
背景
Aliware
容器网络为何出现
-
cgroup:实现资源的可配额 -
overlay fs:实现文件系统的安全性和便携性 -
namespace:实现资源的隔离性
-
IPC :System V IPC 和 POSIX 消息队列 -
Network:网络设备、网络协议栈、网络端口等 -
PID:进程 -
Mount:挂载点 -
UTS:主机名和域名 -
USR:用户和用户组
容器网络的基本要求
-
IP-per-Pod,每个 Pod 都拥有一个独立 IP 地址,Pod 内所有容器共享一个网络命名空间 -
集群内所有 Pod 都在一个直接连通的扁平网络中,可通过 IP 直接访问
-
所有容器之间无需 NAT 就可以直接互相访问 -
所有 Node 和所有容器之间无需 NAT 就可以直接互相访问 -
容器自己看到的 IP 跟其他容器看到的一样
-
Service cluster IP 尽可在集群内部访问,外部请求需要通过 NodePort、LoadBalance 或者 Ingress 来访问
网络插件介绍
Aliware
网络插件概述
-
有配置文件,能够提供要使用的网络插件名,以及该插件所需信息 -
让 CRI 调用这个插件,并把容器的运行时信息,包括容器的命名空间,容器 ID 等信息传给插件 -
不关心网络插件内部实现,只需要最后能够输出网络插件提供的 pod IP 即可
-
Hybridnet
-
阿里云 ACK 发行版 -
阿里云 AECP -
蚂蚁金服 SOFAStack
-
Calico
-
工作负载之间的网络连接 -
工作负载之间的网络安全策略
-
Bifrost
-
Bifrost 中的网络流量可以通过传统设备进行管理和监控 -
支持 macvlan 对于 service 流量的访问
通信路径介绍
-
VXLAN
-
VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网),是由 IETF 定义的 NVO3(Network Virtualization over Layer 3)标准技术之一,采用 L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求
-
IPIP
-
基于 TUN 设备实现 IPIP 隧道,TUN 网络设备能将三层(IP 网络数据包)数据包封装在另外一个三层数据包之中,Linux 原生支持好几种不同的 IPIP 隧道类型,但都依赖于 TUN 网络设备 -
ipip: 普通的 IPIP 隧道,就是在报文的基础上再封装成一个 IPv4 报文 -
gre: 通用路由封装(Generic Routing Encapsulation),定义了在任意网络层协议上封装其他网络层协议的机制,所以对于 IPv4 和 IPv6 都适用 -
sit: sit 模式主要用于 IPv4 报文封装 IPv6 报文,即 IPv6 over IPv4 -
isatap: 站内自动隧道寻址协议(Intra-Site Automatic Tunnel Addressing Protocol),类似于 sit 也是用于 IPv6 的隧道封装 -
vti: 即虚拟隧道接口(Virtual Tunnel Interface),是一种 IPsec 隧道技术 -
本文中我们使用的是 ipip 这种普通的 IPIP 隧道
-
BGP
-
边界网关协议BGP(Border Gateway Protocol)是一种实现自治系统AS(Autonomous System)之间的路由可达,并选择最佳路由的距离矢量路由协议
-
Vlan
-
VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。VLAN内的主机间可以直接通信,而VLAN间不能直接通信,从而将广播报文限制在一个VLAN内
网络插件的原理
-
calico 利用 IPIP 等隧道技术或者宿主机间建立 BGP 连接完成容器路由的互相学习解决了跨节点通信的问题。 -
hybridnet 利用 vxlan 隧道技术、宿主机间建立 BGP 连接完成容器路由的互相学习或者 ARP 代理来解决跨节点通信的问题。 -
bifrost 通过内核 macvlan 模块利用交换机 vlan 的能力来解决容器通信问题
网络插件分类及对比
-
网络插件分类
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
网络插件对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
SNAT: 对数据包的源 IP 地址进行转化 -
podIP:由 podIP 直接通信 -
veth pair:在 Linux 下,可以创建一对 veth pair 的网卡,从一边发送包,另一边就能收到,对于容器流量来说会通过主机侧的 veth pair 网卡进入主机网络栈,即会过主机的 iptables 规则后再由物理网卡发出。 -
macvlan子接口:macvlan 子接口和原来的宿主机主接口是完全独立的,可以单独配置 MAC 地址和 IP 地址,对外通信时,容器流量不会进入主机网络栈,既不会过主机的iptables规则,只会经过二层由物理网卡发出。
网络插件应用场景
-
希望对数据中心物理网络较少侵入性,可选择使用隧道方案
-
需支持双栈,则可选 hybridnet vxlan 方案 -
只支持单栈 IPv4,则可选 calico IPIP,calico vxlan 方案
-
希望数据中心支持并使用 BGP
-
宿主机处于同网段内,则可选 calico BGP 方案(支持双栈) -
宿主机处于不同网段内,则可选 hybridnet bgp 方案(支持双栈)
-
对于业务的高性能和低延迟的追求,出现了 macvlan,ipvlan l2 等方案 -
公有云场景下,可选用 terway 方案,或者其他 ipvlan l3 方案,或者隧道方案 -
也有为了满足全场景而开发的方案,如 hybridnet、multus 等,Multus 一款为支持其他 CNI 能力的开源容器网络插件
网络插件架构及通信路径
Aliware
Hybridnet
-
整体架构
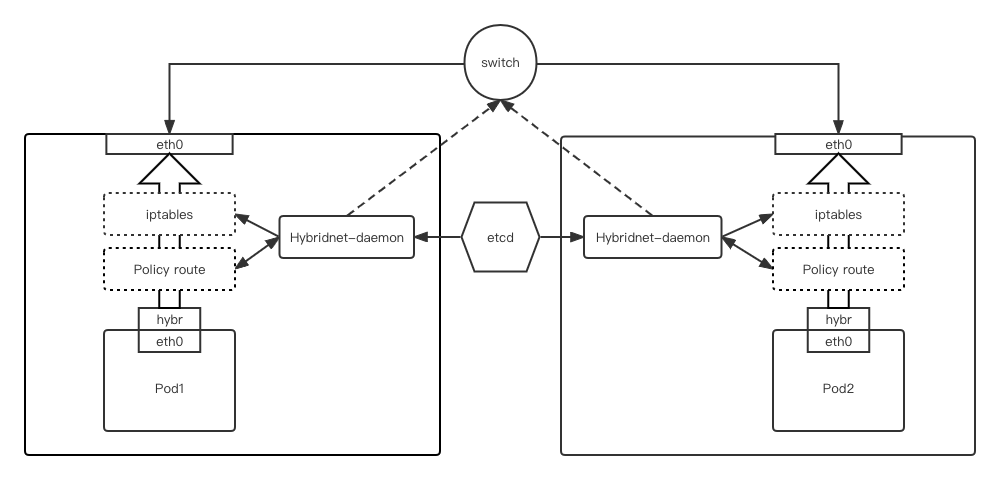

-
Hybridnet-daemon:控制每个节点上的数据平面配置,例如 Iptables 规则,策略路由等
-
通信路径
1、VXLAN 模式
-
同节点通信

-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 39999 路由表,并在 39999 路由表中匹配到 Pod2 的路由规则 -
流量从 hybrYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从pod2的eth0->主机侧的hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到39999路由表,并在39999路由表中匹配到 Pod1 的路由规则 -
流量从 hybrXXX 网卡进入 Pod1 容器网络栈,完成回包动作
-
跨节点通信
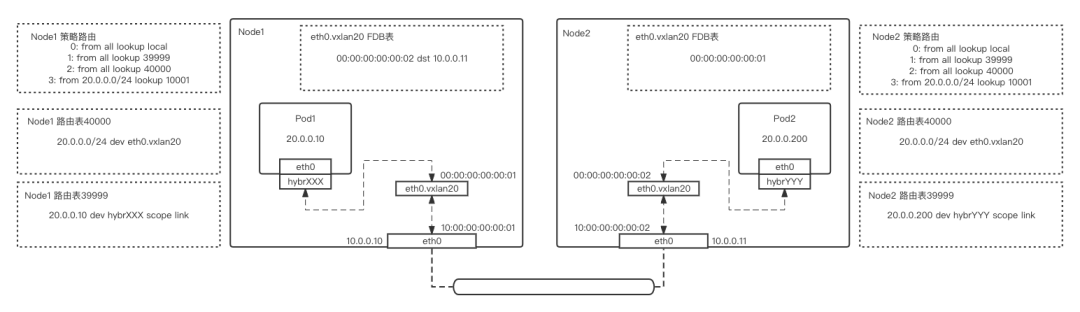
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 40000 路由表,并在 40000 路由表中匹配到 Pod2 所在网段需要发往 eth0.vxlan20 网卡的路由规则 -
eth0.vxlan20 设备的转发表中记录了对端 vtep 的 mac 地址和 remoteip 的对应关系 -
流量经过 eth0.vxlan20 网卡,封装一个 UDP 的头部 -
经过查询路由,与本机处于同网段,通过 mac 地址查询获取到对端物理网卡的 mac 地址,经由 Node1 eth0 物理网卡发送 -
流量从 Node2 eth0 物理网卡进入,并经过 eth0.vxlan20 网卡解封一个 UDP 的头部 -
根据 39999 路由表,流量从hybrYYY网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 40000 路由表,并在 40000 路由表中匹配到 Pod1 所在网段需要发往 eth0.vxlan20 网卡的路由规则 -
eth0.vxlan20 设备的转发表中记录了对端 vtep 的 mac 地址和 remoteip 的对应关系 -
流量经过 eth0.vxlan20 网卡,封装一个 UDP 的头部 -
经过查询路由,与本机处于同网段,通过 mac 地址查询获取到对端物理网卡的 mac 地址,经由 Node2 eth0 物理网卡发送 -
流量从 Node1 eth0 物理网卡进入,并经过 eth0.vxlan20 网卡解封一个 UDP 的头部 -
根据 39999 路由表,流量从 hybrXXX 网卡进入 Pod1 容器网络栈,完成回包动作
2、VLAN 模式
-
同节点通信
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 39999 路由表,并在 39999 路由表中匹配到 Pod2 的路由规则 -
流量从 hybrYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 39999 路由表,并在 39999 路由表中匹配到 Pod1 的路由规则 -
流量从 hybrXXX 网卡进入 Pod1 容器网络栈,完成回包动作
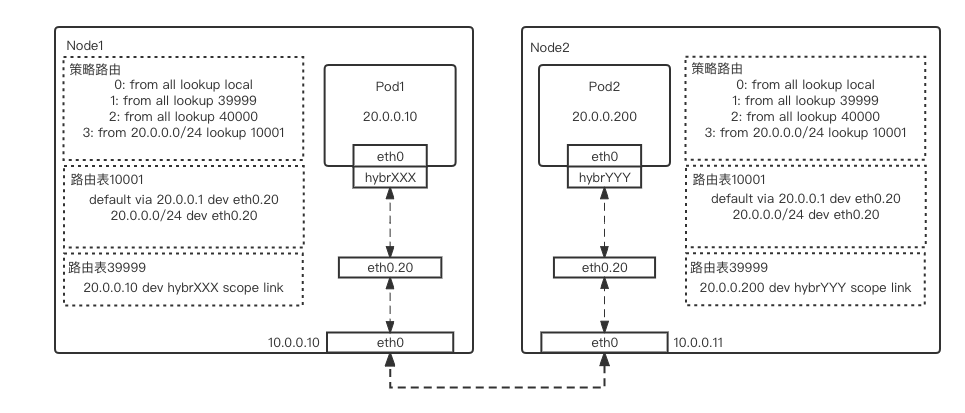
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 10001 路由表,并在 10001 路由表中匹配到 Pod2 相对应的路由规则 -
根据路由规则,流量从 eth0.20 网卡所对应的 eth0 物理网卡发出,并发往交换机 -
在交换机上匹配到 pod2 的 MAC 地址,所以将流量发往 Node2 所对应的 eth0 物理网卡 -
流量被 eth0.20 vlan 网卡接收到,并根据 39999 路由表匹配到的路由,将流量从 hybrYYY 网卡打入 pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 10001 路由表,并在 10001 路由表中匹配到 Pod1 相对应的路由规则 -
根据路由规则,流量从 eth0.20 网卡所对应的 eth0 物理网卡发出,并发往交换机 -
在交换机上匹配到 pod1 的 MAC 地址,所以将流量发往 Node1 所对应的 eth0 物理网卡 -
流量被 eth0.20 vlan 网卡接收到,并根据 39999 路由表匹配到的路由,将流量从 hybrXXX 网卡打入 pod1 容器网络栈,完成回包动作
3、BGP 模式
-
同节点通信
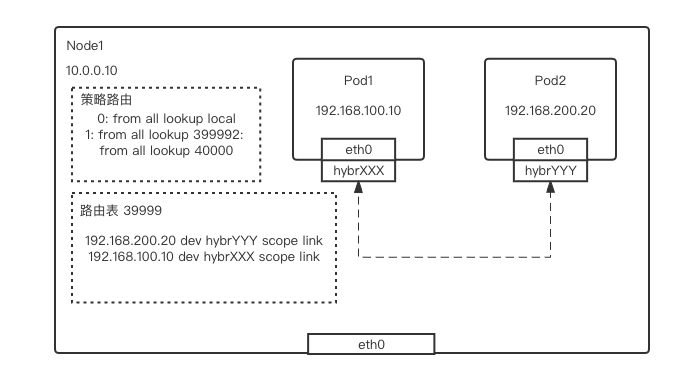
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 39999 路由表,并在 39999 路由表中匹配到 Pod2 的路由规则 -
流量从 hybrYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 39999 路由表,并在 39999 路由表中匹配到 Pod1 的路由规则 -
流量从 hybrXXX 网卡进入 Pod1 容器网络栈,完成回包动作
-
跨节点通信
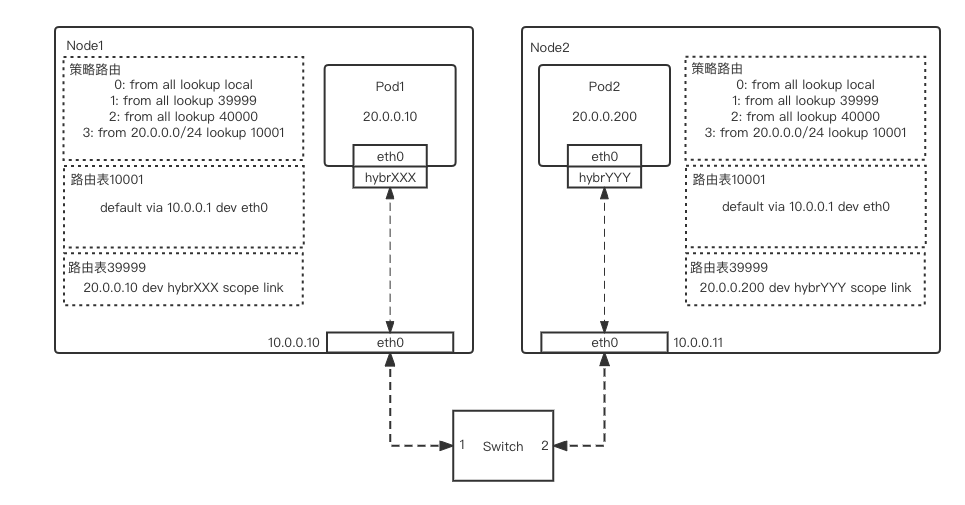
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 hybrXXX,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 10001 路由表,并在 10001 路由表中匹配到默认路由 -
根据路由,将流量发往 10.0.0.1 所对应的交换机 -
在交换机上匹配到 pod2 所对应的特定路由,将流量发往 Node2 eth0 物理网卡 -
流量从 hybrYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 hybrYYY,进入主机网络栈中 -
根据目的 IP,流量在主机的策略路由匹配到 10001 路由表,并在 10001 路由表中匹配到默认路由 -
根据路由,将流量发往 10.0.0.1 所对应的交换机 -
在交换机上匹配到 pod1 所对应的特定路由,将流量发往 Node1 eth0 物理网卡 -
流量从 hybrXXX 网卡进入 Pod1 容器网络栈,完成回包动作
Calico
-
纯三层的数据中心网络方案 -
利用 Linux Kernel 使得宿主机实现 vRouter 来负责数据转发 -
vRouter 通过 BGP 协议传播路由信息 -
基于 iptables 还提供了丰富而灵活的网络策略规则
-
整体架构
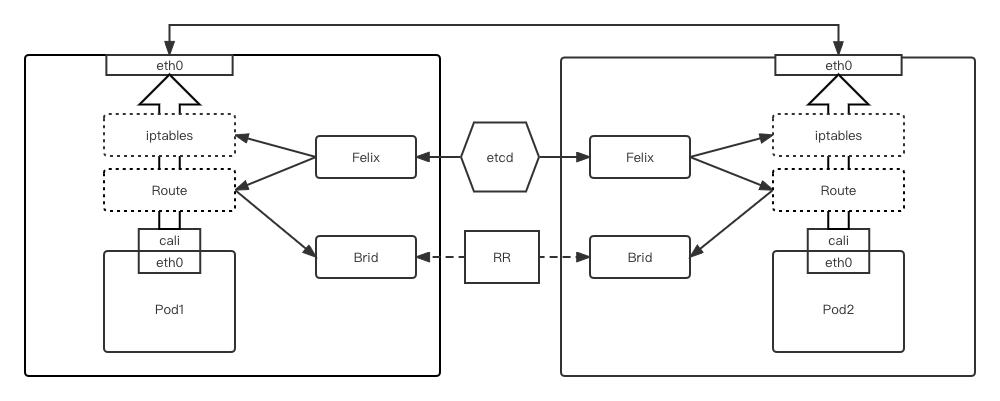
-
Felix:运行在每个容器宿主节点上,主要负责配置路由、ACL 等信息来确保容器的联通状态 -
Brid:把 Felix 写入 Kernel 的路由信息分发到 Calico 网络,保证容器间的通信有效性 -
etcd:分布式的 Key/Value 存储,负责网络元数据一致性,确保 Calico 网络状态的准确性 -
RR:路由反射器,默认 Calico 工作在 node-mesh 模式,所有节点互相连接, node-mesh 模式在小规模部署时工作是没有问题的,当大规模部署时,连接数会非常大,消耗过多资源,利用 BGP RR ,可以避免这种情况的发生,通过一个或者多个 BGP RR 来完成集中式的路由分发,减少对网络资源的消耗以及提高 Calico 工作效率、稳定性
-
通信路径
1、IPIP 模式
-
同节点通信
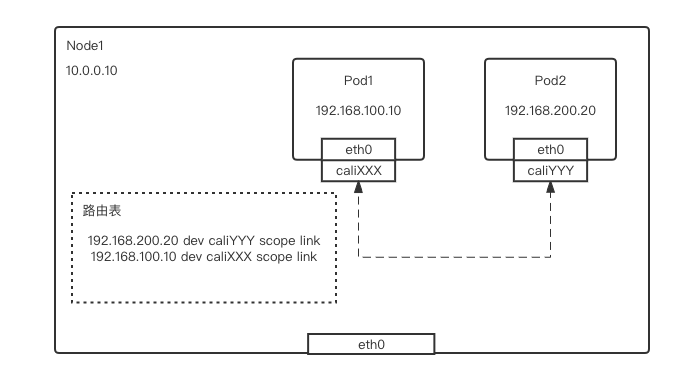
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 caliXXX,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod2 的路由规则 -
流量从 caliYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 caliYYY,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod1 的路由规则 -
流量从 caliXXX 网卡进入 Pod1 容器网络栈,完成回包动作
-
跨节点通信
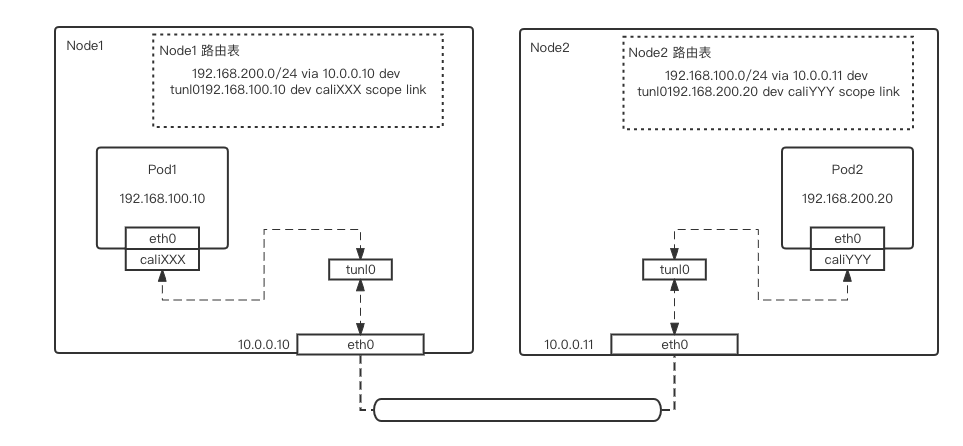
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 caliXXX,进入主机网络栈中
-
src: pod1IP -
dst: pod2IP
-
根据目的 IP,流量在路由表中匹配到将流量转发到 tunl0 网卡上的路由规则
-
src: pod1IP -
dst: pod2IP
-
流量从 tunl0 进行 IPIP 封装(即封装一个 IP 头部),通过 eth0 物理网卡发出
-
src: Node1IP -
dst: Node2IP
-
流量从 Node2 的 eth0 网卡进入 Node2 的主机网络栈
-
src: Node1IP -
dst: Node2IP
-
流量进入 tunl0 进行 IPIP 解包
-
src: pod1IP -
dst: pod2IP
-
流量从 caliYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
src: pod1IP -
dst: pod2IP
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 caliYYY,进入主机网络栈中
-
src: pod2IP -
dst: pod1IP
-
根据目的 IP,流量在路由表中匹配到将流量转发到 tunl0 网卡上的路由规则
-
src: pod2IP -
dst: pod1IP
-
流量从 tunl0 进行 IPIP 封装(即封装一个 IP 头部),通过 eth0 物理网卡发出
-
src: Node2IP -
dst: Node1IP
-
流量从 Node1 的 eth0 网卡进入 Node1 的主机网络栈
-
src: Node2IP -
dst: Node1IP
-
流量进入 tunl0 进行 IPIP 解包
-
src: pod2IP -
dst: pod1IP
-
流量从 caliXXX 网卡进入 Pod1 容器网络栈,完成回包动作
-
src: pod2IP -
dst: pod1IP
2、BGP 模式
-
同节点通信
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 caliXXX,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod2 的路由规则 -
流量从 caliYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 caliYYY,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod1 的路由规则 -
流量从 caliXXX 网卡进入 Pod1 容器网络栈,完成回包动作
-
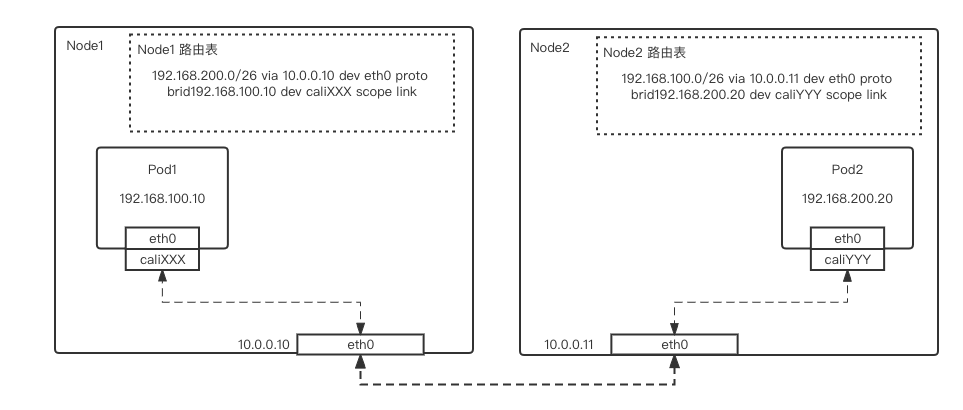
跨节点通信
-
Pod1 流量通过 veth-pair 网卡,即从 pod1 的 eth0->主机侧的 caliXXX,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod2 相对应网段的路由规则,并从 Node1 eth0 物理网卡发出 -
流量从 Node2 eth0 物理网卡进入,并从 caliYYY 网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 veth-pair 网卡,即从 pod2 的 eth0->主机侧的 caliYYY,进入主机网络栈中 -
根据目的 IP,流量在路由表中匹配到 Pod1 相对应网段的路由规则,并从 Node2 eth0 物理网卡发出 -
流量从 Node1 eth0 物理网卡进入,并从 caliXXX 网卡进入 Pod1 容器网络栈,完成回包动作
Bifrost
-
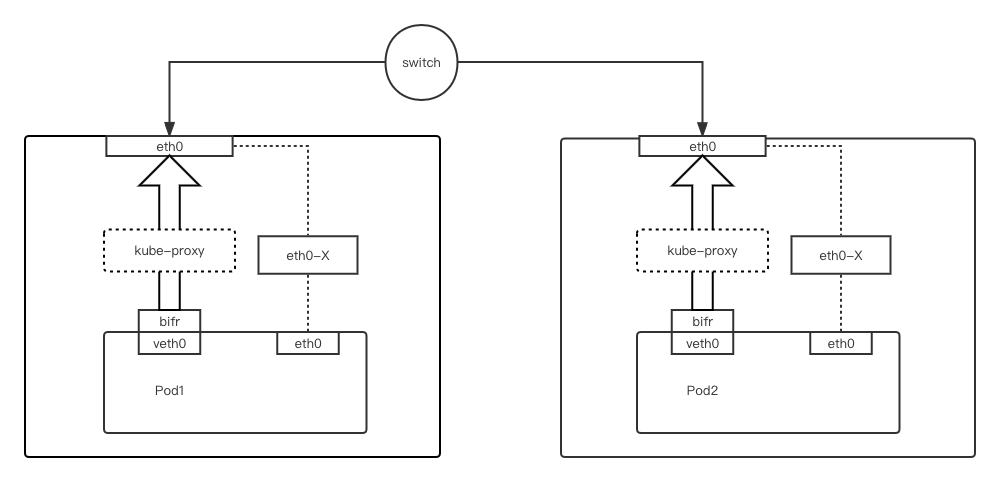
整体架构
-
veth0-bifrXXX:bifrost 对于 macvlan 实现 service 访问的一套解决方案,通过 veth-pair 网卡完成在主机网络栈中的 kube-proxy + iptables 对于服务流量转化为对 pod 的访问 -
eth0:容器内的 eth0 网卡为主机 vlan 子网卡对应的 macvlan 网卡
-
通信路径
1、MACVLAN 模式
-
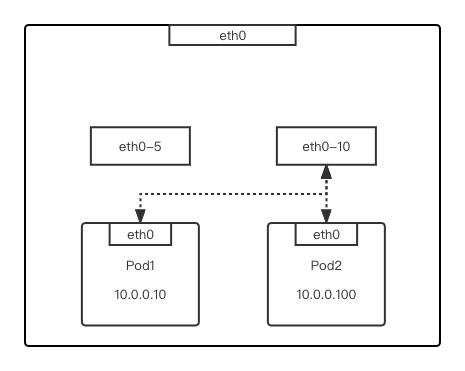
同节点同 vlan 通信
-
Pod1 流量通过 macvlan 网卡,即 pod1 的 eth0 走二层网络进入 eth0-10 vlan 子网卡 -
由于 macvlan 开启 bridge 模式,能够匹配到 pod2 的 MAC 地址 -
流量从 eth0-10 vlan 子网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 macvlan 网卡,即 pod2 的 eth0 走二层网络进入 eth0-10 vlan 子网卡 -
由于 macvlan 开启 bridge 模式,能够匹配到 pod1 的 MAC 地址 -
流量从 eth0-10 vlan 子网卡进入 Pod1 容器网络栈,完成回包动作
-
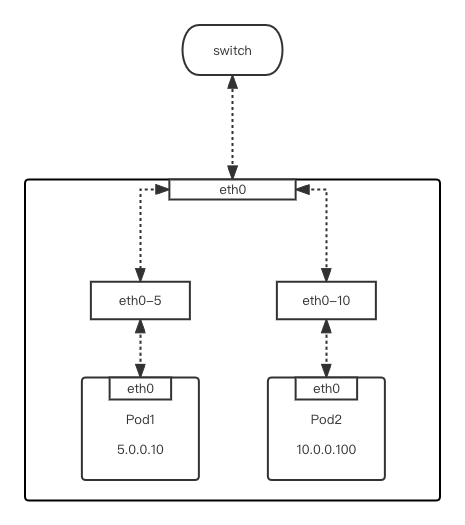
同节点跨 vlan 通信
-
Pod1 流量通过 macvlan 网卡,即 pod1 的 eth0 走默认路由(网关为 5.0.0.1)进入 eth0-5 vlan 子网卡 -
由于在 eth0-5 上找到网关 5.0.0.1 的 MAC 地址,所以将流量从 eth0 物理网卡出打到交换机上 -
流量在交换机上匹配到了 pod2 的 MAC 地址 -
流量进入 Pod2 所在宿主机的物理网卡,并进入相对应的 eth0-10 vlan 子网卡 -
流量从 eth0-10 vlan 子网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 macvlan 网卡,即 pod2 的 eth0 走默认路由(网关为 10.0.0.1)进入 eth0-10 vlan 子网卡 -
由于在 eth0-10 上找到网关 10.0.0.1 的 MAC 地址,所以将流量从 eth0 物理网卡出打到交换机上 -
流量在交换机上匹配到了 pod1 的 MAC 地址 -
流量进入 Pod1 所在宿主机的物理网卡,并进入相对应的 eth0-5 vlan 子网卡 -
流量从 eth0-5 vlan 子网卡进入 Pod1 容器网络栈,完成回包动作
-
跨节点通信
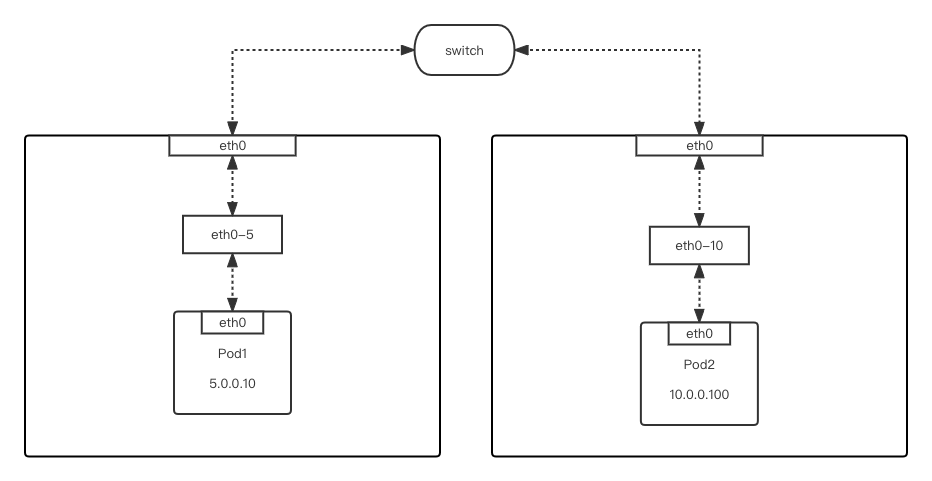
-
Pod1 流量通过 macvlan 网卡,即 pod1 的 eth0 走默认路由(网关为 5.0.0.1)进入 eth0-5 vlan 子网卡 -
由于在 eth0-5 上找到网关 5.0.0.1 的 MAC 地址,所以将流量从 eth0 物理网卡出打到交换机上 -
流量在交换机上匹配到了 pod2 的 MAC 地址 -
流量进入 Pod2 所在宿主机的物理网卡,并进入相对应的 eth0-10 vlan 子网卡 -
流量从 eth0-10 vlan 子网卡进入 Pod2 容器网络栈,完成发包动作
-
Pod2 流量通过 macvlan 网卡,即 pod2 的 eth0 走默认路由(网关为 10.0.0.1)进入 eth0-10 vlan 子网卡 -
由于在 eth0-10 上找到网关 10.0.0.1 的 MAC 地址,所以将流量从 eth0 物理网卡出打到交换机上 -
流量在交换机上匹配到了 pod1 的 MAC 地址 -
流量进入 Pod1 所在宿主机的物理网卡,并进入相对应的 eth0-5 vlan 子网卡 -
流量从 eth0-5 vlan 子网卡进入 Pod1 容器网络栈,完成回包动作
面临的问题及未来发展
Aliware
IPv4/IPv6 双栈
-
背景
-
IPv4
-
IPv4 是互联网协议第四版,是计算机网络使用的数据报传输机制,此协议是第一个被广泛部署的 IP 协议。每一个连接 Internet 的设备(不管是交换机、PC 还是其他设备),都会为其分配一个唯一的 IP 地址,如 192.149.252.76,如下图所示,IPv4 使用 32 位(4 字节)地址,大约可以存储 43 亿个地址,但随着越来越多的用户接入到 Internet,全球 IPv4 地址已于 2019 年 11 月已全数耗尽。这也是后续互联网工程任务组(IEIF)提出 IPv6 的原因之一。
-
IPv6
-
IPv6 是由 IEIF 提出的互联网协议第六版,用来替代 IPv4 的下一代协议,它的提出不仅解决了网络地址资源匮乏问题,也解决了多种接入设备接入互联网的障碍。IPv6 的地址长度为 128 位,可支持 340 多万亿个地址。如下图,3ffe:1900:fe21:4545:0000:0000:0000:0000,这是一个 IPv6 地址,IPv6 地址通常分为 8 组,4 个十六进制数为一组,每组之间用冒号分隔。
-
IPv4 地址数量已经不再满足需求,需要 IPv6 地址进行扩展 -
随着国内下一代互联网发展政策的明确,客户数据中心需要使用 IPv6 来符合更严格的监管
-
现状
|
|
|
|
|
|
|
|
|
|
|
|
-
ipip 是普通的 IPIP 隧道,就是在报文的基础上再封装成一个 IPv4 报文,所以不支持 IPv6 的封包
多网卡(多通信机制)
-
背景
-
部分客户真实 IP 资源紧张,导致无法全部使用 underlay 方案 -
客户希望把 UDP 网络和 TCP 网络分开,导致如基于 TCP 协议的网络模型无法独立存在于 UDP 网络中
-
现状
-
在单一 CNI 调用 IPAM 时,通过 CNI config 配置生成相对应的网卡并分配合适的 IP 资源 -
通过元 CNI 依次调用各个 CNI 来完成相对应的网卡并分配合适的 IP 资源,如 multus 方案
网络流量管控
-
背景
-
传统防火墙在容器云的东西向场景下,难以起到流量管控,需要提供服务间或容器间流量管控的能力
-
现状
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考资料
1、calico vxlan ipv4 overlay组网跨主机通信分析
https://www.jianshu.com/p/5edd6982e3be
2、Qunar容器平台网络之道:Calico
http://dockone.io/article/2434328
3、最好的vxlan介绍
https://www.jianshu.com/p/cccfb481d548
4、揭秘 IPIP 隧道
https://morven.life/posts/networking-3-ipip/
5、BGP基础知识
https://blog.csdn.net/qq_38265137/article/details/80439561
6、VLAN基础知识
https://cshihong.github.io/2017/11/05/VLAN%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/
7、Overlay和Underlay网络协议区别及概述讲解
https://www.cnblogs.com/fengdejiyixx/p/15567609.html#%E4%BA%8Cunderlay%E7%BD%91%E7%BB%9C%E6%A8%A1%E5%9E%8B
8、东西向流量牵引方案小结
http://blog.nsfocus.net/east-west-flow-sum/
9、容器网络接口(CNI)
https://jimmysong.io/kubernetes-handbook/concepts/cni.html
10、K8s 网络之深入理解 CNI
https://zhuanlan.zhihu.com/p/450140876
本文转载自陈赟豪(环河) 阿里巴巴中间件,原文链接:https://mp.weixin.qq.com/s/Hr9qpkfTWP9jxYR2sNOeFA。