
单namenode节点
准备
文件下载:
jdk-8u241-linux-x64.tar.gz
hadoop-3.2.0.tar.gz
节点安排:
hadoop1 → 从节点
hadoop2 → 主节点
首先确保hadoop1能够免密登录hadoop1以及hadoop2
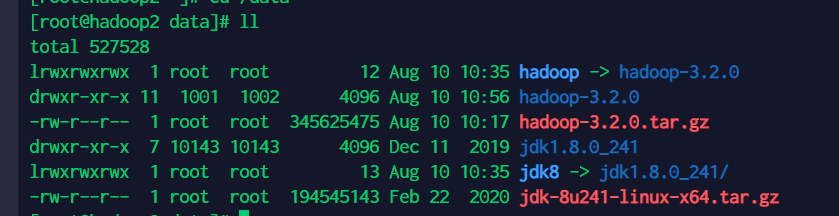
将文件下载到/data目录下,并解压、建立软连接,最终状态如下:

hadoop相关配置修改
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/data/tmp</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50000</value>
</property>
</configuration>hadoop-env.sh
新增
export JAVA_HOME=/data/jdk8start-dfs.sh
开头新增(根据你启动用户修改,如果是root则填root)
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstop-dfs.sh
开头新增
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootworkers修改为
hadoop1
hadoop2
系统环境变量修改
hadoop1和hadoop2都执行
/etc/profile
新增
export JAVA_HOME=/data/jdk8
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin修改完之后执行 source /etc/profile刷新
新建目录
hadoop1和hadoop2都执行
mkdir -p /data/hadoop/data/dfs/data
mkdir -p /data/hadoop/data/tmp
mkdir -p /data/hadoop/data/dfs/name初始化namenode
hadoop namenode -format
启动hdfs
主节点执行
start-dfs.shNameNode HA
安装zookeeper
准备zookeeper二进制包
apache-zookeeper-3.5.9-bin.tar.gz
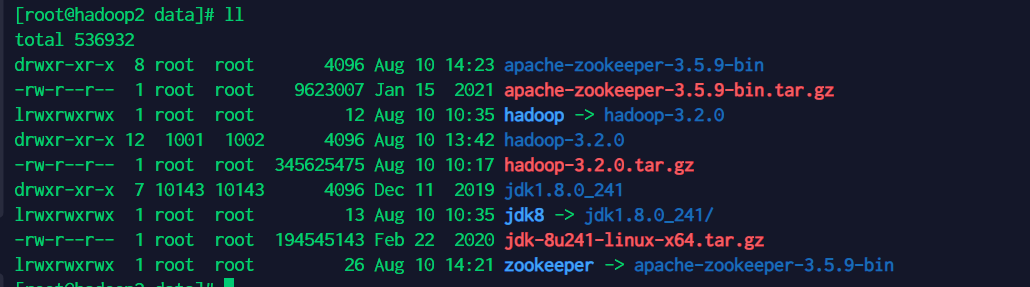
在hadoop2节点安装并启动zookeeper
修改配置文件
cp zookeeper/conf/zoo_sample.cfg zookeeper/conf/zoo.cfg
修改zoo.cfg为
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
启动zookeeper
cd zookeeper && bin/[zkServer.sh](http://zkServer.sh) start停止hdfs
stop-dfs.sh修改hdfs-site.xml
新增配置:
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/journal/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop2:2181</value>
</property>注意:保证所有节点上所有的配置都是一样的。
启动journalnode
启动journalnode,hadoop1和hadoop2节点都执行
hdfs --daemon start journalnode在hadoop2节点执行
hdfs namenode -initializeSharedEdits启动zkfc
hadoop2节点执行格式化zk,
hdfs zkfc -formatZKhadoop2节点启动zkfc进程
hdfs --daemon start zkfchadoop2节点启动namenode
hdfs --daemon start namenode复制namenode元数据
将hadoop2节点的namenode元数据复制到hadoop1相同的目录
scp -r /data/hadoop/data/dfs/name/* hadoop1:/data/hadoop/data/dfs/name/在Hadoop1节点执行
hdfs namenode -bootstrapStandby启动namenode
hadoop1节点启动
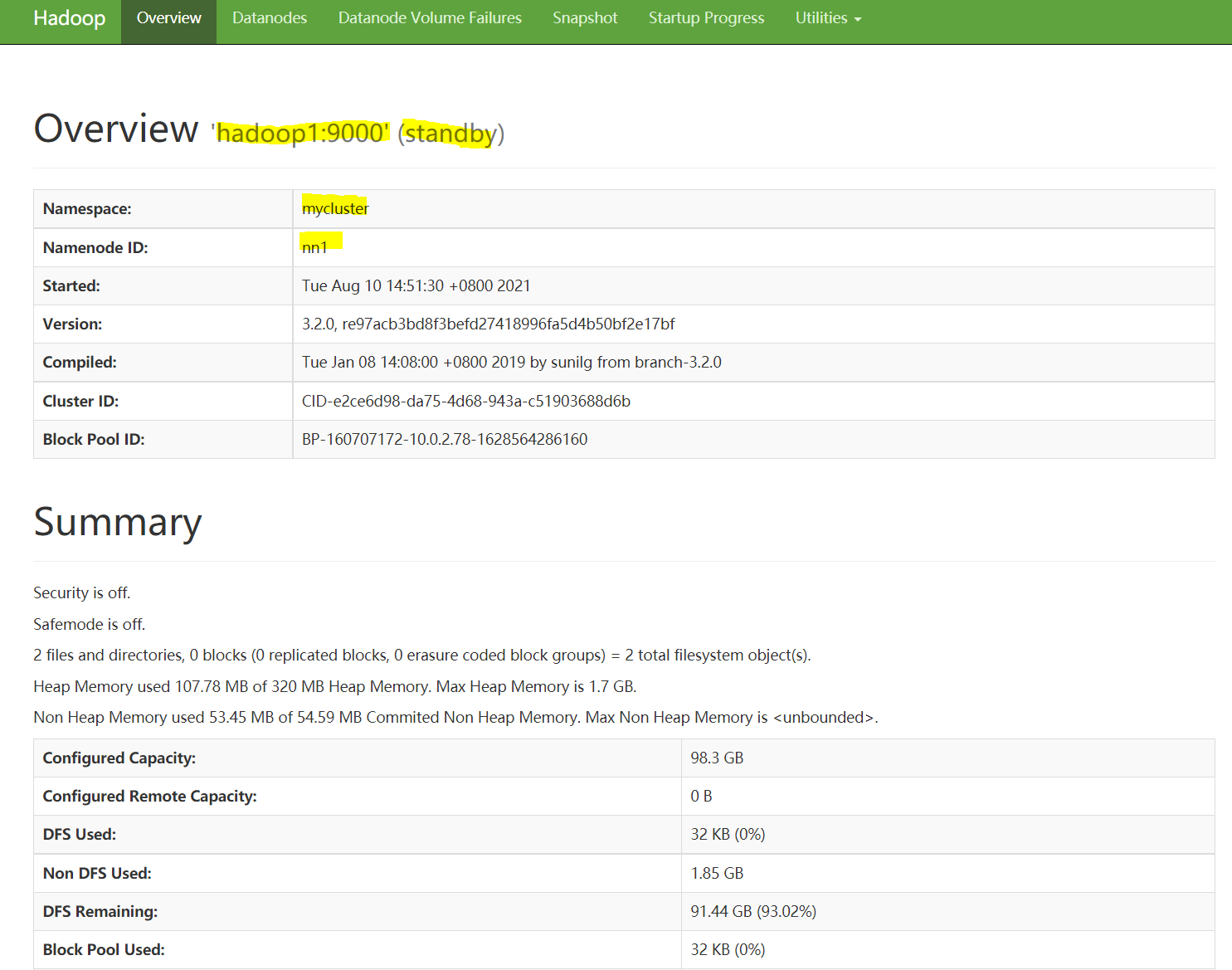
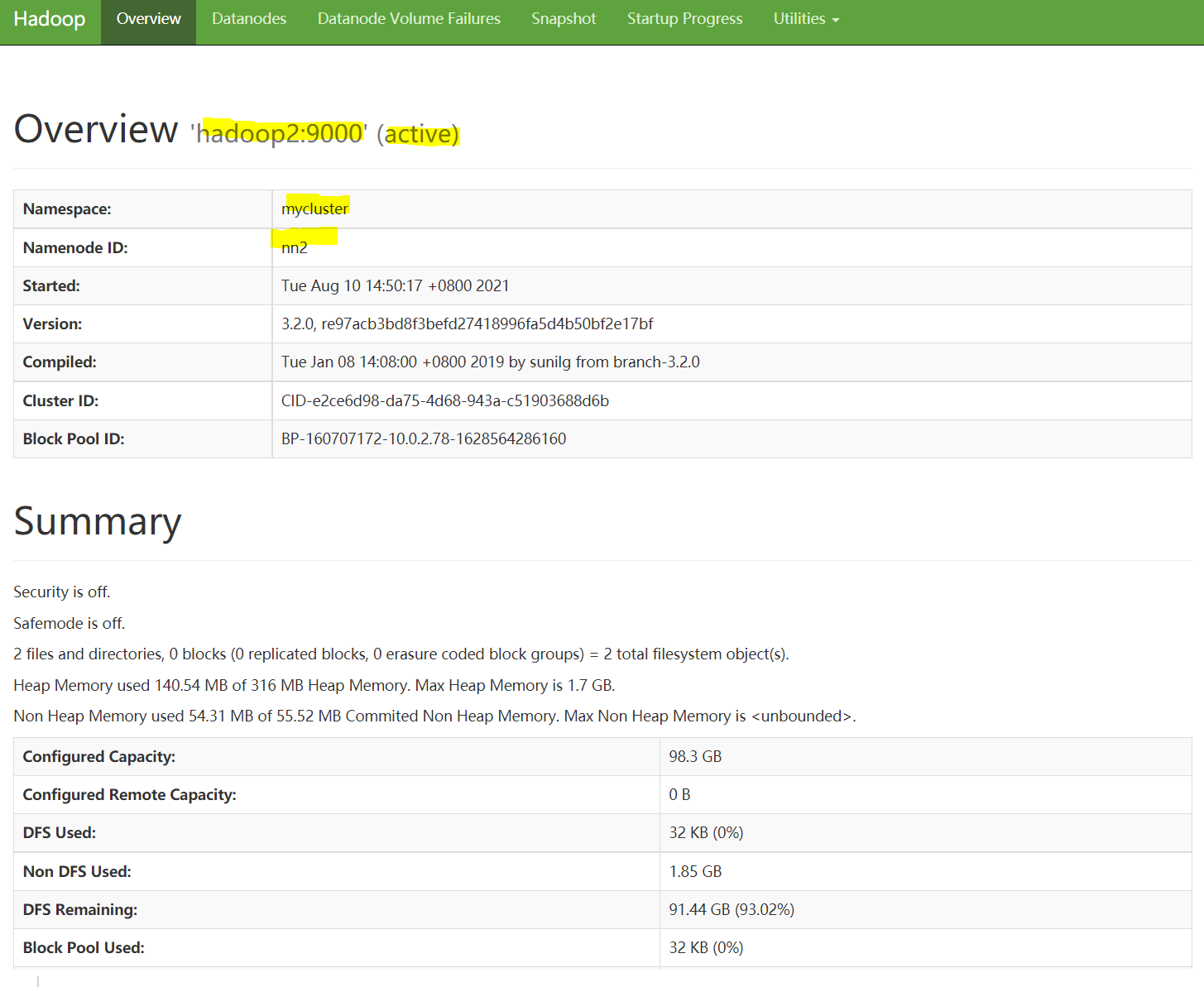
hdfs --daemon start namenode至此hadoop1和hadoop2已经启用了namenode的高可用特性,其通过zk自动选举。具体如下图所示:
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/303/
[…] hdfs集群安装(单namenode和HA模式) […]