
随着 Pinterest 不断从一个只保存想法的地方发展为一个发现激发行动的内容的平台,直接发布到 Pinterest 的创作者的原生内容有所增加。随着 Pinterest 上创作者生态系统的发展,我们致力于通过创作者代码等举措确保 Pinterest 保持积极和鼓舞人心的环境,这是一项强制接受准则(例如“善待”和“检查事实”)的内容政策在创作者可以发布创意 Pin 图之前。我们还在 Idea Pin 评论上设置了防护栏,包括积极性提醒、评论删除和关键字过滤工具以及垃圾邮件预防信号。在技术方面,我们使用机器学习中的尖端技术来近乎实时地识别和执行违反社区政策的评论。我们还使用这些技术首先显示最具启发性和最高质量的评论,以带来更高效的体验并推动参与。
由于机器学习解决方案于 3 月推出,可在报告之前自动检测可能违反政策的评论并采取适当措施,我们看到评论报告率下降了 53%(每 100 万评论展示的用户评论报告)。
在这里,我们分享我们如何构建可扩展的近实时机器学习解决方案,以识别违反政策的评论并按质量对评论进行排名。
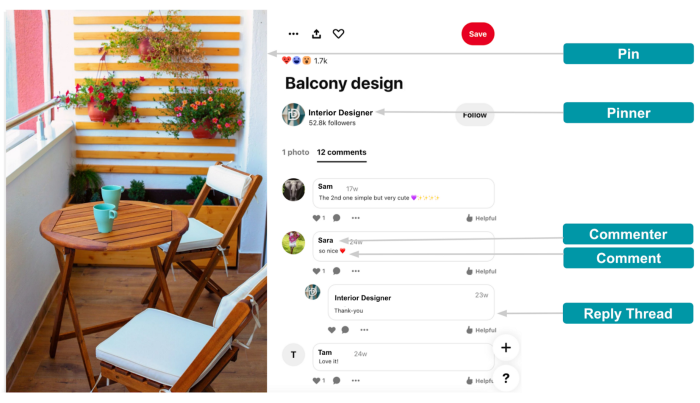

评论的方面
我们大致确定了评论的四个方面:不安全,或者评论是否违反了我们的社区准则; 垃圾邮件; 情绪; 和质量。 评论的情绪可以是正面的、中性的或负面的。 评论的质量可高可低。 我们通过使用内在维度来衡量评论的质量:可读性、与 Pin 的相关性和细微差别。 如果注释没有错误且可理解,则注释是可读的。 相关评论是特定的并且与 Pin 图的内容相关。 细微的评论是问题、技巧、建议、请求,或描述评论者的个人经历或与 Pin 图的互动。 细微、易读且与 Pin 评论相关的评论被认为是高质量的。
机器学习解决方案
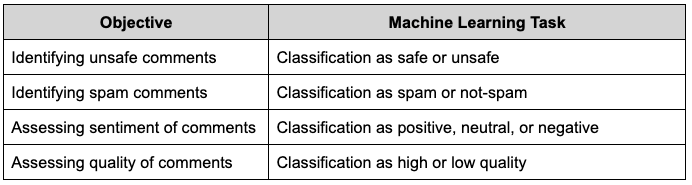
我们利用机器学习技术来识别违反政策(不安全和垃圾邮件)的评论,并评估评论的情绪和质量。 我们将这些任务中的每一个都建模为分类任务,如表 1 所示。我们的机器学习解决方案目前支持多种语言(英语、法语、德语、葡萄牙语、西班牙语、意大利语和日语),未来将扩展到其他语言。
训练数据
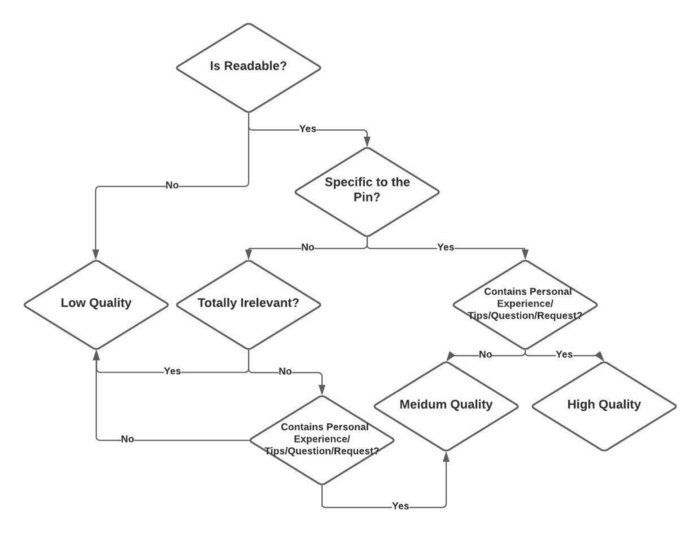
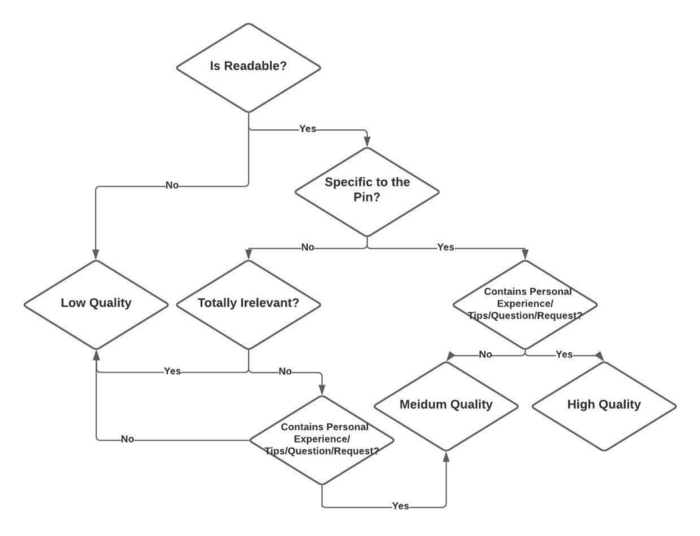
我们仅使用标记的英语评论训练模型。我们采用混合方法来限制收集标记数据的成本。不安全、垃圾邮件和非垃圾邮件标记的评论是通过对社区报告评论的人工验证获得的。安全标记的评论是通过对 Pinterest 上的所有评论进行随机抽样生成的,因为不安全评论的数量非常少。正面和负面情绪类别的标记数据是通过人工标记随机采样的评论获得的。由于负面评论的流行率也极低,我们使用 Vader 情绪分析器对评论进行采样以进行负面情绪标记。对于质量标签,我们收集了评论者对评论的每个质量定义因素的回应。最后,我们使用图 2 所示的决策流程图将这些回复分为三个质量等级。目前,我们将所有中等质量的评论都视为高质量的评论,并将在未来探索一种单独的处理方式,以更好地控制评论质量排名。
模型
我们设计了一个多任务模型,如图 3 所示,它通过微调强大的最先进的预训练转换器模型(多语言 DistilBERT)来利用迁移学习。这种设计选择在整体性能、生命周期成本和开发速度方面产生了最佳价值。成本降低来自使用预训练模型,该模型需要相对少量的标记数据进行进一步训练,并且必须在整个生命周期内维护单个模型。我们的评估表明,多任务模型的性能与每个分类任务的独立模型相当。我们利用了一个多语言预训练模型,因为它帮助我们增加了模型的覆盖范围,尽管性能有所降低,但不需要对这些语言进行任何特定的训练,而不需要对英语以外的许多语言进行训练。
为了引入上下文并提高模型的性能,我们还使用了 Pin、Pinner、评论者和附加评论功能,这些功能是 Pinterest 评论生态系统的组成部分(如图 1 所示)。这些特征与 DistilBERT 的最后一个隐藏层输出连接,并输入到联合多层感知器 (MLP) 中,这也允许特征之间的交叉学习。 Pin 功能包括 PinSage 嵌入和 Pin 语言。 Pinner 和评论者特征包括使用 PinnerSage 嵌入得出的它们之间的品味相似性和语言等个人资料特征。附加注释功能是注释长度和语言。
每个任务头都有自己的输出层,可以生成类的分数分布。 二元分类头对输出使用 sigmoid 激活,对损失使用二元交叉熵。 情感分类头使用softmax输出层和交叉熵损失。 对于每个训练数据实例,只有那些任务头对数据点具有标签的整体损失函数有贡献。 该模型使用 Tensorflow 和 Keras 实现,并在多个 GPU 上使用数据并行进行训练。 我们针对召回率和误报率进行了优化。 我们学习了一个分数截止值来识别不安全、垃圾邮件和负面情绪评论。
接口
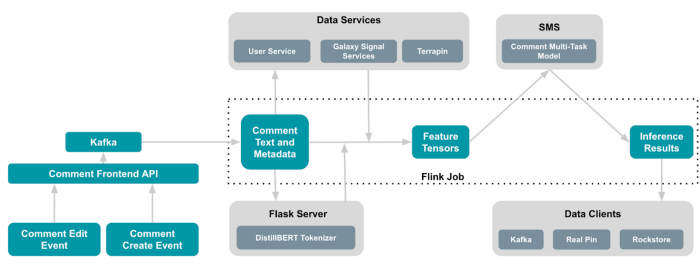
如图 4 所示,我们使用 Pinterest 的流数据平台 (Flink) 对新创建/编辑的评论进行了操作,以近乎实时地对新创建/编辑的评论进行评分。我们在 Pinterest 的在线模型服务平台 (SMS) 中托管多任务评论模型。为了为 DistilBERT 准备输入,我们在 Python Flask 中托管了来自拥抱面孔作为服务的相应标记器。 Flink 作业从由前端 API 服务填充的 Kafka 队列接收评论及其相关元数据,这些队列是针对新的评论创建或评论编辑事件。此作业使用评论的语言作为过滤器来推断仅支持语言的评论。它通过 HTTP 与 Flask 服务通信以获取 DistilBERT 输入。它从一堆 Pinterest 的数据服务(例如 Galaxy Signal Service 和 Terrapin)中获取模型所需的其他输入特征。 Flink 作业将所有特征转换为张量,然后向 SMS 发出预测请求。最终,它将推理结果下沉到多个数据客户端,例如 Rockstore、RealPin 和 Kafka,以供其他消费者服务和使用。 Rockstore 是 Pinterest KVStore 平台的分布式键值存储以及行政管理和协调 API 和 MySQL 后端存储。 RealPin 是一个高性能的对象检索系统,具有高度可定制的排名、聚合和过滤功能。
服务
我们有两个独立的服务工作流,它们使用推理输出和执行策略以及排名评论。 工作流的分离提供了逻辑模块化并促进了简化的操作、管理和诊断。 第一个工作流过滤不安全和垃圾评论,另一个使用情绪和质量分数等因素采取适当的过滤或排名操作。 我们目前将回复视为独立评论并提供类似处理。
结论
我们的机器学习解决方案针对可能违反政策的评论提供了强大的防御,并确保我们的 Pinner 社区有一个安全的生态系统来参与和受到启发。 由于上下文、不断变化的趋势和其他细微差别(如讽刺、否定、比较、语气、极性、情感转换、含义转换等)的作用,识别有害评论和评估评论质量将继续发展。我们计划迭代改进 我们的解决方案并修订我们的社区准则。 我们还看到了将该模型用于其他用例的机会,例如隐藏式字幕、直接消息传递和其他基于文本的用户参与形式。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/3087/