


1. 背景
1.1 整体架构
腾讯广告系统中的日志数据流,按照时效性可划分为实时和离线,实时日志通过消息队列供下游消费使用,离线日志需要保存下来,供下游准实时(分钟级)计算任务,离线(小时级/天级/Adhoc)分析处理和问题排查等基于日志的业务场景。因此,我们开发了一系列的日志落地处理模块,包括消息队列订阅 Subscriber,日志合并,自研 dragon 格式日志等,如下图所示:

-
Subscriber:Spark Streaming 任务,消费实时数据,落地到 HDFS,每分钟一个目录,供下游准实时 Spark Streaming 计算任务使用;
-
日志合并:小时级 Spark 批处理任务,合并分钟级日志到小时级日志并进行压缩,解决分钟级日志的小文件和低压缩比等问题,供下游天级/小时级 Spark 任务使用;
-
Dragon转换:天/小时级 MapReduce 任务,dragon 是自研的基于 Parquet 的列存文件格式,重点针对广告日志 Protobuf 格式数据的多嵌套层级做了定制优化,同时具有列存压缩比高,支持按列查询访问等优势,用于3个月以上的长期日志存储。
1.2 问题和不足
随着广告业务的发展,广告日志量逐渐增大,日志使用方逐渐增多,现有的方案遇到了如下问题:
-
日志种类多,从时效性上看有分钟级/小时级,日志的格式除了 dragon,分钟级和小时级的存储格式也不相同,开发人员想分析日志或排查问题时,需要理解不同的 HDFS 目录 + 对应的时间范围 + 对应的日志格式,总而言之,日志不统一,使用复杂,容易出错,易用性差。此外,同一份日志数据,存在分钟级/小时级/dragon等多个副本,存储冗余,同时也需要中间做日志转换的计算资源。
-
性能和资源,广告日志有众多的下游使用方,各个使用方根据组织架构和运营场景的不同,往往只关注一部分日志,举例来说,微信广告的开发和运营同事只关注微信流量上的广告事件,或者进一步细分为朋友圈,公众号,小程序等某组广告位的广告事件,QQ流量的同事也会分为 QQ 空间,腾讯视频,腾讯新闻等等。对于业务关注的这部分日志来说,也只关注全部字段中的一小部分。由于 dragon 日志的高延迟,例行化的下游任务和日常的问题排查分析一般都是基于分钟级 + 小时级的日志。因此,大量不相关的日志数据和字段在计算任务中被加载解析后直接被过滤掉,日志访问缺乏有效的裁剪(data/column pruning)等优化手段,性能差,资源利用率低。
-
日志生态和管理,自研的 dragon 格式和一些查询辅助工具,缺乏长期的支持和优化,无法接入公司的大数据生态和工具平台。使用方直接通过具体的 HDFS 路径访问,导致日志路径升级下线等需要广播周知,下游使用方配合切换,成本极高。此外,大量任务使用相同的账号和鉴权,缺乏权限管理/敏感数据管理/访问审计等治理手段。
2. 广告日志数据湖
2.1 离线改造方案

针对现有架构遇到的问题,我们调研并建设了基于数据湖 Iceberg 的方案,在原有的分钟级日志的基础上,引入小时级 Spark 入湖任务,主要的工作和改造:
A、新建数据湖表,即 Iceberg 表 schema 的设计,除了支持广告业务字段外,重点是数据分区的规划如下:
-
一级分区小时时间 YYYYMMDDHH;
-
二级分区流量站点集集合,即把不同的流量分开,微信流量,联盟流量,视频流量等;
-
三级分区广告位集合,同一站点集下数据可以进一步划分,例如微信流量,可以进一步划分为朋友圈,公众号,小程序等,相应地开发运营同事可以方便的读取所需的数据,广告位集合的划分规则由各个流量侧的同事指定,后续可以随时按需调整。
B、Spark 入湖任务,读取1小时的 HDFS 分钟级日志 + ETL + 入湖。任务入湖采用 overwrite 模式,一次写入一个小时的完整数据,保证任务的幂等性。下游各个使用方基于数据湖表,可以方便的通过 SQL/Spark 来读取数据,无需关心数据的存储位置和格式,大大简化日志的使用。
C、读取优化,除了上面提到的数据分区外,针对常用的查询访问模式,持续构建数据湖中数据列的 metrics,可以支持 Iceberg 文件层级的过滤。同时,数据湖底层采用 parquet 文件,配合 Spark SQL 化的访问接口,很自然的支持了按列的访问(projection pushdown)和过滤(filter pushdown),能在多个层级(分区,文件,parquet row group)快速过滤掉无关的文件和数据,优化资源使用。
2.2 实时化改造 – 实时湖仓
在项目建设初期,我们选择了小时级入湖,没有急于上线实时入湖,主要基于下面几点考虑:
A、基于分区设定,小时入湖可以做到幂等性,批量一次性覆盖写入,方便调试和测试,快速打通上线基于数据湖的日志数仓,供下游体验使用;
B、广告日志数据量大,实时写入数据湖的方案难度和风险比较大,实时写入的性能和稳定性都是未知的,如何保证数据不重不漏,如何在任务重启(任务异常,发布重启)时保证数据不重不漏,如何变更 Iceberg 表的 schema 等等;
C、数据正常写入数据湖后,下游使用方如何消费数据湖表的增量数据,小文件问题如何解决,是否影响查询性能,整体存储成本上涨多少,小文件过多对底层 HDFS 集群压力如何。
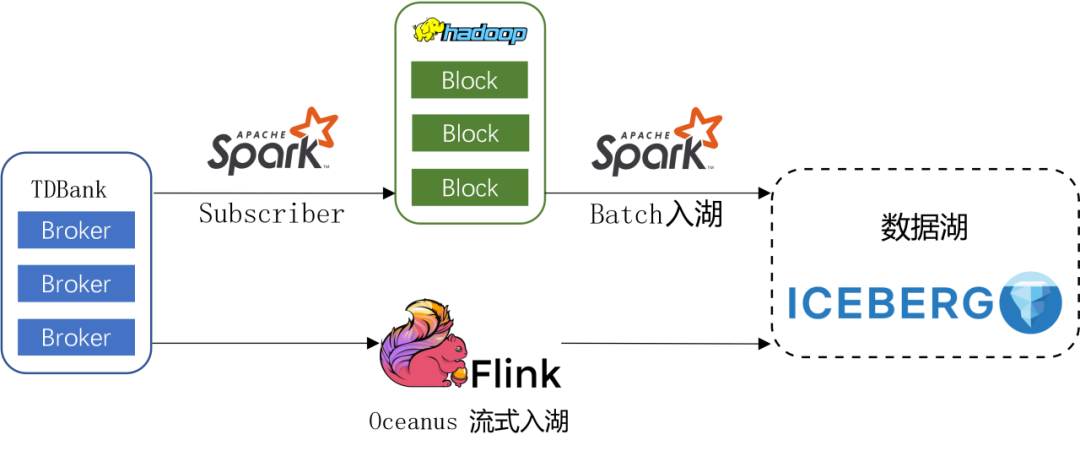
针对这些考虑点,结合 Spark batch 入湖积累的经验,我们建设了基于 Flink 的实时入湖链路,如下图所示:
-
基于 Flink 的分钟级入湖任务,实时消费消息队列 + ETL + 写入数据湖,基于 Flink Checkpoint 机制,可以做到 exactly-once,任务异常和重启时都能保证数据的准确性和实效性。除了表数据更加实时外,下游也可以基于 Iceberg 的增量数据,在 Spark/Flink 中实现分钟级的计算更新。
-
原有的 Spark 小时入湖任务仍然保留,用于数据重跑,数据修复,历史数据回刷等场景,完整的一次性覆盖写入一个小时分区的数据。
-
接入数据湖的自动优化服务,后台异步处理小文件合并,孤儿文件删除,表生命周期管理等维护清理工作,持续优化数据的存储和查询性能。
2.3 湖仓一体方案的优势
原子性保证
之前采用Spark批量写入数据,如果需要修改数据(如补录数据)原子性是无法保证的,也就是说如果有多个Job同时Overwrite一个分区,我们是无法保证最终结果的正确性。如果用户同时进行任务查询,也有可能读到不完整的数据。Iceberg表的所有修改都提供了很好的原子性保证,提供了Serializable的隔离级别。并且提供了时间旅行,可以查询修改之前的历史数据。
统一的数据存储
不同于之前的方案将数据采用不同的格式存储且分散在不同的HDFS路径上,在数据入湖后数据统一存储在数据湖中,用户不需要关心底层的数据格式,对用户暴露出来是统一的表。并且由于Iceberg对底层的存储层做了抽象处理,所以表的管理者可以灵活的修改表的IO层相关的参数,比如修改压缩算法,修改存储Format(支持Parquet, ORC, AVRO),修改表的存储路径等。并且这些底层的修改对上层的用户来说都是无感知的。
列式存储更高的压缩比和更好的查询优化
Iceberg底层的存储Format默认采用的Parquet格式,采用列式的存储格式可以提供更好的压缩比,节省存储成本。并且可以根据查询语句进行列剪枝和谓词下推,这些方法都可以在Plan Task时就尽可能的过滤掉无关的文件。
灵活的Schema Evolution和Partition Evolution
Schema Evolution: 由于广告业务复杂度高,日志数据的一大特点就是字段特别多,需要根据用户的需求进行增加或者删除列字段,所以Schema需要经常改动。这就需要数据湖能提供完整的表schema变更(add/delete/update)能力,并且对用户做到透明。而Iceberg已经具备了此能力,我们可以很方便的通过SQL/Java API的方式修改表的schema,并且不会影响已有用户的查询任务。
Partition Evolution:在数仓或者数据湖中一个加速数据查询很重要的手段就是对数据进行分区,这样查询时可以过滤掉很多的不必要文件。Iceberg的分区字段同样是可以修改的(add/delete/update),并且做到对用户透明。这就给表的管理者对表结构进行优化升级留有了很大的空间,可以根据需要和业务发展来调整分区结构。
多引擎支持
Iceberg是一个开放的Table Format,对存储层和计算层都做了很好的抽象,所以不同的计算引擎都可以通过对应的接口实现表的读写,并且支持流式引擎和批处理引擎对同一张表操作。当前天穹系统支持Iceberg的引擎有:Spark,Flink,Presto,StarRocks。可以根据查询要求和计算任务的复杂度选择不同的引擎,如在IDEX上用Presto查询时效性要求较高的语句,用Spark执行一些计算量很大的ETL任务,用Flink进行流式任务计算。
3. 湖仓一体方案遇到的挑战和改进
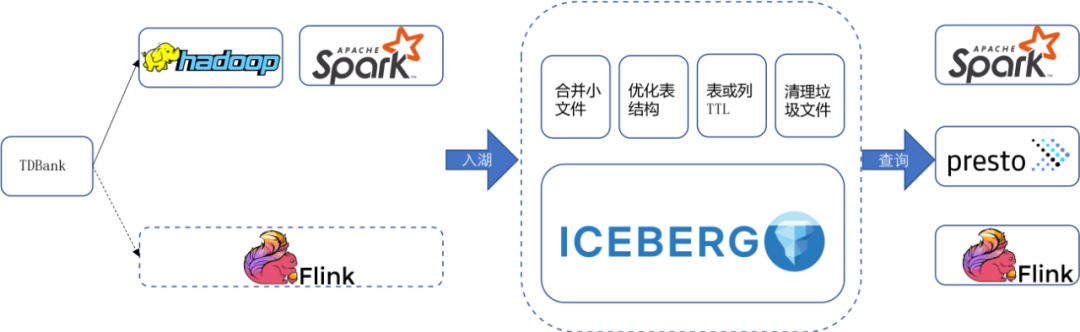
日志数据从各个终端写入消息队列,然后通过Spark批写入或者Flink流式(开发中)写入数据湖,入湖的数据可以通过Spark/Flink/Presto进行查询分析。同时数据湖还提供了异步的优化任务:合并小文件,优化表结构,表级别/列级别的TTL,清理垃圾文件等服务。
接下来我们从入湖,湖上分析和优化服务三个方面介绍我们遇到的问题和改进。
3.1 入湖
优化commit时的内存占用
在介绍流程前,我们先简单介绍下Iceberg文件的组织结构。Iceberg的每个文件由DataFile表示,DataFile存有该文件的Format(Parquet/ORC/Avro),文件存储位置,Partition Value,Column Stats(每个列的MIN-MAX等信息)等。多个DataFile合并为一个ManifestFile,ManifestFile存有该文件的位置,所有DataFile的Partition Value的摘要信息(Partition Value MIN-MAX信息)和一些统计信息等。
如下图所示,Spark从HDFS读取source数据,切分成多个Task,每个Task会根据Table Property设置的每个DataFile的大小生成一个或者多个DataFile,每个Task的返回结果就是一个或者多个DataFile结构。Spark Driver在收集到所有的DataFile后,首先将多个DataFile结构写入到一个ManifestFile里,然后生成一个由多个ManifestFile组成的Snapshot并Commit到Catalog。
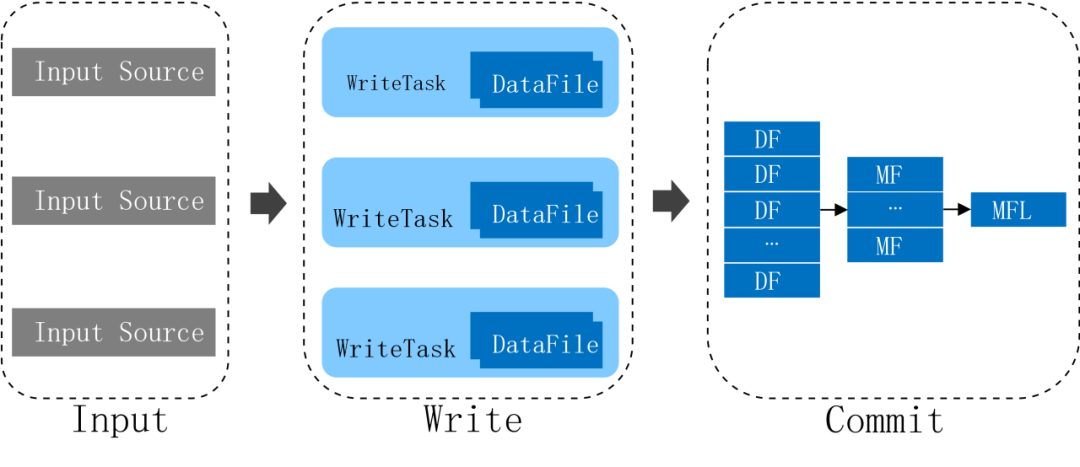
当前日志数据是每一小时进行一次入湖操作,数据量较大,所以生成的DataFile数量特别多,并且由于DataFile存有Column Stats,列越多DataFile占用的内存就越大,因此当前这种持有所有DataFile再commit的操作需要Spark Driver的内存设置的特别大,否则很容易出现OOM。为此我们实现了如下的Commit By Manifest:
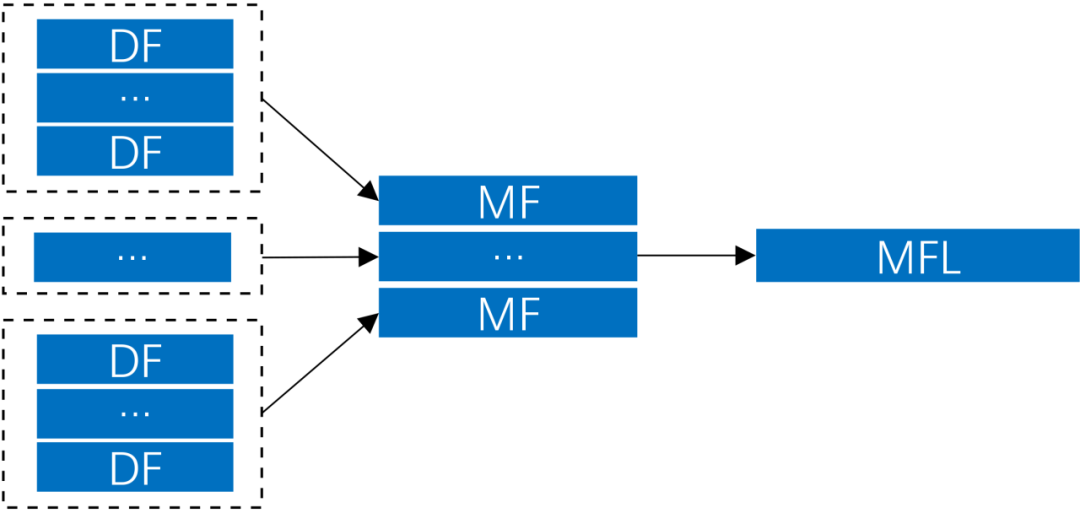
Spark Driver端并不是等到所有的DataFile都收集到才会commit,而是把收集到的DataFile先写入ManifestFile,然后继续后面的步骤,这样改进后Driver的内存需求大幅下降。用户可以通过参数控制是否开启:
spark.sql.iceberg.write.commit-by-manifest = true; // 默认是false优化入湖任务生成的文件数量
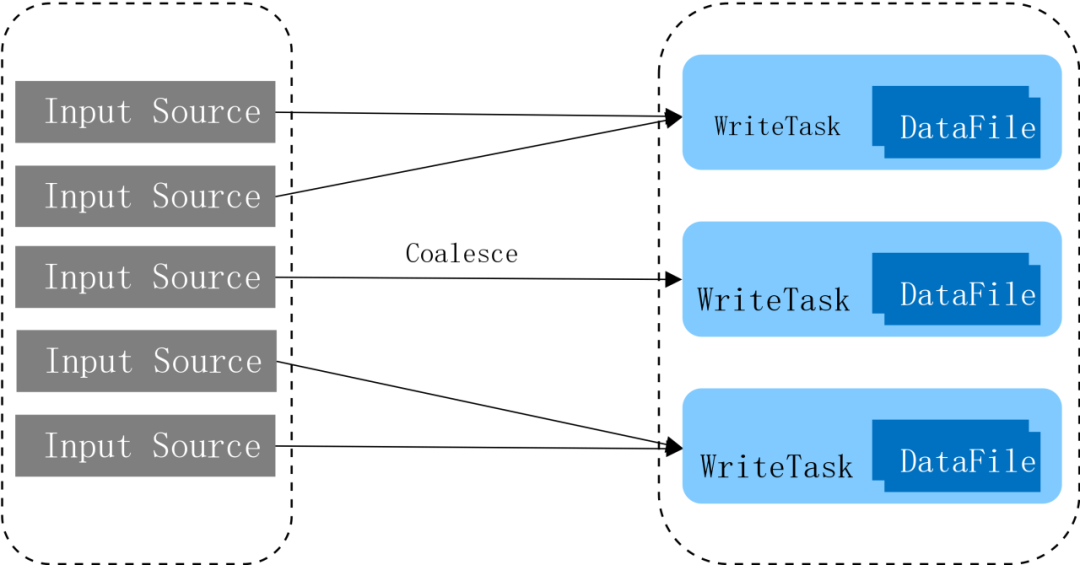
上面提到当前日志入湖是从HDFS读取数据写入到数据湖,Spark读取source数据切分成Task,每个Task的输入数据大小约等于HDFS Block Size。由于数据湖表设置有分区,所以输入的数据会根据分区设置生成多个文件,如果设置有N个分区字段,往往生成的文件个数就会是任务个数的N倍。一个HDFS Block Size大小的文件会切分成了多个小文件,不仅影响了读的性能,也因为HDFS文件个数的激增增加了HDFS NameNode压力。刚开始我们采用Iceberg提供的小文件合并服务来解决这个问题,但是由于数据量太大和文件数量过多,我们发现自动合并小文件服务占用了太多的计算资源,因此需要从源头上解决这个问题。所以我们在读取Source数据后加上一个coalesce,来控制写入Iceberg的任务个数,以此来控制一个Batch写入生成的文件个数。通过这个改进单次Batch写入生成的文件数量减少了7倍左右。
3.2 湖上查询分析
首先我们简单介绍下Spark读取Iceberg表的流程,Spark引擎分析和优化SQL语句得到物理执行计划,在DataSource端进行任务执行时会将SQL涉及到的列和过滤条件下推到Iceberg表。前文提到Iceberg表中的ManifestFile和DataFile存有Partition信息和列的统计信息,所以过滤条件可以用这些信息进行文件过滤,并且在文件上进一步进行列剪枝。我们将文件信息展示在Spark Log里。
22/08/19 14:50:04 INFO util.CloseableIterableWithFilterMetrics:MANIFEST_DATA File Filter (Filtered: 1684, Total: 1731)-- Filter by: ManifestMetrics, filtered: 168422/08/19 14:50:04 INFO util.CloseableIterableWithFilterMetrics:DATAFILE File Filter (Filtered: 11062771, Total: 11063575)-- Filter by: PartitionFilter, filtered: 97763-- Filter by: ManifestMetrics, filtered: 10965008
改进Iceberg Task Plan减少Task个数
日志表的列数很多(目前已经超过1000列,还在持续增加中),并且顶级列只有21个,所以是一个复杂的嵌套类型的表结构。Iceberg表默认采用Parquet作为底层数据的存储格式,Parquet是一种列式的存储结构,其存储结构如下:

Parquet本身对列式数据就做了很好的支持,比如列式数据可以获得更好的压缩比,更好的列剪枝等。但是在日志平台用户的测试和使用中依然发现了一些问题:
B、表的Schema中有很多字段是嵌套类型的,但是在Spark 2.X版本对嵌套类型的谓词下推和列剪枝支持的不是很好,在实际的查询中发现读了很多不必要的数据。
针对问题A,解决问题的办法很明显,就是让一个Task多读点数据,这样可以避免任务调度带来的开销,也可以避免每个Task的主要耗时都在频繁的打开文件。目前有两种做法:
-
可以在读取时设置Spark DataFrameReader的option参数:read.split.target-size,默认是128MB,可以设置大点,比如256MB。在我们的测试中有40%的性能提升。
-
当前Iceberg在Plan Task时只是根据 read.split.target-size 对文件进行切分,但是实际上并不是所有列都需要读取。所以我们在进行Task Plan时可以加入column stats,这样可以把多个小的split合并到一个大的split,来实现1的目的,并且根据stats来实现,更为准确。目前这个方案正在开发中。
针对问题B,目前天穹的Spark 3.1.2已经可以很好的支持的嵌套类型的谓词下推和列剪枝了,我们在Spark 3.1.2上跑同样的query,对比Spark 2.4.6有6倍的性能提升。但是考虑到很多业务代码都还依赖于Spark2的代码,日志平台的同事将一些分区字段由嵌套字段调整到了顶端字段,可以一定程度上缓解该问题。当然更高效的解决办法依然是升级到Spark 3.X上。
优化Schema Evolution对文件过滤的影响
前文提到我们会时常对表的列进行更改,比如我们对Table添加一个列: ,当我们写入数据时,表中的数据可以分为如下两部分:在添加字段前已经存在于表的数据Old Data,在添加字段后写入的数据New Data。
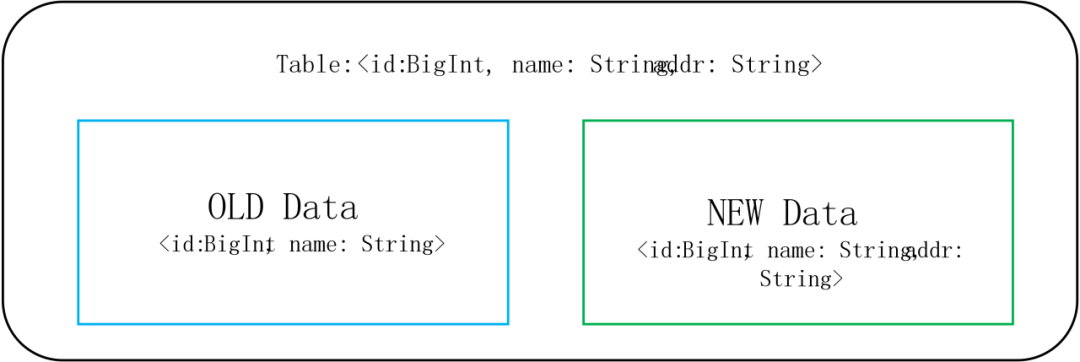
当我们执行如下Query,在Iceberg生成查询任务时,所有的OLD Data都无法根据where条件过滤,因为我们没有addr列的Metrics,无法知道这些文件是否满足where条件。
SELECT * FROM iceberg.db.table WHERE start_with('addr', 'some_value');为此我们在DataFile数据结构上加上了写入文件时的Schema信息,这样我们在查询上述语句时就可以先判断where条件的列是否存在于写入表的schema中,可以过滤更多的文件。如根据Schema过滤了文件,可以在Spark Log里看到类似于如下所示信息:
DATAFILE File Filter (Filtered: 20, Total: 25)-- Filter by: SchemaFilter, filtered: 15-- Filter by: DataFileMetricsFilter, filtered: 52022-07-27 17:09:17,173 INFO util.CloseableIterableWithFilterMetrics:MANIFEST_DATA File Filter (Filtered: 0, Total: 5)
Spark DPP支持
在SQL优化中,Join的优化一直是一个重点。Spark SQL Join任务中BroadCastHashJoin是一个比较高效的Join方式,因为该方式避免了Spark Shuffle过程。BroadCastHashJoin是将Join的维度表通过广播的方式发布到每个计算进程,以此来和事实表做Join。在大数据处理中优化SQL查询的重要手段就是谓词下推和列剪枝以此来减少不需要的数据读取,在BroadCastHashJoin中由于维度表已经存在于每个计算进程中了,所以我们可以利用维度表对事实表做文件过滤。DPP(Dynamic Partition Pruning)就是这样一个优化手段,利用维度表对事实表进行分区过滤,其示意图如下:
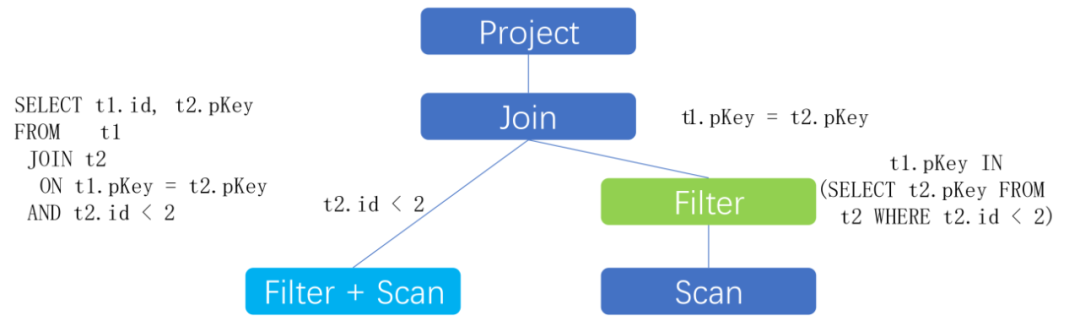
Iceberg对Spark的支持是基于Spark DataSource V2的接口实现的,Spark的DPP对Datasource V2表的支持是从3.2版本才开始支持的。当前天穹Spark3的版本是Spark 3.1.2,为此我们在天穹Spark 3.1.2上提供了DPP对Datasource V2的支持,并且在Iceberg Spark 3.1版本上实现了DPP相应的接口。用户在使用时只需要通过如下参数来控制是否开启DPP:
spark.sql.iceberg.enable-dynamic-partition-pruning = true; // 默认是开启的Spark 复杂类型向量化读
Iceberg中支持非复杂类型(除了Struct,Map,List这些复杂类型)的向量化读,或者称之为Batch读。Parquet的每一列数据由三部分组成:Repetition Level,Definition Level和Value。Repetititon Level定义了当前Column Path上哪一个字段是重复的,Definition Level定义了该字段是否为null。对于Repetition Level/Definition Level都采用的是RLE(Run Length Encoding / Bit-Packing Hybrid )编码。Bit-Packing编码就是用更少的Bit来表示当前的Value,比如人的年龄,采用7个bit来存储就足够了。Run Length Encoding简化如下所示:
[1, 2, 2, 5, 5, 5, 5, 7, 7, 7] -> [1 1, 2 2, 4 5, 3 7]我们在解码Parquet列数据时首先需要解码Repetition Level/Definition Level,RLE的向量化读解码伪代码如下。很明显在解码Run Length Encoding时可以利用到CPU的SIMD加速,并且数据都在CPU Cache中,所以可以更快的解码。同样如果是Run Length Encoding的数据也可以受益。
ColumnVector columnVector = ...int numRecords = readInt();int bitPackedValue = unBitPack(readValue());for (int i = 0; icolumnVector[startOffset + i] = bitPackedValue;}
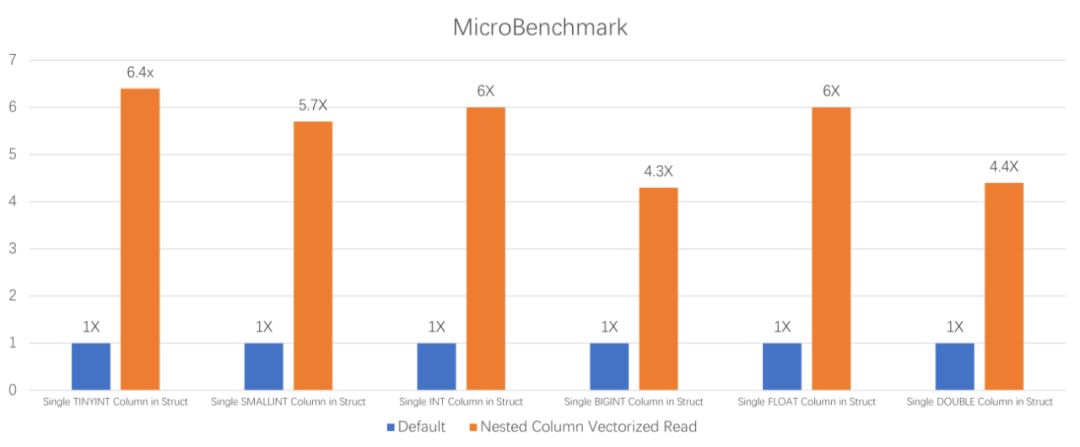
但是Iceberg目前还不支持对复杂类型采用向量化读,所以如果在查询的列中有复杂类型的字段时就自动转换为非向量化读了。对于日志平台这种很复杂的表结构,大部分字段都是复杂类型。而在Spark 3.3版本开始支持了Parquet的复杂类型的向量化读,为此我们在内部的Spark 3.1.2版本上移植了该特性。Micro Benchmark结果如下:
3.3 对PB级表的自动优化服务改进
数据湖优化服务提供了一些通过异步任务实现的优化服务,如小文件合并,表级别TTL,优化文件组织结构和删除垃圾文件等。但是日志文件的特点衍生了一些新的需求。
列字段生命周期管理
首先是列级别的生命周期管理,当前这个功能还在开发过程中。表级别的生命周期管理很好理解,用户可以配置一个TTL时间和一个有时间属性的字段(long类型或者符合指定格式的时间类型),优化服务会判断表中的文件是否超过TTL来删除过期文件。列字段的TTL源自不是所有的列都有相同的价值,特别是日志表的一千多个字段,有些字段的实效性是小于别的字段的,所以可减少这些字段的存储时间以此来降低整个表的存储成本。
支持根据时间区间合并小文件
在已有的合并小文件实现中,我们通常是对单个分区的文件进行小文件合并,这样可以避免由于表中小文件太多导致任务占用的资源太多,但是日志文件单个分区依然有几十TB,这依然会导致一个Job需要占用太多的计算资源,并且Job失败的重试代价比较大,为此我们实现了可以基于时间分区的小文件合并。

4. 项目收益
日志底座数仓
建设统一的日志底座,广告日志存储在数据湖 Iceberg 表中,用户无需关心日志格式和路径,只需指定表名 + 时间范围即可访问日志。支持 IDEX SQL/Spark 等多种访问方式,其中 SQL 方式简单灵活,开箱即用,无需代码编译打包部署等繁杂步骤,Spark 方式访问 Iceberg 是标准化的 dataframe 接口,适用于熟悉 Spark 的开发者,无论何种方式,均无需理解底层的文件存储和格式细节,总之,新手也能快速上手日志。
接入公司大数据平台生态,权限管理/视图管理/访问审计等多种管控手段和工具,为后续的数据治理,数据合规,系统升级等提供基础。
性能提升和成本优化
日志读取和查询,Iceberg 具有优秀的读取性能,可以充分利用 Iceberg 对列存的字段裁剪 + Iceberg 分区过滤 + Iceberg metrics 的文件级别过滤 + 底层 parquet 文件内部过滤等多种过滤优化手段,大幅提升读取性能,更好的支持广告业务。
基于底层 parquet 列存压缩,Iceberg 表平均存储占用相比原来的 HDFS 日志,存储节省 ~50%,大幅降低日志的存储成本。同时,基于上述的多种优化手段,原有的基于 HDFS 日志/Hive 表的计算分析任务,迁移到数据湖 Iceberg 表后,计算资源平均节省 ~40%,大幅降本增效。
5、未来规划
当前已有部分规划中的已经在进行中:
-
基于Flink的实时入湖,已经在开发中了,上线后会提供更好的实时性。
-
Spark异步IO加速Iceberg文件读取的优化也已经在开发中。
-
根据表的查询统计信息对常用的过滤字段开启索引加速查询。
列字段的生命周期管理,进一步降低存储成本。

本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/11069/