
1. 业务背景介绍
在数仓ETL、实时计算的场景下,我们基于Flink SQL批流一体的框架进行了一定规模的作业迁移。在研发作业管理系统中,我们引入Apache Zeppelin组件作为Flink SQL作业提交客户端,Flink 批流作业可视化预览的核心组件。在一年多时间的产线实践中,我们对作业提交的方式策略进行了几次演进,目前在跑作业规模Flink Batch 任务日均运行超5000次,流作业500+,均稳定运行。
1.1 Apache Zeppelin 介绍
Apache Zeppelin是一款基于Web的Notebook产品,能够交互式数据分析。使用Zeppelin,您可以使用丰富的预构建语言后端(或解释器)制作交互式的协作文档,例如Scala、Python、SparkSQL、Hive、FlinkSQL等。
在Flink的集成方面,Zeppelin支持Flink的3种主流语言,包括Scala、PyFlink和SQL。同时,Zeppelin也提供了三种模式的Flink 任务提交,Local模式、Remote模式、Yarn Session/Application模式,社区在对Kubernetes Application模式也在开发中。Zeppelin还支持在解析器/任务作用域的Flink运行时参数配置,集成hive catalog ,并支持简易的cron job执行,并对多版本Flink均提供了支持,最新的master分支支持了最新的Flink 1.15版本。
以下是Flink on Zeppelin 主要feature:
Feature |
Feature 说明 |
|
多版本Flink支持 |
同时支持 Flink 1.10 到 1.15 的 6 个大版本,并且同时支持Scala-2.11 和Scala-2.12 |
|
多种运行模式支持 |
支持4种不同Flink运行模式:Local,Remote,Yarn,Yarn-Application,K8s(开发中) |
|
多语言支持,并且打通多语言间的协作 |
支持3种Flink开发语言:SQL,Python,Scala,并且打通各个语言之间的协作,比如用Python写的UDF可以用在用Scala写的Flink 作业里 |
|
支持Hive |
内置HiveCatalog |
|
交互式开发模式 |
交互式的开发模式可以大幅度提高开发效率 |
|
流式数据可视化 |
支持流式数据的动态可视化展现,方便调试和大屏展示 |
|
SQL 语言功能增强 |
同时支持Batch ,Streaming 模式,支持单行/多行 SQL 注释,支持指定jobName,并行度,Multiple Insert |
|
支持Rest API 方式提交Job |
除了在Zeppelin页面提交作业,也可以调用Zeppelin的Rest API来提交作业,将Zeppelin集成到自己的系统里。 |
|
多租户支持 |
支持多个用户在Zeppelin上开发,互不干扰 |
1.2 基于NoteBook作业提交的痛点
在最初任务较少时,我们将批、流作业都运行在单节点Zeppelin server中,直接使用SQL模式进行运行,由于每个长跑作业都需要建立实时监控,对server压力很大,调度任务从外部运行SQL,也经常出现卡顿,无法提交作业的情况。后来我们改用pyflink后台作业提交,作业监控额外通过监控程序管理,但随着任务增加,单台节点无法满足任务提交需要,期间做了批、流server独立拆分,增加单节点机器配置等,但依然无法稳定。

主要问题有以下:
-
Zeppelin Server单点故障导致已经运行流作业失败,批作业无法正常提交;最初使用yarn这种模式提交,客户端 Flink Interpreter 进程运行在 Zeppelin所在的机器这边,每个客户端对应一个Yarn上的Flink Cluster,如果Flink Interpreter进程很多,会对Zeppelin这台机器造成很大的压力,导致进程挂死。
-
并发提交任务几乎不可能,虽然后续切换Yarn Application 模式可以把Flink interpreter 跑在了JobManager里 缓解客户端压力,但同时大规模提交pyflink作业仍存在执行效率问题;
-
无法灵活个性化参数,解析器提前创建出,只能通过不断的新建notebook,控制session cluster 通过解析器提供的作用域,解析器配置错误影响所有关联notebook的任务提交。
2. 架构改进
2.1 改造后批/流作业提交架构
-
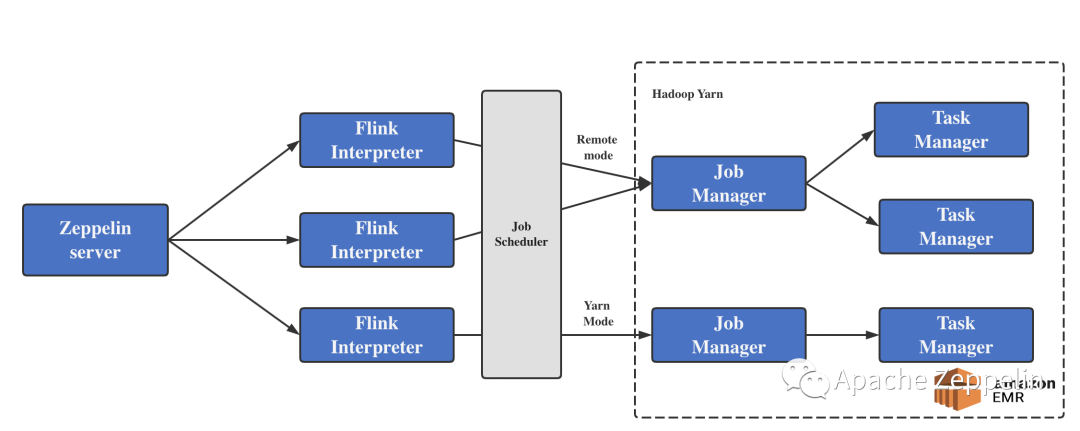
流作业提交优化
-
通过调用Zeppelin Server的rest api 新建Flink解析器;
-
新建notebook及paragraph,执行Pyflink程序,解析作业参数,执行依赖包加载及作业执行时配置;
-
通过自研job scheduler 对作业配置信息进行分析,判断作业提交方式为remote 还是yarn;
-
并发提交作业时,首先会进入资源队列,通过判断临时解析器数量,超过一定数量时,等待释放资源提交;
-
remote模式提交到hadoop yarn 中已经存在的job manager中,共享管理资源;
-
yarn模式通过解析器新建flink cluster ;
-
作业提交后,通过回调Zeppelin api,获取当次作业的提交信息记录到作业日志数据库中,包含yarn application id及job id,并提交至flink统一后台监控程序监控;
-
销毁解析器进程,归档作业notebook归档。
-
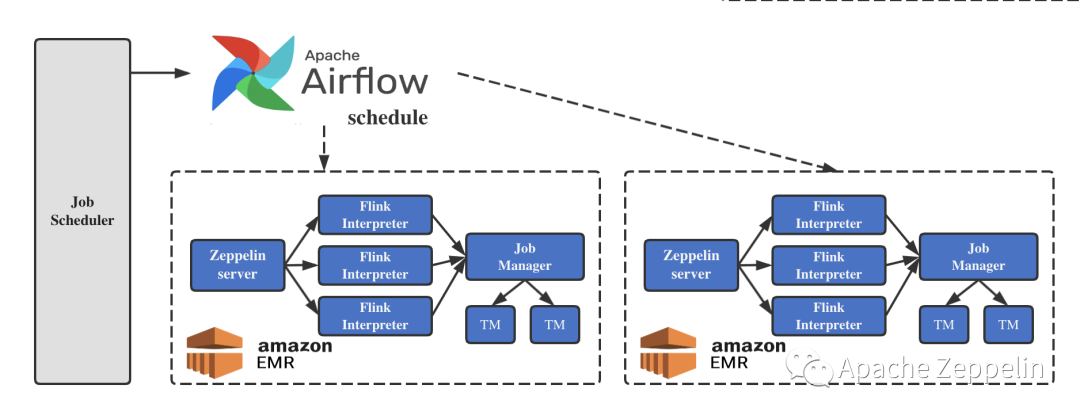
批作业提交优化
-
在统一作业管理中注册Flink Batch SQL 作业,并配置调度时间及依赖关系;
-
Airflow 生成dag,定时触发执行;
-
每一组任务执行时,首先新建EMR 集群,初始化Zeppelin环境;
-
通过Airflow 程序访问Zeppelin API使用同一个作用域为全局的解析器配置模板生成解析器;
-
同时为每一个Flink SQL 作业新建notebook,并执行作业SQL;
-
通过Zeppelin同步API执行所有notebook完成后,记录此组作业的最终执行结果及异常日志;
-
完成写入日志表后,销毁EMR集群。
2.2 作业提交架构优化收益
-
流作业支持了以作业组为单位的Flink On Yarn作业提交,每次提交作业独立创建解析器,提交完成后销毁解析器,有效降低了Zeppelin server的负载,通过作业调度管理器可以将同一个分组的作业提交到同一个cluster,共享作业资源。支持并发提交流作业并不会对Zeppelin server造成负担。具有水平扩展性,作业调度器可以兼容多个Zeppelin server 作为客户端提交作业;
-
批作业与流作业的Zeppelin server独立开,每次运行批作业使用AWS EMR 集成的Zeppelin进行任务提交,具备很强的水平扩展性。同一批作业运行规模也可随EMR的节点规模及节点类型进行垂直扩展,使得批作业提交不受Zeppelin单节点限制。
3. 实践要点
3.1 Python 环境及包管理
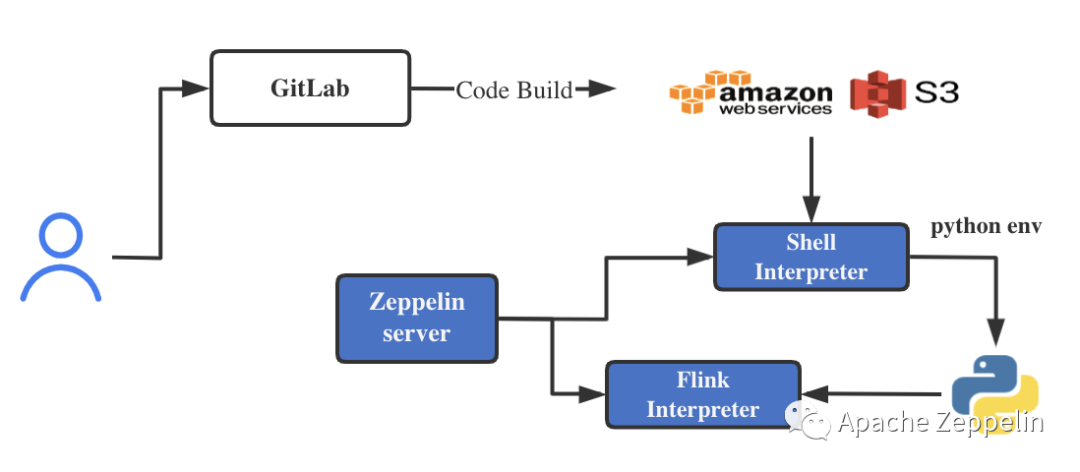
在运行pyflink过程中,需要提交将python依赖包安装到环境中,这里我们使用anaconda将python环境预先打包通过code build 存储到S3存储中,在执行pyflink 之前,首先使用Shell解析器初始化python环境,通过配置Flink 解析中python的路径,访问安装好依赖的环境。

环境包管理流程
3.2 AirFlow 批作业调度
我们通过对Zeppelin Rest API 封装了Zeppelin Airflow的operator,支持了几个重要的操作,如通过yaml模板创建Zeppelin解析器,创建notebook、paragraph,运行指定paragraph,记录Zeppelin 运行日志,销毁解析器,归档notebook等。可以很方便地基于operator对Zeppelin server进行访问。
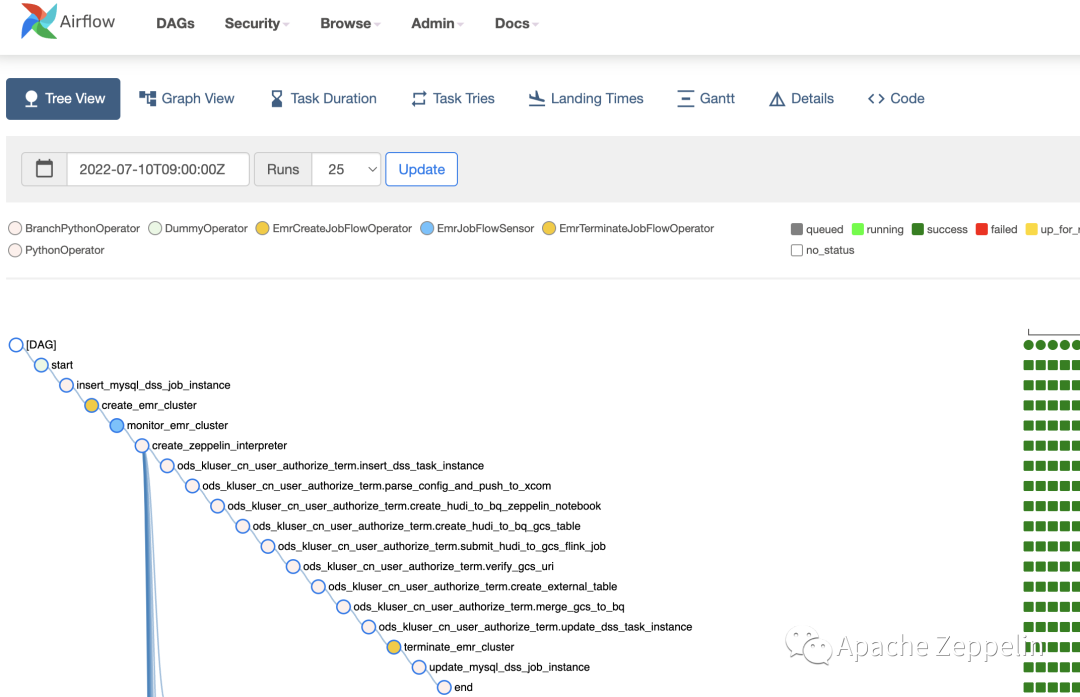
通过作业管理系统,我们将注册的任务记录在mysql数据库中,使用Airflow 通过扫描数据库动态创建及更新运行dag,将flink batch sql 封装为一类task group,包含了创建AWS EMR 临时集群,初始化Zeppelin服务,并通过Airflow的operator进行作业提交。
3.3 Flink SQL流作业资源调度
如前所述,通过自研作业管理系统,提交流作业时,主要执行pyflink进行任务的后台提交,虽然通过临时创建解析器,提交后销毁的方式可以有效减轻Zeppelin server压力,但是如果作业并发提交时,依然会遇到执行python造成内存及cpu负载。所以,在作业提交的资源调度上,进行提交队列的缓冲,限制Zeppelin server同时执行的并发数,并可以方便地进行多server提交作业。
对于同一个作业组的作业提交,如果第一次提交,会通过解析器创建flink cluster进行任务提交,而对于组内已有作业运行,即通过获取rpc 地址进行remote模式提交,类似如下图的入参。

4. 未来展望
Jobschedule对多版本Flink支持
Flink 及相关组件的版本频繁,为了支持A/B测试及业务迁移验证,后续需要支持提交不同的Flink 版本,而Zeppelin天然提供了对多版本Flink的支持,我们后续只需简单适配就可以实现。
更加灵活的参数及依赖包管理模式
后续对特定作业的运行时参数及依赖包需要支持可定制,灵活配置,当然仅限新任务提交到新的cluster生效。
Developed by KLOOK Data Team(Taylor、Wilson、Singh)
本文为从大数据到人工智能博主「jellyfin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/7737/