
Parquet介绍
Parquet 是一种开源文件格式,用于处理扁平列式存储数据格式,可供 Hadoop 生态系统中的任何项目使用。 Parquet 可以很好地处理大量复杂数据。它以其高性能的数据压缩和处理各种编码类型的能力而闻名。与基于行的文件(如 CSV 或 TSV 文件)相比,Apache Parquet 旨在实现高效且高性能的平面列式数据存储格式。
Parquet 使用记录粉碎和组装算法,该算法优于嵌套命名空间的简单展平。 Parquet 经过优化,可以批量处理复杂数据,并具有不同的方式来实现高效的数据压缩和编码类型。 这种方法最适合那些需要从大表中读取某些列的查询。 Parquet 只需读取所需的列,因此大大减少了 IO。 Parquet 的一些好处包括:
- 与 CSV 等基于行的文件相比,Apache Parquet 等列式存储旨在提高效率。查询时,列式存储可以非常快速地跳过不相关的数据。因此,与面向行的数据库相比,聚合查询耗时更少。这种存储方式已转化为节省硬件并最大限度地减少访问数据的延迟。
- Apache Parquet 是从头开始构建的。因此它能够支持高级嵌套数据结构。 Parquet 数据文件的布局针对处理大量数据的查询进行了优化,每个文件在千兆字节范围内。
- Parquet 旨在支持灵活的压缩选项和高效的编码方案。由于每一列的数据类型非常相似,每一列的压缩很简单(这使得查询更快)。可以使用几种可用的编解码器之一来压缩数据;因此,可以对不同的数据文件进行不同的压缩。
- Apache Parquet 最适用于交互式和无服务器技术,如 AWS Athena、Amazon Redshift Spectrum、Google BigQuery 和 Google Dataproc。
Parquet 和 CSV 的区别
CSV 是一种简单且广泛使用的格式,被 Excel、Google 表格等许多工具使用,许多其他工具都可以生成 CSV 文件。 即使 CSV 文件是数据处理管道的默认格式,它也有一些缺点:
- Amazon Athena 和 Spectrum 将根据每次查询扫描的数据量收费。
- 谷歌和亚马逊将根据存储在 GS/S3 上的数据量向您收费。
- Google Dataproc 收费是基于时间的。
Parquet 帮助其用户将大型数据集的存储需求减少了至少三分之一,此外,它还大大缩短了扫描和反序列化时间,从而降低了总体成本。
Spark读写parquet文件
Spark SQL 支持读取和写入 Parquet 文件,自动捕获原始数据的模式,它还平均减少了 75% 的数据存储。 Spark 默认在其库中支持 Parquet,因此我们不需要添加任何依赖库。下面展示如何通过spark读写parquet文件。
本文使用spark版本为3.0.3,运行如下命令进入本地模式:
bin/spark-shell数据写入
首先通过Seq创建DataFrame,列名为“firstname”, “middlename”, “lastname”, “dob”, “gender”, “salary”
val data = Seq(("James ","","Smith","36636","M",3000),
("Michael ","Rose","","40288","M",4000),
("Robert ","","Williams","42114","M",4000),
("Maria ","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1))
val columns = Seq("firstname","middlename","lastname","dob","gender","salary")
import spark.sqlContext.implicits._
val df = data.toDF(columns:_*)
使用 DataFrameWriter 类的 parquet() 函数,我们可以将 Spark DataFrame 写入 Parquet 文件。在此示例中,我们将 DataFrame 写入“people.parquet”文件。
df.write.parquet("/tmp/output/people.parquet")
查看文件


数据读取
val parqDF = spark.read.parquet("/tmp/output/people.parquet")
parqDF.createOrReplaceTempView("ParquetTable")
spark.sql("select * from ParquetTable where salary >= 4000").explain()
val parkSQL = spark.sql("select * from ParquetTable where salary >= 4000 ")
parkSQL.show()

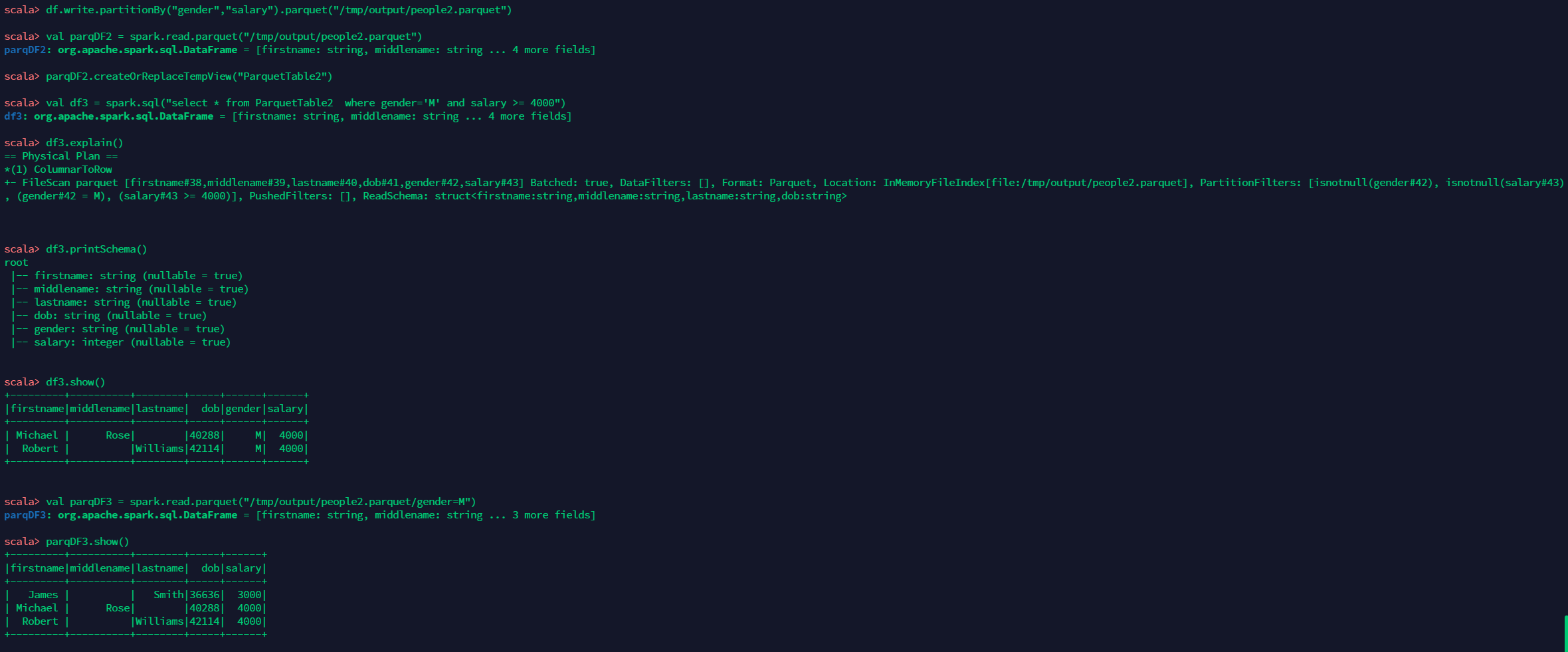
写入分区数据
df.write.partitionBy("gender","salary").parquet("/tmp/output/people2.parquet")
val parqDF2 = spark.read.parquet("/tmp/output/people2.parquet")
parqDF2.createOrReplaceTempView("ParquetTable2")
val df3 = spark.sql("select * from ParquetTable2 where gender='M' and salary >= 4000")
df3.explain()
df3.printSchema()
df3.show()
val parqDF3 = spark.read.parquet("/tmp/output/people2.parquet/gender=M")
parqDF3.show()得到如下结果
Flink读写parquet文件
默认情况下,Flink包中未包含parquet相关jar包,所以需要针对特定版本下载flink-parquet文件。本文以flink-1.13.3为例,将文件下载到flink的lib目录下
cd lib/
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-parquet_2.12/1.13.3/flink-sql-parquet_2.12-1.13.3.jar在完成下述测试之前,在本地启一个flink standalone集群环境。
bin/start-cluster.sh执行如下命令进入Flink SQL Client
bin/sql-client.sh读取spark写入的parquet文件
在上一节中,我们通过spark写入了people数据到parquet文件中,现在我们在flink中创建table读取刚刚我们在spark中写入的parquet文件数据
create table people (
firstname string,
middlename string,
lastname string,
dob string,
gender string,
salary int
) with (
'connector' = 'filesystem',
'path' = '/tmp/output/people.parquet',
'format' = 'parquet'
)
select * from people;得到如下结果:


使用Flink写入数据到parquet文件
然后使用flink,往刚刚创建的table再写入数据:
insert into people values('Tom', 'Mary', 'Ken', '21334', 'F', 5000);在Flink UI查看执行结果

再次查询数据
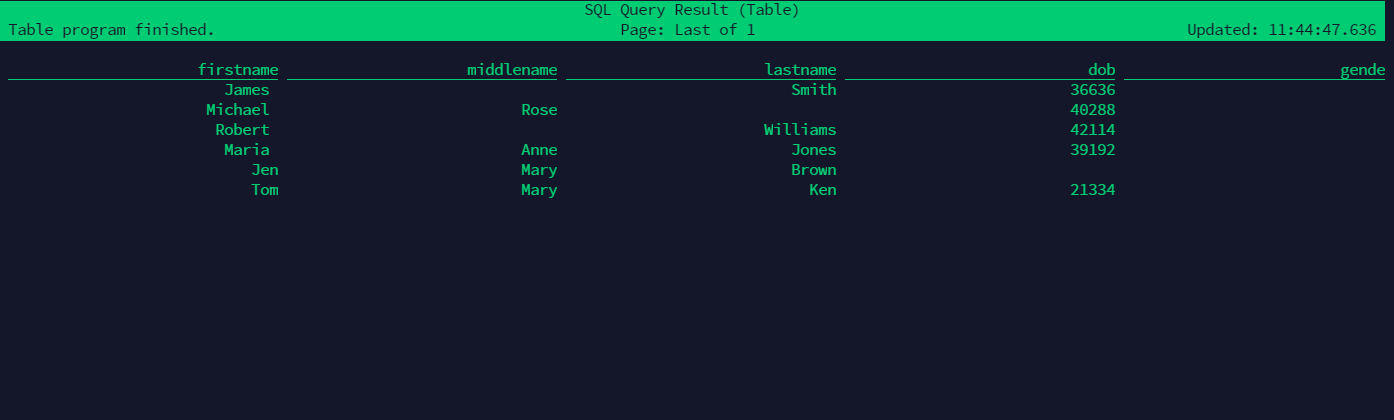
可以查到我们刚刚新插入的数据。
参考文献:
-
https://sparkbyexamples.com/spark/spark-read-write-dataframe-parquet-example/
-
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/formats/parquet/
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/3575/