
最近在做搜索相关的事情,也看到Github代码搜索的发展历程,不曾想其第一代搜索引擎上线居然是2008年(那一年刚上初一),或许是有时间的积淀与技术的进步才使得今天的我们在github上搜索代码可以如此方便。接下来我们一起来看看GitHub代码搜索服务发展历史。
一代目的搜索界面
一开始,GitHub 宣布支持代码搜索,正如您对标有“社交代码托管”标语的网站所期望的那样。 一切都很好。
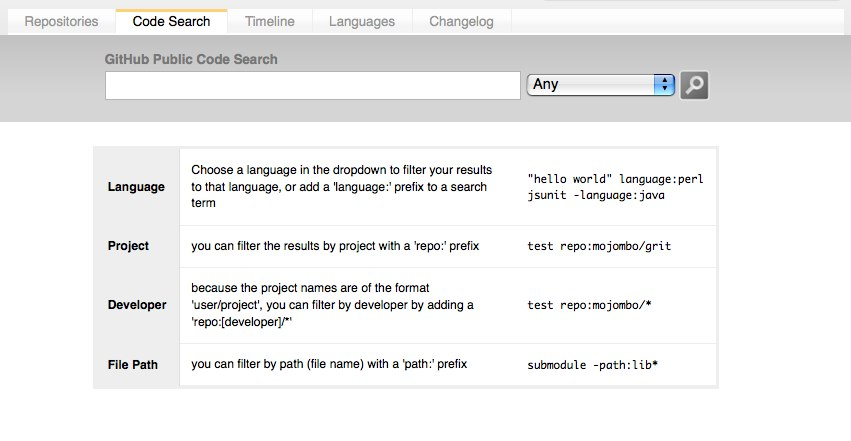

全局搜索的第一次迭代通过将所有公共文档索引到 Solr 实例中来工作,该实例确定了您获得的结果。
该搜索界面将让您在源代码中输入您要查找的任何内容,并获得我们公共存储库中匹配的任何文件的突出显示结果。 您还将获得一个侧边栏,其中包含结果的语言细分和存储库细分的方面计数。
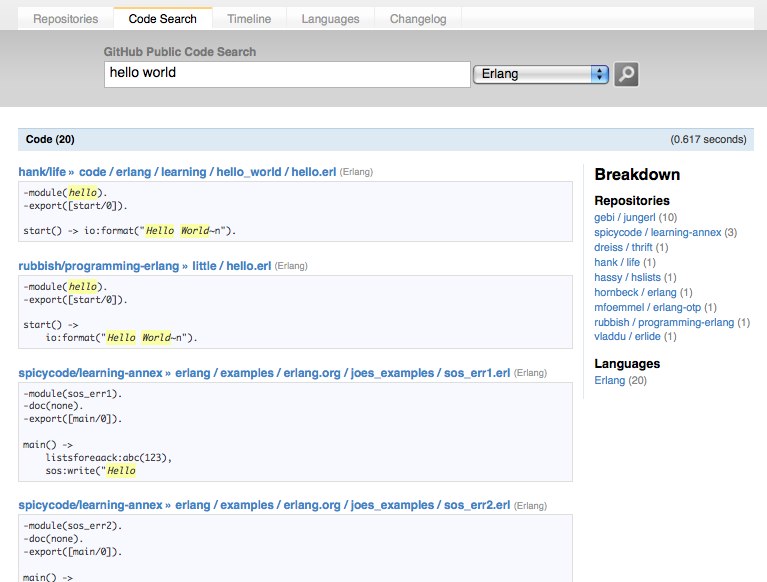
您还可以搜索任何特定语言,如果您要通过在下拉列表中选择该语言来查找特定内容:
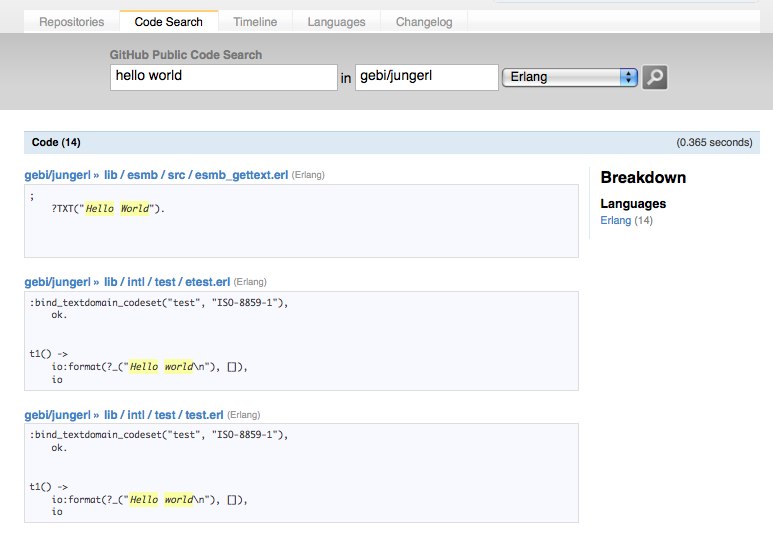
您还可以通过单击侧栏中列出的语言或存储库之一来细化搜索结果,以仅深入查看这些结果:
发布后不久,当时处于测试阶段的 Google Code Search 也开始在 GitHub 上抓取公共存储库,从而为开发人员提供了一种搜索它们的替代方法。 (最终,几年后谷歌代码搜索停止了,尽管 Russ Cox 关于它如何工作的优秀博客文章仍然是后续项目的重要灵感来源。)
使用 Elasticsearch 扩展
到 2010 年,搜索领域出现了相当大的动荡。 Solr 作为一个子项目加入了 Lucene,而 Elasticsearch 作为一种在 Lucene 之上构建和扩展的好方法而兴起。 虽然 Elasticsearch 直到 2014 年 2 月才会发布 1.0.0 版本,但 GitHub 于 2011 年开始尝试采用它。将要点索引到 Elasticsearch 中以使其可搜索的初步试验显示出巨大的希望,不久之后显示这是 GitHub 上所有搜索的未来,包括代码搜索。
事实上,在 2013 年初,就在 Google 代码搜索即将结束之际,GitHub 推出了由 Elasticsearch 集群支持的全新代码搜索,整合了公共和私有存储库的搜索体验并更新了设计。 搜索索引在发布时涵盖了近 500 万个存储库。

总的来说,我们使用 Elasticsearch 的经验非常出色。它支持 GitHub.com 上的各种搜索,在整个过程中表现出色。代码搜索索引是迄今为止我们运营的最大集群,自案例研究以来,它的规模又增长了 20-40 倍(达到 162 个节点,包括 5184 个 vCPU、40TB 的 RAM 和 1.25PB 的后备存储,支持查询负载平均每秒 200 个请求,索引超过 530 亿个源文件)。这证明了 Elasticsearch 的能力,我们在本质上是一个现成的搜索引擎。
我的代码不是小说
Elasticsearch 在大多数搜索工作负载中表现出色,但几乎立即与代码搜索相关的一些问题和摩擦开始出现。 也许最广泛观察的是代码搜索文档中的这条评论:
您不能在搜索查询中使用以下通配符:. , : ; / \ ` ‘ ” = * ! ? # $ & + ^ | ~ < > ( ) { } [ ] @。搜索将忽略这些符号。
源代码不像普通文本,那些“标点符号”字符实际上很重要。 那么为什么它们会被 GitHub 的生产代码搜索忽略呢? 这归结为我们的 Elasticsearch 摄取管道是如何配置的。
当文档被添加到 Elasticsearch 索引时,它们会通过一个称为文本分析的过程,该过程将非结构化文本转换为针对搜索优化的结构化格式。通常,文本分析被配置为规范化与搜索无关的细节(例如,大小写折叠文档以提供不区分大小写的匹配,或将空白运行压缩为一个,或词干以搜索“摄取”还可以找到“摄取管道”)。最终,它执行标记化,将规范化的输入文档拆分为应该对其出现进行索引的标记列表。
许多可用于文本分析的功能和默认值都适用于索引自然语言文本。为了为源代码创建索引,我们定义了一个自定义文本分析器,应用了一组精心挑选的规范化(例如,大小写折叠和压缩空格有意义,但词干提取没有意义)。然后,我们配置了一个自定义模式标记器,使用以下正则表达式拆分文档:%q_[.,:;/\\`'”=*!@?#$&+^|~<>(){ }[]\s]_. 如果仔细观察,您会发现查询字符串中被忽略的字符列表!
由该拆分产生的标记然后进行最后一轮拆分,提取以 CamelCase 和 snake_case 分隔的单词部分作为附加标记,使它们可搜索。为了举例说明,假设我们正在摄取包含以下声明的文档:pub fn pthread_getname_np(tid: ::pthread_t, name: *mut ::c_char, len: ::size_t) -> ::c_int;。我们的文本分析阶段会将以下令牌列表传递给 Elasticsearch 以进行索引:pub fn pthread_getname_np pthread getname np tid pthread_t pthread t name mut c_char c char len size_t size t c_int c int。特殊字符根本没有出现在索引中;相反,重点是从标识符和关键字中恢复的单词。
设计文本分析器很棘手,一方面涉及索引大小和性能之间的艰难权衡,另一方面涉及可以回答的查询类型。上述方法是对不同策略进行仔细试验的结果,代表了一种很好的折衷方案,使我们能够启动和发展代码搜索近十年。
源代码的另一个考虑因素是子字符串匹配。假设我想了解如何在 Rust 中获取线程的名称,并且我依稀记得该函数被称为 thread_getname 之类的东西。搜索 thread_getname org:rust-lang 不会在我们的 Elasticsearch 索引上给出任何结果;同时,如果我在本地克隆 rust-lang/libc 并使用 git grep,我会立即找到 pthread_getname_np。更一般地说,高级用户几乎可以立即进行正则表达式搜索。
能找到的最早的内部讨论可以追溯到 2012 年 10 月,比基于 Elasticsearch 的代码搜索公开发布的时间早了一年多。Github考虑了各种改进 Elasticsearch 标记化的方法(实际上,我们将 pthread_getname_np 变成了标记 pthread、getname、np 和 pthread_getname_np——如果我搜索 pthread getname 而不是 thread_getname,我会找到 pthread_getname_np 的定义)。Github还评估了 Russ Cox 所描述的三元词标记化。Github的结论由一位 GitHub 员工总结如下:
trigram 标记化策略非常强大。 它将以搜索时间和索引大小为代价产生出色的搜索结果。 这是我想采用的方法,但还有一些工作要做,以确保我们可以扩展 ElasticSearch 集群以满足此策略的需求。
鉴于上述 Elasticsearch 集群的初始规模,当时大幅增加存储和 CPU 需求是不可行的,因此我们推出了针对代码标识符调整的尽力而为的标记化。
多年来,Github不断回到这个讨论。受 Elasticon 2016 上与 Elasticsearch 专家的一些对话启发,支持特殊字符的一个有前途的想法是使用 Lucene 标记器模式,该模式在空白运行时拆分代码,但也用于从单词字符到非单词字符的转换(至关重要的是,使用前瞻/后视断言,在这种情况下不消耗任何字符;这将为每个特殊字符创建一个标记)。这将允许搜索“answer >= 42”以找到源文本答案 >= 42(不考虑空格,但包括比较)。实验表明,这种方法需要 43-100% 的时间来索引代码,并且生成的索引比基线大 18-28%。查询性能也受到影响:充其量与基线一样快,但某些查询(尤其是那些使用特殊字符的查询,或以其他方式拆分为许多标记的查询)最多慢 4 倍。最后,典型的查询速度降低 2.1 倍似乎代价太高了。
到 2019 年,Github在扩展 Elasticsearch 集群方面进行了大量投资,只是为了跟上底层代码语料库的有机增长。这给了我们一些性能空间,在 GitHub Universe 2019 上,我们有足够的信心宣布“完全匹配搜索”测试版,它基本上遵循上述想法,可用于允许列出的存储库和组织。我们预计该索引的 Elasticsearch 资源使用量将增加约 1.3 倍。有限测试版的经验非常有启发性,但事实证明,在额外资源需求与指数持续增长之间取得平衡太难了。此外,即使在标记化改进之后,仍然有许多不受支持的用例(如子字符串搜索和正则表达式)我们看不到任何途径。最终,完全匹配搜索在短短半年多的时间里就消失了。
项目黑鸟(Blackbird)
实际上,暂停对精确匹配搜索的投资的一个主要因素是一个非常有前途的研究原型搜索引擎,内部代号为 Blackbird。该项目已于 2020 年初启动,其目标是确定哪些技术将使我们能够在 GitHub 规模上提供代码搜索功能。
让我们回想一下Github的宏伟目标:全面索引 GitHub 上的所有源代码,支持增量索引和文档删除,并提供闪电般快速的精确匹配和正则表达式搜索(具体而言,全局查询不到一秒的 p95,相应地降低目标组织范围和回购范围的搜索)。在不使用比现有 Elasticsearch 集群多得多的资源的情况下完成所有这些工作。集成 GitHub 上可用的其他丰富代码智能信息来源。很简单,对吧?
我们发现没有现成的代码索引解决方案可以满足这些要求。 Russ Cox 的代码搜索三元组索引仅存储文档 ID 而不是发布列表中的位置;虽然这使得它非常节省空间,但随着语料库的大小,性能会迅速下降。几个后续项目用职位信息或其他数据扩充了发布列表;这需要大量的存储和 RAM 成本(Zoekt 报告了 3.5 倍语料库大小的典型索引大小),这使得它在我们的规模上过于昂贵。分片策略也很重要,因为它决定了负载分布的均匀程度。在考虑将索引扩展到 GitHub 上的所有存储库时,任何显着的每个存储库开销都变得令人望而却步。
最后,Blackbird 说服我们全力以赴为代码构建自定义搜索引擎。用 Rust 编写,它创建并增量维护一个由 Git blob 对象 ID 分片的代码搜索索引;这通过重复数据删除为我们节省了大量存储空间,并保证了跨分片的均匀负载分布(这是通过 repo 或 org 进行分片的经典方法,例如我们现有的 Elasticsearch 集群,缺乏)。它支持对文档内容进行正则表达式搜索,并且可以捕获额外的元数据——例如,它还维护符号定义的索引。它满足了我们的性能目标:虽然总是有可能提出一个遗漏索引的病态搜索,但对于“真正的”搜索来说它的速度非常快。该索引也非常紧凑,重量约为(去重)语料库大小的 1/3。
一个重要的认识是,如果我们想将 GitHub 上的所有代码索引到一个索引中,结果评分和排名绝对至关重要;你真的需要先找到有用的文件。 Blackbird 实现了许多启发式方法,一些特定于代码的(排名定义和惩罚测试代码),以及其他通用目的(排名完整匹配和惩罚部分匹配,以便在搜索线程时,名为 thread 的标识符将排名高于 thread_id ,它将排在 pthread_getname_np 之上)。当然,发生匹配的存储库也会影响排名。我们希望在作为测试创建的长期被遗忘的存储库中的随机匹配之前显示来自流行的开源存储库的结果。
所有这一切都在进行中。我们不断调整我们的评分和排名启发式方法,优化索引和查询过程,并迭代查询语言。我们有一长串要添加的功能。但是我们希望将我们今天拥有的东西交到用户手中,以便您的反馈可以决定我们的优先事项。
站在巨人的肩膀
现代软件开发是关于协作和利用开源的力量。 我们的新代码搜索也不例外。 如果没有数以万计的开源贡献者和维护者的出色工作,他们构建了我们使用的工具、我们依赖的库以及我们可以采用和开发的富有洞察力的想法,我们就不可能接近它的当前状态。
参考文档
https://github.blog/2021-12-15-a-brief-history-of-code-search-at-github/
https://github.blog/2008-11-03-github-code-search/
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/opensource-share/3141/