


分享嘉宾:张友军 字节跳动
编辑整理:王宇翔
出品平台:DataFunTalk
导读:今天很高兴能与大家分享字节数据平台在实时数仓中的一些实践。目前在数据湖和Hudi相关的一些基本技术原理方面社区已有较多的介绍,所以我们今天的分享主要聚焦于实践部分的内容。
今天我们的分享主要分为四个部分:
-
实时数仓场景介绍
-
数据湖在实时数仓场景初探
-
数据湖在实时数仓典型场景实践以及深度优化
-
未来规划
01
实时数仓场景介绍
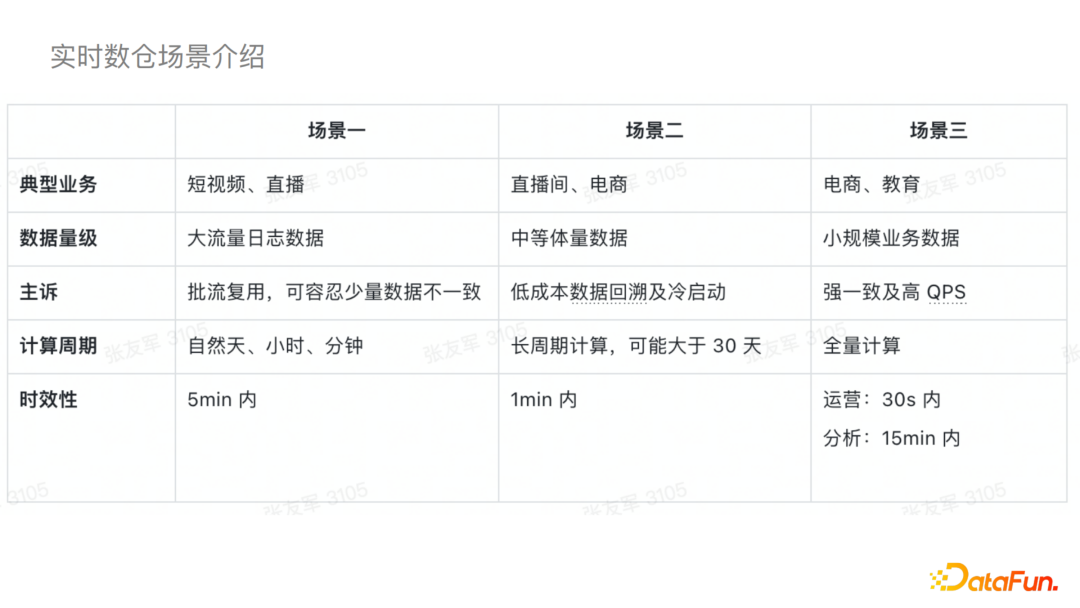
为了数据湖更好的落地,我们在落地之前与业务做了一些深入的沟通,并根据不同业务的特点主要分为了三个场景:
①场景一典型的业务主要是短视频和直播,它的数据量级一般都比较大,例如大流量的日志数据,其计算周期一般是自然的天、小时或者分钟级别的,实时性的要求一般是五分钟内,主要诉求是批流的复用,可以容忍少量数据的不一致。
②场景二一般是直播或者电商的部分场景,数据量一般是中等体量,为长周期计算,对于实时性的要求一般是一分钟以内,主要诉求是低成本的数据回溯以及冷启动。
③场景三主要是电商和教育的一些场景,一般都是小规模的业务数据,会对数据做全量计算,其实时性要求是秒级的,主要诉求是强一致性以及高QPS。
我们结合这些特点基于数据湖做了一些成套的解决方案,接下来我们会基于实际的一些场景和案例一一去了解。
02
实时数仓场景初探
本节我们讨论的是字节实时数仓场景的初探以及遇到的问题和解决方案。
坦白地讲,在最初落地时大家对数据湖能支持线上生产的态度都是存疑的,我们开始的方案也就比较保守。我们首先挑选一些对比现有解决方案,数据湖具有凸显的优势的场景,针对其中的一些痛点问题尝试小规模的落地。
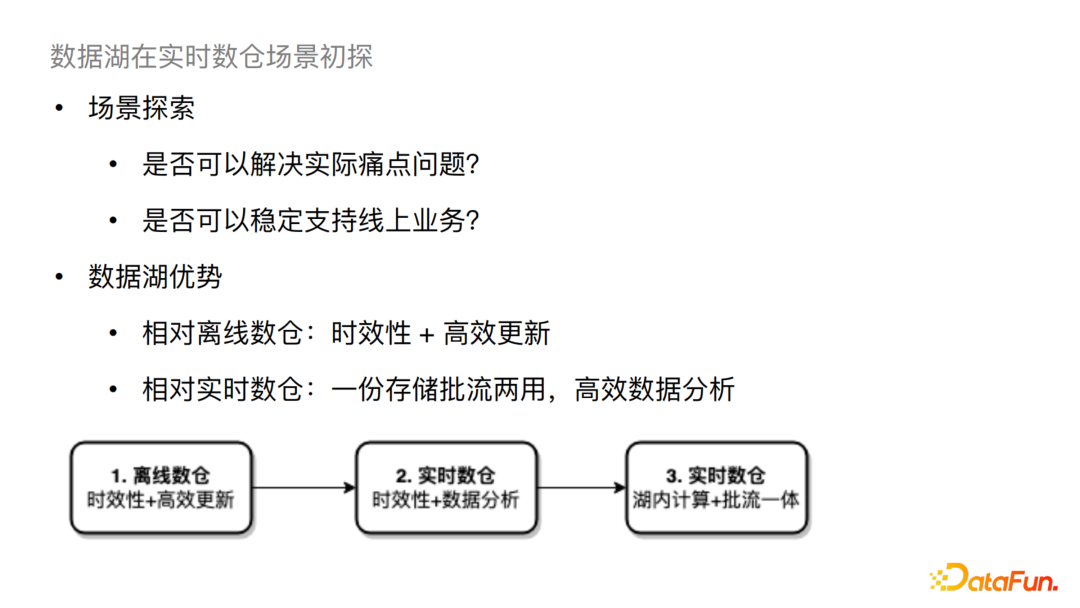
离线数仓有两个比较大的问题,一个是时效性问题,现状一般是天或小时级;第二个比较大的问题是更新问题,例如需要更新某个小时内的部分数据,现状需要将分区内数据全部重刷,这样的更新效率是很低的。对于这样的场景,数据湖兼具时效性和高效更新能力。同时相对于实时数仓来说,数据湖可以一份存储,批流两用,从而直接进行高效的数据分析。
基于以上对业务的分析,我们会按照以下步骤来做一线的落地。
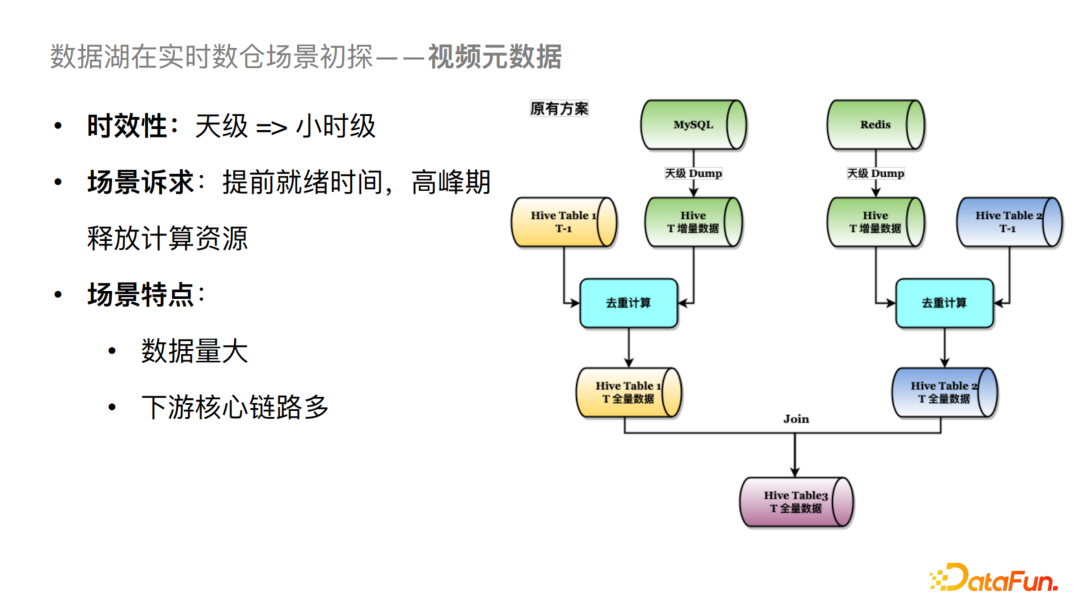
1. 基于视频元数据的落地方案
看上图我们原有的方案有三个Hive表,Hive Table 1,2,3。对于整个链路来说我们会把左边MySQL数据源的数据导到Table 1中,右边Redis的数据导到Table 2中,然后将两个表做Join。这里存在两个比较大的问题,一个是高峰期的资源占用率较高,因为天级 Dump 数据量较大,且都集中在凌晨;二是就绪时间比较长,因为存在去重逻辑,会将 T-1 天分区的数据和当天分区的数据合并去重计算后落到当天(T天)的分区。
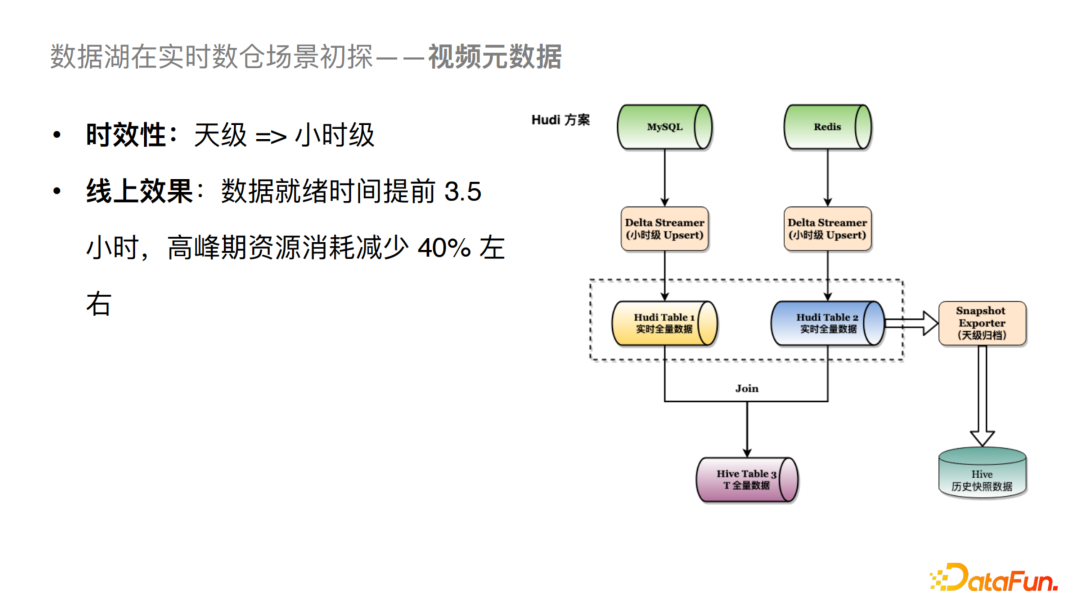
我们通过引入Hudi把天级的Dump分摊到每个小时进行Upsert。由于Hudi自身可以支持去重的逻辑,我们可以将Table 1看成一个实时的全量数据,当小时级别(例如23点)的数据一旦Upsert完成之后,我们就可以直接进行下游的Join逻辑,这样的话我们可以将数据的就绪时间提前3.5个小时左右,高峰期的资源消耗可以减少40%。
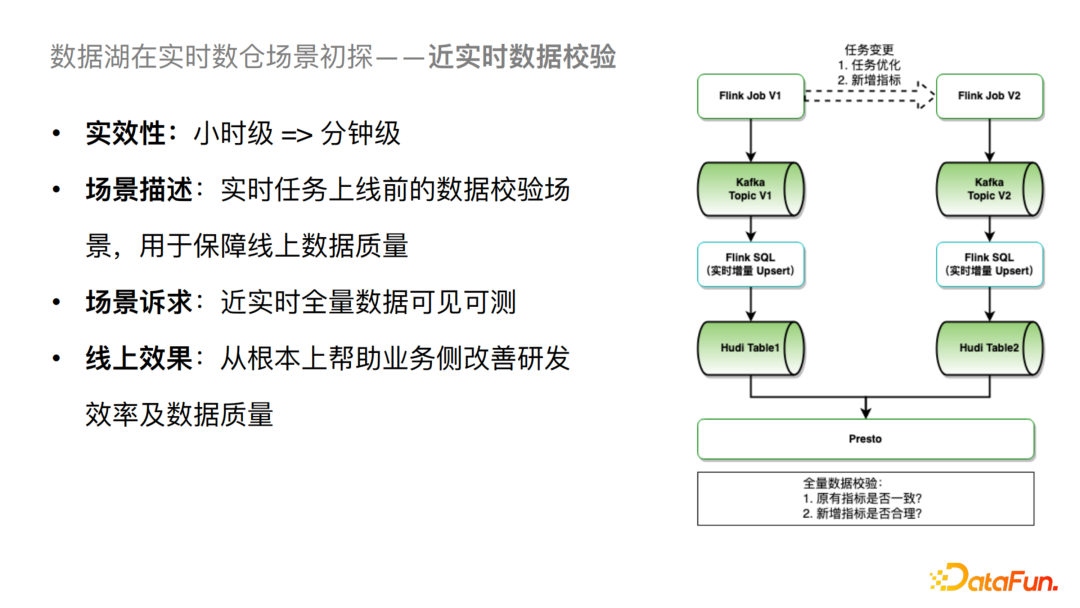
2. 近实时数据校验方案
对于实时场景来说,当实时任务进行一个比较频繁的变更,比如优化或者新增指标的改动,一般需要校验实时任务的产出是否符合预期。我们当前的方案是会跑一个小时级别的Job,将一个小时的数据从Kafka Dump到Hive之后再校验全量数据是否符合预期。在一些比较紧急的场景下,我们只能抽查部分数据,这时候就对时效性的要求就比较高。在使用基于的Hudi 方案后,我们可以通过Flink将数据直接Upsert到Hudi表中,之后直接通过Presto查询数据从而做到全量数据近实时的可见可测。从线上效果来看可以极大提高实时任务的开发效率,同时保证数据质量。
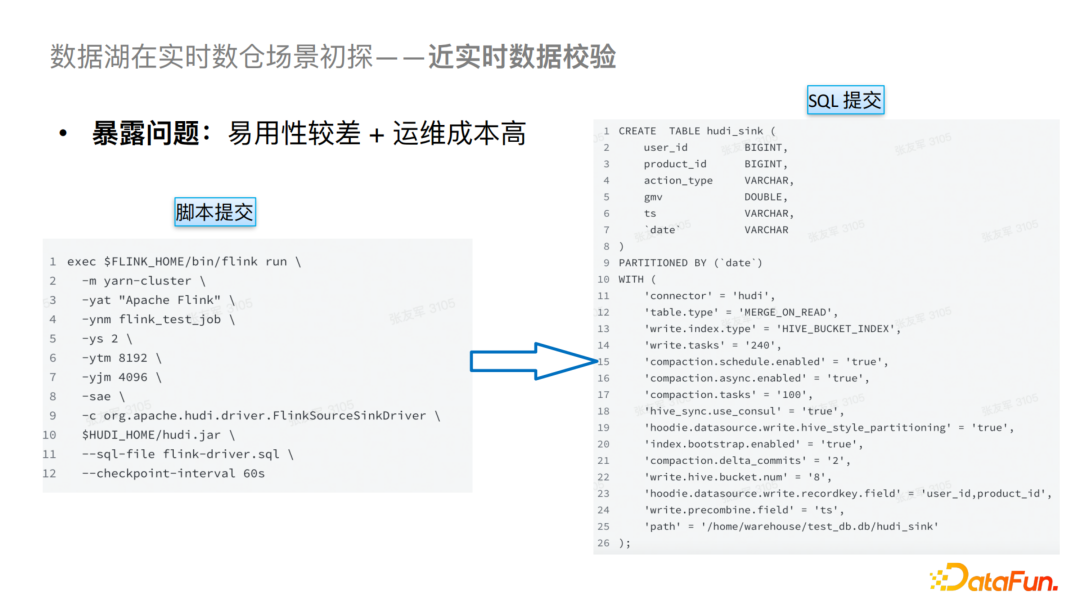
在以上探索过程中遇到了比较多的问题,第一个问题就是易用性比较差,运维成本和解释成本比较高。对于易用性这一部分,我们起初是通过脚本来提交SQL,可以看到SQL中的参数是比较多的,并且包含DDL的Schema,这在当列数比较多的情况下是比较麻烦的,会导致易用性较差,并且对业务侧来说也是不可接受的。
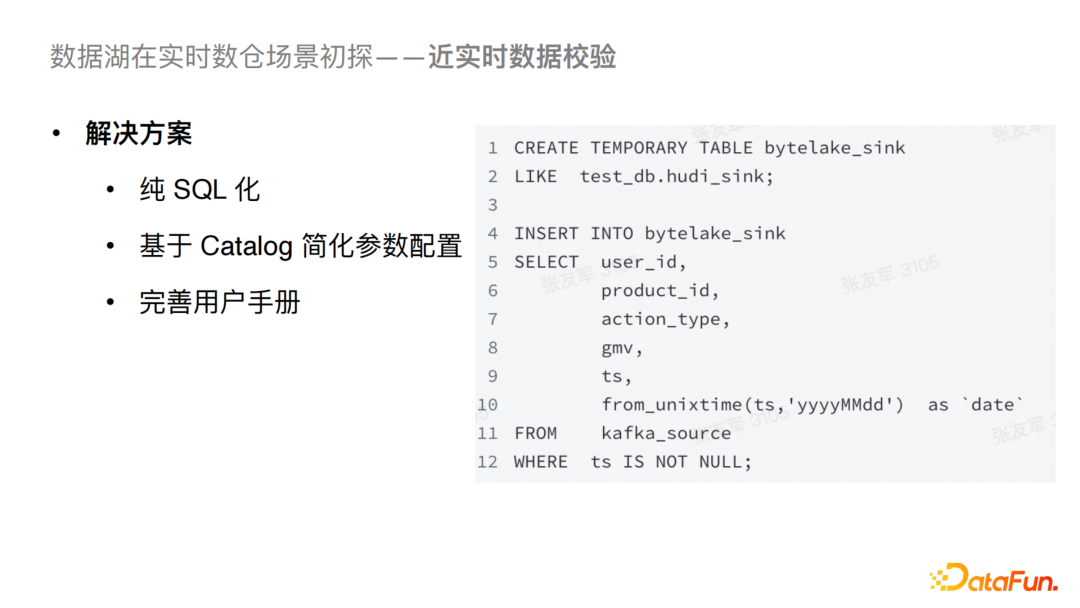
对于以上问题我们做了一个针对性的解决方案,首先我们对之前的任务提交方式替换为了纯SQL化提交,并且通过接入统一的Catalog自动化读取 Schema和必要参数,入湖的SQL就可以简化为如图的形式。
03
典型场景实践
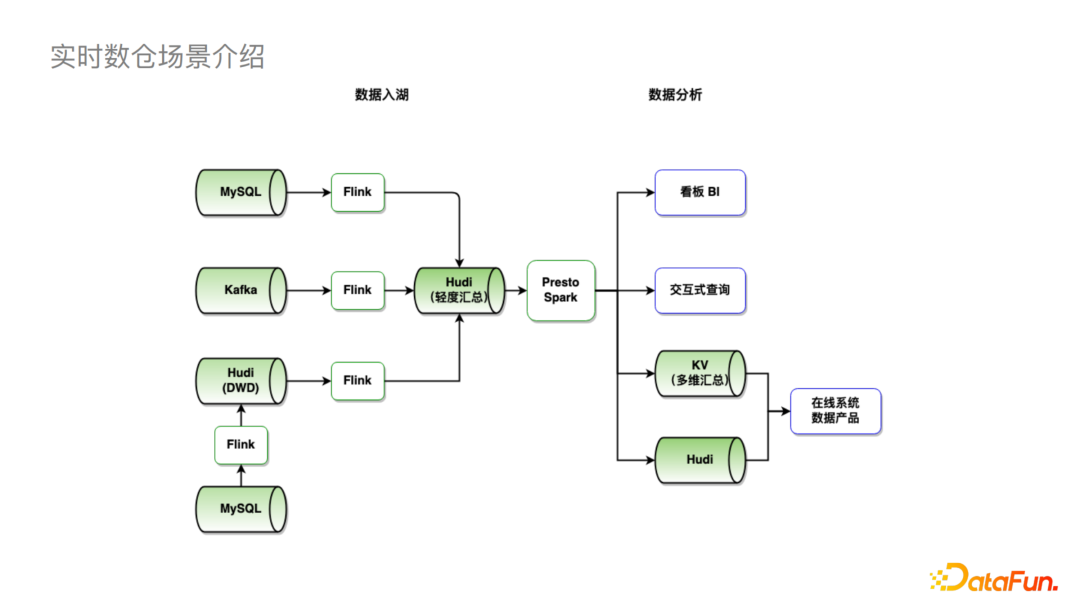
接下来让我们看字节目前基于Hudi的实时数仓整体链路。
可以看到,我们支持数据的实时入湖,例如MySQL,Kafka通过Flink可以直接落到Hudi;也支持进行一定的湖内计算,比如图中左下将MySQL数据通过Flink导入Hudi进一步通过Flink做一些计算后再落到Hudi。在数据分析方面,我们可以使用Spark和Presto连接看板BI进行一些交互式查询。当我们需要接到其他在线系统,尤其是QPS较高的场景,我们会先接入到KV存储,再接入业务系统。
让我们来看具体场景。
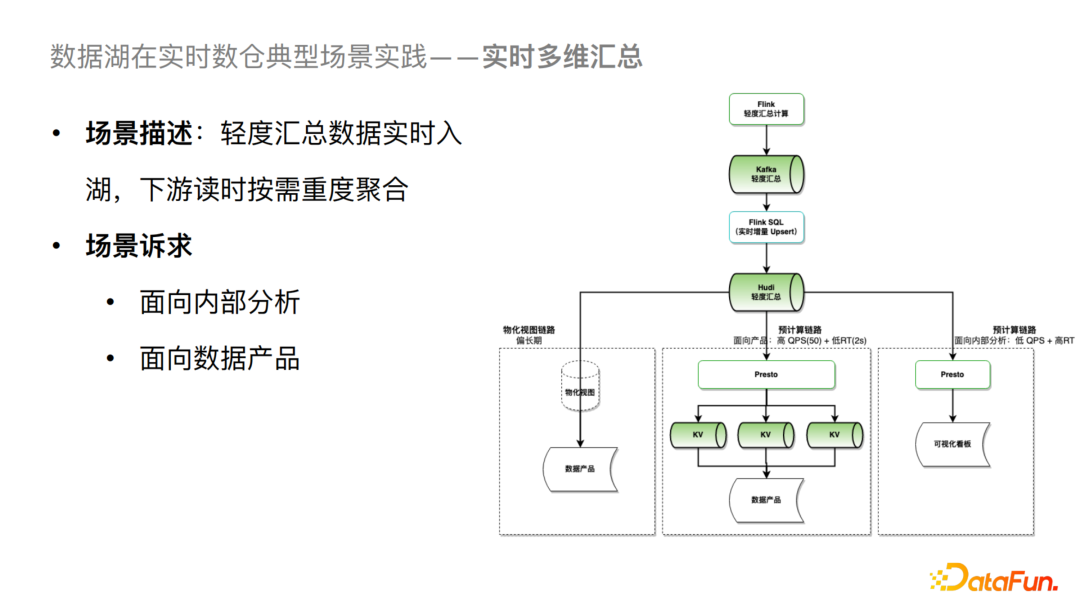
1. 实时多维汇总
对于一个实时多维汇总的场景,我们可以把Kafka 数据增量写入到 Hudi 的轻度汇总层中。对于分析场景,可以基于 Presto 按需进行多维度的重度汇总计算,并可以直接构建对应的可视化看板。这个场景对QPS和延迟要求都不是很高,所以可以直接构建,但是对于高 QPS 和低延迟诉求的数据产品场景,目前的一个解决方案是通过 Presto 进行多维度预计算,然后导入到 KV 系统,进一步对接数据产品。从中长期来看我们会采取基于物化视图的方式,这样就可以进一步去简化业务侧的一些操作。

在以上链路中,我们也遇到了比较多的问题:
①写入稳定性差。第一点就是Flink在入湖的过程中任务占用资源比较大,第二点是任务频繁重启很容易导致失败,第三点是Compaction没有办法及时执行从而影响到查询。
②更新性能差。会导致任务的反压比较严重。
③并发度难提升。会对Hudi Metastore Service(目前字节内部自主研发的Hudi元数据服务,兼容Hive接口,准备贡献到社区)稳定性产生比较大的影响。
④查询性能比较差。有十分钟的延迟甚至经常查询失败。
面对这些问题,我接下来简单介绍一下针对性的一些解决方案:
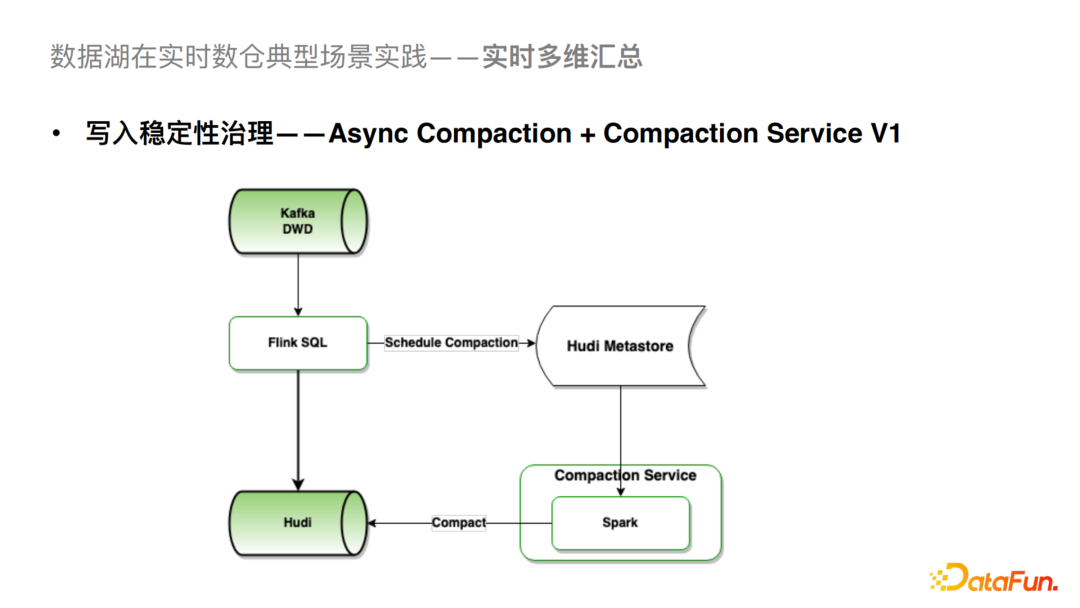
①写入稳定性治理
这一块我们通过异步的Compaction + Compaction Service的方案去解决这个问题。我们之前Flink入湖默认是在Flink内部去做Compaction,发现这一步是暴露以上一系列问题的关键。经过优化,Flink入湖任务只负责增量数据的写入,以及 Schedule Compaction逻辑,而Compaction执行则由Compaction Service负责。具体而言,Compaction Service 会从Hudi Metastore异步拉取Pending Compaction Plan,并提交Spark批任务完成实际的Compact。Compaction执行任务与Flink写入任务完全异步隔离,从而对稳定性有较大提升。
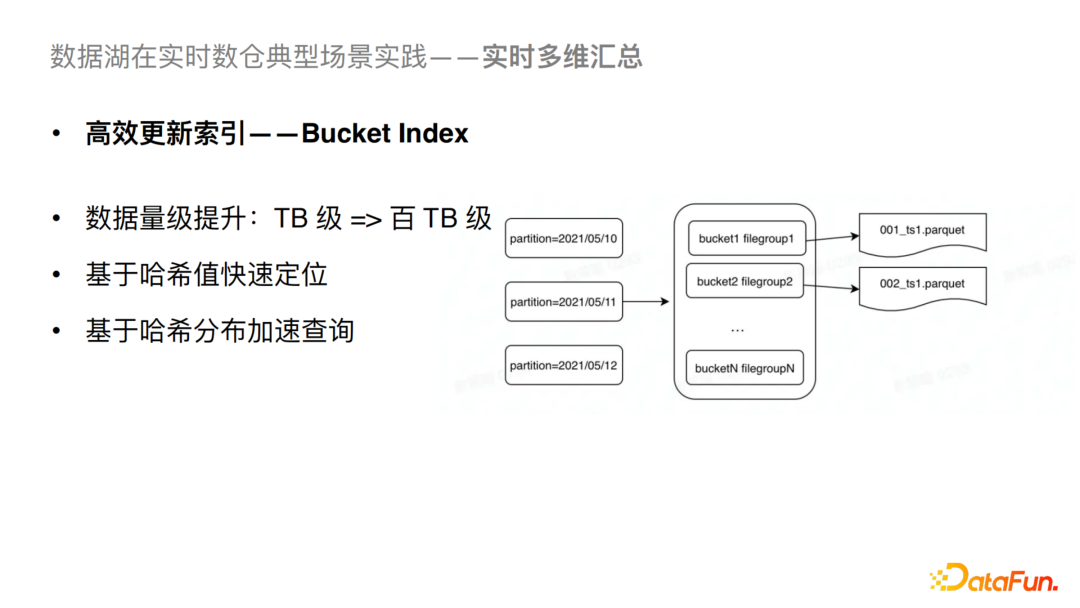
②高效更新索引
支持数据量级的大幅提升。简单来说,我们可以基于哈希计算快速定位目标文件,提升写入性能;同时可以进行哈希过滤,从而也可以进行查询分析侧的优化。
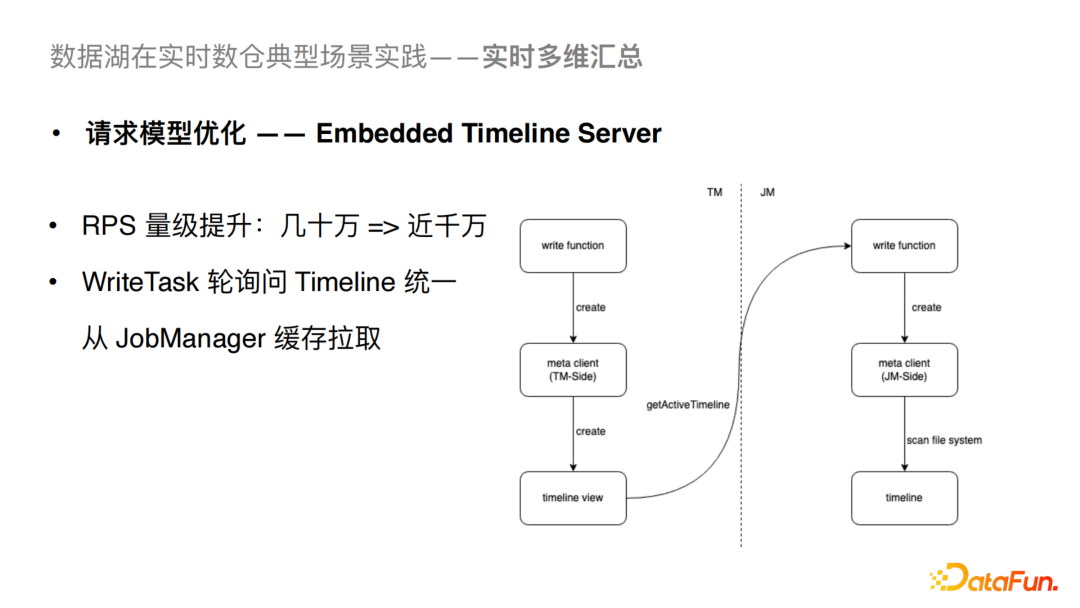
③请求模型的优化
当前的Hudi社区版的WriteTask 会轮询Timeline,导致持续访问Hudi Metastore,从而造成拓展能力受限的问题。我们将WriteTask的轮询请求从Hudi Metastore转移到了对JobManager缓存的拉取,这样就能大幅降低对Hudi Metastore的影响。经过这个优化可以让我们从几十万量级的RPS(Request Per Sec)提升到近千万的量级。
接下来我们来讲一下查询相关的优化。
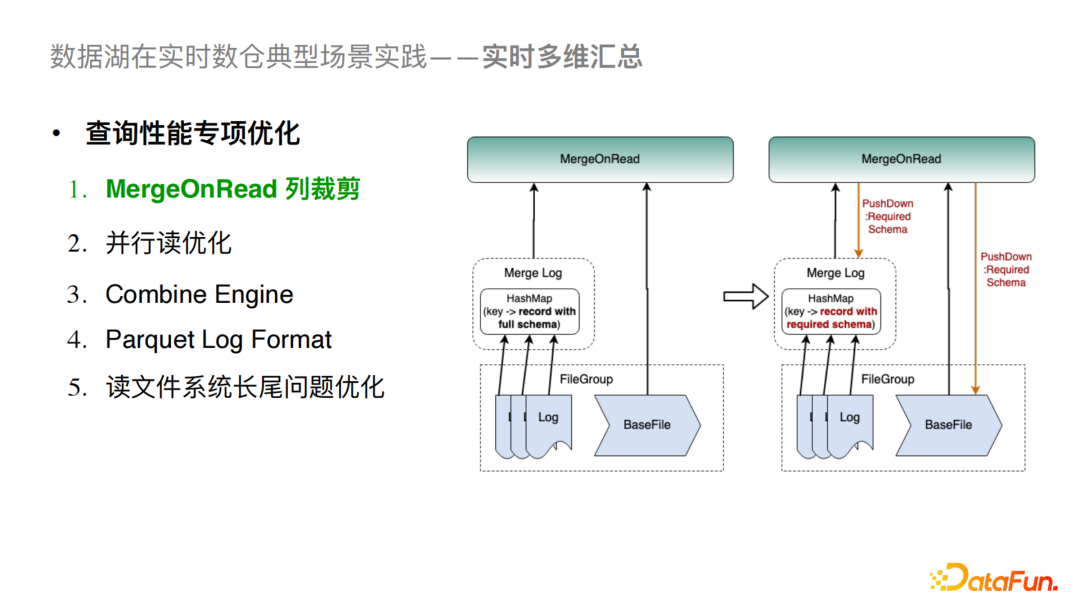
④MergeOnRead列裁剪
对于原生的MergeOnRead来说,我们会在全量读取LogFile和BaseFile之后做合并,这在只查询部分列的时候会造成性能损耗,尤其是列比较多的情况。我们所做的优化是把列的读取下推到Scan层,同时在进行log文件合并时,会使用map结构存储K,V(K是主键,V是行记录),之后对行记录做列裁剪,最后再进行Log Merge的操作。这样会对序列化和反序列化开销以及内存使用率都有极大降低。
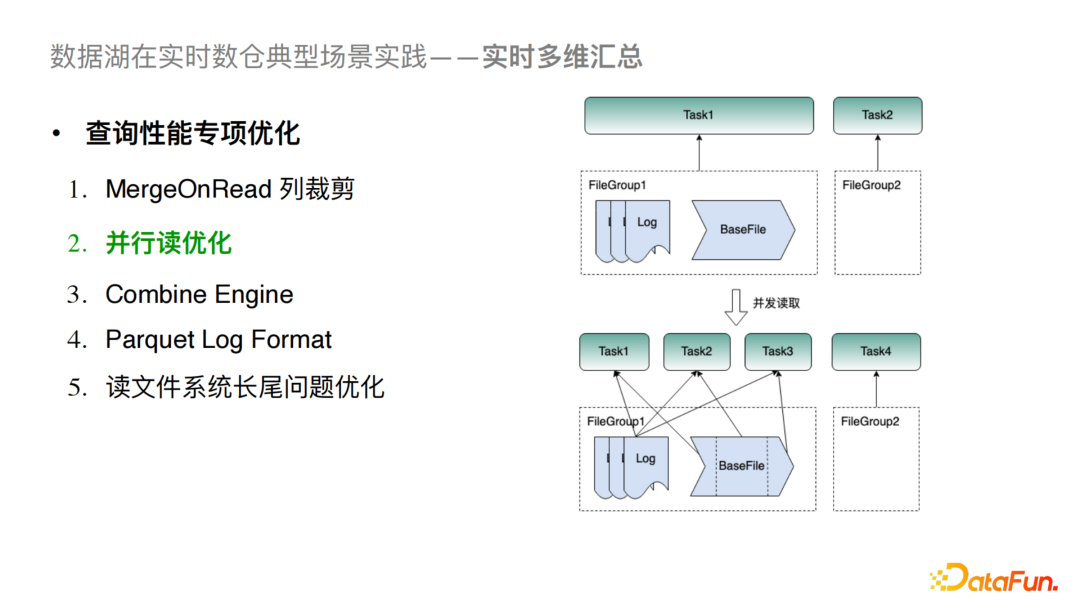
⑤并行读优化
一般引擎层在读Hudi时,一个Filegroup只对应一个Task,这样当单个 FileGroup 数据量较大时就极易造成性能瓶颈。我们对此的优化方案是对BaseFile进行切分,每个切分的文件对应一个Task从而提高读并行度。
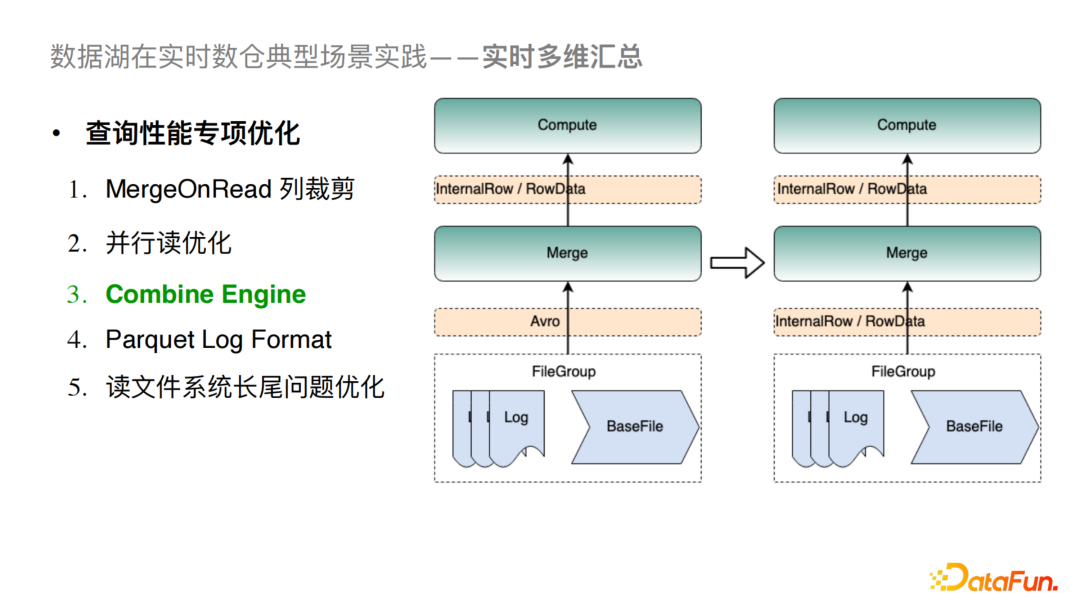
⑥Combine Engine
Hudi社区版目前在内存中对数据的合并和传输的实现完全是基于Avro格式,这会造成与具体引擎对接时有大量的序列化与反序列化计算,从而导致比较大的性能问题。对于这个问题我们与社区合作做了Combine Engine的优化,具体做法就是将接口深入到了引擎层的数据结构。例如在读取FileGroup时我们直接读取的就是Spark的InternalRow或是Flink的RowData,从而尽量减少对Avro格式的依赖。这样的优化可以极大地提高MergeOnRead和Compaction的性能。
接下来两个优化由于时间原因就不做详细介绍了。

⑦实时数据分析
这个场景我们可以把明细数据直接通过Flink导入到Hudi中,还会根据DIM表做一个宽表的处理从而落到Hudi表。这个场景的诉求主要有两点,一个是日志型数据的高效入湖,另一个是实时数据的关联。对于这两个场景的诉求,我们针对性的进行了一些优化。
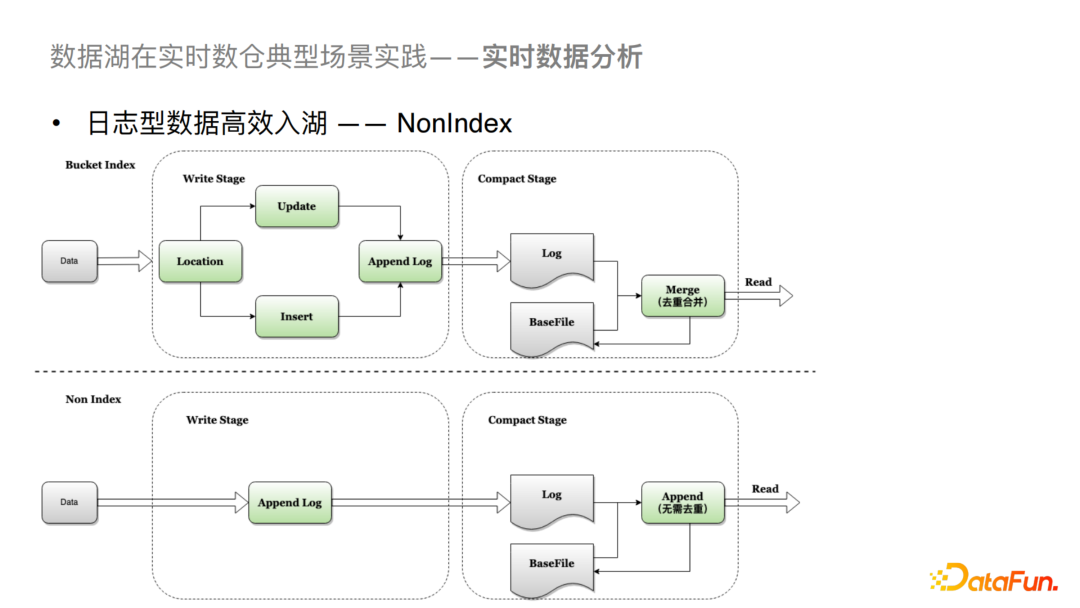
⑧日志型数据高效入湖
对于日志型数据,我们支持了NonIndex的索引。Hudi社区版主要支持是基于有主键的索引,比如Bloom Filter或者是我们给社区提供的Bucket Index。生成基于主键的索引方式主要会有两个步骤,第一个步骤是数据在写进来的时候会先对数据做定位,查询是否有历史数据存在,如果有的话就Update,没有的话就Insert,之后会定位到对应的文件把数据Append到Log中。然后在Merge或者在Compaction的过程中要在内存中做合并与去重处理,这两个操作也是比较耗时的。对于NonIndex来说,是不存在主键的概念的,所以支持的也是没有主键的日志型数据入湖。这样对于日志型数据在写入时可以直接Append到Log File中,在合并的过程中,我们可以不做去重处理,直接将增量数据数据Append到Base File中。这样就对入湖的效率有了很大的提升。
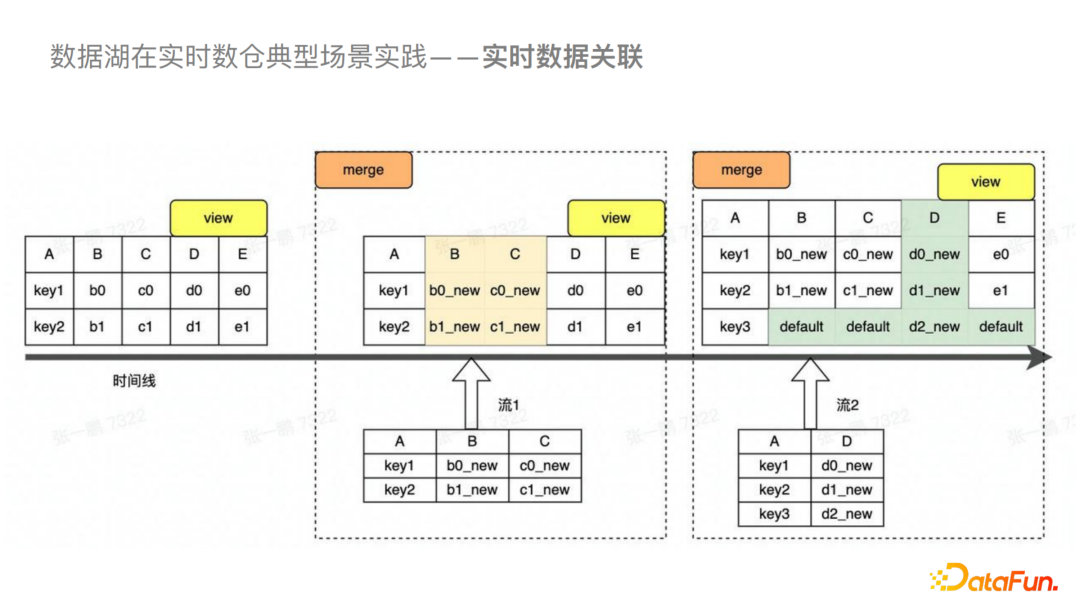
⑨实时数据关联
针对目前实时Join出现的一系列问题,我们基于Hudi支持了存储层的关联。对Hudi来说不同的流可以完成其所对应列的写入,并在Merge的时候做拼接,这样对于外界查询来说就是一个完整的宽表。具体来说,在实时数据写入的过程中有一个比较大的问题是怎么处理多个流的写入冲突问题。我们主要是基于Hudi Metastore来做冲突检测。
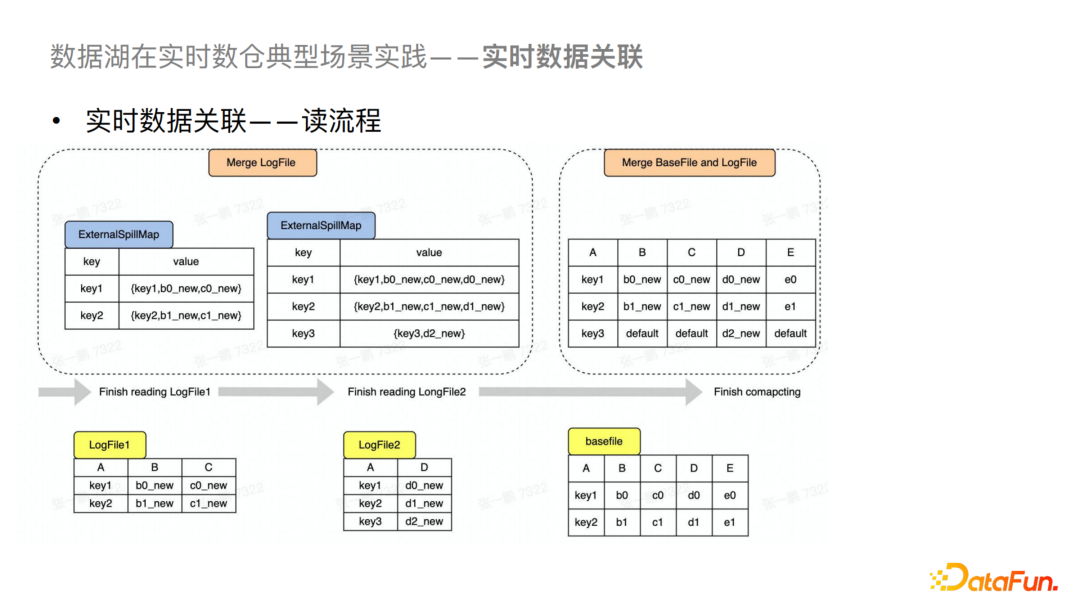
对于读的流程,我们会先将多个LogFile读入内存进行Merge,然后再与BaseFile进行最终Merge,最后输出查询结果,Merge和Compaction都会使用到这个优化。
04
未来规划

1. 弹性可扩展的索引系统
我们刚刚介绍了Bucket Index支持大数据量场景下的更新,Bucket Index也可以对数据进行分桶存储,但是对于桶数的计算是需要根据当前数据量的大小进行评估的,如果后续需要re-hash的话成本也会比较高。在这里我们预计通过建立Extensible Hash Index来提高哈希索引的可扩展能力。
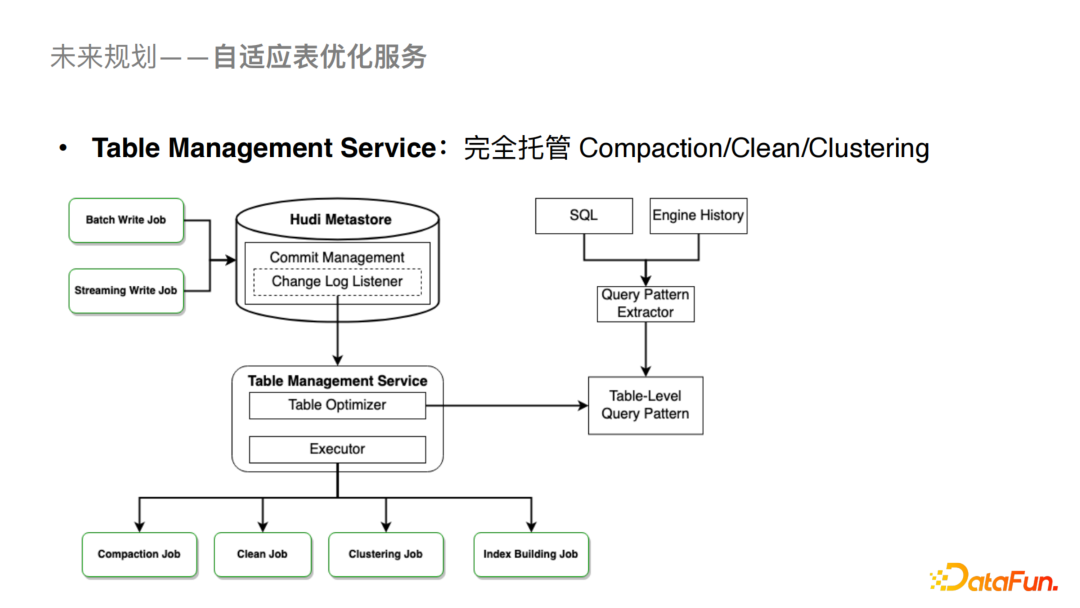
2. 自适应的表优化服务
为了降低用户的理解和使用成本,我们会与社区深度合作推出Table Management Service来托管Compaction,Clean,Clustering以及Index Building的作业。这样对用户来说相关的优化都是透明的,从而降低用户的使用成本。

3. 元数据服务增强
目前我们内部已经使用Hudi Metastore稳定支持了一些线上业务,但是也有更多需求随之而来,预计增强的元数据服务如下:
①Schema Evolution:支持业务对Hudi Schema变更的诉求。
②Concurrency Control:在Hudi Metastore中支持批流并发写入。
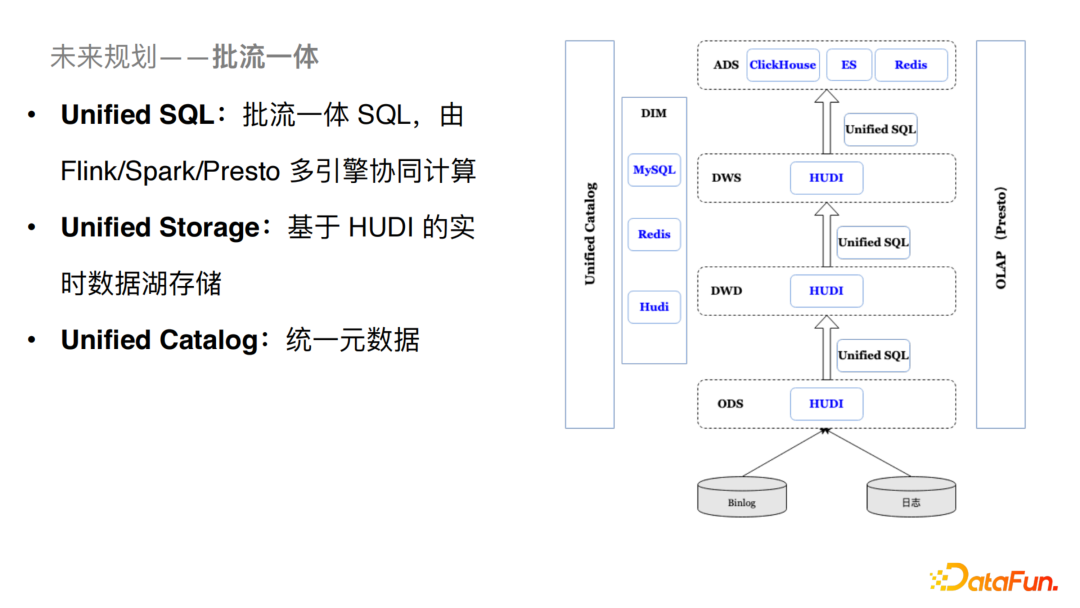
4. 批流一体
对于流批一体处理,我们的规划如下:
①Unified SQL:做到批流统一的SQL层,Runtime由Flink/Spark/Presto多引擎协同计算。
②Unified Storage:基于Hudi的实时数据湖存储,由Hudi来做统一的存储。
③Unified Catalog:统一元数据的构建以及接入。
05
问答环节
Q1:MergeOnRead 列裁剪的文件格式是列式的还是行式的?
A1:在没有优化前是基于Avro的行式存储我们目前已经支持了Parquet Log的列存格式,能够带来存储以及查询性能上的提升。
Q2:Async Compaction的调度是在Flink内部访问的Hudi Metastore吗?
A2:Flink之前默认是做了三件事,第一件事是Hudi增量写,第二件事是在几次增量写之后会Schedule一个Compaction计划,第三件事是执行Compaction Plan。我们目前所做的事情是只把Compaction Plan执行的这一步拆分了出来使用Compaction Service拉取Hudi Metastore元数据来执行Compaction。(图见写入稳定性治理)
Q3:Hudi 表是如何管理的?
A3:通过Hudi Metastore。目前我们使用的Hudi Metastore主要是部署在MySQL上面,支持文件与库表元数据的管理,Snapshot 服务,Hudi自有的Timeline 服务以及一些并发控制的处理。上层接口我们完全兼容Hive Metastore的接口标准,然后基于Hudi特性,我们拓展了Hudi特有的例如Timeline 相关的接口。同时我们支持流批应用统一接入到Hudi Metastore去做数据处理。(图见元数据服务增强)
Q4:可以深入介绍一下多流写Hudi的流程以及冲突解决吗?
A4:多流Hudi增量写入,不同的流可以写到不同的Log文件中去,这一点是不冲突的,会产生冲突的点是二阶段的提交冲突,如果涉及到写的是同一个列的话是会产生列冲突的,这时我们会在Hudi Metastore中进行列级别的冲突检测,如果有冲突的话会直接拒绝提交,没有的话我们会认为是写两个流,就可以正常并发写入。(图见实时数据关联 — 写流程)
Q5:实时数仓里的Kafka流表和Hudi流表是什么关系,以后是否会用Hudi表来代替Kafka的流表?
A5:我们今天介绍主要是Hudi支持的一些近实时(分钟级别)场景的落地和尝试,在某些场景我们需要秒级的响应,这样就需要我们做一些流批一体的规划和尝试。长期来看我们会使用Hudi 流式能力来替换Kafka的流式能力。(图见未来规划 – 流批一体)
Q6:实时数仓是否每一层都用Hudi?
A6:湖内计算还在小范围的推广阶段,某些场景我们正在做POC,个别场景也在准备上线的过程中。
Q7:为何会使用Bucket Index?
A7:在使用Bucket Index前我们使用的是Bloom Filter Index,布隆过滤器在小数据量场景使用是没有问题的,但在百TB级别的数据下会有突出的假阳性的问题,当数据不存在的时候会扫描很多非必须的文件造成资源浪费。通过Bucket Index 我们可以直接通过hash值的计算能更加快速的定位数据所在的文件。
推荐阅读
华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
基于 Apache Hudi 的湖仓一体技术在 Shopee 的实践
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/10220/