


分享嘉宾:刘嘉承 Alluxio 核心组研发工程师
编辑整理:曾新宇 对外经贸大学
出品平台:DataFunTalk
导读:今天分享的题目是Alluxio元数据和数据的同步,从设计实现和优化的角度进行讨论。主要包括以下几个方面的内容:
-
Alluxio简介
-
Alluxio的数据挂载
-
Alluxio和底层存储的一致性
-
Alluxio和UFS的元数据/数据同步
-
元数据同步的实现原理和优化
-
对不同场景的推荐配置
01
Alluxio是云原生的数据编排平台,通过解耦计算和存储层,在中间产生了一个数据编排层,负责对上层计算应用隐藏底层的时间细节。Alluxio提供了统一的存储命名空间,在中间层提供了缓存和其他数据管理功能。在下图可以看到有Spark、Hive、Map reduce这一类传统的Hadoop大数据计算应用、Presto 这种OLAP类型的数据分析,还有像Tensorflow、Pytorch这样的AI应用。存储层比较丰富,包括各种各样的存储。

图1 Alluxio简介
下面是Alluxio用户列表,这些公司都公开展示了Alluxio的使用场景。通过粗略分类,看到非常多的行业,包括互联网、金融、电子商务、娱乐、电信等。感兴趣的同学可以关注公众号,上面有相关文章的汇总。

图2 Alluxio的用户展示
02
Alluxio数据挂载
这部分将首先回顾Alluxio如何通过数据挂载实现统一编排层;之后讨论Alluxio如何和底层存储保持一致;介绍元数据和数据同步功能;Alluxio的时间原理和优化;最后对不同场景的推荐配置给出建议。
1. Alluxio统一的数据命名空间
首先介绍数据挂载这个功能。Alluxio通过把底层存储挂载到Alluxio层上,实现了统一的数据命名空间。

图3 Alluxio统一命名空间
上图的例子中Alluxio挂载了HDFS和对象存储。Alluxio的文件系统树就是由左右两棵树合成,形成了一个虚拟文件系统的文件系统树。它可以支持非常多的底层存储系统,统一把它们称作Under File System。称为Under是因为它们都处于Alluxio的抽象层下。Alluxio支持各种各样不同的底层存储系统,比如不同版本的HDFS,支持NFS, Ceph, Amazon S3, Google Cloud之类不同的对象存储。除此之外还支持非常多其他类型的对象存储,比如微软Azure、阿里、华为、腾讯,也包括国内其他供应商,如七牛对象存储。左下图中的例子是在自己的电脑上运行Alluxio,可以挂载不同的存储,比如挂载HDFS,另外还可以挂载不同版本的HDFS,挂载对象存储,挂载网盘。
2. Alluxio挂载点
Alluxio的统一命名空间,实际就是把挂载合成了一个Alluxio的虚拟层。Alluxio的挂载点可以粗略分成两种:
-
根挂载点
-
嵌套挂载点
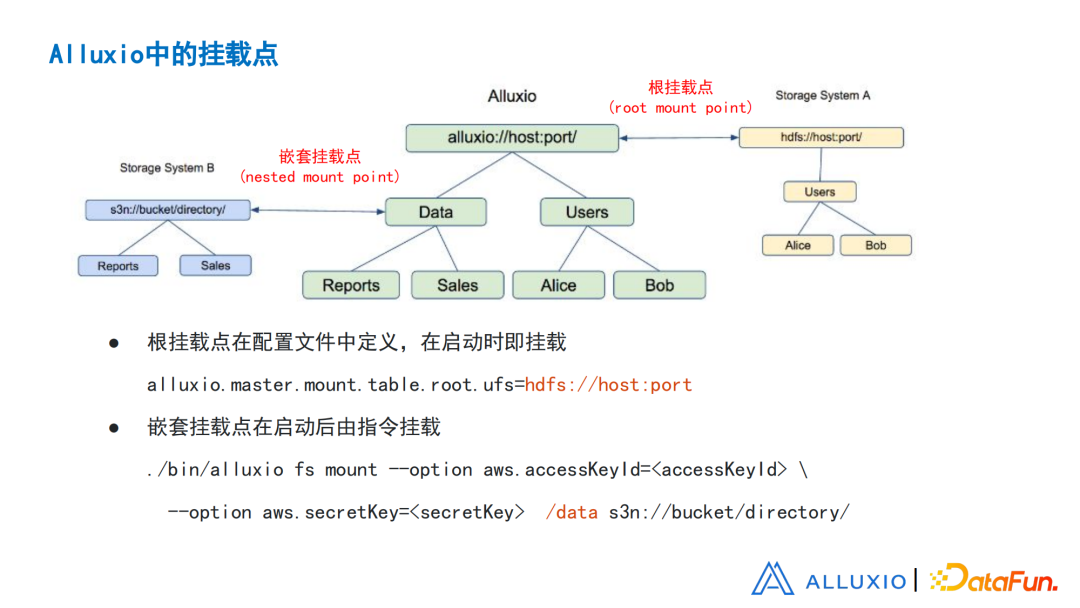
图4 Alluxio挂载点
根挂载点直接挂在根节点上,组成了Alluxio的根节点。如果没有根节点,无法产生,继续形成下面的结构。所以要求在配置文件里面定义根挂载点,系统启动的时候就进行挂载,不挂载就没有办法启动。
嵌套挂载点比较灵活,可以通过指令进行挂载。通过这个命令行,发出通知,做挂载的操作。同样地,可以挂载,也可以卸载,就是把Mount换成Unmount。嵌套挂载点是嵌套在目录的下面,可以挂在某个部分下面,不一定挂载在根节点下面。这里有个要求,即两个嵌套点的树不能互相覆盖,这样带来的好处是比较灵活。如果根挂载点将来需要更换,为了避免需要改配置和重启服务,可以使用一个dummy的根挂载点,比如就挂载在本地路径下面,不使用它,且不在它下面创建任何文件,它存在的唯一目的就是可以启动Alluxio服务。然后在此基础上,把所有要管理的存储,都以嵌套挂载点的方式挂载上去。之后如果要改变,就直接卸载更换为其它挂载点,这样就很灵活。所有挂载和挂载操作,都会记录在日志里,重启系统,并重启服务之后,无需再手动操作。
3. Alluxio策略化数据管理
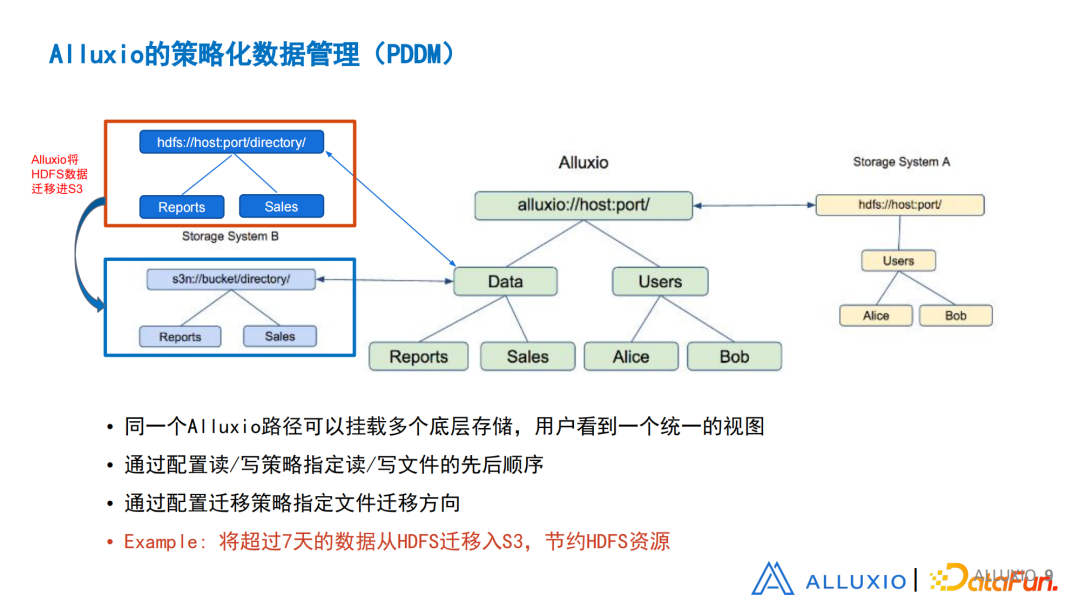
图5 Alluxio策略化数据管理
挂载操作有一个进阶版操作,目前只包含在商业版本里面。所做的事情就是让用户可以把两个存储挂载到同一个路径下,可以互相覆盖。同时通过配置读写策略,定义读写文件到哪个存储里,并给出操作的先后顺序。同时Alluxio有一个迁移策略,让文件可以自动在Alluxio的管理下,在多个存储之间进行迁移。例如,把HDFS和对象存储同时挂载到同一路径下,上层用户只能看到这样一棵树,但是实际上背后有两个不同的存储。通过配置,让Alluxio把HDFS的数据,根据一些规则,定期迁移进S3,例如规定将超过七天的数据,认定是不常用到的冷数据之后,把它从HDFS的集群拿出来,迁移到S3,节省HDFS的存储空间。
03
Alluxio底层存储一致性
在把底层存储挂载到Alluxio的统一命名空间上之后,如何保持Alluxio和底层存储的一致性?我们在这一部分进行分析。

图6 Alluxio与一致性
Alluxio和底层存储的一致性,要从Alluxio命名空间中文件的来源说起。文件的操作分为两类:
-
一类是写,上层应用通过Alluxio创建一个文件,通过Alluxio写入UFS;
-
一类是读,上层应用通过Alluxio读一个文件,当发现自己没有这个文件的时候,Alluxio从UFS进行加载。
一致性可以分为两个部分:
-
Alluxio UFS元数据的一致性
-
Alluxio UFS数据的一致性
下面先看写数据的一致性。
1. Alluxio写文件流程
首先Alluxio写文件的流程可以把它抽象成两步。第一步是客户端到Alluxio,第二步是Alluxio到UFS。

图7 Alluxio写文件流程
其中的每一步都可以抽象成下面的三个步骤:
-
创建文件
-
写数据
-
提交文件
同样Alluxio到存储系统也可以同样地抽象提取。
客户端和Alluxio之间,主要流程分三步:
-
客户端向发请求创建一个文件;
-
找到Alluxio Worker写具体对应的数据;
-
在写完数据之后,提交这个文件。
同样Alluxio到存储系统也抽象成三步。不同存储系统的抽象和具备的一致性,都不同,此处进行抽象只是为了便于理解。比如要求强一致性保证,但是很多对象存储,给的一致性保证会弱很多,比如写进去之后不能马上读到这个数据。在这里,不考虑这种本身的不一致性的问题。假设Alluxio向存储提交了之后,就能保证存储端的文件就是需要的样子。
Alluxio为了满足不同的需求,设计了几种不同的写策略,下面逐一分析写策略的流程以及带来的数据一致性保证。
2. Must-Catch写模式
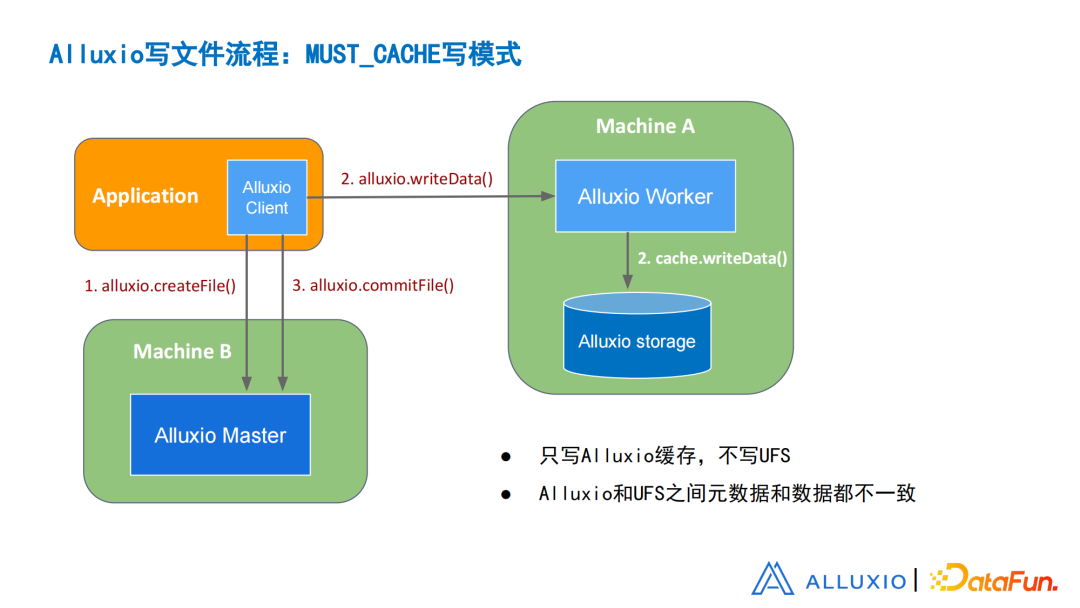
图8 Alluxio:MUST_CACHE写模式
首先是常用的MUST_CACHE模式。在这种模式下,只会写Alluxio缓存不写UFS。这个模式分为三步:
首先客户端会向Alluxio 发出创建文件请求,创建的文件只是一个空文件,作为一个占位;
之后Alluxio Worker实现具体数据的写操作,具体数据会被分割成多个数据块,作为Block存在于Alluxio Storage里面。
在缓存写之后,客户端对Master做提交文件的请求,告诉Master写了这些数据块,写到Worker,然后更新对应的元数据,也知道了这些数据块和Worker所对应的位置。
在这样的流程之后,Alluxio不会向UFS创建这个文件,也不会写这个文件,所以Alluxio和UFS之间的元数据和数据都不一致。
3. Through写模式
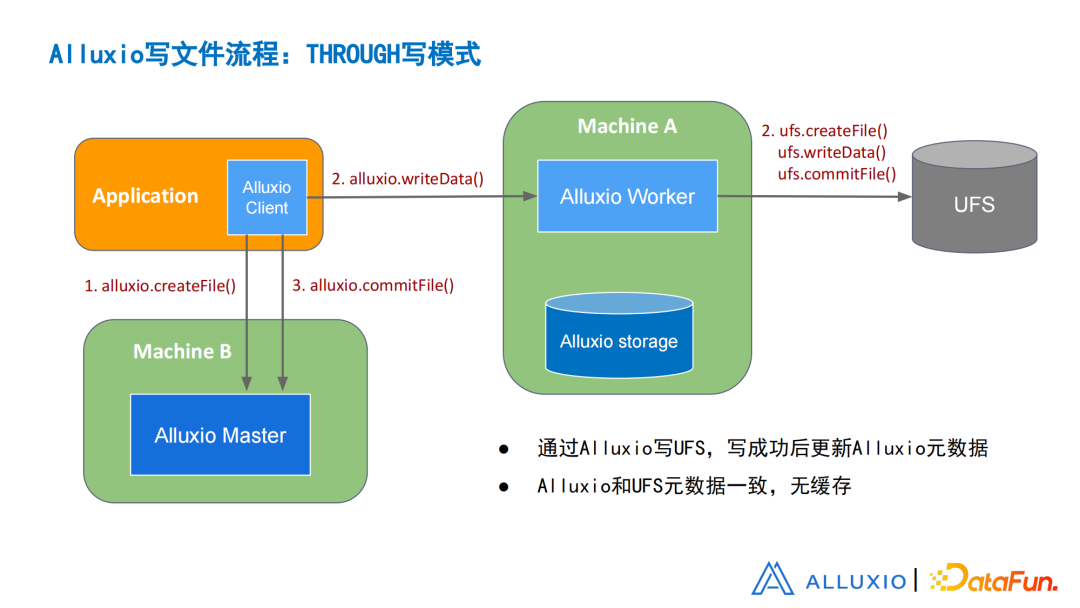
图9 Alluxio:Through写模式
THROUGH的写模式有所不同,这里同样的 createfile() 发出一个请求,然后找Worker写数据。Worker会做三件事:
-
创建文件
-
写文件
-
提交文件
在第二步结束后,客户端会向Alluxio 提交这个文件。因为Alluxio 的提交是发生在文件写完了之后,所以,Alluxio和UFS此时的元数据是一致的。因为没有数据缓存,所以也不存在数据一致性的问题。
Alluxio的缓存是在需要读之后才会产生,而这种THROUGH模式是比较适合用来写已知不再会被Alluxio读取的数据。所以在这种情况下,元数据是一致的,也不存在数据不一致的问题。
4. CACHE_THROUGH写模式
下面的CACHE_THROUGH模式就是前面两种模式的结合。

图10 Alluxio:CATCH_THROUGH写模式
唯一的不同点是在第二步,写缓存的同时又写了UFS。在这两个都成功之后,第二步才会成功,之后客户端才会做提交操作。同样的道理,因为Alluxio在UFS更新之后才更新,所以两者的元数据和数据都是一致的。
5. ASYNC_THROUGH写模式
最后是ASYNC_THROUGH异步写模式,和前面的模式唯一的区别是第二步中的UFS写变成了异步,放在了第四步。

图11 Alluxio:ASYNC_THROUGH写模式
在Alluxio写缓存之后,首先创建了文件之后,在第二步写了Alluxio缓存;在第二步缓存写完之后,Worker就向客户端返回成功;然后由客户端向Master提交文件。注意在这个时候,Worker还没有去UFS创建这个文件,也没有向UFS写文件。在Alluxio向客户端返回请求成功之后,在之后的某个时间,由Job Service把这个文件创建到时里面,并且持久化。
需要注意:在异步的模式下,持久化由于某些原因失败了,比如Alluxio成功之后,突然有人直接向里面创建了一个同名的文件,在第四步的时候,由于缓存和之间产生了不一致,导致这个文件无法创建、无法写入。这个时候,Alluxio会有不一致的问题,此时需要人工介入来解决这个冲突。
6. 读文件流程
前文介绍以上四种不同的写模式以及一致性保证,现在来看Alluxio的读文件流程。读文件也可以粗略分成两种:冷读和热读。

图12 Alluxio:读文件流程
简单来说,冷读情况下Alluxio不知道这个文件,需要从加载元数据和数据。热读的时候,缓存命中,不需要加载元数据和数据。
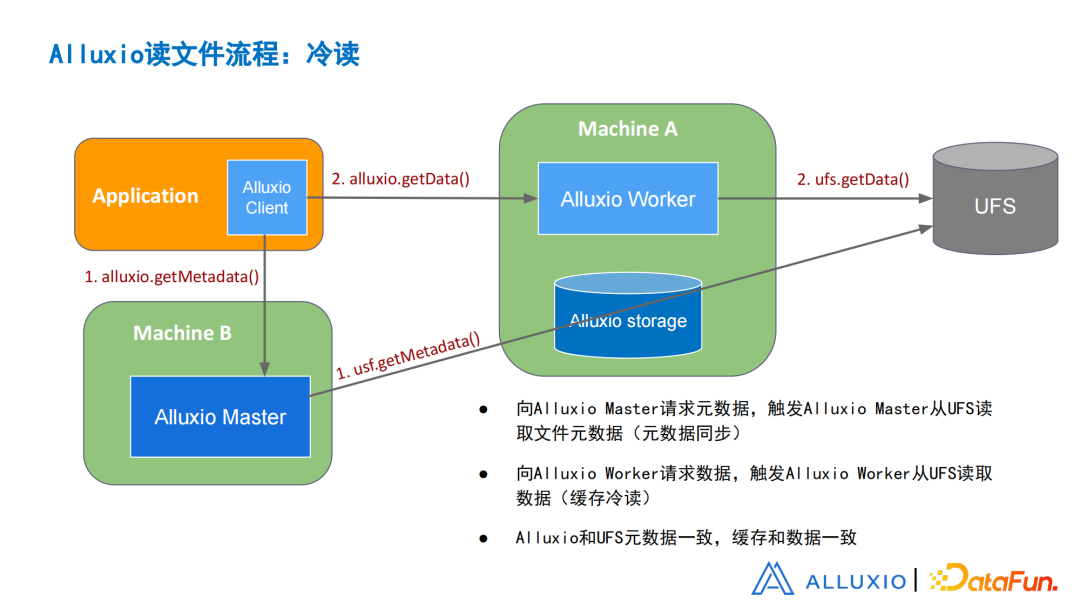
图13 Alluxio:冷读文件
在冷读流程里,客户端向Alluxio请求元数据,此时Master还没有这个元数据,所以会向UFS发出一个请求,并从UFS加载这个元数据,这也称之为元数据同步。
在客户端具体读数据的时候,客户端找到Worker,Worker此时还没有缓存,于是Worker会向UFS做缓存的加载,这就是常说的缓存冷读。在做完这两个步骤之后,缓存是和元数据一致的。
② 热读文件

图14 Alluxio:热读文件
在热读的情况下,元数据可以在缓存里面找到,数据可以在Worker里面找到;此时不会有对UFS的读请求。
在缓存命中的时候,如何保证缓存与和是一致的?这里包括元数据的一致和数据的一致。这个简单的来说,就是通过Alluxio的元数据和数据的同步机制,也就是下一部分的内容。
04
Alluxio和UFS元数据和数据同步
1. 检查Alluxio元数据/数据一致性
首先考虑这个问题:在什么时候需要检查Alluxio的元数据和数据的一致性?
首先在写数据的时候需要检查。如果这个文件在已经存在了,作为缓存,除了放弃这个操作之外,也没有其他的选项。因为不能在用户不知情的情况下,覆盖掉用户在里面的数据。
在读数据的时候,同样需要考虑如果文件在里面已经更新了,那缓存也需要对应进行更新,需要UFS考虑里面的文件是否发生了变化。

图15 检查Alluxio:元数据/数据一致性
2. 保证Alluxio元数据/数据一致性
元数据和数据的一致性分成两步来逐个讨论。首先讨论如何保证Alluxio元数据和一致。Alluxio通过两种方式来保证:

图16 保证Alluxio:元数据/数据一致性
第一种是通过基于时间的假设,在里面的文件,在一段时间内它是不变的。判断方法是在每一次文件源信息、元数据请求的时候,检查Alluxio的元数据是否足够新。
这个判断分成了两个不同的部分:
-
在每一次请求的时候
-
检查这个元数据是否足够新
这种元数据的同步机制是惰性的,只有在请求的时候才会进行检查。这样设计的理念是尽量避免访问慢的操作、昂贵的操作。这样的事情越少越好、越懒越好。如果Alluxio所知的文件信息足够新,就假设Alluxio和UFS是一致的。如果不够新,就放弃这个假设再做一次同步;同时更新Alluxio里面的元数据。
② 基于通知
另外一个思路就是抛弃基于时间的假设,基于通知,依赖文件更改的告知。这个不是假设,是一个确定的信息。如果没有通知文件有变化,就确定Alluxio和现在的文件是一致的。
其次是如何保证Alluxio和UFS的数据保持一致。思路也非常简单:保持数据的一致,只需要确定元数据及是否一致。这里做出的假设是:如果UFS的数据,文件内容有所改变,那这个改变一定会反映在文件的元数据上。要么是文件的长度改变,要么是这个文件的Hash,也就是哈希值会发生改变。通过观察这个Alluxio和的元数据,可以发现这些变化点。
如果基于这个假设,Alluxio的元数据和UFS保持一致时缓存和UFS也会一致。如果观察元数据发现内容有变化,那么就更新元数据并抛弃已有缓存。在下一次读的时候,重新加载缓存。如果发现文件的内容没有变化,只做必要的元数据更新,不抛弃数据缓存。
3. 数据同步机制
Alluxio提供两种同步机制,这里先介绍时间戳机制,再介绍基于消息的同步机制。
① 基于元数据时间戳的同步机制
下面先看一下第一种机制,基于元数据时间戳的同步机制。

图17 基于元数据时间戳同步
时间戳主要是通过配置项alluxio.user.file.metadata.sync.interval,通常称之为sync.interval或者interval。比较同步数据上次同步的时间戳和配置项。配置项中有几种不同的配置方式:
-
配置为-1,就只在第一次加载的时候进行同步,之后就永远不再和这个底层存储去做同步了;
-
配置为0,每一次访问的时候,都会进行同步,抛弃所有知识,不做任何假设。
-
比较常用的一种是用户指定一个配置值,做一个假设,如果上一次同步的时间还没有超出这个时间,就假设原信息是新的。这个假设是基于对这个文件的了解,比如:知道文件的来源,知道文件由哪些业务流程产生的。在此基础上,可以做一个合理的推断:只需每隔照一段时间去检查的就足够。如何进行配置,请看下图。
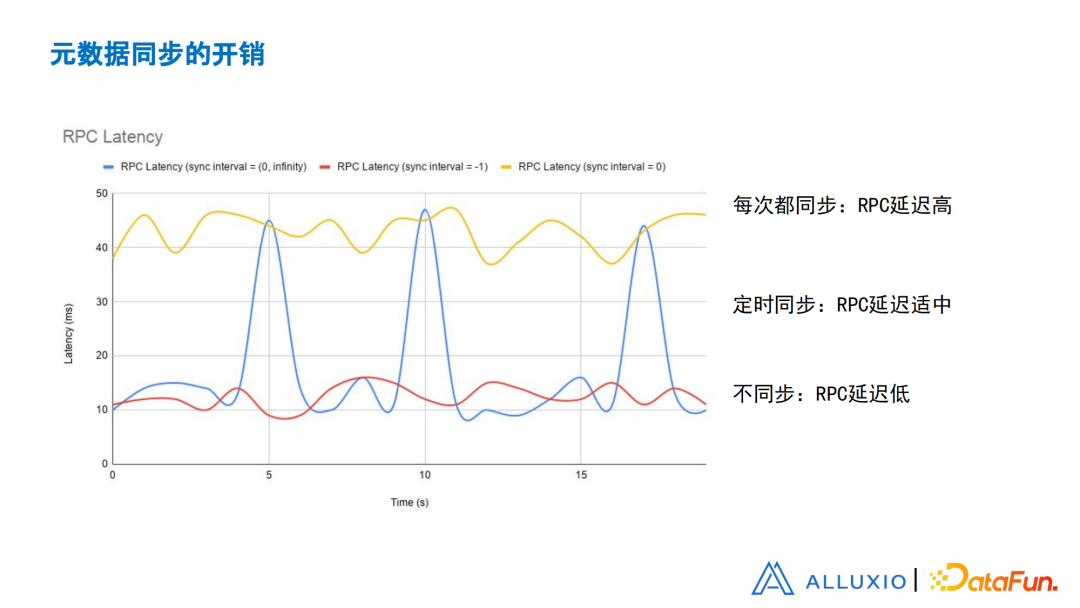
图18 元数据同步的开销
-
这张图展示了不同的配置方式带来什么样的行为。这张图的纵轴是一个RPC完成所需时间。不同的环境、不同测试方式都会得到不一样的结果。主要看相互之间的大小关系。如果把interval设成零,就是每一次都同步,那每一个RPC都会有元数据同步的开销,延迟会比较高;
-
如果interval设为-1,完全关掉同步,只要文件存在于Alluxio里面,完成第一次加载,之后的每一次,RPC都会有一个低的延迟,因为没有做的同步操作。
-
最常用的是设置成一个适中的值,实际上带来这样一个结果,就是如果还在interval之内,RPC能得到快速的返回;如果达到了interval,触发一次同步,那在下一次RPC就会有一个比较高的开销。通过这样的方式,实际上把这个元数据同步的开销,平均到每一次的RPC请求中。这也大家比较喜欢的方式,因为取得了一个平衡。
② 同步时间间隔配置

图19 同步时间间隔配置
这个时间间隔具体配置有三个,优先级是由低到高,后面的配置可以覆盖前面的配置。
-
第一种最基础是配置文件/环境变量方式,是最不灵活的方式。因为整个集群里面文件都不同,假设也不同,很难使用同样间隔,所以一般都给一个默认值。
-
第二种方式是基于路径的设置做配置。比如:通过管理员指令给这个Alluxio的/data_center1路径,添加property也就是sync.interval。意思就是假设来自数据中心这个路径下的所有文件夹下面所有路径,都按照一个小时一次的时间间隔,在超过一个小时之后,才去再进行一次原文件的同步。这样的假设的根源就是:知道来自数据中心的文件,它的更新不是特别频繁,那可以做出这样的一个判断。
-
第三种方式是直接写在指令里面。ls是大家最常用的命令。比如:对/data/tables下面的文件做ls操作的时候,给予一个大于零的值。意思就是:如果因为不小心误操作或者多做了几次ls,不小心多敲了几次回车或者脚本写错,至少还有一个回旋的余地,不会一下子触发大量元数据同步的操作。
Alluxio还提供一些语法糖指令,比如:loadMetadata指令就是专门为了触发元数据同步。如果加上-F选项,实际上的意思就是把sync.interval设成0,相当于强制进行一次元数据的刷新。ls和metadata这两个指令的区别:ls把文件展示在面前,ls的RPC有网络开销, 会把信息发给你,客户端要保存下来,并且展示出来。这个不是每一次都需要,假如只是想要触发一次元数据的同步,只需loadMetadata就可以,返回值只有成功或者失败,可以节约很多网络带宽和的内存开销。
③ 基于消息的同步机制
以上是基于时间的同步机制,下面看一下另外一种思路,就是基于消息同步机制。

图20 基于消息同步
首先需要Alluxio 2.0版本以上,以及Hadoop 2.6.1版本以上,因为HDFS底层的inotify机制是在2.6版本加进去的。实际上发生的就是从HDFS的namenode直接读取HDFS有哪些文件发生了变化。实现原理就是维护了一个Alluxio和namenode之间通过HDFS的inotify机制保持了一个信息流。Alluxio定期心跳从这个信息流里面去读,有哪些文件发生了变化,然后根据这个变化的具体的类型,Alluxio决定要不要再去namenode触发一次元数据的同步。
这样的元数据同步是有的放矢,不再是基于时间猜测。每一次同步都是有理有据,知道文件已经改变,称为Active Sync,也是因为在这里化被动为主动,不再被动去猜,而是主动知道了有哪些变化,然后主动去触发同步。但是这个inotify只能告诉告诉我们哪些文件发生了变化以及变化是什么类型,包含的信息很少,具体要做同步还需要一个元数据同步的机制,所以这一步是绕不开的。具体的使用也非常简单,可以通过指令来开启它,也可以关闭,或者查看现在有哪些HDFS路径或挂载点开启了这个功能,这些指令也受Journal日志保护,当开启了Active Sync功能之后,就会被记录在Journal日志里面,在重启集群之后,无需重敲一遍指令。
4. Active Sync性能取舍
Active Sync也不是万能药,它做了一些功能的取舍。每种设计都有它的取舍,因此也有适合和不适合的场景。

图21 Active Sync性能取舍
Active Sync在确定了文件更改之后,再去做同步操作,它省掉了那些没有变化、无用的同步操作。但是每一个文件的更改,都会触发同步操作。具体文件的更改并不一定是客户端的请求,虽然是主动加载它,但实际上并不一定用到,有可能是多余的操作。
Active Sync和基于时间戳的同步机制,各有利弊。具体选择时需要进行考量,在后面的章节会总结分析哪种场景适合的配置。同时要注意Active Sync只支持HDFS,原因是只有HDFS提供API,其他存储没有机制可以知道有哪些文件发生了变化,所以没有办法来实现。
05
元数据同步实现与优化
在了解了机制后,现在了解一下元数据同步的实现原理,然后再看元数据同步的优化。
1. 元数据同步原理
目前元数据的同步粗略分为左下角的这几个步骤。左上角我们列出了元数据同步的参与者。包括了RPC线程,就是Master端,来自于RPC的线程池。第2个参与者称作同步线程池(sync thread pool)。第3个参与者称作预取线程池(prefetch thread pool)。这里有一个InodeTree,就是Alluxio里面维护的所有文件的元数据,形成了一个树状的结构。图中的UFS代表着实际的底层存储。所有对UFS的连线都是一个对外部系统的RPC,是比较昂贵的操作。
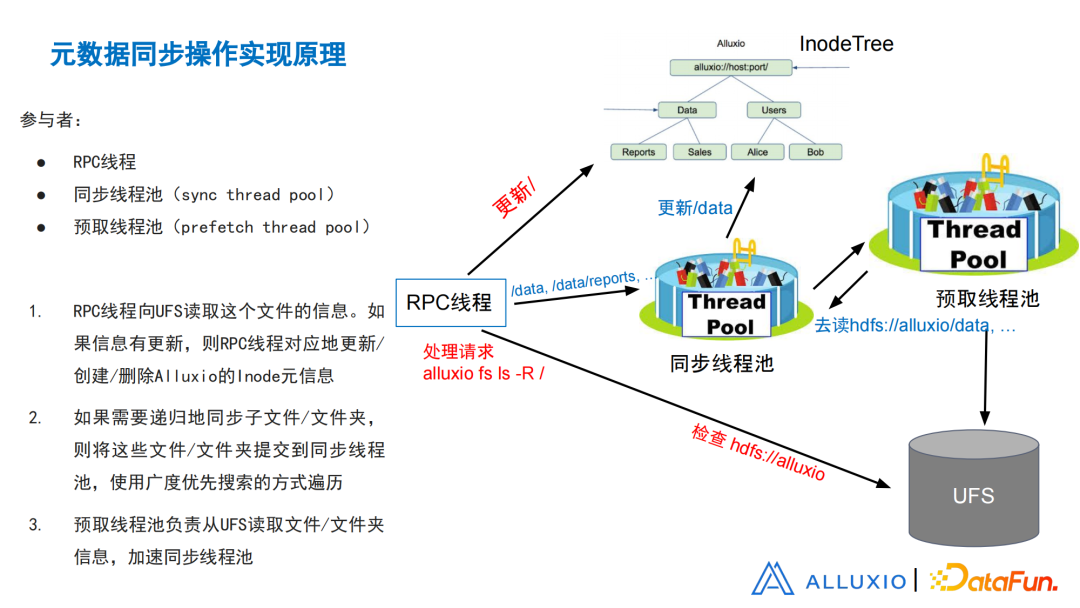
图22 元数据同步原理
同步步骤分三步:
① RPC线程向UFS读取文件的元信息。在处理请求ls -R 时,对根节点全量的文件树进行一次ls操作。此时基于时间戳,需要触发元数据同步, RPC线程就会读取文件根节点的信息,检查挂载HDFS://alluxio根节点的信息。如果发现信息有更新,就去InodeTree里面找根节点,则RPC线程对应地更新/创建/删除Alluxio的Inode元信息,并且这个节点进行更新。
② 如果在处理递归的时候,发现下面还有其他目录,整棵树都需要进行一次搜索,此时把递归文件/文件夹提交到同步线程池(sync thread pool)。用广度优先搜索的方式进行遍历,也就是常说的BFS。当提交这个任务后。会去同步线程池,在BFS的过程中,按照一定的顺序遍历这棵树,data -> user -> others -> report …
在这个过程中,主要是做两件事情:
-
如果发现走到某个节点,需要对进行一次请求,它不会自己做这个请求,而是把这个请求交给预取线程池(prefetch thread pool)。
-
如果发现下一步要去遍历User -> others -> report …
就把任务提前交给预取线程池,告诉它去读HDFS里面相关的这些路径,这也就是称为预取的原因。在真正处理这个路径之前,就提前告诉它,因为操作会需要很长的时间,保证性能最好的方式就是提前做这个事情;等任务处理到的时候,已经准备好了。这样最高地利用了多线程的并发。
在处理每个节点的时候,确认预取线程池准备好的结果;如果有更新,就更新自己的InodeTree。
③ 预取线程池负责从读取文件或者文件夹信息,把结果交给这个同步线程池,来加速这个具体的同步过程。
2. 性能优化-缓存
在这个时间原理的基础上,进行了一系列的优化。

图23 性能优化-缓存
首先就是做了缓存的优化。主要的设计理念就是因为UFS操作非常贵、非常慢,希望尽可能多的地缓存结果,节省的操作。
缓存优化涉及下面这几种缓存:
-
缓存了哪些路径不存在,因为确定这个缓存不存在,需要去读取UFS,又需要有一个外部的RPC;
-
缓存哪些UFS文件最近被读取过,和时间戳相互配合。知道上一次读取的时间戳,就可以根据时间戳确定是否再次读取;
-
缓存UFS文件的具体信息,预取线程和同步线程用来交换信息的数据结构。在预取完之后把结果放到缓存里,由这个同步线程将结果更新进Alluxio InodeTree。
3. 算法优化-锁优化
在缓存优化之外,基于Alluxio的版本迭代,也做了各种各样的元数据同步优化,其中比较大的就是算法的优化。
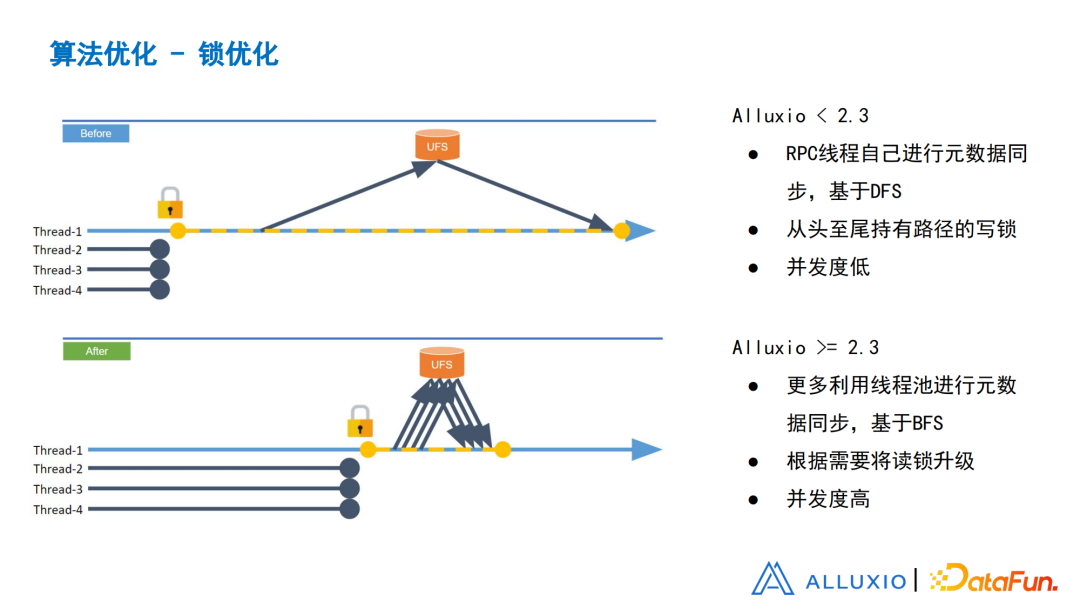
图24 算法优化-锁优化
在Alluxio2.3版本之前,所有的RPC线程是自己进行元数据的同步。如果递归基于DFS自己遍历这棵树,从头到尾都持有路径的写锁。如果是递归,实际上是写锁锁住了整个子树。在锁住子树的过程中,其他线程就无法读取子树里的内容,并发度低,由于是单线程,做了非常多需要Block时间长的操作。
在Alluxio2.3里面非常大的优化,就是把它改成了多线程并发同步的算法,更多利用线程池操作,DFS改成了BFS。根据需要,读锁升级,而非从头至尾持有写锁。读写锁的好处就是让不同的线程之间有了更高的并发度。这样在同步某一棵子树的过程中,其他线程还有机会可以读到这里面的内容,所以整体的并发会更高。
4. 性能优化-调整并行度
第三个优化来自于用户对线程池的配置。

图25 性能优化-并行度
在Alluxio 2.3里面加入了线程池之后,可以通过配置参数调整元数据同步的并行度。之前单线程没有配置可言。调整并行度一般是通过这三个参数。
-
第一个参数控制了单个RPC请求里面的这个元数据同步,它的BFS并行度调的越高,并行度越高,更快的机会也就越大,同时对这个系统的占用也会越多;
-
第二个是同步线程池大小;
-
第三个是预取线程池大小。
两个线城池的大小,建议配置成CPU数的倍数,具体比例以及系统应该配多大,取决于这两个线程所做工作的时间,以及中间的配合方式。所以没有给出统一建议,建议根据具体程序运行的时候,CPU比如可以做一些火焰图、分析延迟以及inodetree更新的延迟,做一个更加合理的配比。默认的配比都是CPU的倍数,如果没有在无数据同步看到非常明显的瓶颈,不需要进行特别细粒度的调节。
06
对不同场景的推荐配置
最后针对不同的场景具体分析问题,推荐比较好的配置。
1. 场景1

图26 场景一配置
最简单的场景就是:所有的写和读全都经过了Alluxio。无疑Alluxio所有的元数据都是最新,此时无需做元数据同步。可以关闭元数据同步,提升性能。
2. 场景2
第二个场景稍微复杂一些。大部分的操作经过Alluxio,但是不排除还有一些场景,会绕过Alluxio直接改动原来里面的文件。

图27 场景二配置
在这种场景下,为了保证Alluxio和UFS元数据和数据的一致,还是要保留一部分元数据同步的操作。在这里分HDFS和非HDFS进行考虑,主要是因为这些HDFS比别人多一个选项Active Sync。
HDFS的情况下,需要考虑这几个点:如果HDFS更新非常频繁,就是绕过Alluxio的更新非常频繁,或者HDFS的namenode的压力比较大,不建议使用Active Sync,而是使用基于时间的被动同步。使用被动同步的原因是Active Sync是基于Alluxio心跳,去namenode拉取具体有哪些文件发生了改动,每一次拉取都是一次RPC,给namenode施加的压力。同时如果文件发生了改动,Alluxio就又会向namenode发起RPC去同步这些文件。因此希望尽量减少这些操作来降低namenode的压力。
如果基于时间的被动同步,能给予减少元数据同步操作的机会,则使用基于时间的被动同步;反之要使用Active Sync,因为更加主动,时效性更高。如果不会带来性能负担,完全可以去尝试一下。
如果不是HDFS,只能用基于时间的被动同步。
建议尽量节约元数据同步的操作,具体做法考虑每个数据、每个路径更新的频率大概是如何。基于这样的考量,尽量给sync interval设一个比较大的值,尽量减少元数据的触发。
3. 场景3
第三个场景稍微有些不同。大部分或全部更新都不经过Alluxio,而更新又非常频繁。

图28 场景三配置
在这种情况下,使用HDFS而且时效性又非常重要,使用Active Sync是唯一方案。因为如果把sync interval调到一个特别低的值,甚至可能触发比Active Sync更多的同步。如果把它设成零之后,每一次都不会触发同步,会进一步加大同步的操作开销。
如果时效性并不十分重要,建议使用这个基于时间的被动同步。通过节省开销,减少元数据同步的操作,就能提升系统的性能。同样如果不是HDFS,则使用基于时间的被动同步。
图29 更多信息访问方式
以上是三个场景的分析,也是今天分享的全部内容。最后是进入我们官方微信的公众号的截图、二维码和Slack官方帐号。如果想加入微信讨论群、了解社区动态发展、或者想要投递简历、想要加入我们在中国和美国的团队,都可以联系我们万能的Alluxio小助手。
感谢大家。
07
答疑
Q:在ASYNC_THROUGH mode当中,因UFS原因导致ASYNC上传始终失败,这种情况怎么优雅地处理,以避免不一致?
A:这个问题非常好,问到了痛点。目前没有一个特别优雅的解决方案。
在异步方式下没有call back,或者hook的自动介入,只能人为介入。Alluxio2.4商业版中加入了一个job service dashboard查看异步任务的状态。如果异步持久化失败了,这个地方可以看到所有失败的异步任务。目前只能通过这个方式观察究竟有哪些东西失败了,然后再人为进行干预。
我们已经注意到job service的问题,打算重新设计整个job service,从几个方向,可扩展Scalability, Fault-tolerance,包括monitoring, failure mode, 恢复等。未来版本里面会做出更好的设计,有很多场景,并加入人工干预模式。通过开放一些接口,可以自动化地读到这些东西,或是可能会增加界面,让用户定义一些方式。
Alluxio到了一个新的阶段,要好好思考,用更加scalable的方案去解决这些问题。这些异步的操作已经提上了议事日程。
Q:和HDFS可以不同路径设置不同的同步时间吗?
A:可以用配置参数的方法去实现。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/7099/