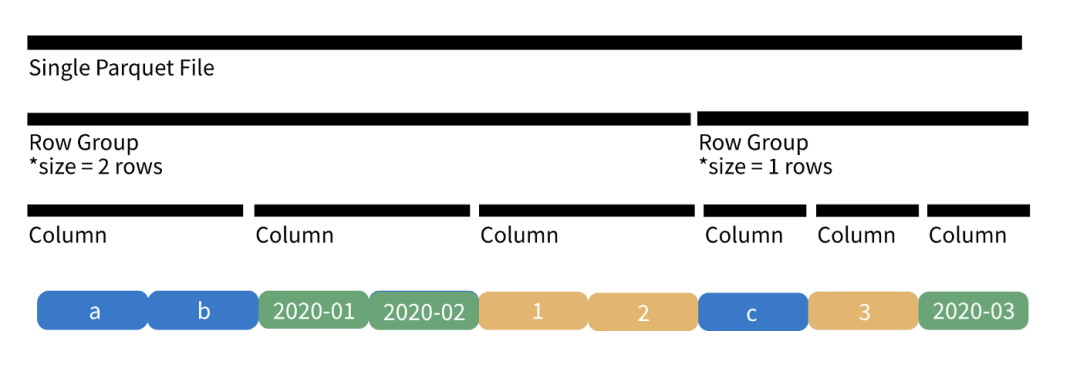
总体而言 Parquet 遵循以下结构
Root > Parquet Files > Row Groups > Columns > Data Page
首先文件根目录只是一个包含所有内容的目录。在根目录中有许多单独的 .parquet 文件,每个文件都包含我们数据的一个分区。一个 parquet 文件由许多RowGroup行组组成,一个RowGroup行组包含许多列。最后在列中是数据页,它实际上保存了原始数据和一些相关的元数据。
我们可以在下面的图 4 中看到单个 .parquet 文件的简化表示
如果你对细节感到好奇,可以参考文档[5]。 重复Repetition和定义级别definition levels[6]对于充分理解数据页的工作方式必不可少。
3. 其他优化
自 2013 年问世以来,Parquet 变得更加智能。底层结构与上述格式基本没有变化,但添加了许多可以提高某些类型数据性能的特性。
3.1. 数据有很多重复值!
解决方案:游程编码Run-length Encoding (RLE)[7]
假设我们有一列包含 10,000,000 个值,但所有值都是 0。要存储此信息,我们只需要 2 个数字:0 和 10,000,000 — 值和它重复的次数。
RLE 就是这样做的。当发现许多连续重复时,Parquet 可以将该信息编码为对应于值和计数的元组。在我们的示例中,这将使我们免于存储 9,999,998 个数字。
3.2. 数据变化非常大
解决方案:使用 Bit-Packing[8] 进行字典编码[9]
假设我们有一列包含国家名称,其中一些很长。如果我们想存储“刚果民主共和国”,我们需要一个可以处理至少 32 个字符的字符串列。
字典编码用一个小整数替换我们列中的每个值,并将映射存储在我们数据页的元数据中。当在磁盘上时,我们的编码值被打包以占用尽可能少的空间,但是当我们读取数据时,我们仍然可以将列转换回其原始值。
3.3. 数据使用复杂的过滤器
解决方案:投影和谓词下推[10]
在 Spark 环境中我们可以通过投影和谓词下推避免将整个表读入内存。因为 Spark 操作是惰性求值的,这意味着它们在我们实际查询数据之前不会执行,所以 Spark 可以将最少数量的数据拉入内存。快速提醒一下,谓词作用于行和投影作用于列。因此如果知道只需要几列和行的一个子集,实际上不必将整个表读入内存——它在读取过程中被过滤。
3.4. 有很多不同的数据
解决方案:Deltalake[11]
最后 Deltalake 是一个开源的“Lakehouse”框架,它结合了数据湖的动态特性和数据仓库的结构。如果计划使用 Parquet 作为组织数据仓库的基础,那么 ACID 保证和事务日志等附加功能非常有用。
概括
Parquet 是一种非常有效的文件格式,适合实际使用。它在最小化表扫描并将数据压缩到小尺寸方面非常有效。如果您是数据科学家,Parquet 可能应该是首选文件类型。
引用链接
[1] 快约 50 倍: [https://towardsdatascience.com/how-fast-is-reading-parquet-file-with-arrow-vs-csv-with-pandas-2f8095722e94](https://towardsdatascience.com/how-fast-is-reading-parquet-file-with-arrow-vs-csv-with-pandas-2f8095722e94)[2] snappy、gzip、LZO: [https://stackoverflow.com/questions/35789412/spark-sql-difference-between-gzip-vs-snappy-vs-lzo-compression-formats](https://stackoverflow.com/questions/35789412/spark-sql-difference-between-gzip-vs-snappy-vs-lzo-compression-formats)[3] src: [https://towardsdatascience.com/csv-files-for-storage-no-thanks-theres-a-better-option-72c78a414d1d](https://towardsdatascience.com/csv-files-for-storage-no-thanks-theres-a-better-option-72c78a414d1d)[4] 参见此处: [https://parquet.apache.org/docs/file-format/metadata/](https://parquet.apache.org/docs/file-format/metadata/)[5] 文档: [https://parquet.apache.org/docs/file-format/](https://parquet.apache.org/docs/file-format/)[6] 重复Repetition和定义级别definition levels: [https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet](https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet)[7] 游程编码Run-length Encoding (RLE): [https://en.wikipedia.org/wiki/Run-length_encoding#:~:text=Run%2Dlength%20encoding%20(RLE),than%20as%20the%20original%20run.](https://en.wikipedia.org/wiki/Run-length_encoding#:~:text=Run%2Dlength%20encoding%20(RLE),than%20as%20the%20original%20run.)[8] Bit-Packing: [https://parquet.apache.org/docs/file-format/data-pages/encodings/#a-namerlearun-length-encoding–bit-packing-hybrid-rle–3](https://parquet.apache.org/docs/file-format/data-pages/encodings/#a-namerlearun-length-encoding–bit-packing-hybrid-rle–3)[9] 字典编码: [https://stackoverflow.com/questions/64600548/when-should-i-use-dictionary-encoding-in-parquet](https://stackoverflow.com/questions/64600548/when-should-i-use-dictionary-encoding-in-parquet)[10] 投影和谓词下推: [https://stackoverflow.com/a/58235274/3206926](https://stackoverflow.com/a/58235274/3206926)[11] Deltalake: [https://docs.databricks.com/delta/index.html](https://docs.databricks.com/delta/index.html)
本文转载自小漫 漫谈大数据,原文链接:https://mp.weixin.qq.com/s/NNsdqm2qGTuzagGFjFWgrA。