


分享嘉宾:周劲松 网易
编辑整理:王贤才 碧桂园
出品平台:DataFunTalk
导读:这次分享的主题是网易内部孵化的数据湖项目Arctic。在分析了部分现有开源数据湖项目后,网易结合自身需求,孵化了Arctic。本次分享的内容包括五大方面:
-
什么是数据湖?
-
网易需要的数据湖
-
Arctic核心原理
-
现有成果
-
总结与规划
什么是数据湖
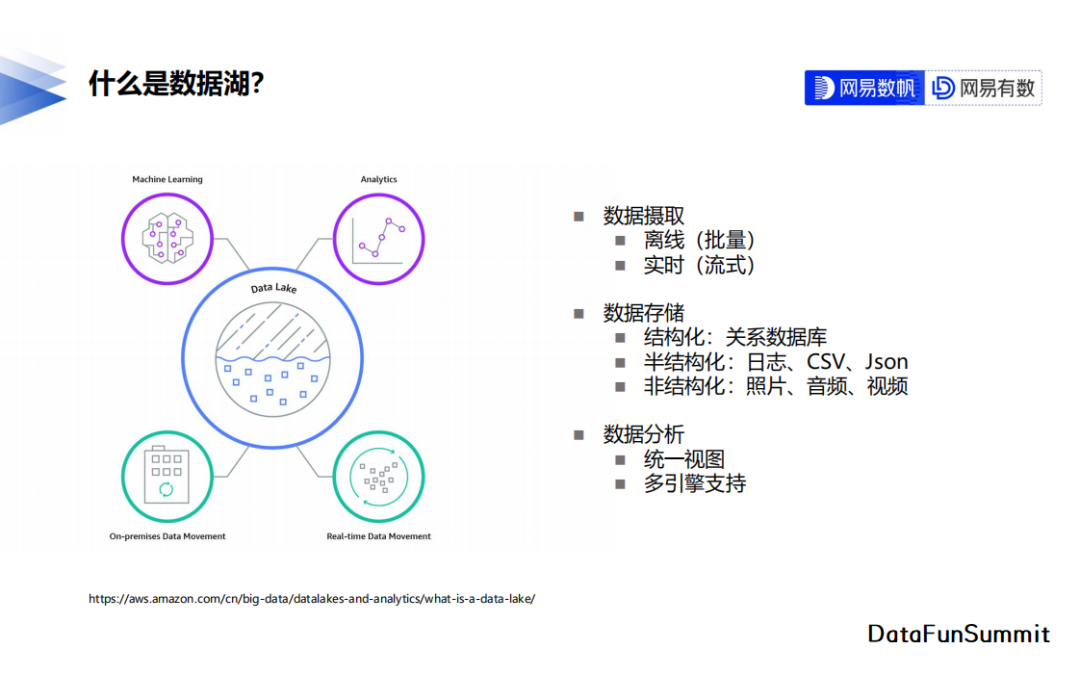
我们从数据摄取、数据存储和数据分析三个方面来描述数据湖的特性。
数据摄取就是数据写入,数据湖既可以支持批量的数据写入,也可以支持流式的数据写入。
从数据存储上来说,相较于数仓只能存储结构化的数据,我们希望数据湖既能存储结构化的数据,比如关系型数据库中的数据,也支持存储半结构化的数据,比如应用系统的业务日志,同时还能存储非结构化的数据,比如照片、音频或者视频数据。但是现在实际的使用情况下,存储结构化与半结构化的需求比非结构化的需求更多一些。
从数据分析的角度上来说,数据湖更强调存储。在计算上,尽量利用不同计算引擎的特点去处理不同的需求,为了支持不同的计算引擎,数据湖一般会提供统一的结构去描述其中的数据。下图是亚马逊的一个数据湖产品图,它支持实时的或者定时的把一些数据写到数据湖里面,在数据湖上完成数据分析以及机器学习相关的应用。
传统数据湖更强调其灵活性,而在数据治理上普遍功能较弱。为了弥补数据湖在数据治理上的不足,涌现出了一批完善数据湖数据治理的项目,比较出名的有三个,我们称之为数据湖三剑客。它们分别是:Delta Lake、Apache Hudi、Apache Iceberg。

Delta Lake:从功能上来讲,支持事务隔离,支持同时对数据进行读写,有数据多版本的概念。Delta Lake在流批一体上,除了支持传统的批量写入,还可以通过Spark Streaming写入实时数据,也可以从表里读出实时数据,但是现在还无法实时更新/删除数据。表结构修改方面,它只支持新增字段。
Apache Hudi:很好地弥补了Delta Lake在实时更新和删除数据上的不足,同时这也成为了它最大的特点。但是我们在调研时Apache Hudi和spark还是强绑定的关系,虽然社区已经发起适配Apache Flink的讨论,但对现有的代码改动较大,等待其开发完并能投入生产还需要不少时间。另外Hudi引入了额外的索引开销(Bloom Filter或者HBase)进行数据组织,虽然提升了数据合并的性能,但却也带来了额外的计算、运维开销。
Apache Iceberg:是三者中最年轻,也是代码最简洁的一个,但与Delta Lake一样,其在数据实时写入与读取的支持上还不完善。
经过分析,三款数据湖产品都有自己的特点,但是都不能完全满足我们对数据湖的需求。
网易需要什么样的数据湖
为了描述网易对数据湖的需求,先来介绍下网易数据开发的现状。
以网易云音乐的一个数据开发过程为例,云音乐的数据主要来自两方面,一个是业务埋点日志,另一个是数据库里的Binlog日志。开发模式就是较为标准的Lambda架构,离线链路通过Spark在HDFS上做T+1的批量计算;如果对数据实时性有较高要求的场景,则通过Flink在Kafka上做实时链路的建设,数据应用时再结合批量计算和实时计算的结果。
Lambda架构最大的问题就是流和批的重复建设,不仅造成了双倍的成本投入,实际开发过程中还极容易出现流批口径不一致,导致最后数据质量不高的结果。

基于这样的开发现状,网易对数据湖的最重要需求是什么呢?
-
首先流批一体是我们的核心需求,新的开发模式要能够同时支持实时、批量的数据写入、读取,能方便地在其上用Flink实现实时数据开发,也能通过Spark实现批量的数据加工,不仅能存放只有追加的日志数据,也能存储有变更需求的Binlog数据。我们计划按照三个层级逐级推进流批一体,首先是统一流批的表元数据,接下来统一流批的存储方式,最后统一流批的开发模式。
-
另外一个重要的需求是兼容性,新的数据湖方案要能兼容已有的Hive表,无需把已有的Hive数据重新迁移到数据湖上,也不用对已有的数据开发任务进行重新的编写来适应新的数据湖特性。与原有系统的兼容性很大程度决定了新系统能否得到很好的推广。
-
除以上两点外,还有高性能、低延迟,以及支持ACID、表结构变更、文件治理等常规的数据湖能力。

Arctic核心原理
为了满足上面提到的需求,网易内部孵化了流批一体的实时数据湖项目——Arctic。
1. Arctic架构

上图是Arctic现有的架构,中间虚线部分为Arctic的核心模块,虚线以外的部分则是对接的一些计算引擎。
Arctic表内部分成了两个表空间,一个是base表空间,一个是change表空间,base表空间存储表的基础数据,或者也叫存量数据。change表空间存储表的变更数据,在进行查询时将change表的数据合并入base表后返回给用户,以得到实时变更之后的数据,这个过程我们叫它Merge-On-Read。
随着数据不断写入,change数据越来越多,Merge-On-Read的性能必将大大下降。Arctic内部通过自动的合并过程将堆积的change数据合并到base表中,以提升Merge-On-Read的性能。
现阶段Arctic集成了Apache Flink完成对实时数据的写入和读取,集成了Apache Spark完成对存量数据的写入与读取,集成了Impala与Presto完成数据分析。
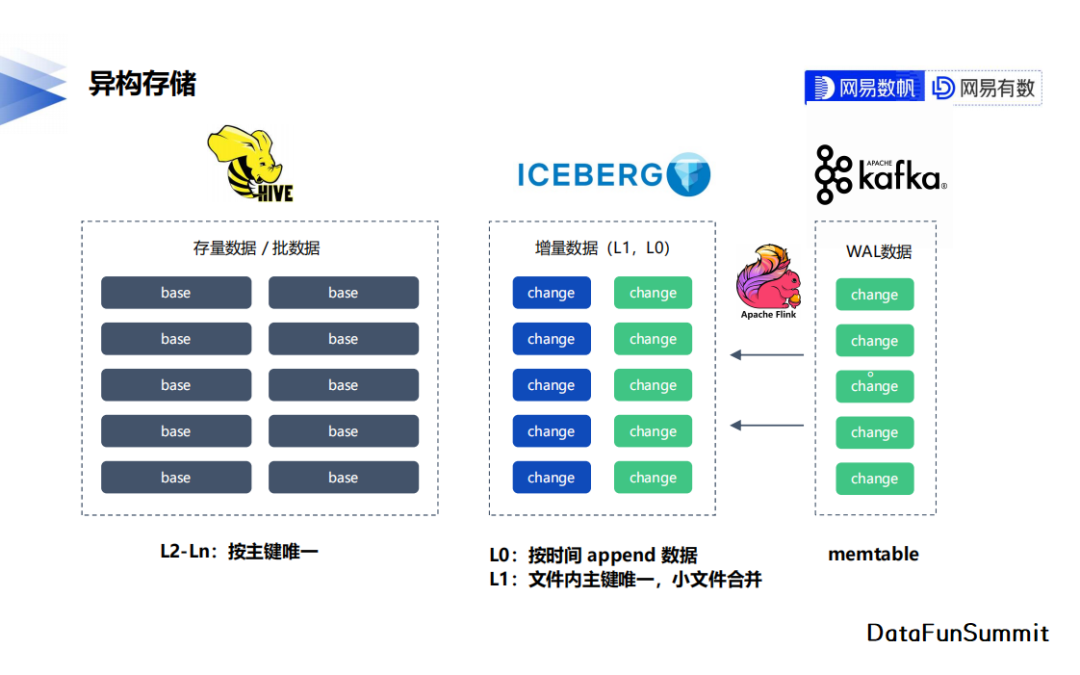
2. 异构存储
根据需求的不同,base表与change表选择了不同的存储方案。源于对历史Hive表的兼容需求,base表仍然选择使用Hive进行管理。change表是新增的内容,我们选择了Apache Iceberg对其进行数据管理,主要依赖了其多版本的机制与灵活的文件管理方式。对于有毫秒级实时消费的场景,我们还会在Iceberg的change表之上使用Apache Kafka构建一块毫秒级的change数据分发管道。
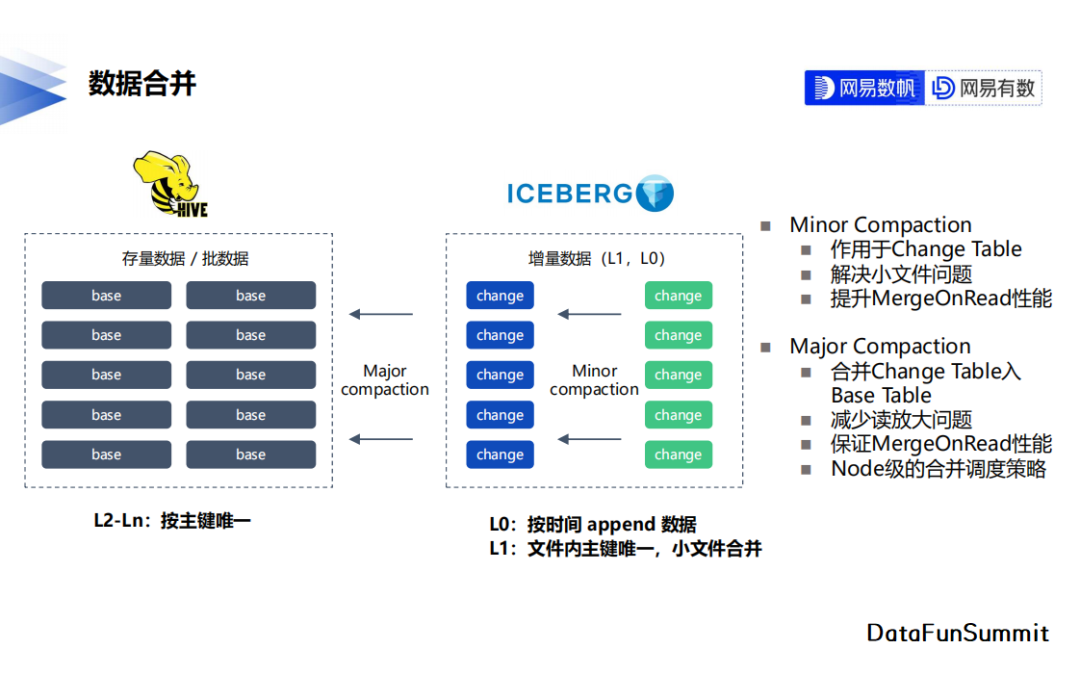
3. 数据合并
文件合并方面,我们拆分出主要合并change表的Minor Compaction,与合并change表到base表的Major Compaction过程。合并不仅解决了前面提到的读放大问题,也负责实时写入场景下的小文件治理问题。
现有成果
下图为Arctic在云音乐落地之后新的开发模式。Arctic统一了实时与离线操作的表对象,支持同时使用Flink与Spark对表完成实时与离线的数据开发。新的开发模式很好地解决了Lambda架构下schema不一致的问题,同时也加速了离线链路向实时链路升级的速度。

未来规划
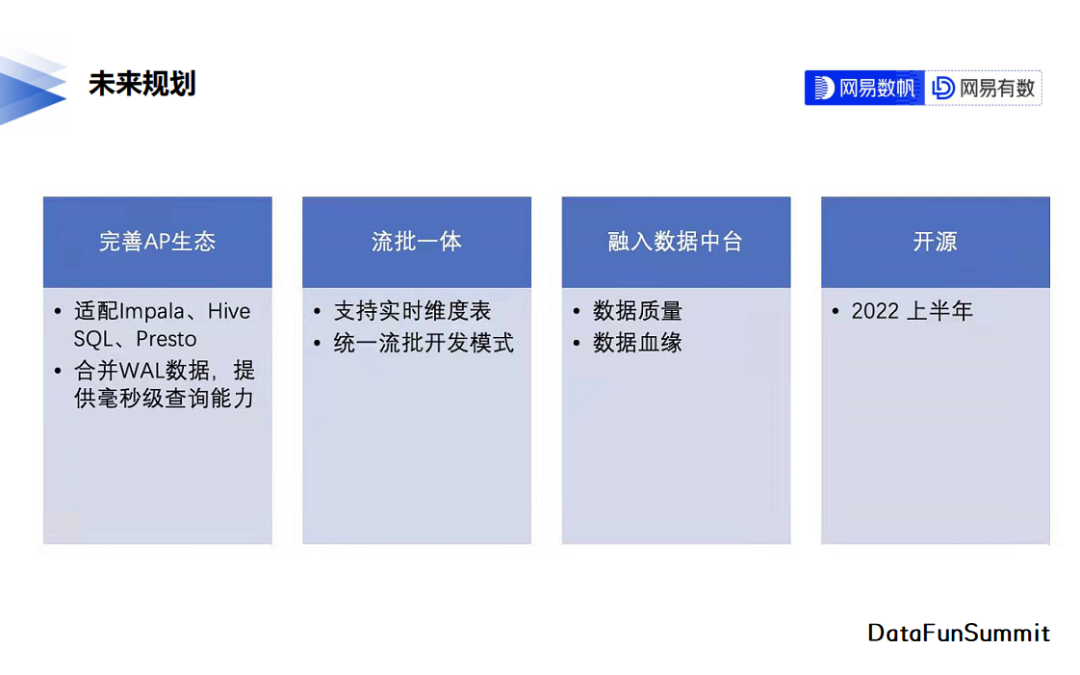
现阶段Arctic对Presto、Impala等AP引擎的集成还不够完善,后续我们会花更多的时间与精力优化Arctic在AP场景下的查询性能。同时针对数据延迟要求特别高的场景,我们会考虑将Kafka中毫秒级的数据纳入Merge-On-Read的范围内。
另外,流批一体仍然会是我们继续探索的主要方向。Arctic现阶段解决了元数据与表数据的流批一体,下一阶段是数据开发上的流批一体探索。
在周边生态完善方面Arctic将融入数据中台的数据质量、数据血缘等系统。
Arctic计划于2022上半年开源。
今天的分享就到这里,谢谢大家。

*
本文转载自datafuntalk,原文链接:https://mp.weixin.qq.com/s/CiUsdNTdd6jeSXLAaAg01w。
Целомудрие Ваших постов отнюдь не имеет границ