1.前言
2.背景
3.技术方案
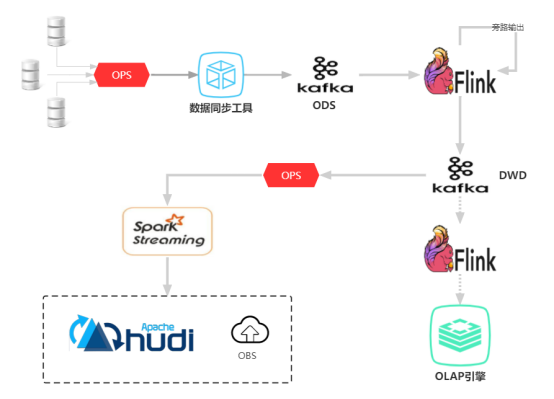

4.数据流向图
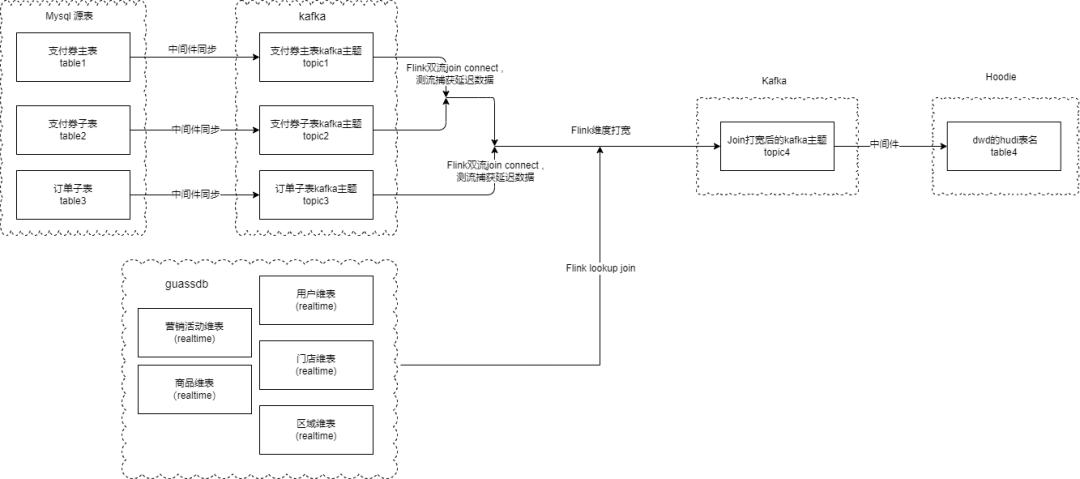
5.实现细节






6.总结
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/11455/

1.前言
2.背景
3.技术方案
4.数据流向图
5.实现细节
6.总结
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/11455/