


OPPO 大数据平台目前有 20+个服务组件,数据量超 1EB,离线任务数近百万,实时任务数千,数据开发分析师超千人。这也带来了系统复杂度的问题,一方面是用户经常对自己的任务运行状况“摸不着头脑”,不管是性能问题,还是参数配置问题,甚至是一些常见的权限报错问题,都需要咨询平台给出具体的解决方案;另一方面是平台面对各类繁杂任务,运维人员经常需要对任务故障定位和排除,由于任务链路长,组件日志多,运维压力大。因此急需对任务进行实时监控和诊断,不仅要能够帮助用户快速定位异常问题,还需给出具体的建议和优化方案,同时还能治理各类“僵尸”和不合理任务,从而达到降本增效的目的。据调研,目前业界尚无成熟的开源任务诊断平台。为此我们开发了大数据诊断平台,通过诊断平台周优化任务实例数超2 万,取得了良好的效果。
“罗盘”(Compass)便是基于 OPPO 内部大数据诊断平台的开源项目(项目地址:https://github.com/cubefs/compass),可用于诊断 DolphinScheduler、Airflow 等调度平台上所运行的大数据任务。我们希望通过“罗盘”(Compass)回馈开源社区,也希望更多人参与进来,共同解决任务诊断的痛点和难题。
罗盘目前已支持以下功能和特性:
-
非侵入式,即时诊断,无需修改已有的调度平台,即可体验诊断效果。 支持多种主流调度平台,例如 DolphinScheduler、Airflow 或自研等。 支持多版本 Spark、Hadoop 2.x 和 3.x 任务日志诊断和解析。 支持工作流层异常诊断,识别各种失败和基线耗时异常问题。 支持引擎层异常诊断,包含数据倾斜、大表扫描、内存浪费等 14 种异常类型。 支持各种日志匹配规则编写和异常阈值调整,可自行根据实际场景优化。
罗盘已支持诊断类型概览:
|
诊断维度 |
诊断类型 |
类型说明 |
|
失败分析 |
运行失败 |
最终运行失败的任务 |
|
首次失败 |
重试次数大于1的成功任务 |
|
|
长期失败 |
最近10天运行失败的任务 |
|
|
耗时分析 |
基线时间异常 |
相对于历史正常结束时间,提前结束或晚点结束的任务 |
|
基线耗时异常 |
相对于历史正常运行时长,运行时间过长或过短的任务 |
|
|
运行耗时长 |
运行时间超过2小时的任务 |
|
|
报错分析 |
sql失败 |
因sql执行问题而导致失败的任务 |
|
shuffle失败 |
因shuffle执行问题而导致失败的任务 |
|
|
内存溢出 |
因内存溢出问题而导致失败的任务 |
|
|
成本分析 |
内存浪费 |
内存使用峰值与总内存占比过低的任务 |
|
CPU浪费 |
driver/executor计算时间与总CPU计算时间占比过低的任务 |
|
|
效率分析 |
大表扫描 |
没有限制分区导致扫描行数过多的任务 |
|
OOM预警 |
广播表的累计内存与driver或executor任意一个内存占比过高的任务 |
|
|
数据倾斜 |
stage中存在task处理的最大数据量远大于中位数的任务 |
|
|
Job耗时异常 |
job空闲时间与job运行时间占比过高的任务 |
|
|
Stage耗时异常 |
stage空闲时间与stage运行时间占比过高的任务 |
|
|
Task长尾 |
stage中存在task最大运行耗时远大于中位数的任务 |
|
|
HDFS卡顿 |
stage中存在task处理速率过慢的任务 |
|
|
推测执行Task过多 |
stage中频繁出现task推测执行的任务 |
|
|
全局排序异常 |
全局排序导致运行耗时过长的任务 |
(一)非侵入式,即时诊断
这里以 DolphinScheduler 调度平台为例。
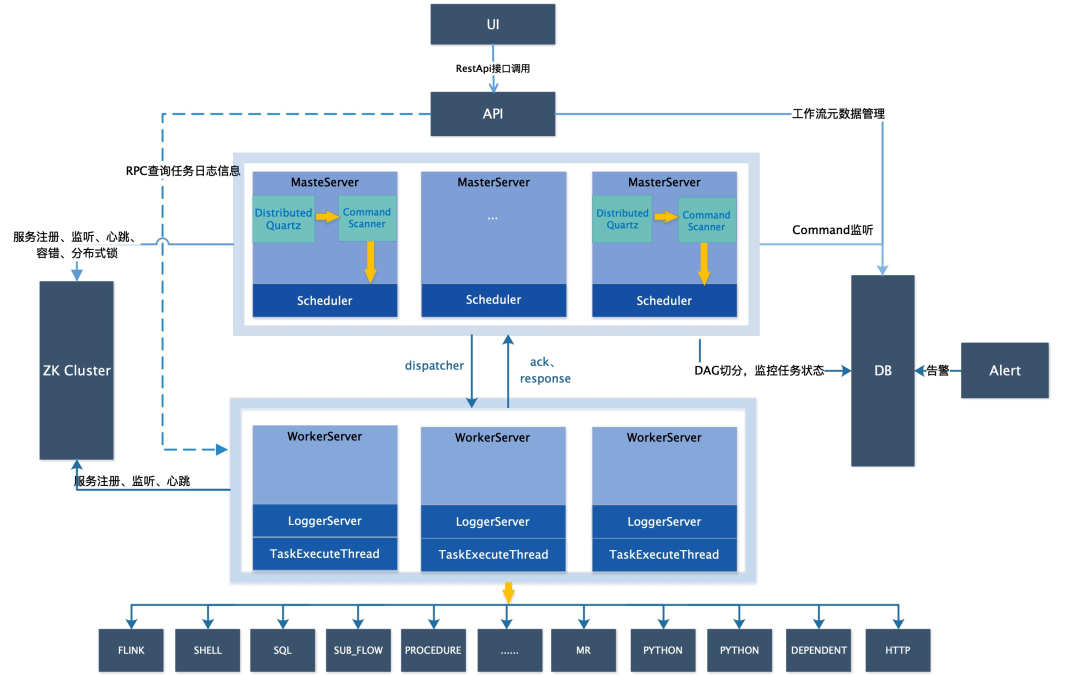
从架构上看,MasterServer 主要负责 DAG 任务切分、任务提交监控并持久化任务实例数据到 DB 中,WorkerServer 主要负责任务的执行和提供日志服务,同时在 UI 提供了查看远程日志的功能。为了能够获取任务元数据和相关日志进行诊断,一个方式是在 MasterServer 中监听任务状态事件,另一个方式是订阅 MySQL
binlog 日志。为了减少对 DolphinScheduler 的修改,我们采取了第二种方式。
因此只需要在 DolphinScheduler创建一个工作流,并运行,等待运行结束,我们便可在罗盘上看到该任务运行失败等异常。
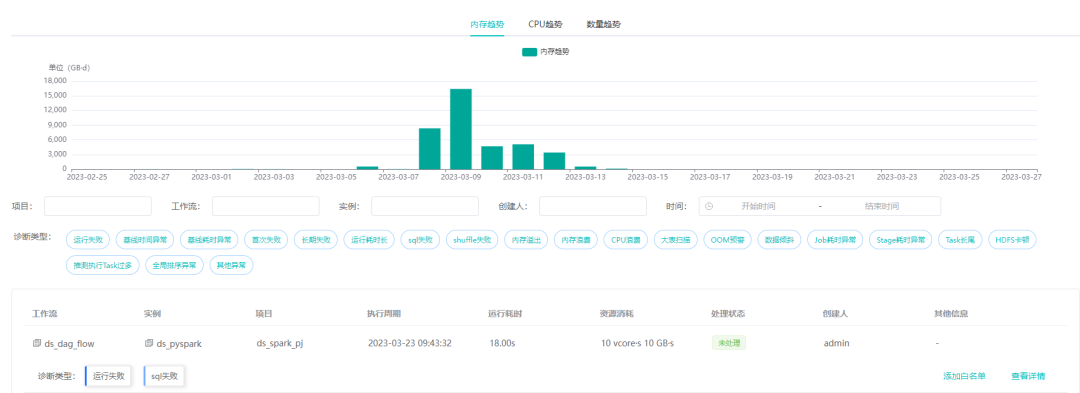
罗盘不但实现了对调度平台的解耦,还能在任务运行结束后即时诊断,同时提供了丰富的 UI 展示服务。如果您不需要我们提供的 UI 服务,那也可以直接查询罗盘诊断的元数据,展示在需要的地方。
(二)工作流层异常诊断
对于工作流层的任务实例,常见问题可分为两类:一类是失败的任务,例如首次失败、最终运行失败和长期失败;另一类是耗时异常的任务,例如基线时间异常、基线耗时异常和运行耗时长。
1. 诊断失败的任务
用户经常忽略首次失败,甚至加大重试次数,如果不重视,最终可能会演变为最终失败。罗盘记录和诊断分析了每次失败的原因,不仅可以为用户快速定位问题,还可以在故障回溯时找到根因。对于长期失败的任务,需要通知用户整改或清理,避免造成资源浪费。
2. 诊断耗时异常的任务
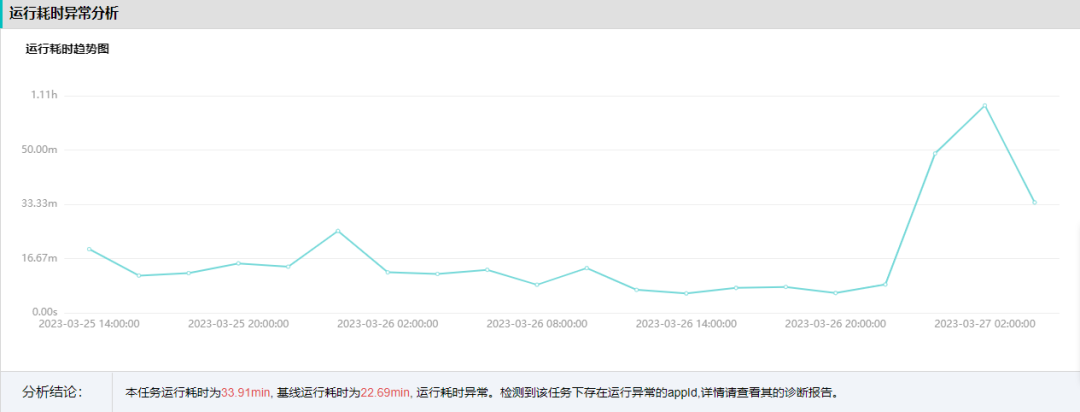
针对需要 SLA 保障的任务,罗盘不仅分析了相对于历史正常结束时间,是否提前结束或者晚点结束的任务,即基线时间异常,也分析了相对于历史正常运行时长,是否运行时间过长或者过短的任务,即基线耗时异常。对于运行耗时长的任务,例如超过几个小时以上的大任务,用户和平台都需要分析是任务本身的问题,还是平台的问题。
(三)Spark 引擎层异常诊断
对于 Spark 任务,常见的问题可以归为三类:一类是运行时报错,另一类是运行时效率,最后一类是资源使用率问题。
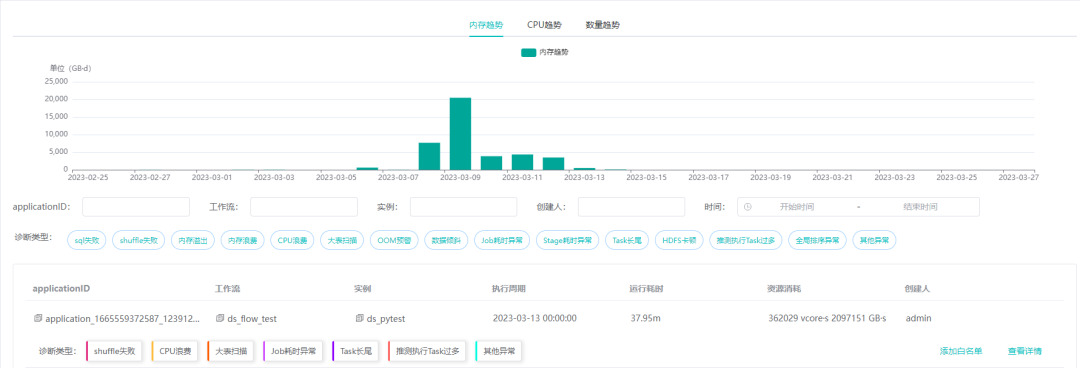
1. 诊断运行时报错异常
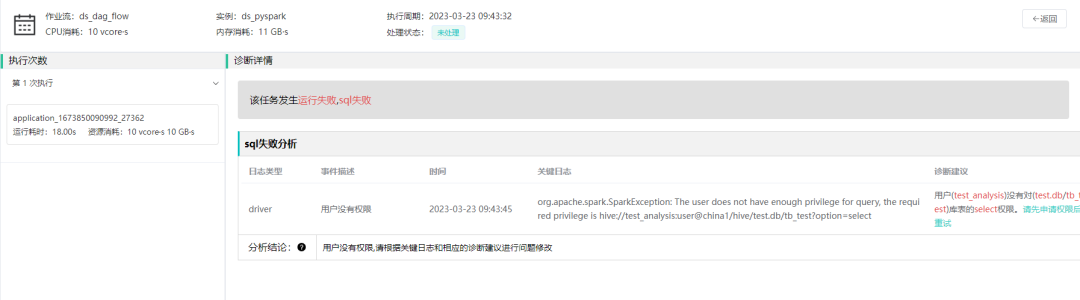
引擎层常见报错有 sql 失败、shuffle 失败和内存溢出等。此类报错具有明显的日志特征,可根据关键字提取分类,使用已有的知识库,提供给用户具体的解决方案,提升用户体验和效率。
罗盘提供了 sql 失败日志分析的规则,通常涉及到操作权限,库表不存在及语法等问题,此类问题可直接指引用户去申请权限。

shuffle 问题会严重影响任务运行甚至导致失败,需要重点关注,如果您目前没有更好的解决方案,也可以参考 OPPO 开源的高性能远程 shuffle 服务。
( https://github.com/cubefs/shuttle )

内存溢出也是经常导致任务失败的一大问题,可提取关键日志诊断分析并建议用户优化内存配置参数。
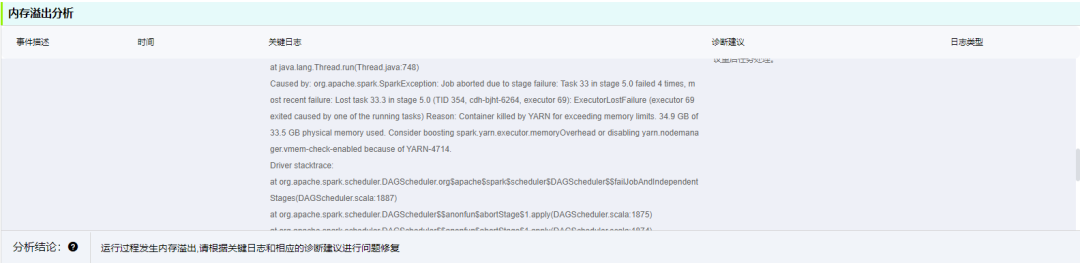
除了以上问题,罗盘还提供了 40+的日志识别规则及建议,也可自行根据实际场景扩展识别规则。
2. 诊断运行时效率异常
如果任务执行耗时较长或者突然变慢,用户直接在调度平台无法判断是任务自身问题,还是调度平台问题,亦或是计算引擎的问题。为了排查 Spark 引擎,一般需要专业分析 SparkUI,比较不直观。罗盘对影响引擎执行效率的问题做了全面的检测,覆盖大表扫描,数据倾斜,Task 长尾,全局排序,OOM 风险,Job/stage 耗时异常,HDFS 卡顿,推测执行 Task 过多等问题。
罗盘对执行的 SQL 扫描表行数,直观呈现在表格中。如果用户没有进行分区条件筛选,可能会发生全表扫描,需要提醒用户优化 SQL,避免导致内存溢出和影响集群,以提升运行效率。

罗盘检测每个 Task 的数据处理量并判断数据是否倾斜。当数据倾斜时,可能会导致任务内存溢出,计算资源利用率低,作业执行时间超出预期。

罗盘检测所有 Task 的耗时,并按 Stage 呈现在柱状图中,方便用户判断是哪个 Stage 执行耗时异常。形成的原因一般是读取数据过多或读取数据慢。如果是数据倾斜造成读取数据过多,则按数据倾斜方式处理。如果同时 HDFS 发生卡顿,则会导致读取数据慢,则需要排查集群问题。
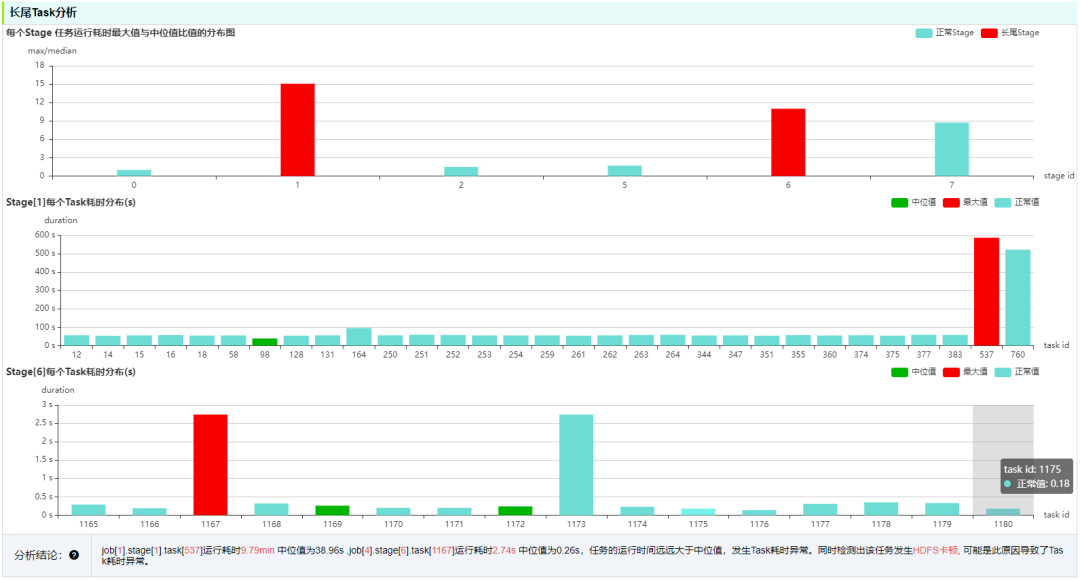
用户经常在 SQL 中使用了排序函数却不加分区限制,会导致全局排序。如果只有一个 Task 处理数据,需要建议用户重新分区,避免造成资源浪费和影响运行效率。

罗盘检测执行 SQL 广播内存占比,当广播数据过大,会导致 driver 或 executor 出现 OOM 风险,需要提醒用户禁用广播或取消强制广播,必要时申请增加内存。

罗盘计算每个 Job/stage 实际计算时间和空闲时间,一般是资源不足时出现,需要关注集群资源问题。
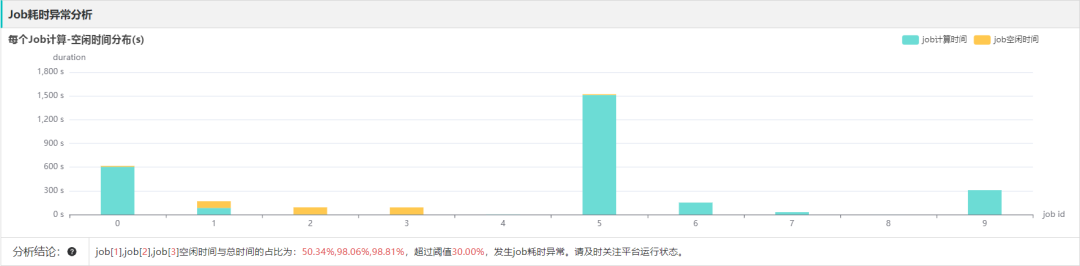
当出现 HDFS 卡顿时,会影响 Task 读取数据速率,从而影响执行效率,需要关注 HDFS 集群运行状态。
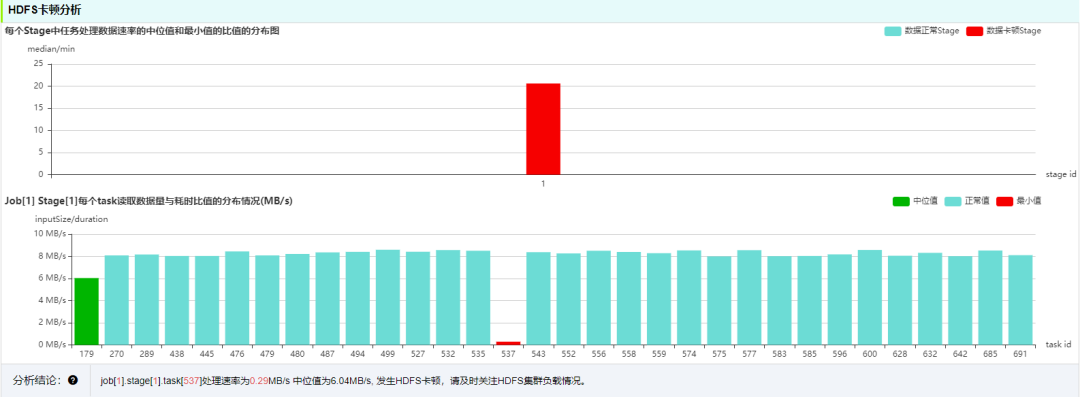
推测执行 (speculative) 是指作业执行单元 Task 在同一个 Stage 中的执行时间相比其他 Task 执行时间长,在其他 Executor 发起相同 Task 执行,先完成的 Task 将 Kill 另个 Task, 并取得结果。需要关注集群运行状态。
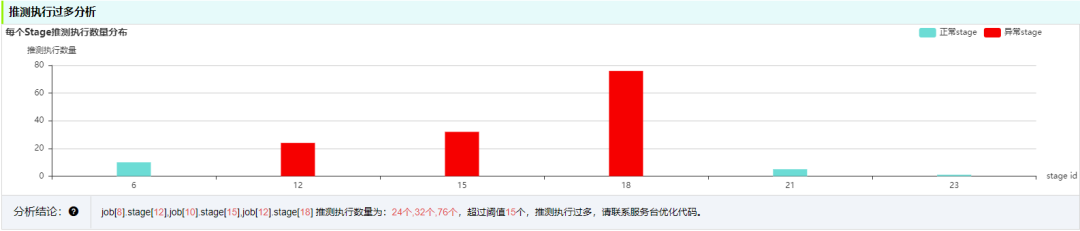
3. 诊断资源使用率异常
对于用户不确定任务 CPU 和内存使用情况,不知道怎么申请多大规格资源的问题,罗盘直观呈现了 CPU 和内存使用占比,方便用户优化资源配置参数,以节约资源成本。
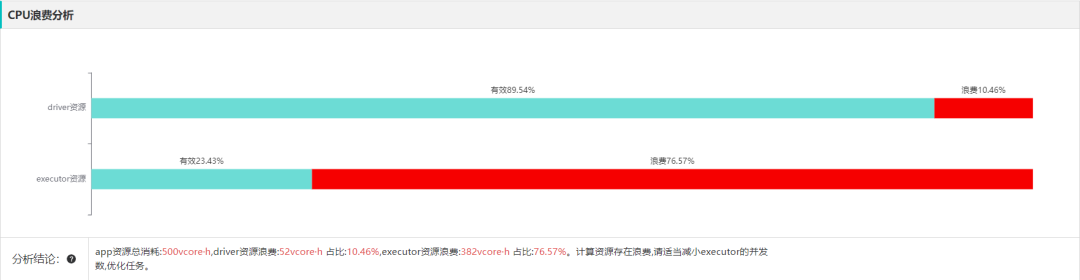
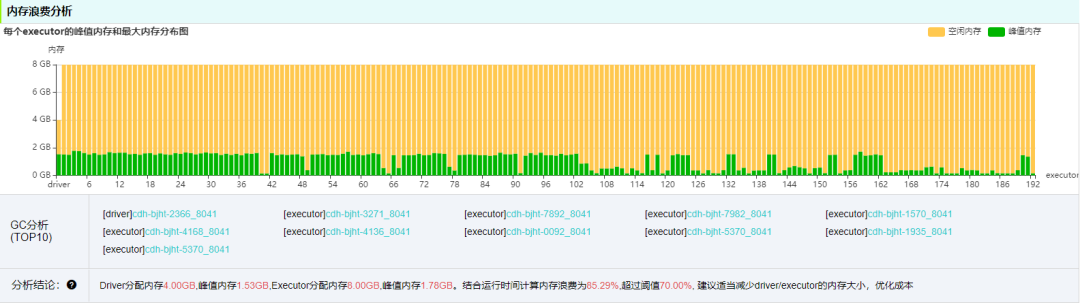
罗盘还提供了 GC 日志分析功能,可查看执行过程 GC 是否存在性能问题。

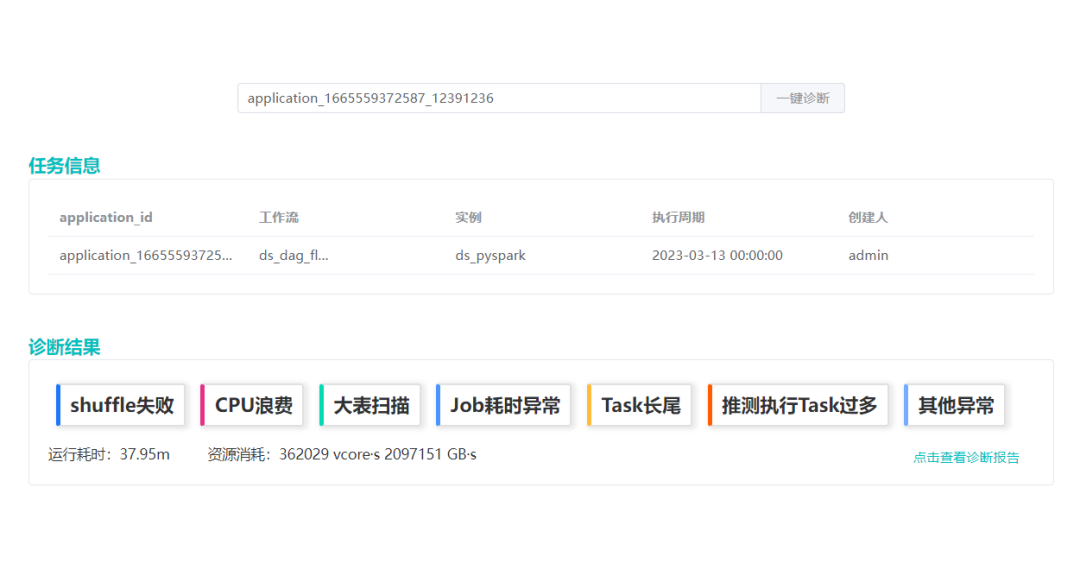
(四)一键诊断、报告总览等功能
除了以上功能,我们还提供了一键诊断的功能,为用户提供详细的诊断报告。同时还有报告总览数据和白名单功能等。

整体架构图

整体架构分 3 层:
-
第一层为对接外部系统,包括调度器、Yarn、HistoryServer、HDFS 等系统,同步元数据、集群状态、运行环境状态、日志等到诊断系统分析; 第二层为架构层,包括数据采集、元数据关联&模型标准化、异常检测、诊断 Portal 模块; 第三层为基础组件层,包括 MySQL、Elasticsearch、Kafka、Redis 等组件。
具体模块流程阶段:
(1)数据采集阶段:从调度系统将用户、DAG、作业、执行记录等工作流元数据同步至诊断系统;定时同步 Yarn
ResourceManager、Spark HistoryServer App 元数据至诊断系统,标志作业运行指标存储路径,为后续数据处理阶段作基础;
(2)数据关联&模型标准化阶段:将分步采集的工作流执行记录、Spark App、Yarn App、集群运行环境配置等数据通过 ApplicationID 介质进行关联,此时,工作流层与引擎层元数据已关联完毕,得到数据标准模型 (user, dag, task, application, clusterConfig, time);
(3)工作流层&引擎层异常检测阶段:至此已经获得数据标准模型,针对标准模型进一步 Workflow 异常检测流程,同时平台维护着一套沉淀多年的数据治理知识库,加载知识库到标准模型,通过启发式规则,对标准模型的指标数据、日志同时进行异常挖掘,结合集群状态及运行是环境状态,分析得出工作流层、引擎层异常结果;
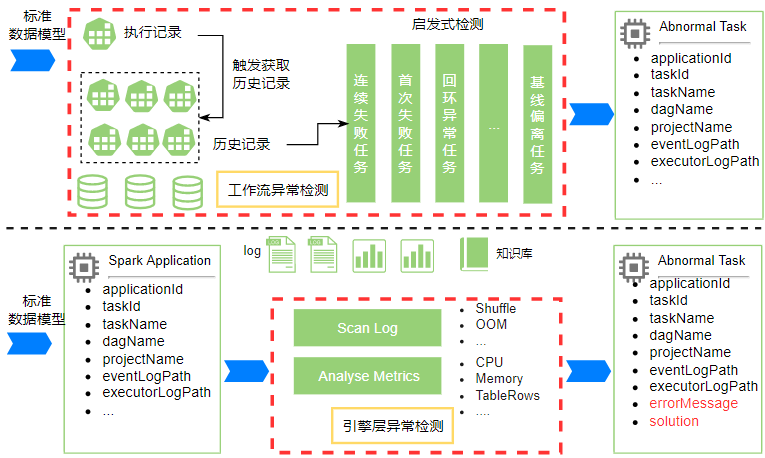
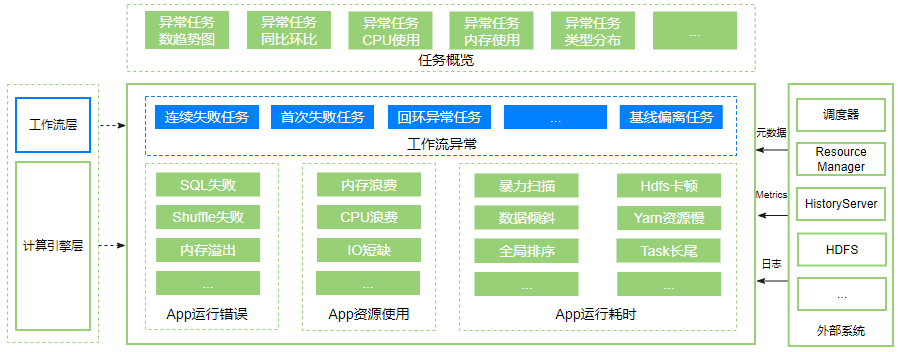
(4)业务视图:存储、分析数据,提供给用户任务概览、工作流层任务诊断、引擎层作业 Application 诊断,工作流层展示调度器执行任务引发的异常,如任务失败、回环任务、基线偏离任务等问题,计算引擎层展示 Spark 作业执行引发的耗时、资源使用、运行时问题;
(一)部署体验
这里我们以 DolphinScheduler(2.0.6 版本)为例,体验如何快速集成罗盘。如果你还没有部署 DolphinScheduler,可参考官网部署指南。如果你已经在使用 DolphinScheduler,那么只需要部署罗盘即可。罗盘支持单机和集群部署,如果你想要快速体验罗盘的功能,可使用单机部署模式,罗盘依赖 Kafka、Redis、zookeeper 和 ElasticSearch,需要提前安装,依赖服务完成后即可通过部署脚本进行罗盘部署:
代码编译
git clone https://github.com/cubefs/compass.gitcd compassmvn package -DskipTests
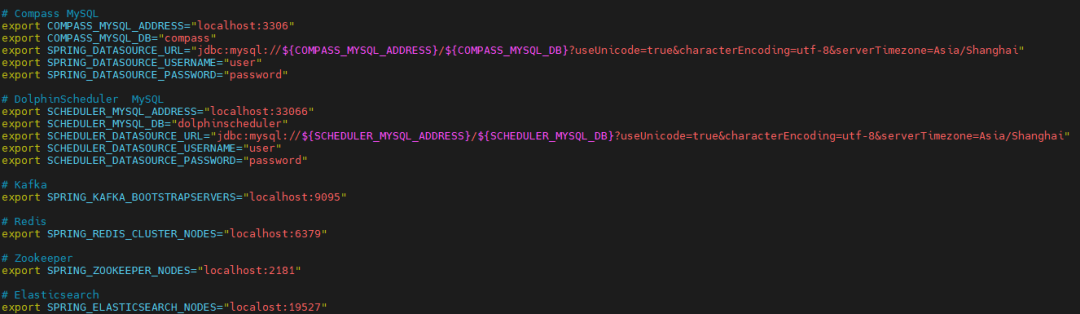
修改配置
cd dist/compass# 修改数据源和相关配置,如下图vim bin/compass_env.sh
-
一键部署
./bin/start_all.sh
(二)使用示例
首先在 DolphinScheduler 创建好项目
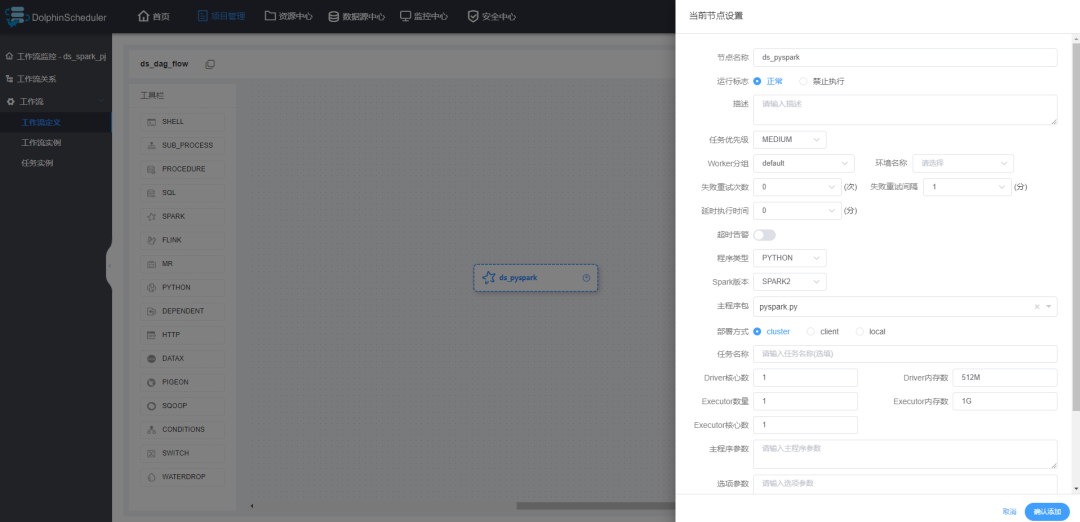
然后创建一个 SPARK 任务的工作流
最后上线该任务和运行

打开罗盘 Web UI,默认路径为 http://localhost:7075/compass/ ,输入 DolphinScheduler 的账号密码,罗盘自动同步了 DolphinScheduler 用户信息。

最后进入任务运行页面,便可以看到所有的异常任务诊断信息。
-
罗盘主要围绕离线调度任务、计算引擎两个方面对问题进行定位分析,使用丰富的知识库,提供给用户解决优化方案,同时达到降本增效的目的。 目前已开源部分主要包含对任务工作流和 Spark 引擎层的问题诊断,不久将发布针对 Flink 任务的异常和资源问题诊断。 未来将引入更深层次的算法和诊断模型,实现去规则和阈值,使异常诊断更加智能化。
【Github 地址】:https://github.com/cubefs/compass
欢迎参与贡献,如果您有需求或建议可以提issue 到 Github,我们将及时为您解答。
OPPO 安第斯智能云(AndesBrain)是服务个人、家庭与开发者的泛终端智能云,致力于“让终端更智能”。作为 OPPO 三大核心技术之一,安第斯智能云提供端云协同的数据存储与智能计算服务,是万物互融的“数智大脑”。
本文转载自安第斯智能云,原文链接:https://mp.weixin.qq.com/s/YRropn7qW0upXTLTNK53-A。